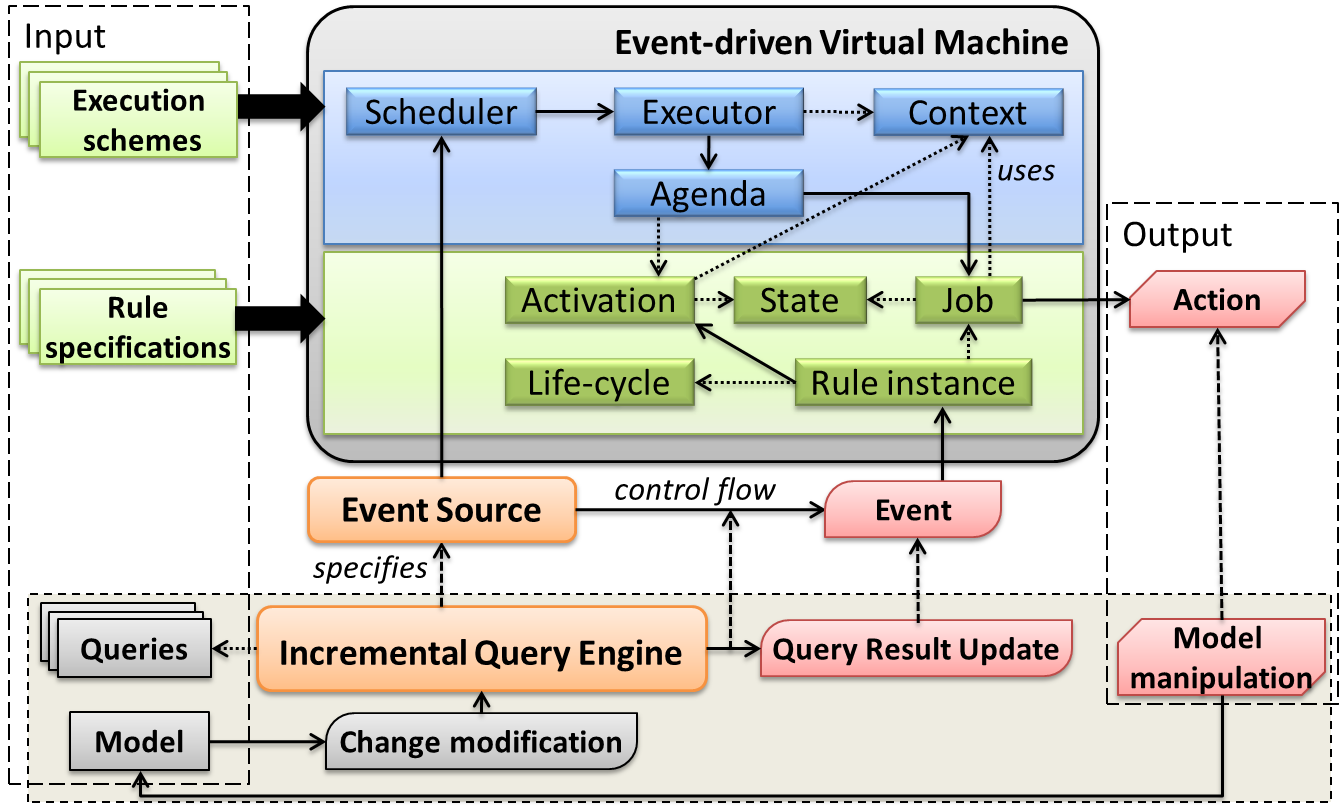
The Event-driven Virtual Machine
Nowadays, collaboration and scalability challenges in modeling tools are typically addressed with dedicated problem-specific solutions e.g.:
-
On-the-fly constraint evaluation engines (to provide scalability for model validation)
-
Incremental model transformation tools (to address performance issues of e.g. model synchronization)
-
Incremental model comparison algorithms (to support versioning and model merge in collaborative scenarios)
-
Design space exploration tools (to optimize models towards a design goal).
The common recurring task in these applications is to capture and process not only the models, but also their changes as a stream of events (operations that affect models). We generalized this approach to provide a common conceptual framework for an event-driven virtual machine (EVM) architecture.
The EVM is a rule-based system with a special focus on versatile model transformations, with built-in support for reacting to model and query result changes and user interactions. The EVM integrates various execution schemes into a uniform and flexible architecture, to provide a common framework that even allows for combinations of advanced model transformation scenarios, e.g. by the interleaving of various execution strategies (batch, live/triggered and exploratory) within a single transformation program.
1. Core architecture
The event-driven virtual machine allows the central management of executable actions defined on event sources and can execute these actions automatically with a predefined schedule.
-
An activation is wrapper of a pattern match with a corresponding rule instance and state.
-
Activation states are: inactive, appeared, fired, updated, disappeared
-
-
A rule instance manages the activations corresponding to a rule specification in a given VIATRA Query engine.
-
A rule specification defines the life cycle for changing the activation state in response to events and the possible actions that can be executed on an activation in a given state.
-
Events related to a life cycle are: match appears/disappears/updates, activation fires
-
State transitions in a life cycle always have a source state, an event and a target state. There can be only one (source state, event) pair in the life cycle, thus the target state is always deterministic.
-
Jobs are atomic actions that are performed if an activation is fired when in a state defined by the job.
-
An activation is enabled if there is at least one job that is defined for the current state of the activation.
-
-
An agenda is a collection of rule instances with an added responsibility of ordering the enabled activations of all rule instances related to the same VIATRA Query engine
-
The agenda keeps track of the activations of the rule instances by an activation notification mechanism. Rule instances notify the agenda if one of their activations changed state in response to an event.
-
-
An executor is responsible for executing enabled activations in the agenda when it is scheduled to do so, and to provide an execution context to store execution results or other data related to execution.
-
A scheduler is defined to respond to some kind of global event (e.g. transaction commit, user request, or VIATRA Query Base update callback) by scheduling its executor.
-
A rule engine is created for a given VIATRA Query engine and an optional set of rule specifications, and has its own agenda.
-
A execution schema is a special rule engine, that also has a scheduler set up.
2. Example code
We illustrate the two main usage modes of the EVM with UML models. First, we have to define the preconditions with patterns, then define the rule specifications which can be added to a rule engine or execution schema.
The example project is on the repository: UML EVM Example
2.1. Precondition pattern definition
The code example below shows the possibleSuperClass and onlyInheritedOperations patterns of that are based on the UML example, the complete query definition can be found in our repository: preconditions.vql
/* Precondition for add generalization rule */
pattern possibleSuperClass(cl : Class, sup : Class) {
neg find superClass(cl, _otherSup);
neg find superClass(_cl2, sup);
}
/* Precondition for create owned operation */
pattern onlyInheritedOperations(cl : Class) {
find hasOperation(cl, _op);
neg find ownsOperation(cl, _ownOp);
}2.2. Rule specifications
We define two rule specifications, both encapsulated by a method in UMLexampleForEVM.java.
The first rule specification uses the possibleSuperClass pattern as a precondition and when executed for a given class pair, it creates a new Generalization element to set the class sup as a superclass for cl. The life-cycle is the most simple, where neither the updated, nor the disappeared state is used.
// the job specifies what to do when an activation is fired in the given state
Job job = Jobs.newStatelessJob(CRUDActivationStateEnum.APPEARED, new PossibleSuperClassProcessor() {
@Override
public void process(Class cl, Class sup) {
System.out.println("Found cl " + cl + " without superclass");
Generalization generalization = UMLFactory.eINSTANCE.createGeneralization();
generalization.setGeneral(sup);
generalization.setSpecific(cl);
}
});
// the life-cycle determines how events affect the state of activations
DefaultActivationLifeCycle lifecycle = DefaultActivationLifeCycle.DEFAULT_NO_UPDATE_AND_DISAPPEAR;
// the factory is used to initialize the matcher for the precondition
IMatcherFactory<PossibleSuperClassMatcher> factory = PossibleSuperClassMatcher.factory();
// the rule specification is a model-independent definition that can be used to instantiate a rule
RuleSpecification spec = Rules.newSimpleMatcherRuleSpecification(factory, lifecycle, Sets.newHashSet(job));The second rule specification is similar, it uses the onlyInheritedOperations pattern and when executed it creates a new operation with name newOp and adds it to the class which had no own property before.
Job job = Jobs.newStatelessJob(CRUDActivationStateEnum.APPEARED, new OnlyInheritedOperationsProcessor() {
@Override
public void process(Class cl) {
System.out.println("Found class " + cl + " without operation");
Operation operation = UMLFactory.eINSTANCE.createOperation();
operation.setName("newOp");
operation.setClass_(cl);
}
});
DefaultActivationLifeCycle lifecycle = DefaultActivationLifeCycle.DEFAULT_NO_UPDATE_AND_DISAPPEAR;
IMatcherFactory<OnlyInheritedOperationsMatcher> factory = OnlyInheritedOperationsMatcher.factory();
RuleSpecification spec = Rules.newSimpleMatcherRuleSpecification(factory, lifecycle, Sets.newHashSet(job));2.3. Fire activations manually using a rule engine
The first option when using the EVM is creating a rule engine, which manages the set of activations, but will not fire the enabled activations. A rule engine has no context of its own, so the user can create one to use when firing activations. The rule specifications above are returned by the two getter methods, and the addRule method is used on the rule engine to instantiate the rules.
// create rule engine over query engine
RuleEngine ruleEngine = RuleEngines.createViatraQueryRuleEngine(engine);
// create context for execution
Context context = Context.create();
// prepare rule specifications
RuleSpecification createGeneralization = getCreateGeneralizationRule();
RuleSpecification createOperation = getCreateOperationRule();
// add rule specifications to engine
ruleEngine.addRule(createGeneralization);
ruleEngine.addRule(createOperation);Once a rule specification is added to the rule engine, the existing activations of a given rule can be retrieved from the rule engine and can fire them manually. Alternatively, the next activation as selected by the conflict resolver (which is a simple hash set without ordering) can be retrieved and fired.
// check rule applicability
Set<Activation> createClassesActivations = ruleEngine.getActivations(createGeneralization);
if (!createClassesActivations.isEmpty()) {
// fire activation of a given rule
createClassesActivations.iterator().next().fire(context);
}
// check for any applicable rules
while (!ruleEngine.getConflictingActivations().isEmpty()) {
// fire next activation as long as possible
ruleEngine.getNextActivation().fire(context);
}As long as the rule engine exists, it will keep on managing the activations of added rules. It is possible to remove a single rule, which will remove all its activations from the rule engine, and the rule engine can be disposed when not needed anymore.
// rules that are no longer needed can be removed
ruleEngine.removeRule(createGeneralization);
// rule engine manages the activations of the added rules until disposed
ruleEngine.dispose();2.4. Fire activations automatically with an execution schema
The second option for using the EVM is to create an execution schema that has a scheduler to fire activations after predefined events and an executor that specifies how to fire activations when scheduled. In the example, we use the feature in VIATRA Query Base that allows us to register a callback on model changes. An execution schema is created using a VIATRA Query engine and a scheduler factory, then the rules are added, in the same way as for the rule engine.
// use IQBase update callback for scheduling execution
UpdateCompleteBasedSchedulerFactory schedulerFactory = Schedulers.getIQEngineSchedulerFactory(engine);
// create execution schema over ViatraQueryEngine
ExecutionSchema executionSchema = ExecutionSchemas.createViatraQueryExecutionSchema(engine, schedulerFactory);
// prepare rule specifications
RuleSpecification createGeneralization = getCreateGeneralizationRule();
RuleSpecification createOperation = getCreateOperationRule();
// add rule specifications to engine
executionSchema.addRule(createGeneralization);
executionSchema.addRule(createOperation);In the example we simply modify the model by removing a generalization from a random class. When the model modification is handled by VIATRA Query, the callback notifies the scheduler, which starts the executor, which in turn will fire enabled activations as-long-as-possible. The scheduler in the example uses the model update listener of the engine (see bug 398744) to get callbacks on changes.
// execution schema waits for a scheduling to fire activations
// we trigger this by removing one generalization at random
SuperClassMatcher.factory().getMatcher(engine).forOneArbitraryMatch(new SuperClassProcessor() {
@Override
public void process(Class sub, Class sup) {
sub.getGeneralizations().remove(0);
}
});Similarly to the rule engine, it is possible to remove a rule from the execution schema or to dispose it when not needed any longer. The main difference between the rule engine and the execution schema is, that once a rule has been added, the activations that are enabled will be executed automatically every time the scheduler is notified. This allows us to implement components that can react to changes incrementally, without requiring additional scaffolding.
// rules that are no longer needed can be removed
executionSchema.removeRule(createGeneralization);
// execution schema manages and fires the activations of the added
// rules until disposed
executionSchema.dispose();2.5. Impose ordering between activations of different rules
Activations that are enabled are in conflict with each other since firing any of them can cause the other activations to become disabled. The conflict set of a rule engine is the set of enabled activations of all rules, and users can define a conflict resolver that provides an ordering in the conflict set (bug 403825).
2.6. Enabling log messages in EVM
Due to the event-driven nature of EVM, it is often difficult to debug your program, since the control flow will go through EVM internals and activation life-cycle is handled independently of activation firing. In order to see exactly what happens inside EVM, you can set the log level of the Log4J logger of rule engines to display DEBUG or even TRACE level messages. The log will include events, activation state changes, scheduling and executor events, firing and other useful information.
// just set the log level of the engine as needed
ruleEngine.getLogger().setLevel(Level.DEBUG);3. Observing EVM Execution with Adapters
To ease the development of reactive transformations over EVM, it is beneficial have support for debuggers, profilers and similar tools. These all require to allow observing the execution of the transformation and/or provide indirect control over transformations. The Adapter Framework for EVM provides a generic, easy-to-use technique for creating user defined adapter and listener implementations.
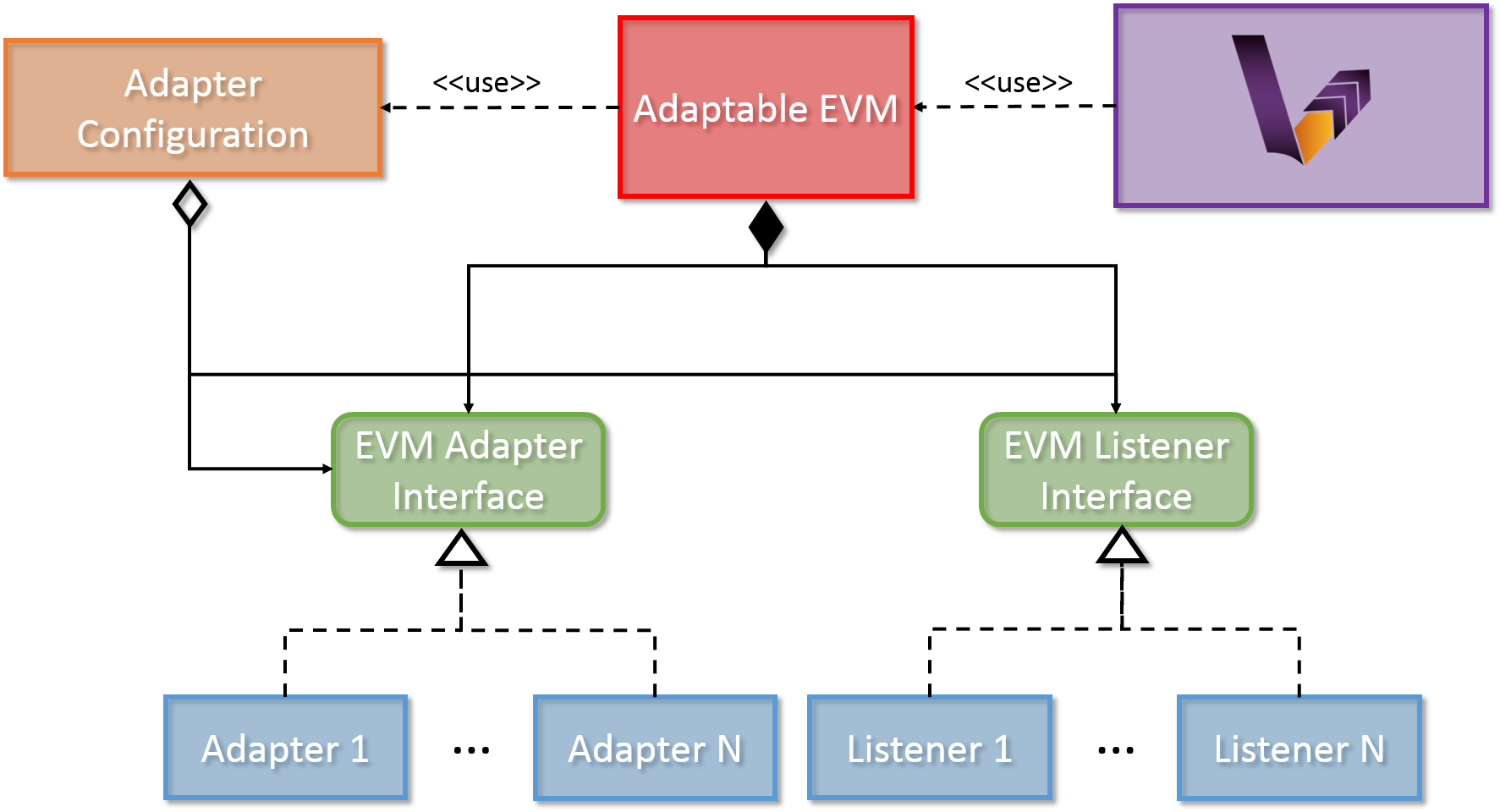
Figure 1. High level architecture
The most important concepts of the Adapter Framework are as follows:
- Adapter Interface
-
The Adapter Interface defines a set of callback methods that are executed at certain points during the transformation execution. These actions are capable of altering the execution sequence of transformation rules. A number of Adapters can implement this interface, in order to define additional functionality that should be undertaken at certain points in the transformation.
- Listener Interface
-
The Listener Interface defines a set of callback methods that are executed at certain points during the transformation execution. The actions defined in these methods can have no effect on the transformation itself, purely aim at providing a solution to listening to certain transformation-related events. A number of Adapters can implement this interface, in order to define additional functionality that should be undertaken at certain points in the transformation.
- Adaptable EVM
-
The Adaptable EVM is responsible aggregating the used Adapter and Listener instances and delegates the callback method calls from the internal VIATRA objects towards the appropriate callback method of each adapter or listener at certain points during execution. The Adaptable EVM is also responsible for setting up VIATRA transformation to utilize adapters.
- Adapter Configuration
-
The adapter configurations serve multiple purposes. They can either define dependency relations between adapter imple-mentations, or specify complex use cases which requires more than one adapter to func-tion properly
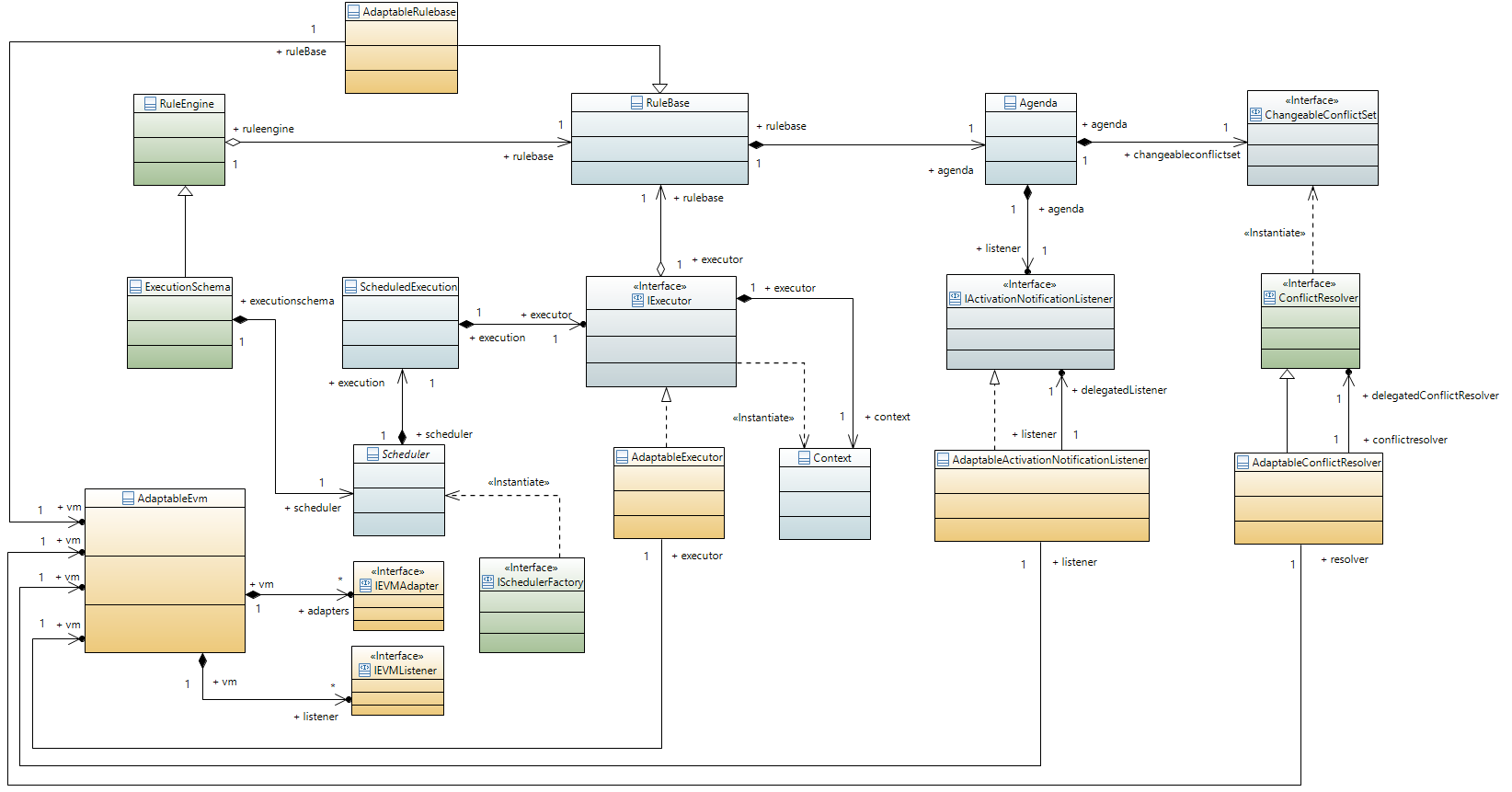
3.1. Connection with EVM
The class diagram below depicts the relations between the internal EVM elements and members of the EVM adapter framework. The classes with color green are API classes through which the user can define EVM based programs; blue marks internal EVM classes and interfaces while yellow marks the adaptable classes.
-
AdaptableEVM:
-
Aggregates listeners and adapters
-
Assembles an adapter supporting EVM instance
-
ExecutionSchema
-
RuleEngine
-
-
-
IEVMAdapter: Callback methods for manipulation the set of EVM Activations to be executed
-
Wraps a handed Iterator with one defined by the adapter implementation → manipulate the Activations handed to the executor.
-
Wraps a handed ChangeableConflictSet with one defined by the adapter implementation → Activations returned by the conflict set can be manipulated.
-
-
IEVMListener: Defines a set of callback methods that can be used to listen to certain EVM-based events, and react to them accordingly. However these callback methods cannot manipulate the EVM rule execution sequence in any way. Callback methods can be defined for the following events: (for details check Javadoc)
-
Initialization/disposal
-
Before/after activation firing
-
Before/after transaction
-
Activation state change
-
Activation removed
-
Activation created
-
EVM rule added/removed
-
-
AdaptableRulebase: The Adaptable RuleBase extends the EVM Rulebase. It has a reference to an AdaptableEVM object, through this it can notify adapters about the addition and removal of EVM rule Specifications.
-
AdaptableExecutor: The Adaptable Executor as the same responsibilities as the EVM Executor, however, it can also notify EVM listeners about the starting/ending transactions and activations firings. It also enables adapters to alter the set of Activations the executor is assigned to fire.
-
AdaptableActivationNotificationListener: Delegates a default EVM activation notification listener. apart from calling the respective methods of the delegated activation change listener, it also notifies EVM listeners about activation state changes.
-
AdaptableConflictResolver: The adaptable conflict resolver allows EVM adapters to override or alter the conflict set created by a delegated conflict resolver instance, in order to modify the execution sequence of an EVM-based program.
| Not all EVM instances are adaptable because the notification handling may have an effect on performance. However, there are APIs available that create adaptable EVM instances when an adapter or listener is added, otherwise rely on the default, non-adaptable version. |
3.2. Defining adapter and listener implementations
3.2.1. EVM Listener implementation example
EVM listener implementations should implement the IEVMListener interface, or extend the AbstractTransformationListener abstract class. Usage of the abstract class is recommended, as it enables the developer to only subscribe to a certain set of EVM events without implementing every method if the IEVMAdapter interface. The following source code example shows a simple logging listener implementation.
public class FiringLoggingEVMListener extends AbstractTransformationListener{
private final Logger logger;
public FiringLoggingEVMListener(Logger logger) {
this.logger = logger;
}
@Override
public void beforeFiring(Activation<?> activation) {
logger.debug("BEFORE FIRING " + activation.toString());
}
@Override
public void afterFiring(Activation<?> activation) {
logger.debug("AFTER FIRING " + activation.toString());
}
}3.2.2. EVM Adapter implementation example
Similar to the listeners, EVM adapters can either implement the IEVMAdapter interface or the AbstractTransformationAdapter abstract class. The following example shows a simple adapter that is capable of changing the set of adapters executed during the EVM program execution. Note that the actual activation selection is not implemented, the example only focuses on showing a viable skeleton implementation for changing EVM execution sequences.
public class ExecutorIteratorManipulatorAdapter extends AbstractTransformationAdapter{
@Override
public Iterator<Activation<?>> getExecutableActivations(Iterator<Activation<?>> iterator) {
if(iterator instanceof ConflictSetIterator){
return iterator;
}else{
return new ExecutorIteratorManipulatorIterator(iterator);
}
}
public class ExecutorIteratorManipulatorIterator implements Iterator<Activation<?>>{
private final Set<Activation<?>> activations = Sets.newHashSet();
public ExecutorIteratorManipulatorIterator(Iterator<Activation<?>> delegatedIterator){
while(delegatedIterator.hasNext()){
activations.add(delegatedIterator.next());
}
}
@Override
public boolean hasNext() {
return !activations.isEmpty();
}
@Override
public Activation<?> next() {
return getActivation(activations);
}
@Override
public void remove() {
throw new UnsupportedOperationException("Deletion from this iterator is not supported.");
}
}
private Activation<?> getActivation(Set<Activation<?>> activations){
//Get the next activation to be fired
}
}3.3. Assembling an Adaptable EVM infrastructure
As mentioned before, the assembly of the adaptable EVM infrastructure is handled by the AdaptableEVM class. However this class is only capable of crating an infrastructure that contains all of the above mentioned adaptable entities. The assembly however is relatively simple and can be done manually as well. the following examples present the assembly sequence via showing code fragments from the AdaptableEVM class (this refers to the AdaptableEVM instance).
Assembling an Adaptable RuleBase
public RuleEngine createAdaptableRuleEngine(ViatraQueryEngine queryEngine) {
//Create an adaptable conflict resolver that wraps a default arbitrary conflict resolver
//If an adaptable conflict resolver is not needed, create the arbitrary conflict resolver
AdaptableConflictResolver conflictResolver = new AdaptableConflictResolver(new ArbitraryOrderConflictResolver(),
this);
//Create an agenda based on the created conflict resolver regardless of adaptability
Agenda debugAgenda = new Agenda(conflictResolver);
//Set the used activation state change listener. At this point either an adaptable listener, or a default listener can be handed to the Agenda.
//Note, that the adaptable listener wraps the default one
debugAgenda.setActivationListener(
new AdaptableActivationNotificationListener(debugAgenda.getActivationListener(), this));
//Create an adaptable rule based based on the created adaptable or default EVM components.
//If listening to rule additions is not needed the adaptable RuleBase can be replaced with an EVM default one.
RuleBase debugRulebase = new AdaptableRuleBase(ViatraQueryEventRealm.create(queryEngine), debugAgenda, this);
//Create the RuleEngine based on the rule base.
return RuleEngine.create(debugRulebase);
}
</source>| if you are planning to use an adaptable rule base and want to access the full adapter functionality, use an Adaptable Executor to fire activations. See the VIATRA BatchTransformation (source) and BatchTransformationStatements (source) classes. |
Assembling an Adaptable ExecutionSchema
public ExecutionSchema createAdaptableExecutionSchema(ViatraQueryEngine queryEngine,
ISchedulerFactory schedulerFactory, ConflictResolver conflictResolver) {
//Create an adaptable executor that wraps a default EVM executor
//If an adaptable Executor is not needed, create the default EVM one.
IExecutor executor = new AdaptableExecutor(new Executor(), this);
//Create an adaptable conflict resolver that wraps a default arbitrary conflict resolver
//If an adaptable conflict resolver is not needed, create the arbitrary conflict resolver
ConflictResolver adaptableConflictResolver = new AdaptableConflictResolver(conflictResolver, this);
//Create an agenda based on the created conflict resolver regardless of adaptability
Agenda debugAgenda = new Agenda(adaptableConflictResolver);
//Set the used activation state change listener. At this point either an adaptable listener, or a default listener can be handed to the Agenda.
//Note, that the adaptable listener wraps the default one
debugAgenda.setActivationListener(
new AdaptableActivationNotificationListener(debugAgenda.getActivationListener(), this));
//Create an adaptable rule based based on the created adaptable or default EVM components.
//If listening to rule additions is not needed the adaptable RuleBase can be replaced with an EVM default one.
RuleBase debugRulebase = new AdaptableRuleBase(ViatraQueryEventRealm.create(queryEngine), debugAgenda, this);
//Create a scheduled execution instance based on the executor and rule base objects. (regardless of adaptability)
//The scheduled execution is responsible for handling scheduling reentry.
ScheduledExecution execution = new ScheduledExecution(debugRulebase, executor);
//Create a scheduler instance based on the scheduled execution object. (regardless of adaptability)
Scheduler scheduler = schedulerFactory.prepareScheduler(execution);
//Create execution schema
final ExecutionSchema schema = ExecutionSchema.create(scheduler);
//Ser the conflcit resolve of the schema
schema.setConflictResolver(adaptableConflictResolver);
return schema;
}4. Usage scenarios
Both the data binding and validation frameworks of VIATRA use the EVM for handling events.
-
Data binding: observable match result collections are created in the createRuleSpecification method of ObservableCollectionHelper (org.eclipse.viatra.databinding.runtime.collection package)
-
Validation constraints are created in the constructor of ConstraintAdapter (org.eclipse.viatra.validation.runtime package)
4.1. Programming against the EVM API
The basic usage of the EVM is to react to match set changes easily.
4.1.1. Efficiently reacting to pattern match set changes
If you want to efficiently react to appearing, changing or disappearing matches, the EVM is a perfect choice. Just define a rule specification with the correct life-cycle and jobs and create an execution schema as described above.
-
If you only want to react to appearance events: use
DefaultActivationLifeCycle.DEFAULT_NO_UPDATE_AND_DISAPPEARand a single APPEARED job. -
If you want to react to both appearance and disappearance: use
DefaultActivationLifeCycle.DEFAULT_NO_UPDATEand two jobs, one with APPEARED and the other with DISAPPEARED state. -
If you want to react to changes of match parameters (e.g. an attribute value changes, but the match still exists): use
DefaultActivationLifeCycle.DEFAULTand add an additional job with UPDATED state.
4.2. Roll your own event provider for EVM
The EVM core is independent of EMF and VIATRA Query, see https://bugs.eclipse.org/bugs/show_bug.cgi?id=406558 You can create your own event realm and use the EVM core concepts to execute event-driven rules. You can see a small example in https://git.eclipse.org/c/viatra/org.eclipse.viatra.examples.git/tree/query/evm-proto
5. Design decisions and code style
These guidelines are derived from the main decision to create a defensive framework to minimize the internal argument checks and other defensive programming measures required.
5.1. User interaction with the framework
-
Users interact with rules and activations through Façade classes:
-
RuleEngine façade provides access to an Agenda and it’s rule instances
-
ExecutionSchema façade provides access to a Scheduler and through that to the Executor
-
These Façade classes can be retrieved through the static methods of EventDrivenVM or by static create methods (for specific implementations)
-
-
Any object that a user can access through the Façade must have only public methods that do not endanger their engine (e.g. Activation.fire(), but not Activation.setState())
-
Any collection that a user can access through the Façade must be immutable to avoid modifications (e.g. getActivations)
-
Any object that is provided by the user must be copied if it’s later modification can cause internal problems (e.g. life cycle for rules)
5.2. Parameters, input checking and logging
-
Method parameters cannot be null!
-
This is checked by Preconditions.checkNotNull(ref, msg). Return a meaningful message on null.
-
Use the
this.field = checkNotNull(field, msg)form in constructors when possible. -
Define delegate methods where optional parameters are allowed.
-
-
All logging is done through the rule base, use the debug level for detailed report messages and error or warning when encountering a real problem (e.g. ViatraQueryException)
5.3. Default implementations
There are a high number of notification mechanisms and event processing, that must have an interface for extendibility, a good default implementation and a clear way of overriding.
-
In RuleInstance notification providers and listeners are created in prepareX methods.
-
Default life cycles prepared with unmodifiable static instances.
-
Update complete provider implementations (IQBase and EMF transaction).
-
Scheduler implementations (update complete and timed).
-
Job implementations (stateless with a single match processor, and recording for transactional model modification).
-
Job implementations can specify their own error handling (https://bugs.eclipse.org/bugs/show_bug.cgi?id=404307)
-
6. Usage Example
This section will sketch out how EVM can be used to describe transformation steps over an EMF model. At first, a VIATRA Query Engine is to be initialized over an EMFScope. This EMFScope contains the resource set in which the source and the target of the transformation can be found. The main part of the demo is in the execute method. As domain of this transformation,
6.1. Transformation rules
We have two main rule: the hostMapping and appMapping.
The hostMapping has three job (one for all states of the life cycle):
-
The pattern: This rule is based on the hostInstances pattern. This pattern finds all host instances.
-
ActivationState.CREATED: This job create deployment hosts for host instances. The ip of the deployment host is set here.
-
ActivationState.DELETED: This removes deployment pairs of disappeared host instances.
-
ActivationState.UPDATED: This will be invoked when the hostInstances pattern updated (so when a host type or host instance is modified). The description of the deployment host is set to
modified.
-
The appMapping has only two job:
-
The pattern: This rule is based on the applicationsInstances pattern. This finds application instances which is allocated to host instance which has a pair in the deployment.
-
ActivationState.CREATED: Creates the deployment application (sets the id).
-
ActivationState.DELETED: Removes the deployment application.
-
6.2. Resolver
There is an InvertedDisappearancePriorityConflictResolver which can be used to order activations.
6.3. Execution versions
6.3.1. Execution Schema
This is the simple way of the execution. For this you need to set the simple field to true (at the top of the class).
A scheduler factory is created for the ViatraQueryEngine and an execution schema is created based on this factory and the ViatraQueryEngine. After these steps the conflict resolver is set and rules are added to the schema. The execution is triggered by the startUnscheduledExecution method.
Code:
// Create schema
val schedulerFactory = Schedulers.getQueryEngineSchedulerFactory(engine)
val schema = ExecutionSchemas.createViatraQueryExecutionSchema(engine, schedulerFactory)
// Setup conflict resolver
schema.conflictResolver = resolver
// Add rules to the schema
schema.addRule(hostMapping)
schema.addRule(appMapping)
schema.startUnscheduledExecution6.3.2. Advanced executions
Here are the versions of manual executions of activations. For these the value of the simple field should be false.
6.3.2.1. Common parts
For all advanced version of execution need a rule engine (based on the ViatraQueryEngine), a context, and the setup of these elements (conflict resolver and addition of rules for the rule engine).
Code:
// Create rule engine over ViatraQueryEngine
val ruleEngine = RuleEngines.createViatraQueryRuleEngine(engine)
// Create context for execution
val context = Context.create()
// Conflict resolver also can be used here
ruleEngine.conflictResolver = resolver
// Add rule specifications to engine
ruleEngine.addRule(hostMapping)
ruleEngine.addRule(appMapping)6.3.2.2. Fire one activation of a specific rule
Activations of a rule can be queried from the rule engine. This is a set which can be iterated and the activation can be fired (with the context) so we can fire the first one.
Code:
// Check rule applicability
val createClassesActivations = ruleEngine.getActivations(hostMapping)
if (!createClassesActivations.empty) {
// Fire activation of a given rule
createClassesActivations.iterator.next.fire(context)
}6.3.2.3. Fire all activations
Next activation from the rule engine is fired while the set of conflicting activations is not empty so we can fire all activations. After firing all activations rules are removed from the rule engine.
Code:
// Check for any applicable rules
while (!ruleEngine.conflictingActivations.empty) {
// Fire next activation as long as possible
ruleEngine.nextActivation?.fire(context)
}
// Remove rules after execution
ruleEngine.removeRule(appMapping)
ruleEngine.removeRule(hostMapping)6.3.2.4. Filter activations
First of all a custom event filter is created. This filter works over HostInctanceMatch objects and filter out match which contains host instance with the specified nodeIp. The rule should be added to the rule engine with the filter (if we want that the unfiltered rule does not cause a problem it should be removed) and after this we can iterate over the activations just like in the previous version (but only one deployment host will be created if the original rule has been removed).
Code:
// Create custom filter for IP
var eventFilter = new EventFilter<HostInstancesMatch>() {
override isProcessable(HostInstancesMatch eventAtom) {
eventAtom.hostInstance.nodeIp == FILTERED_IP
}
}
// Replace the simple rule with the rule->filter pair in the engine
ruleEngine.removeRule(hostMapping)
ruleEngine.addRule(hostMapping, eventFilter)
// Fire all activations
while (!ruleEngine.conflictingActivations.empty) {
// Fire next activation as long as possible
val nextActivation = ruleEngine.nextActivation
nextActivation?.fire(context)
}6.3.2.5. Manage conflict set manually
At this version a different filter is created: a ViatraQueryMatchEventFilter which works with a specific match. This match is created for a host instance. We need to add the hostMapping-filter pair to the rule engine. The removal of the original rule is not necessary.
Code for filter:
// Create query match filter with a partial match object
val matchFilter = ViatraQueryMatchEventFilter.createFilter(
HostInstancesMatch.newMatch(
engine.hostInstancesByIp.getOneArbitraryMatch(null, FILTERED_IP).hostInstance
)
)
// Add the rule->filter pair to the engine
ruleEngine.addRule(hostMapping, matchFilter)The main part of this section is the next: a scoped conflict set is created from the rule engine. It expects a resolver and a multi map of rules and filters. Because of this last point the original rule does not need to be removed from the rule engine. Important that the simple rule addition uses empty filter (and not a null value) when registers the rule so at the map empty filter should be used for these rules. The nextActivation method of this conflict set gives the next activation which can be fired (if no activation can be fired the return value will be null so a null check is necessary before the fire).
Code for conflict set:
// Check that there is any conflicting activation
if(!ruleEngine.conflictingActivations.empty) {
// Create the conflict set
val conflictSet = ruleEngine.createScopedConflictSet(resolver,
// From filtered hostMapping rule and unfiltered appMapping
ImmutableMultimap.of(
hostMapping, matchFilter,
appMapping, appMapping.createEmptyFilter
)
)
// Iterate over activations of the conflict set
var nextActivation = conflictSet.nextActivation
while(nextActivation != null) {
nextActivation.fire(context)
nextActivation = conflictSet.nextActivation
}
}