Eclipse Webtools Architecture Overview
The background and status of this document.
Version 0.1 August 16, 2004.
While this document is a work product of the WTP Architecture Group I will have to take
full responsibility for all the many errors and omissions it contains,
but will give credit both to the Architecture Group and the many other
teams for their many valuable contributions to it and the time they spend
educating me.
This first version of this document is being distributed now,
even though still rough and incomplete (I'd guess about 50% incomplete), to get some community
readership to determine if it represents a useful direction and if it
should be continued. Feedback, questions, and comments can be made to
the wtp-dev mailing list.
Thank you for your contributions, David Williams (david_williams@us.ibm.com)
|
Purpose and Objectives
Given a heterogeneous group of people, companies, and contributions, it
would be difficult for WTP to be easily "open" to a community without some
overview of its architecture. The
purpose of this document is to give a high-level view of the
architecture that is implicit in most of the initial contributions. Over time, this document will capture the architecture of the Eclipse Web Tooling Platform. This document is not the Architectural Plan, as required by the Eclipse
Development Process listed on the Eclipse Governance page. That Plan will be written later, but, hopefully, as an outgrowth of this docuent.
This
Overview documents the current and desired architecture of WTP
as a whole -- that is, contributed components will (still) be expected to
document their own architecture, designs, APIs, and how they fit in to
overall architecture -- and, since it is a comunity based project, the level and timing of that documentation will vary greatly.
The benefit of having an overall document is that it can capture things
that are not captured by individual pieces: both across component relationships and
also things which might seem unique when individual pieces are examined,
but which are really common when the system is viewed as a whole.
The
primary reason for doing this work is to make it easier for others to
contribute to WTP and to integrate with it. That is, it is to serve as
something of a road map, guiding contributors and integrators on the
most scenic areas of interest. It is definitely not intended to be a "how to" manual -- it won't give all the answers to specific questions (and actully in most cases not any of the answers to specific questions) -- but hopefully will make it easier to find where to look for the answers. Also, it is definitely not intended to be a
return to centralized development practices, but simply to help guide
decentralized development. To stretch a commonly used open source
metaphor, the architecture document is to be more of architecture of a
bazaar, rather than the architecture of a cathedral (and, to be
explicit, the best bazaars do have some organization -- they are not
just random anarchy!).
A second reason for doing this work is to help keep track of holes or errors in
current architecture -- or, stated another way, find things that are not
architected, but merely implemented.
This architecture document may summarize the
extensible and pluggable areas where components can be easily changed or
extended. But that's primarily documented component by component.
It
is hoped this document will also be useful as planning and requirements
input, for example, if there are missing or redundant pieces, it would
be easier to plan what to do about that, given some overall
documentation, rather than trying to decide each individual case in
isolation. Eventually, in the long run, hopefully it'll evolve to work in the opposite direction too, input from requirements and plannning can be used to modify this document and the architecture itself.
This architecture document is expected to be a "living" document,
updated at least every milestone both to remain "current" and to be
improved with feedback from the community. It is also anticipated that
people contributing to this document will be code-contributing members.... that
is, its no ivory tower where work goes on in isolation!
Web Standard Tools vs. J2EE Standard Tools
Overall the project is "split" into Web Standard Tools (WST) and J2EE Standard Tools (JST), as is well described by the links from the description of the project Eclipse Web Tools
Platform Project .
Architecturally, the J2EE components depend on the Web Standard components, but not vice versa. (That is, I should say this will be case, there's still some case of refactoring needed to have "perfect" separation).
Architecturally significant use cases
High level uses case are document here to give a high level idea of the what this overview is meant to cover.
[4 to 6 more high level use cases to be added later.]
- Create a web application, including deployment descriptors, HTML, JSP, and
Java files, and run them from the WTP-IDE on a local or remote test
server.
Architectural Viewpoints
The architecture is described from several points of view. Each
point of view highlights particular aspects of the system, and different
readers may be interested in one view over others. Overall, though, this document focuses on documenting the "model-driven" architecture, meaning that the system is described in terms of the model objects, their properties, and how they interact with each other. For example, its not intended to document an editor for a web resource, but that fact that it can be modified by changing specific models is the architecturally important part.
Static Development system Viewpoint
This is the system as its "actively idle" ... that is, a
developer in using it to create a web application, using editors,
wizards, properties, etc. to create artifacts, but does not include
actually running, debugging, deploying, or publishing anything.
Run/Debug Development viewpoint
This view point highlights those areas of the system that come into
play while running or debugging on a test server, to test that the
application works correctly.
Components view point
This view point shows the systems as "logical collections",
typically "owned" by one team, typically in same geographical area.
In addition to the logical grouping, the Components view point will
mention significant supporting classes or pre-reqs which might not be
obvious from the other view points.
Static Development system
Server/Runtime target
The server/runtime target defines the properties and runtime class
library of a particular server. These properties and runtime class
library is used by the web project to know what's appropriate for that
web project, given certain servers.
This figure of a simplified view of the server target shows how its definition comes from an Eclipse Extension, but that a particular defined instance of a server would have extra info associated (and saved) with it, such as where the runtime jars are located on the local file system. The runtime jars are needed for "static development", but of course the "real" runtime jars are used when the server is ran.

WebProject and Webnature
The WebProject and WebNature describes how and where various deployment artifacts (resources such as web.xml files, etc.) are stored, and other information that's important at "development time" such as the intended target server.
Its important to note that the actual deployment descriptor for a web
app, namely web.xml, is, in our system, conceptually just a serialized
form of the web app model. This is a frequent pattern though out the framework. And, of course, the web.xml file is still standard, can still be deployed as usual, etc. Of course, there is occasions when there is extra information we'd like to keep track of due to being in an IDE enviroinment that is not really part of the standard deployment descriptor, so that is written to some meta data file associated with the project. These relationships are shown in the following figure.
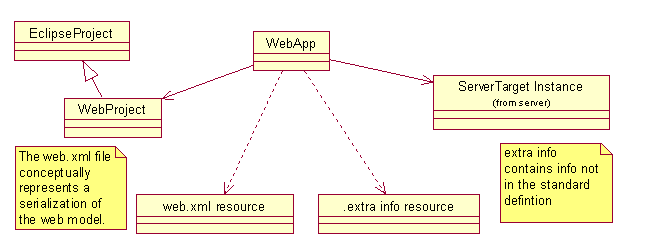
Web resources (html, jsp, xml files, etc).
The main model object used to manipulate web resources are a
StructuredModel and a StructuedDocument. XML, JSP, and HTML all have a
special DOM Model associated with them. DTD and CSS have similar
DOM-like models associated with them, but technically don't meet the DOM
spec. (DTD is very close, CSS is more like a list of nodes, rather can a
hierachey of nodes). The StructuredDocument is very similar to the
IDocument interface, and just adds some specialized events to make
incremental updates possible. The following figure shows these relationships as they might be while editing a web.xml resource.
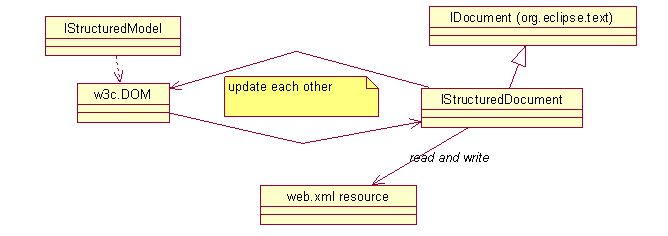
I hope the careful reader is wondering what happens if the web app model and the DOM Model both want to update the web.xml text. There's certainly the usual "resource changed" listeners that are common in Eclipse to help things keep in synch, but sometimes changes are desired from one source or the other without actually saving the resource. This leads to another typcial pattern used in our systems, that of model-to-model adapters, as shown in the following figure. 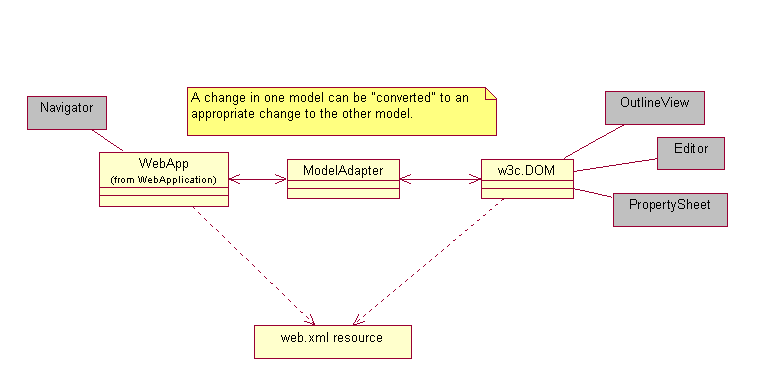
Database Model
[more to be provided later]
Models for databases, connections, tables, etc.
Database Queries
[more to be provided later]
SQL Model based on SQL-99 Standard. Uses/depends on EMF.
WebServices
[more to be provided later]
Run/Debug Development viewpoint
[Obviously ... this section is very incomplete .... more to come ... if deemed important, and if there's time, which I only say since it could be one of the more complicated to document usefully]
Server (proxy)
This server object differs some from the server/runtime target, in
that it actually controls the "running" on the server. In the
standard (contributed) case, this server depends on a
"standard" Eclipse project layout. (A future work item is to
allow more flexible project structures.)
TCPIP Monitor
Its probably worth noting that the TCPIP monitor actually setups a
"proxy" server, to monitor traffic to and from the test server
(it can not monitor traffic from any arbitrary server)..
Components view point
[Editors note: it is in this seciton I'd like to (in the long run) have links to the specfic components design and API documentation.]
Defintion of terms [open to debate]: I've tried to use Subsystem which seems the term the Eclipse
Development Process uses to denote a large, logically related set of components, which are fairly ndependent of other subsystems, at least conceptually. I've used the term Component to mean that part of as subsystem that conceptually has meaning by itself, and which would be recognized or seen by an end-user as "part of the system" and identifiable with some standard or specification. Sub-component is similar, but maybe highly related to other components (due to re-use) but which is typically transparent to the end-user.
Subsystem: Server-tools
WST Component: Server Framework
This framework handles definition of any (or, at least many) servers
and server types, but the actual server support is provided in
subcomponents.
WST Component HTTP standard server tools
WST Component - Internet (Built in Browser, tcpip montior,
Proxy preferenes)
JST Component tomcat standard server tools
Subsystem: Web Resources
This framework is used for deployment descriptors (XML source) [Note:
no special deployment editors are in current contribution, so they are
just treated as xml files. And, of course, true web resources (XML,
HTML, XHTML, CSS, JavaScript).
WST Component Structured Source Editors framework
The primary purpose of extended the base text editing support is to
provide specialized models and events which can lead to better
performance, and easier interaction between other models. In particular,
its thought the most used model in this framework will be the DOM model,
which implements DOM Level 2 APIs but is a "custom"
implementation, which can 1. handle ill formed markup (as it always is
during editing) 2. can be done incrementally (as opposed to
"batch" processing, as most DOM parsers do), and 3. provides a
few "extra" APIs that make the DOM more suitable for use in
tools. Note: the JavaScript editor does not make use of "Structured
Source Editor" models and there is no "JavaScript" model
to interact with ... that interaction is all done at a document level.
JST Component JSPs (editing, menus, wizards, indexing, refactoroing, etc.)
In our framework, JSP's are treated as a "marked up"
document. Technically this is not required by the JSP Specification, but
in practice seems to be the common (maybe only!) case. This allows
interaction with the DOM model of the JSP to modify it, search it, etc.
WTP Component HTML (editing, menus, wizards, indexing,
refactoroing, etc.)
WTP Component CSS (editing, menus, wizards, indexing,
refactoroing, etc.)
WTP Component JavaScript (editing, menus)
WST Subcomponent XML base tools (URI Resolvers, ContentModels, XML and Schema Validation)
Many functions relay on some "low level"
models, which are important enough to call out for special attention.
URI Resolvers are critical in correctly "finding" related
resources in a web project, and "content models" are used to
define the "legal content" of XML, Schema, TLDs, HTML, and JSPs.
These content models also have behavior and extension points to allow "extra data" to be
associated, such as the information used in "hover help".
Includes URI Resolvers, ContentModel Interface (and implementation for
for DTDs and Schemas). This project subcomonent also provides project-based validation of XML files. -- One item for the future is that this component may relay on Xerces, so make use of its XMI interace, to provided better information in validation errors and warnings. The Xerces dependancy is currently intentionally an "internal" dependancy, not shared amount the project. This subcompent has dependancy on EMF.
SubSystem: Web Applications and Projects
WST Subcomponent Common Archive Framework
Handles loading/storing archives using pluggable strategies
WST Subcomponent Project Support
Import/Export/Creation Support
WST Subcomponent Common Navigator
Extensible framework that provides content to resources in workbench
SubSystem: J2EE Applications and Projects
JST Subcomponent J2EE Resources
EMF based models
Also depends on JEM package.
Provides specialized J2EE EMF Resource handling
SubSystem: Database
Component: Data Tools
Component: SQL'99 Tools and models
SubSystem: Webservices
WTP Component WSI
WTP Component WSDL
WTP Component WS Models (soap, uddi, wsil)
SubSystem: XML and Schemas
WTP Component: XML Validation
WTP Component: XML/Schema Generation
Provides "extras" to standard source edinting, the ability to generate and xml instance file from a DTD or Schema is one of the coolist.
SubSystem: Web Tooling Common Base
These are tools and frameworks required by multiple higher level
components, which must be at low level in the stack of components to
be shared, or, with careful review, common utilities.
WTP Component - Validation Framework
Special Eclipse builder, that allows validation of resources.
Typically, higher level components provide extensions to this framework
to handle validating their particular models and resources, such as XML,
EJBs, etc.
Pointers to prerequiste projects
In addition to the base Eclipse, the following projects/packages are prerequistes of the Webtooling Platform.
EMF
EMF, Eclipse Modeling Framework, is a way to define meta models, and then instantiate specific instances of those models. Its particularly famous for being useful to maintain models across multiple products, espcially when the model may change from one release to another (the way that deployment descriptors and J2EE specs change from verison to version.
GEF
GEF, Graphical Editing
Framework, is a framework "on top" of SWT that makes it easier to develop sophistocated, highly customizable user interfaces that go beyond typical widgets (I believe we only use this in our snippets view, subuilder, and schema editor -- though there's been some discussions of using it with XML editor in the future). .
JEM Package
The JEM package, Java EMF Model, is actually part of the VE Project. The VE team has recently made it available as seperate download from their VE
build pages. In addition to allowing easier interaction with other EMF models, it also incorporates BeanInfo into its models (not just reflection). We use it in connection to our J2EE EMF-based models. From what I hear, there's no ISV documentation for this package, but the rose models that are used to create the meta model can be found in CVS on dev.eclipse.org
/home/tools
under
/org.eclipse.jem/rose
To load into rose (from workspace) you'd also have to have org.eclipse.emf.ecore in workspace, and define, in Rose, an EditPathMap of WorkspaceRoot as what ever your workspace root is on your filesystem (then it can find included files/models automatically).
XSD
The XSD, XML Schema Infoset
Model, Project provides a model and API for querying detailed information about schemas and manipulating them.
Others
[Eventually, we may document here certain packages we use and ship internally, such as Xerces, just to help avoid duplicating such internal packages.]
Known Architectural/Design Issues
This section is just to be explicit about architectural issues
that are known and which the architecture committee will be discussing various solutions to.
Note always a clear seperation between "model" and "view" objects ... yes, we confess, occasionally, given some bit of a codes history or deadline driven design, our model/view seperation is less than perfect (but don't get me wrong, its pretty good!).
Multiple java models (JDT and JEM).
Maybe not a real issue per se,
but not sure weve documented differences between them, when to use one
vs. the other, etc.)
Multiple operation/command frameworks are in
initial contribution need to resolve to one and/or coordinate with
base Eclipse plans.
Currently "meta data" or "extra information" is stored inconsistently
(and hard to find/understand). Sometimes in (several) files with no names,
sometimes as OSGI preferences, but theres no framework for common,
easy access.
There are currently two (or more!) frameworks for providing URI resolution. Some work is needed to determine if the Extensible URI Resolution framework can be used to replace all of them.
- WTP Architecture Group
- David Williams, IBM
- Chuck Bridgham, IBM
- Erich Gamma, IBM
- Henrik Lindberg, Frameworx
- Naci Dai, Eteration