Agent Development
In a world increasingly powered by AI, creating reliable and efficient agents isn’t just about technology but also about processes, strucutures and methodologies. This blog will take you behind the scenes of our agent development, and the various phases involved until production rollout.
The development of an AI agent, much like a traditional development, begins with a requirements elicitation and documentation phase. However, the agent development has many different and additional phases which we briefly will touch upon in this article. A simplified diagrammatic view of agent development might look something as this:
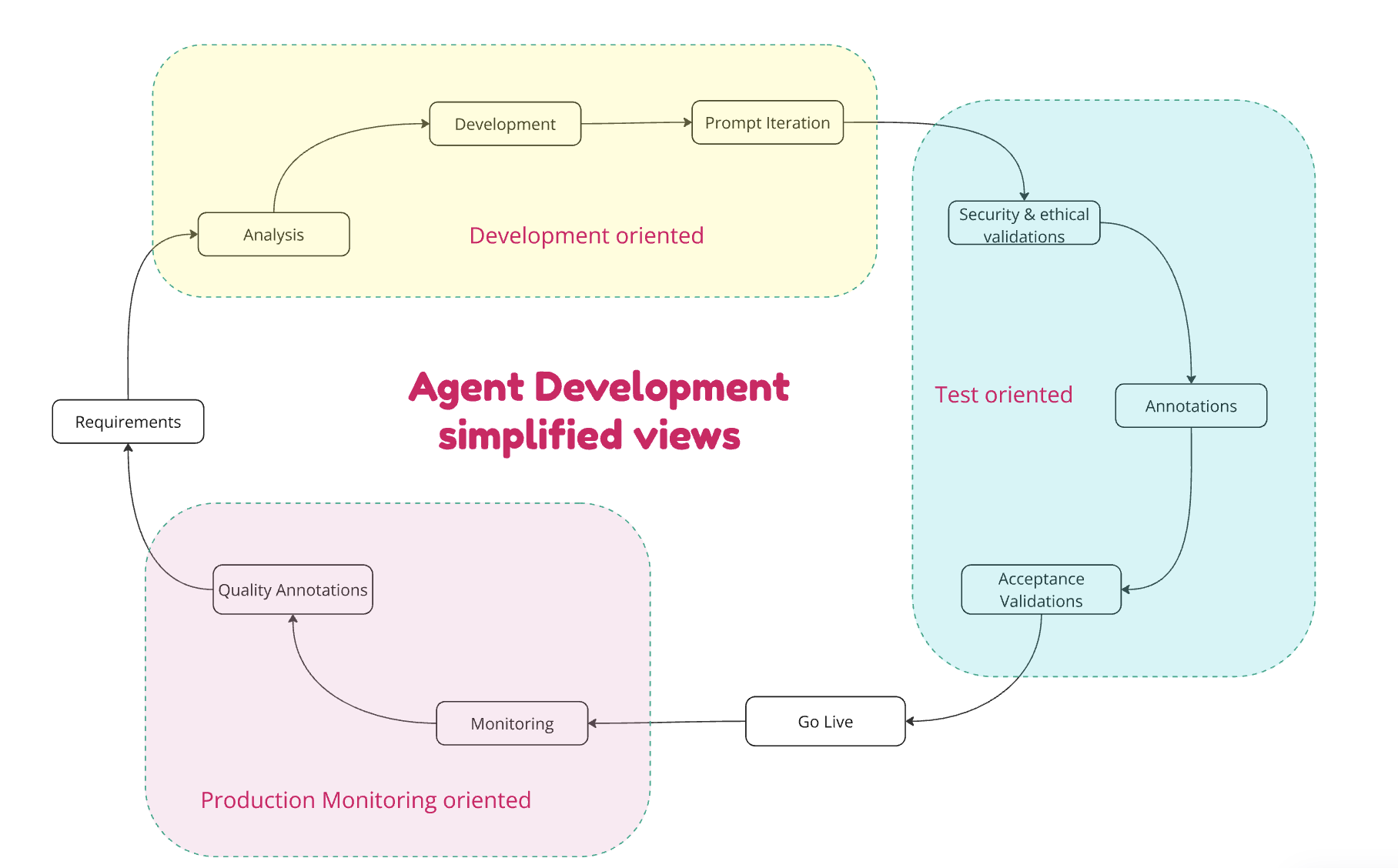
To begin with, we first look at the production dataset available for conversations and service tickets created by our human agents.
In most CRM systems, there is a broad classification already available underneath which few set of conversation details are logged by human agents. For example, there might a conversation with the customer related to a 5G network issue, this may be logged in the CRM system under Network issues category which may have further subcategories.
We looked at this information and determined the categories for which the largest number of tickets were logged in a month. For example, Customers may be calling mostly for Billing related queries. Using these statistics available from production, it is determined which Business domain should be prioritized first. An extensive analysis of this CRM data is done to determine the different category of problems a customer seeks help for under the Billing domain. For each category it is determined what set of knowledge will be required to answer or help with those queries or problems. In some cases the knowledge is right away available from the CRM tickets but in other cases, we may have to scrap data off from webpages, pdf documents or other available knowledge APIs.
As such, the outcome of the Requirements phase is that we usually end up with a detailed story, which is then further broken down into multiple stories for different Teams:
- Knowledge Operations Team
- AI Agent Engineering Team
- Data Science Team
- Security and Compliance Team
Knowledge Operations Team is usually tasked with building pipelines to scrap data off sources such as help and support pages etc, and integrating these pipelines with the vector search services to convert this data into embeddings representations stored in vector databases.
Agent Engineering Team is tasked with development of AI agents that orchestrate and interact with other agents, models, and services in order to cater to the queries for the domain to which that agent belongs.
Agent Data Science Team takes care of determining what is the best model to be used for the specific use cases and language. Our Data Science team also writes initial prompts and runs them through several iterations to get the desired results.
Security and Compliance Team helps out with providing guidelines and doing assessments to ensure we stay compliant to all the GDPR and other security, privacy, and ethical guidelines.
Here is an example story, our teams usually create sub-tasks or sub-stories under each story for different teams.
Example story:
As a Billing agent, I need to use all relevant knowledge and prompts at my disposal to appropriately answer one of the following Billing query.
Agent inscope capabilities: The billing agent must be able to answer anything related to the following:
- Breakdown of bill - Explain and elucidate any question related to tax calculation, extra data usage charges, recurring bill amounts.
- Bill amount surge - In cases when backend provides supporting data, the agent must be able to answer why my current bill is higher than last month's bill.
- Compare bills - Be able to compare bills for two months and spot the differences leading to a higher bill amount.
- Link to down bills - ability to fetch and share urls for last three month bills.
- Charge codes on bill - be able to explain special charge codes on the bills in details for example 'RCMG-1mon' may suggest an international charge code on the bill for one month.
- Third party references - be able to refer the customer to third party portals when there is a third party charge on the bill.
- Bill cycles - be able to guide the customer how bill cycle can be changed if needed.
- Payment status - be able to answer which bills have been fully paid and which have an outstanding amount.
Agent out of scope capabilities:
- Following would be consider out of scope for the capabilities of the agent:
- Anything that is classified as non-billing question by the intent classifier.
- Anything in the Billing intent but which requires access to specific data that is currently not available.
- Anything related to helping the customer make an instant payment using the agent.
KPIs: The agent's success criteria would be coverage of 90% of the in-scope queries with a resolution rate of 80%, 5% fabricating information, and 2% risky information.
Decision framework: Production agent conversation data was analyzed. A classification was made on the high level support type tickets, and it was determined that 50% of the support queries are related to Billing. With this agent going live and meeting the defined KPIs, we expect to deflect approximately 5000 daily calls off the call center.
Utterances: Sample utterances as noted from our agent conversation database, is attached for references and for tests and validations. This data has been refined by our Team of data scientists to make it usable for tests and validations.
Test Data:
- Account existing in the billing system with a bill having consecutive surge over last two months - 2342938498
- Account with only one paid bill in the last three months - 342342342
- Account with special international roaming charge and OTT subscription charge - 9273293482
Samples best response examples as per Utterances dataset:
Use this data as an example for LLMs, prompt refinements and/or multi-shot trainings.
Sample Conversation1
Sample Conversation2
Sample Conversation3
Development Phase
In the development phase our teams undertake several tasks. LMOS platform minimizes the developers efforts and ensures most of the recurring steps and complex interactions are taken care of so developer can only focus on the key enhancements related to the Business domain.
Here are some examples:
Step functions:
Several common functions that have to be undertaken by an agent have been modeled as a step, for example, if there is a url that has been generated by the LLM then it is ascertained in this step whether this is a whitelisted url that can be passed back to the customer or not (removing hallucinated urls). We maintain an easily configurable list of urls that can be updated through a simple CMS frontend by anyone.
Another example might be to classify and rephrase the complete previous LLM conversation so it can be passed as a contextual information in the next request to the LLM.
In general the development of most agents require some pre-defined mandatory steps which are take care of by the platform, for example logging final response, but some steps are configurable and can be skipped depending on capabilities needed from the agent.
There might be many existing steps which are provided by the platform, however depending on the capabilities needed in the agent and Business use cases, new steps may have to be introduced by our Teams. It is carefully ascertained if something can be incorporated as a step in core platform or if it can be added as a validation code in the agent. Our team of architects and software designers take appropriate decisions to guide our team members as needed.
For a case when dynamic control is needed, flow of prompts are modified using pre-defined, configurable templates.
Flow of Prompts:
In several cases, the execution flow for an agent may require some dynamic modifications in run time or may need tweaks via prompt engineering without any code interventions by the Engineering teams.
These would be the classic cases such as depending on the input language, region, tenant or channel we may have to execute some specific code, for example it might be an IVR channel and an additional step might be needed to fine tune the tone or conciseness of the response. This flow of prompts is usually defined via prompt templates, and we have prompt templates created for every agent.
Retrieved Augmented Generation:
For every new agent, accessing RAG knowledge is all about writing a single line of code, and specifying the tenant since LMOS platform natively supports multi-tenancy and decides, on the basis of tenant input, as to which RAG database to query for embeddings.
However, with each new agent, we have to supplement the RAG with new knowledge of the domain. Some of this knowledge is available from pdfs, some from help and support pages and some from pre-existing anonymized conversations.
In each case, we have dedicated knowledge pipelines which are integrated with our search services and these knowledge sources are connected to these pipelines to extract and transform the data into embedding representations stored in our vector databases. This is a task that is undertaken by our Knowledge Operations Team that scours the available resources for the best source of knowledge and integrate them into our pipelines. RAG is a big topic and you can read more about it at RAG overview.
Backend APIs:
There are several cases where specific information pertaining to a user's usage is required, as such an access to some backend APIs is required. In our system, we have a carefully guarded backend database accessible only via a secure API layer after appropriate authentication & authorizations through a central gateway. Access is strictly controlled on a need to know basis and limited only to required non-private datasets.
Based on the Business use cases, several new APIs may be required to be invoked. The developers write corresponding LLM functions for every API that caters to a specific business case, these functions on the basis of Business domains are grouped together with clear annotated descriptions and information for each of these APIs is passed to the LLM to understand which functions is needed to invoke a specific API for fetching specific details.
Each such LLM function also goes through privacy and security review to ensure we stay compliant to norms and regulations, and entity recognition models (Anonymization models) are used to determine and scrub SPI data.
LMOS platform takes care of the underlying complexities such as:
- Transforming the functions to appropriate API request models as per LLM API specifications.
- Invocation of APIs as requested by the LLM via functions.
- Transforming the response back into a an LLM API format.
- Handling the LLM response and handing over to the agent for further processing.
Prompting - Dynamic, natural language based:
Our ARC DSL allows anyone from the team to define prompts in a simple natural language. The prompt engineer has an arsenal of dynamic functions which can be used in prompts to enhance the prompt in real time with additional information which can be fetched from the system during an actual flow. For example, you might want to send a specific url to the LLM depending on the type of customer asking the query, if it is a Business customer there might be a greeting or formal tone to be used. The separation between ARC module for prompting and platform code module allows faster prompt iterations, easy modifications and quicker deployments.
In many cases depending on the Business requirements our teams may require to write new functions which can be used in the dynamic prompt flows.
Since prompts also support multi-tenancy there can be a different prompt which is configurable per channel and tenant for the same step. For example for prompt flow step of 'ClassifyAnswer' you can have a different prompt for IVR and different prompt for chat conversations.
During prompt engineering, our Agent Data Science team iteratively tweaks & validates the prompts so that the BOT response reaches a specific quality threshold.
In addition during prompt engineering, the Data Science members may also take several decision regarding whether to add additional knowledge into the knowledge database or supplement some information within prompts.
The supplemented knowledge may be about some general information that a BOT is supposed to know in terms of the guidelines of an organizations about communications with the customers, or some procedures followed to do something on behalf of the customer. In such cases, usually pdfs or other sources are procured, data is parsed processed, refined into a format and it can either be added as an information in the prompts or it can be added in the RAG by passing via embedding models.
In some cases, it is ascertained that some dynamic information is needed during runtime on the basis of which the LLM is supposed to take appropriate decisions. For example, In some cases it might be helpful for the LLM to know how many services the customer currently has so as to be able to answer better.
In other cases, it might be noticed that disambiguation is needed and the LLMs are instructed to ask specific number of queries in order to better understand the customer's query or to help with a better resolution.
Validation Phase
Annotations:
Responses generated by an LLM powered system are not always accurate, factually correct and reliable. One should ensure to integrate a human in the loop approach for any system that is powered by LLMs before rolling out major functionalities/changes into production specifically for applications where high stakes are involved.
Chatbot applications may need human feedbacks in many different cases/scenarios:
- Evaluate the system before rolling out a new feature in production.
- Recurring regression evaluations to uncover any unknown issues.
- Evaluate a new model, maybe for anonymization or embedding.
- Knowledge retrieval and ranking.
For the LMOS platform, for any new feature or Business domain that is introduced it is always ensured that human evaluators are sharing their feedbacks in a preprod environment before that feature goes live. Our framework has an integrated step 'Response Evaluation' through which another LLM is used to determine the quality and appropriateness of response before passing it on to the customer, however for any new major developments our team always ensures to have human evaluators evaluate the system typically on edge cases that may not conform to typical patterns.
Conversations or queries are fed into the LMOS agents via a chat frontend, and the complete conversational record turn by turn is saved into a database. We currently make use of Opensearch, and ensure each conversation and every message in the conversation can be uniquely identified with a conversationId, turnId respectively.
These conversations or queries are obtained from a processed dataset of conversational records from our CRM systems. In case you have a chat based system (LLM based or guided decision tree based chat system) you can also use these chat conversations, refine & process them into a format that can be fed into this system to generate responses for evaluations.
These generated conversations are basically scrapped via a script and refined into a specific dataset format which can be accepted by a specific tool used for evaluation. For evaluation of our LMOS agentic system, we make use of Argilla which allows us to define and adapt the evaluation criteria and questions as per our requirements. Argilla also supports displaying UI elements like tile, card etc. in case your chat application makes use of those so that the human evaluators are aware of how information was presented to the customers.
The human evaluators are supposed to rate every response on certain parameters for example:
- Does this response contain any sensitive information ?
- How appropriate is this response on a scale of 1-5 ?
After the end of evaluation, the evaluations by human are represented usually in terms of some of these key metrics:
- Risky %
- Fabricating Info %
- Response Quality %
- Hallucination %
The values for these KPIs are generated by Argilla on the basis of defined weightage for each parameter or question.
Specific quality threshold are defined which have to be met for each of those KPIs before any new feature or agent is brought live into production. In case the generated numbers are below the acceptable value threshold then the system is handed back to the Engineers and Data scientists with appropriate feedbacks. Our team of Engineers and Data scientists, and Knowledge Ops members work together to ensure that appropriate optimizations are put into place to bring the system to an acceptable quality level, this can include prompt optimizations, RAG optimizations, etc.
Once the new feature of agent meets an acceptable quality level, then the agent is put into the next phase of Business validation.
In addition, recurring annotations are also done in production to evaluate our system on a weekly basis on the same quality KPIs.
Business Validations:
Since LMOS provides out of the box capabilities such as Blue Green and A/B, we are able to quickly deploy a new agent to a parallel beta test env on production infrastructure.
Our team of Business domain experts assess the quality of response of the bot and provide their feedbacks. Based on these feedbacks the dev teams take appropriate actions to correct the prompts and/or supplement the bot with additional knowledge as needed.
On reaching an appropriate quality threshold the agents are made live for real customers.
Monitoring and Improvements
Post go live, our teams continuously monitor the performance of the BOT. Continuous evaluation tools are used to keep an eye on the performance of the BOT. Frequent manual quality assessments are also done using annotation tools like Argilla.
Appropriate feedbacks noted from production monitoring & quality validations are noted in the backlog as improvement tasks, which are further prioritized and taken up into the sprints.
Differences - Agents vs Traditional development
It is certainly evident to our Development Teams that the outcomes from different iterations of tests are quite unpredictable due to the nature of the LLM models. Our teams make their best attempts at reducing this degree of uncertainty by engaging in various tweaks to the prompts, sharing examples to the BOT, controlling temperature etc. parameters.
This also brings with it the unpredictability in the estimates on the completion of such work which gets some of us thinking that some kind of unpredictability constant must be factored in while calculating the story point estimates for some of these stories.
In addition, there are no established patterns of the kind that are usually found in traditional domains or applications centered around domain driven designs. This leads to our Teams doing more of experimentation, learning from it and then moving forward with data driven decision making.
There are many ethical considerations which are also kept at the back of mind while designing such applications that leverage LLMs.