7. Type Index
7.1. Design Rationale
We use a separate types model to represent types, see Type Model and Grammar. Declared elements (e.g., classes)
in N4JS are parsed and a new types model instance is derived from them. All type references (of the N4JS AST)
are then bound to these type instances and not to the N4JS declaration. However, there exists a relation between a type
and its declaration. The type instances (which are EObjects) are added to the resource of the N4JS file as part of
the public interface of the resource. This public interface is represented by a TModule. While the actual source code
is the first element of a resource (index 0), the module is stored at index 1. It contains the derived type information,
the information about exported variables and functions as well as information about the project and vendor. The Xtext
serializer ignores the additional element. Besides, the complete type instances are stored in the user data section of
the IEObjectDescription of the TModule. Since the user data only allows strings to be stored, the EObjects are serialized
(within a virtual resource). When a reference is then bound to a type, the type can be directly recreated (deserialized)
from the user data. The deserialized EObject is then added to the appropriate resource. It is not necessary to load the
complete file just to refer to a type from that file.
The design relies on two key features of Xtext:
-
Besides the parsed text (i.e., the AST), other elements can be stored in a resource, which are then ignored by the Xtext serializer, while still being properly contained in an EMF resource.
-
The
DerivedStateAwareResourceallows some kind of post processing steps when reading a resource. This enables a custom class, hereN4JSDerivedStateComputer, to create the types models (TClass, TRole and so on) from the parsedN4ClassDeclaration,N4RoleDeclarationand so on.
7.1.1. Getting the Xtext Index (IResourceDescriptions) Content
An instance of the IResourceDescriptions can be acquired from the resource description provider. Just like all services
in Xtext, this can be injected into the client code as well. The resource descriptions accepts a non-null resource set.
The resource set argument is mandatory to provide the index with the proper state. We are differentiating between three
different state. The first one is the persisted one, basically the builder state is a resource description as well, and
it provides a content that is based on the persisted state of the files (in our case the modules and package.json file)
on the file system. The second one is the live scoped index, this is modification and dirty state aware. Namely when using
this resource descriptions then an object description will be searched in the resource set itself first, then in the dirty
editor’s index, finally among the persisted ones. The third index is the named builder scoped one. This index should not be
used by common client code, since it is designed and implemented for the Xtex builder itself.
A resource set and hence the index can be acquired from the N4JS core, in such cases an optional N4JS project can be specified. The N4JS project argument is used to retrieve the underlying Eclipse resource project (if present) and get the resource set from the resource set provider. This is completely ignored when the application is running in headless mode and Eclipse resource projects are not available. It is also important to note that the resource set is always configured to load only the persisted states.
When the Eclipse platform is running, the workspace is available and the all N4JS projects are backed by an Eclipse resource
project. With the Eclipse resource project the resource sets can be initialized properly via the resource set initializer
implementations. This mechanism is used to get the global objects (such as console) and the built-in types (such as string,
number) into the resource set via the corresponding resource set adapters. In the headless case a special resource set
implementation is used; ResourceSetWithBuiltInScheme. This implementation is responsible to initialize the globals and the
built-in types into itself.
7.2. Design Overview
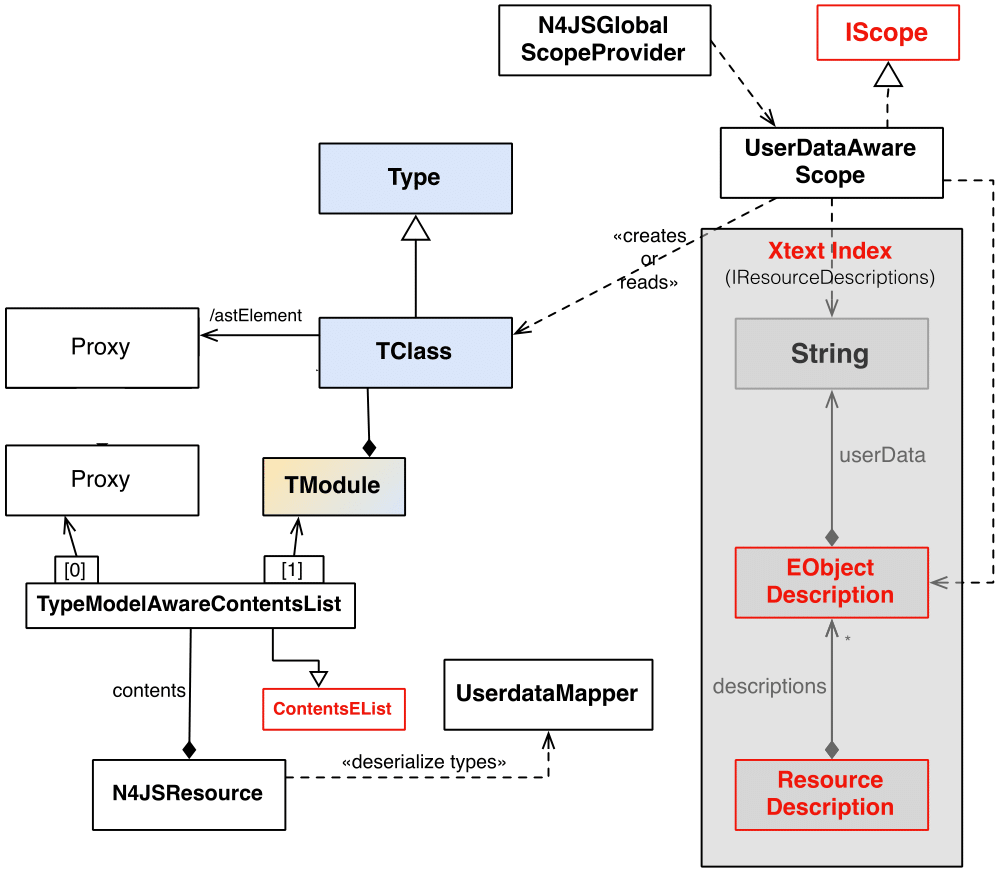
Type Model With Xtext Index shows a simplified UML class diagram with the involved classes. In the figure, a class (defined as N4ClassExpression in the AST and its type TClass) is used as a sample, declared type—roles or enums are handled similarly.
In the Eclipse project build the N4JSResourceDescriptionManager (resp. by the logic of its super class) is called by the
N4JSGenerateImmediatelyBuilderState to get the resource description for a resource. The resource description manager loads
the resource to create / update the resource descriptions. Loading an Xtext resource means that it is reparsed again.
All cross references are handled here only by the lazy linker so that the node model will contain an unresolved proxy
for all cross references.
After the resource is loaded there is a derived state installed to the resource. For this the N4JSDerivedStateComputer will
be called. It will take the parse result (= EObject tree in first slot of the resource) and navigate through these objects
to create type trees for each encountered exportable object that are stored in exported TModule of the resource.
Create Type From AST, a snippet of Type Model with Xtext Index,
shows only the classes involved when creating the types from the resource.
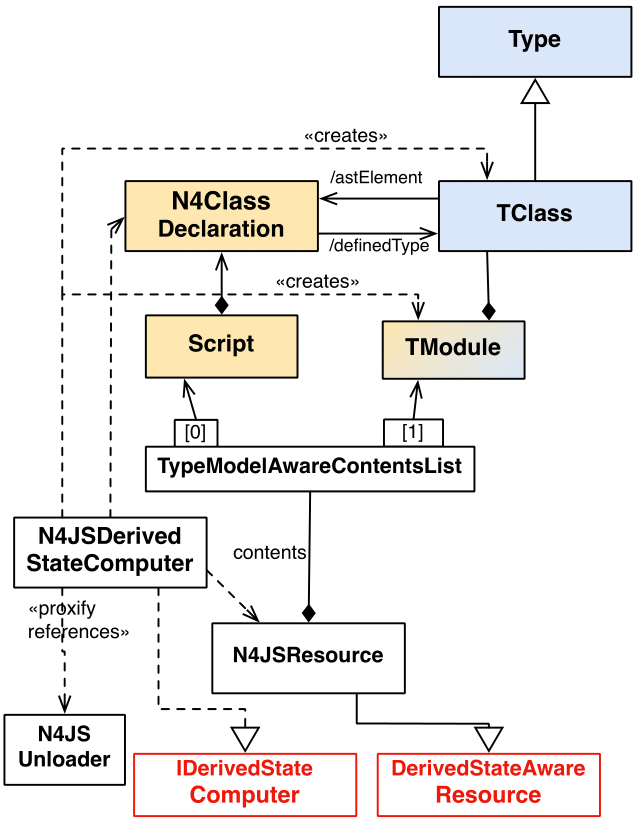
For these elements types have to be derived as they are exportable: N4ClassDeclaration, N4RoleDeclaration, N4InterfaceDeclaration,
N4EnumDeclaration, ExportedVariableDeclaration and FunctionDeclaration.
After loading and initializing the resources now all cross references in the resources are resolved. For this the
ErrorAwareLinkingService is used. This class will in turn call the N4JSScopeProvider to first try to do scoping locally
but eventually also delegate to the global scope provider to find linked elements outside the current resource. This
will be done e.g. for every import statement inside the N4JS resource.
For determine the global scope all visible containers for this resource are calculated. For this the project description
(= loaded package.json file) is used to determine which folders of the current project should be included for looking for
N4JS resources. Also all referenced projects and their resources are added to the visible containers. For these containers
N4JSGlobalScopeProvider builds up a container scope. This container scope will be a N4JSTypesScope instance.
For the actual linked element in the resource to be resolved, its fully qualified name is used. This name is calculated by
using the IQualifiedNameConverter. We bound a custom class named N4JSQualifiedNameConverter who converts the / inside the
qualified name to a dot, so e.g. my/module/MyFileName is converted to my.module.MyFileName. Btw. the initial qualified name
was derived from the node model.
With this qualified name N4JSTypeScope.getSingleElement is called. This method does the actual resolving of the cross reference.
For this the URI of the cross reference is used to determine the linked resource.
There are now three cases:
-
If the resource which contains the linked EObject is already loaded the EObject description found for the URI is returned
-
If the resource is not loaded but the first slot of the resource is empty the referenced type is tried to be rebuild from an existing resource description for the linked resource inside the Xtext index.
-
If the resource is not loaded and the first slot is set, the linked EObject will be resolved with the fragment of the given URI.
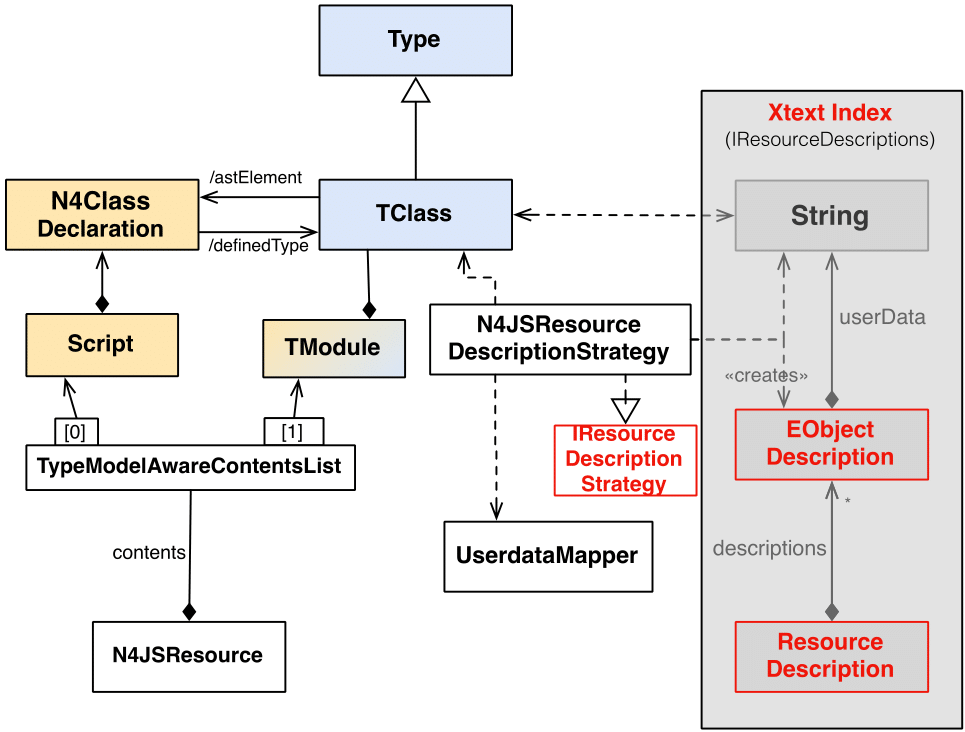
While calculating the resource description for a N4JSResource, the EObject descriptions of their exported objects have to be
calculated as well. For this the N4JSResourceDescriptionStrategy is used. For computing the exported objects of a resource only
the root TModule and its contained types and variables are taken in consideration.
The EObjectDescriptions for a n4js resource include:
-
An exported representation of the derived
TModule. This carries these properties:-
a qualified name (e.g.
my.module.MyFileNamewhen the resource is stored undersrc/my/module/MyFileName.jsin the project and the project description has marked src has src folder). The calculation of the qualified name is delegated to theN4JSNamingUtil. -
the user data which is the serialized string of the exported
TModuleitself. It includes the types determined for this resource, so for every element found in this resource, that is contained in anExportStatement, an EObject has been created before inN4JSDerivedStateComputer. In most cases this an EObject extendingTypefrom the types model, e.g.TClassforN4ClassDeclaration. There is an exception forExportedVariableDeclarationwhereTVariableis used as representative (and this EObject is not contained in the types model only in the N4JS model). For usability reasons (quicker quick fix etc.), also top level types not exported yet are stored in theTModel. -
the information on project and vendor id are part of the module descriptor.
-
-
Descriptions for all top level types that are defined in the resource. These descriptions do not have any special properties, so they just have a name.
-
All exported variables are also described in the resource description. They don’t carry any special information either.
The EObjectDescription for an EObject contained in an ExportStatement:
-
the qualified name of the module export (e.g. for a
N4ClassDeclarationthe qualified namemy.module.MyFileName.MyClassNamewould be produced, when the resource is stored undersrc/my/module/MyFileName.jsin the project, the project description has marked src has src folder and the N4 class uses the name MyClassName]). The calculation of the qualified name is delegated to theN4JSNamingUtil. -
the EObject represented by the EObject description, here this is not the actual EObject from N4JS but the type EObject from the TypeSystem, that has been inferenced by using
N4JSTypeInferencer -
the user data is only an empty map for this EObjectDescription
With this the resource description for a resource should be fully created / updated. Serialize to Index shows the classes involved creating the resource and EObjectDescriptions, along with the serialized type information.
7.3. N4JS Resource Load States
Below state diagram depicts the state transitions when loading and resolving an N4JS resource.

Additionally, the following table relates the values of the resource’s flags to the states.
| State | Parse Result | AST | TModule | ASTMetaInfoCache | loaded | fullyInitialized | fullyProcessed | reconciled |
|---|---|---|---|---|---|---|---|---|
Created |
|
|
|
|
false |
false |
false |
false |
Created' |
|
|
|
|
false |
true |
false |
false |
Loaded |
available |
with lazy linking proxies |
|
|
true |
false |
false |
false |
Pre-linked |
available |
with lazy linking proxies |
with stubs |
|
true |
true |
false |
false |
Fully Initialized |
available |
with lazy linking proxies |
with DeferredTypeRefs |
|
true |
true |
false |
false |
Fully Processed |
available |
available |
available |
available |
true |
true |
true |
false |
Loaded from Description |
|
proxy |
available |
|
indeterminate |
true |
true |
false |
Loaded from Description' |
|
proxy |
with DeferredTypeRefs |
|
indeterminate |
true |
true |
false |
Fully Initialized ® |
available |
with lazy linking proxies |
available |
|
indeterminate |
true |
false |
true |
Fully Processed ® |
available |
available |
available |
available |
indeterminate |
true |
true |
true |
Remarks:
-
oddities are shown in red ink, in the above figure.
-
in the above figure:
-
"AST (proxy)" means the AST consists of only a single node of type
Scriptand that is a proxy, -
"AST (lazy)" means the AST is completely created, but cross-references are represented by unresolved Xtext lazy-linking proxies,
-
"TModule (stubs)" means the TModule has been created with incomplete information, e.g. return types of all TMethods/TFunctions will be
null(only used internally by the incremental builder), -
"TModule (some deferred)" means the TModule has been created, does not contain stub, but some `TypeRef`s are `DeferredTypeRef`s that are supposed to be replaced by proper `TypeRef`s during post-processing.
-
"AST" and "TModule" means the AST/TModule is available without any qualifications.
-
-
state Created': only required because Xtext does not clear flag
fullyInitializedupon unload; that is done lazily when#load()is invoked at a later time.. Thus, we do not reach state Created when unloading from state Fully Initialized but instead get to state Created'. To reach state Created from Fully Initialized we have to explicitly invoke#discardDerivedState()before(!) unloading. -
state Loaded from Description': transition
#unloadAST()from state Fully Initialized leaks a non-post-processed TModule into state Loaded from Description, which is inconsistent with actually loading a TModule from the index, because those are always fully processed. Hence, the addition of state Loaded from Description'. -
states Fully Initialized ® and Fully Processed ®: these states are reached via reconciliation of a pre-existing TModule with a newly loaded AST. These states differ in an unspecified way from their corresponding non-reconciled states. For example, in state Fully Initialized ® the TModule does not contain any DeferredTypeRefs while, at the same time, the TModule isn’t fully processed, because proxy resolution, typing, etc. have not taken place, yet.
-
TODO old text (clarify this; I could not reproduce this behavior): when
unloadASTis called,fullyInitializedremains unchanged. This is why the value offullyInitializedshould be indeterminate in row Loaded from Description; it depends on the previous value if the state Loaded from Description was reached by callingunloadAST.
7.4. Types Builder
When a resource is loaded, it is parsed, linked, post-processed, validated and eventually compiled. For linking and validation type information is needed, and as described above the type information is created automatically when loading a resource using the types builder. Resource Loading shows an activity model with the different actions performed when a resource is loaded.
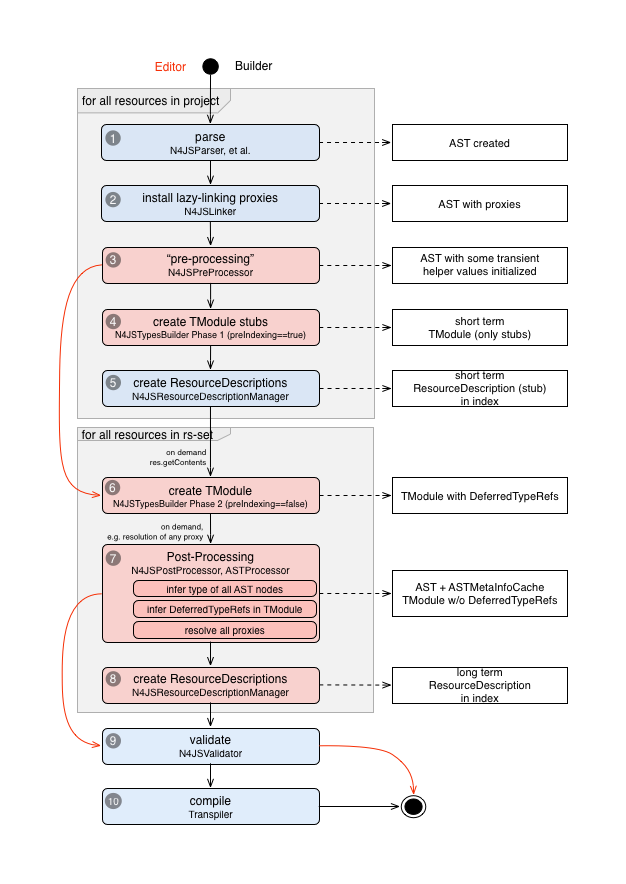
The blue colored steps are standard Xtext workflow. Handling the TModule and storing that in the index are N4 specific (red background).
7.4.1. Type Inference not allowed in Types Builder
A crucial point in the workflow described above is the combination of types model building and type inference. In some cases, the type of a given element is not directly stated in the AST but has to be inferred from an expression and other types. For example, when a variable declaration does not declare the variable’s type explicitly but provides an initializer expression, the actual type of the variable is inferred to be the type of the expression.
However, the types builder cannot be allowed to use type inference, mainly for two reasons:
-
type inference through Xsemantics could lead to resolution of cross-references (i.e. EMF proxies generated by the lazy linker) and because the types builder is triggered when getContents() is called on the containing
N4JSResourcethis would break a basic contract of EMF resources. -
type inference could cause other resources to be loaded which would lead to problems (infinite loops or strange results) in case of circular dependencies. This is illustrated in Types Builder Problem and Types Builder Proxies.
Therefore, whenever the type of a particular element has to be inferred, the types builder will use a special type reference
called DeferredTypeRef [3],
in order to defer the actual type inference to a later stage, i.e. the post-processing stage.


7.4.2. Deferred Type References
Whenever type inference would be required to obtain the actual type of an element, the types builder will insert a stub to defer
actual type inference (see previous section). A dedicated subclass of TypeRef, called DeferredTypeRef, is used that contains neither
the actual type information nor any information necessary to perform the type inference at a later point in time. Later, this
DeferredTypeRef will be replaced during post-processing, see TypeDeferredProcessor.
All DeferredTypeRefs will be replaced by the actual types during post-processing. One important reason for resolving
all DeferredTypeRefs as early as possible is that they are not suited for serialization and therefore have to be removed
from the types model before populating the Xtext index, which includes serializing the TModule into the user data of the
root element. This is always assured by the logic that manages the triggering of the post-processing phase.
To manually trigger resolution of all DeferredTypeRefs in a given types model, simply call method performPostProcessing(CancelIndicator)
of the containing N4JSResource (should never be required by client code such as validations).
7.4.3. Use cases of DeferredTypeRef
Currently, DeferredTypeRefs are created by the types builder only in these cases:
-
actual type of an exported TVariable if no declared type but an initialization expression are given.
-
actual type of a TField if no declared type but an initialization expression are given.
-
actual type of properties of ObjectLiterals if not declared explicitly.
-
actual type of formal parameters and return value of function expressions if not declared explicitly.
Note that this overview might easily get out-dated; see references to class DeferredTypeRef in the code.
7.5. Incremental Builder (Overview)
This section provides a brief overview of how the incremental builder works.
General remarks:
-
The N4JS incremental builder is a combination of Eclipse builder infrastructure, Xtext-specific builder functionality and several adjustments for N4JS and N4MF.
-
The
IBuilderStateimplementation is identical to the persisted Xtext index. No matter how many Xtext languages are supported by the application, only a singleIBuilderStateinstance is available in the application. Since we have one singleIBuilderState, we have one single persisted Xtext index throughout the application. -
For simplicity, the below description assumes we have only N4JS projects in the workspace and no other Xtext languages are installed.
Major components:
-
XtextBuilder(inherits from Eclipse’sIncrementalProjectBuilder):-
the actual incremental builder
-
note: Eclipse will create one instance of
XtextBuilderper project at startup.
-
-
IBuilderState(Xtext specific; no Eclipse pendant):
identical to theXtext index, i.e. the globally shared, persisted instance of
IResourceDescriptions.
Main workflow:
-
for each project that contains at least one resource that requires rebuilding, Eclipse will call the project’s
XtextBuilder. -
each
XtextBuilderwill perform some preparations and will then delegate toIBuilderStatewhich will iterate over all resources in the builder’s project that require rebuilding.
7.5.1. XtextBuilder
Whenever a change in the workspace happens …
-
Eclipse will collect all projects that contain changed resources and compute a project-level build order (using the
build orderof the workspace, seeWorkspace#getBuildOrder(), which is based on project dependencies) -
for the first [4] project with changed resources, Eclipse will invoke method
IncrementalProjectBuilder#build(int,Map,IProgressMonitor)of the project’sXtextBuilder
(NOTE: from this point on, we are in the context of acurrent project) -
in
XtextBuilder#build(int,Map,IProgressMonitor):
the builder creates an empty instance ofToBeBuilt(Xtext specific) -
in
XtextBuilder#incrementalBuild(IResourceDelta,IProgressMonitor):-
The builder will iterate over all files in the project and for each will notify a
ToBeBuiltComputerabout the change (added, updated, or deleted) which can then decide how to update theToBeBuiltinstance, -
then forwards to
#doBuild().Note: if user changes 1..* files in a single project but later more files in other, dependant projects need to be built, the above step will happen for all projects, but will have an effect only for the first project that contains the actual file changes (i.e. in the standard case of saving a single file
ToBeBuiltwill always be non-empty for thefirstproject, and always empty for the other, dependant projects; if aSave Allis done,ToBeBuiltcould be non-empty for later projects as well).
-
-
in
XtextBuilder#doBuild(ToBeBuilt,IProgressMonitor,BuildType):-
first check if
ToBeBuiltis empty AND global build queue does not contain URIs for current project → then abort (nothing to do here) -
creates instance of BuildData with:
-
name of current project (as string)
-
newly created, fresh
ResourceSet -
the
ToBeBuilt(containing URIs of actually changed resources within current project, possibly filtered byToBeBuiltComputer) -
the
QueuedBuildData(an injected singleton) -
mode flag
indexingOnly(only true during crash recovery)
-
-
invoke
IBuilderStatepassing theBuildData
→ updates itself (it is the global Xtext index) to reflect all changes incurrent project; validates and updates markers; runs transpiler (see below for details) -
invoke all registered
IXtextBuilderParticipants(Xtext specific) for thecurrent project-
this is where normally we would do validation and run the transpiler; however, for performance reasons (do not load resource again) we already do this in the
IBuilderState(this is the idea of theGenerateImmediatelyBuilderState) -
in our implementation, almost nothing is done here, except trivial stuff such as deleting files during clean build
At this point: returning from all methods.
-
-
-
back in
XtextBuilder#build(int,Map,IProgressMonitor):
→ return with an array of IProjects; in our case: we return all other N4JSProjects referenced in the package.json of the project-
important: these are not the projects that will be processed next: we need to continue with projects that depend on the current project, not with projects the current project depends on!
-
Eclipse calls the returned projects
interestingProjectsand uses that as a hint for further processing; details not discussed here.
-
-
continue with step one:
Eclipse will invokeXtextBuilder#build(int,Map,IProgressMonitor)again for all other projects that have a dependency to thecurrent projectof the previous iteration, plus all remaining projects with changed resources.
7.5.2. IBuilderState
Invoked: once for each project containing a changed resource and dependant projects.
Input: one instance of BuildData, as created by XtextBuilder, containing:
-
name of current project (as string)
-
newly created, fresh
ResourceSet -
the
ToBeBuilt-
set of to-be-deleted URIs
-
set of to-be-updated URIs
-
-
the
QueuedBuildData, an injected singleton maintaining the following values [5]:-
a queue of URIs per project (below called the
global queue)
(actually stored inQueuedBuildData#projectNameToChangedResource) -
a collection of
all remaining URIs
(derived value: queued URIs of all projects + queues URIs not associated to a project (does not happen in N4JS)) -
a collection of
pending deltas(always empty in N4JS; probably only used for interaction with Java resources)
-
-
mode flag
indexingOnly(only true during crash recovery)
7.5.2.1. Copy and Update Xtext Index
-
in
IBuilderState#update(BuildData,IProgressMonitor):
creates a copy of itsResourceDescriptionsDatacallednewData[6] -
in
AbstractBuilderState#doUpdate(…):
updatesnewDataby writing new resource descriptions into it.-
Creates a new load operation (
LoadOperation) instance from theBuildData#getToBeUpdated()and loads all entries. While iterating and loading the resource descriptions, it updatesnewDataby registering new resource descriptions that are being created on the fly from the most recent version of the corresponding resources. -
Adds these resources to the current project’s build queue. (
BuildData#queueURI(URI uri))
-
-
for all to-be-deleted URIs given in
ToBeBuiltin theBuildData, removes the correspondingIResourceDescriptionfromnewData-
ToBeBuilt#getAndRemoveToBeDeleted()returns all URIs that have been marked for deletion but not marked for update and will clear the set of to-be-deleted URIs inToBeBuilt.
-
7.5.2.2. Build State Setup Phase
-
Calculates a set
allRemainingURIs[7] as follows:-
Initially contains all resource URIs from
newData. -
All URIs will be removed from it that are marked for update (
BuildData#getToBeUpdated()). -
Finally, all URIs will be removed from it that are already queued for build/rebuild. (
BuildData#getAllRemainingURIs()).
-
-
Creates an empty set
allDeltasof resource description deltas
(c.f.IResourceDescription.Delta). [8] -
Process Deleted: for all to-be-deleted URIs, creates a delta where the old state is the current state of the resource and the new state is
nulland adds it toallDeltas. -
Adds all
pending deltasfromQueuedBuildDatatoallDeltas(does not apply to N4JS). -
Enqueue affected resources, part 1: adds to the
global queuethe URIs of all resources affected by the changes inallDeltas.For N4JS, allDeltasalways seems to be empty at this point, so this does nothing at all. -
Creates an empty set
changedDeltasfor storing deltas that were modified by the build phase and represent an actual change. UnlikeallDeltas, this set contains only those URIs that were processed by the builder - the underlying user data information contains the differences between the old and the new state. -
Creates a new
current queueand adds all URIs from theglobal queuethat belong to thecurrent project.
7.5.2.3. Process Queued URIs
Processes all elements from the queue until it contains no more elements.
-
Load the resource for the first/next URI on the current queue
In case of a move, the loaded resource could have a different URI! -
Once the resource has been loaded, it removes its URI from the current queue to ensure it will not be processed again.
-
If the loaded resource is already marked for deletion, stop processing this resource and continue with next URI from the current queue (go to step Load Res) [9]
-
Resolves all lazy cross references in the loaded resource. This will trigger post-processing, including all type inference (c.f.
ASTProcessor#processAST(…)). -
Creates a delta for the loaded resource, including
-
a resource description based on the new state of the resource, wrapped into the
EObject-based resource description (as with the Xtext index persistence inEMFBasedPersister#saveToResource()). -
a resource description for the same resource with the state before the build process.
-
-
Adds this new delta to
allDeltasand, if the delta represents a change (according toDefaultResourceDescriptionDelta#internalHasChanges()), also adds it tochangedDeltas. -
Adds the resource description representing the new state, stored in the delta, to
newData, i.e. the copiedResourceDescriptionsData, replacing the old resource description of the loaded resource [10]. -
If the current queue is non-empty, go to step Load Res and continue with the next URI in the current queue.
7.5.2.4. Queueing Affected Resources
When the current queue contains no more URIs (all have been processed) …
-
Enqueue affected resources, part 2: add to the global queue URIs for all resources affected by the changes in
changedDeltas[11]. -
Returns from
#doUpdate(), returningallDeltas(only used for event notification). -
back in
IBuilderState#update(BuildData,IProgressMonitor):
makes thenewDatathe publicly visible, persistent state of the IBuilderState (i.e. theofficialXtext index all other code will see).
We now provide some more details on how the global queue is being updated, i.e. steps Enqueue Affected Resources and Update Global Queue. Due to the language specific customizations for N4JS, this second resource-enqueuing phase is the trickiest part of the incremental building process and has the largest impact on how other resources will be processed and enqueued at forthcoming builder state phases.
-
If
allDeltasis empty, nothing to do. -
If
allDeltascontains at least one element, we have to check other affected resources by going through the set of all resource URIs (allRemainingURIs) calculated in in the beginning of the build process. -
Assume we have at least one element in the
allDeltasset, the latter case is true and we must check all elements whether they are affected or not. We simply iterate through theallRemainingURIsset and retrieve the old state of the resource description using the resource URI. -
Once the resource description with the old state is retrieved, we check if it is affected through the corresponding resource description manager. Since we currently support two languages, we have two different ways for checking whether a resource has changed or not. One for package.json files and the other for the N4JS language related resources.
-
The package.json method is the following: get all project IDs referenced from the
candidatepackage.json and compare it with the container-project name of the package.json files from thedeltas. The referenced IDs are the followings:-
tested project IDs,
-
implemented project IDs,
-
dependency project IDs,
-
provided runtime library IDs,
-
required runtime library IDs and
-
extended runtime environment ID.
-
-
The N4JS method is the following:
-
We consider only those changed deltas which represent an actual change (
IResourceDescription.Delta#haveEObjectDescriptionsChanged()) and have a valid file extension (.n4js,.n4jsdor.js). -
For each
candidate, we calculate the imported FQNs. The imported FQNs includes indirectly imported names besides the directly imported ones. Indirectly imported FQNs are, for instance, the FQNs of all transitively extended super class names of a direct reference. -
We state that a
candidateis affected if there is a dependency (for example name imported by acandidate) to any name exported by the description from a delta. That is, it computes if a candidate (with givenimportedNames) is affected by a change represented by the description from the delta. -
If a
candidateis affected we have to do an additional dependency check due to the lack of distinct unique FQNs. If a project containing the delta equals with the project contained by the candidate, or if the project containing the candidate has a direct dependency to the project containing the delta, we mark a candidate as affected.
-
-
If a candidate was marked as affected, it will be removed from the
allRemainingURIsand will be added to the build queue. -
If a candidate has been removed from the
allRemainingURIsand queued for the build, we assume itsTModuleinformation stored in the user data is obsolete. To invalidate the obsolete information, we wrap the delta in the custom resource description delta so whenever theTModuleinformation is asked for, it will be missing. We then register this wrapped delta into the copied Xtext index, end the builder state for the actual project then invoke the Xtext builder with the next dependent project.
7.5.3. Example
To conclude this section, we briefly describe the state of the above five phases through a simple example. Assume a
workspace with four N4JS projects: P1, P2, P3 and PX. Each project has one single module with one single
publicly visible class. Also let’s assume project P2 depends on P1 and P3 depends on P2. Project PX have
no dependencies to other projects. Project P1 has a module A.n4js with a class A, project P2 has one single
module B.n4js. This module has a public exported class B which extends class A. Furthermore, project P3 has
one single module: C.n4js. This module contains one exported public class C which extends B. Finally, project
PX has a module X.n4js containing a class X that has no dependencies to any other classes. The figure below
picture depicts the dependencies between the projects, the modules and the classes as described above.

For the sake of simplification, the table below describes a symbol table for all resources:
P1/src/A.n4js |
A |
P2/src/B.n4js |
B |
P3/src/C.n4js |
C |
PX/src/X.n4js |
X |
Let assume auto-build is enabled and the workspace contains no errors and/or warnings. We make one simple modification
and expect one single validation error in class C after the incremental builder finished its processing; we delete the
method foo() from class A.
After deleting the method in the editor and saving the editor content, a workspace modification operation will run and
that will trigger an auto-build job. The auto-build job will try to build the container project P1 of module A. Since
the project is configured with the Xtext builder command, a builder state update will be performed through the Xtext builder.
Initially, due to an Eclipse resource change event (we literally modify the resource from the editor and save it), the
ToBeBuilt instance wrapped into the BuildData will contain the URI of the module A marked for an update. When updating
the copied index content, module A will be queued for a build. While processing the queued elements for project P1,
module A will be processed and will be added to the allDeltas set. Besides that, it will be added to the changedDeltas
set as well. That is correct, because its TModule information has been changed after deleting the public foo() method.
When queuing affected resources, iterating through the set of allRemainingURIs, we recognize that module B is affected.
That is indeed true; module B imports the qualified name of class A from module A and project P2 has a direct
dependency to P1. In this builder state phase, when building project P1, module C is not considered as affected.
Although class C from module C also imports the qualified name of class A from module A, project P3 does not
have a direct dependency to project P1. When module B becomes enqueued for a forthcoming build phase, we assume its
TModule information is obsolete. We invalidate this TModule related user data information on the resource description
by wrapping the resource description into a custom implementation (ResourceDescriptionWithoutModuleUserData). Due to this
wrapping the resource description for module B will be marked as changed (IResourceDescription.Delta#haveEObjectDescriptionsChanged())
whenever the old and current states are being compared.
The Eclipse builder will recognize (via IProjectDescription#getDynamicReferences()) that project P2 depends on project P1
so the Xtext builder will run for project P2 as well. At the previous phase we have enqueued module B for the build.
We will therefore run into a builder state update again. We do not have any resource changes this time, so ToBeBuilt will
be empty. Since ToBeBuilt is empty, we do not have to update the copied Xtext index state before the builder state setup
phase. As the result of the previous builder state, phase module B is already enqueued for a build. When processing B
we register it into the allDeltas set. That happens for each resource being processed by the builder state. But it will be
registered into the changedDeltas because we have previously wrapped module B into a customized resource description delta
to hide its obsolete TModule related user data information. Based on the builder state rules and logic described above,
module C will be marked as an affected resource, will be queued for build and will be wrapped into a customized resource
description delta to hide its TModule related user data information.
In the next builder state phase, when building project P3, we apply the same logic as we applied for project P2. The
builder state will process module C and will update the Xtext index state. No additional resources will be found as
affected ones, nothing will be queued for build. The build will terminate, since there were no changed IResource instances
and the build queue is empty.
The outcome of the incremental build will be a workspace that contains exactly one validation error. The error will be
associated with module C which was exactly our expectation, however, we have to clarify that transitive C dependency
was built due to wrong reasons. Module C was build because we wrapped module B to hide its user data information and
not because it imports and uses class A from module A which should be the logical and correct reason.
7.6. Dirty state handling
When two or more (N4)JS files are opened in editors and one of them is changed but without persisting this change the other open editors should be notified and if this change breaks (or heals) references in one of the other open resources their editors should updated so that warn and error markers are removed or added accordingly.
When there are changes in the currently open editor these changes are propagated to all other open editors. Each Xtext editor has
got its own resource set. The N4JSUpdateEditorStateJob runs for each open editor different from the editor where the changes have
been made. In those editors the affected resources are unloaded and removed from the resource set. Then the Xtext resource of
these editors is reparsed. After reparsing scoping and linking is invoked again, but now the references resources are rebuild
as EObjectDescriptions. The N4JSResource holds its own content that only contains 1..n slots when proxified.
N4JSTypeScope.getSingleElement (called when resolving cross references and the linked element should be returned) will return the
EObjectDescription created from the ModuleAwareContentsList in N4JSResource, that contains the first slot as proxy and the other
slots as types. Sequence Diagram: Dirty State, Trigger N4JSUpdateEditorStateJob shows the flow to trigger the N4JSUpdateEditorStateJob and Sequence Diagram: Dirty State, N4JSUpdateEditorStateJob in Detail
shows the sequence logic of the N4JSUpdateEditorStateJob in detail.

N4JSUpdateEditorStateJob
N4JSUpdateEditorStateJob in DetailA concrete example should illustrate the behaviour of the dirty state handling in conjunction with fully and partial loading of resources:
Let A.js as above, and B.js as follows:
import A from "A.js"
export class B {}-
assume is opened and loaded: is created with
-
is filled with a special proxy to resolve the AST of A only if needed.
-
will be set to type A, loaded from
EObjectDescriptionof A.js/A
-
-
AST of A.js is to be accessed, e.g., for displaying JSDoc. A.js is not opened in an editor! is modified as follows:
-
is filled with AST, i.e. proxy in 0 is resolved
-
is updated with parsed type: 1) proxify , 2) unload (remove from content), 3) reload with parsed types again
-
-
Assume now that A.js is opened and edited by the user.
-
Reconceiler replaces with modified AST
-
LazyLinker updates
-
is proxified
-
B
searchesfor A and finds updated
-
Each opened Xtext editor has got its own resource set! Such a resource set contains the resource for the currently edited
file in the first place. When starting editing the file, the resource is reparsed , reloaded and linking (resolving the cross
references) is done. By resolving the cross references N4JSTypeScope is used and now the URIs of the linked elements are belonging
to resources not contained in the resource set of the editor so these resources a create in the resource set and their contents
is loaded from the resource descriptions via
N4JSResource.loadFromDescription .
When the resource content is loaded from the existing resource description available from Xtext index the first slot is set to be
a proxy with name #:astProxy.
After that for all exported EObject descriptions of that resource description the user data is fetched and deserialized to types
and these types are added to the slots of the resource in order they were exported. But the order is not that important anymore.
As the resource set for the editor is configured to use the DirtyStateManager ( ExternalContentSupport.configureResourceSet(resourceSet, dirtyStateManager) ),
all other open editors will be notified by changes in the current editor. This is done by N4JSDirtyStateEditorSupport that schedules
a N4JSUpdateEditorStateJob that create a new resource description change event.
Via isAffected and ResourceDescription.getImportedNames it is determine if a change in another resource affects this resource.
Before loading the resource always N4JSDerivedStateComputer.installDerivedState is execute that, as we learned earlier, is responsible
for creating the types in the resource.
On every change to a N4JS file that requires a reparse the N4JSDerivedStateComputer.discardDerivedState is executed. This method do an
unload on every root element at the positions 1 to n. In the N4JSUnloader all contents of the this root elements are proxified (i.e.
there is a proxy URI set to each of them) and the references to the AST are set to null (to avoid notifications causing
concurrent model changes). The proxification indicates for all callers of these elements, that they have to reload them. Afterwards
it discards the complete content of the resource. The content is build up again with the reparse of the N4JS file content.
As each editor has its own resource set, only the resource belonging to the current editor is fully loaded. All other referenced resources are only partially loaded, i.e. only the slot 1 of these resources are loaded (i.e. the types model elements) in this resource set. Linking is done only against these types model elements. Synchronization between the resource sets of multiple open editors is done via update job as described above.
7.6.1. Use case: Restoring types from user data
-
Use case: referencing resources in editor: This has been described already in context of dirty state handling
-
Use case: referencing resources from JAR: This is still to be implemented.% taskIDE-37
7.6.2. Use case: Updating the Xtext index
When a N4JS file is changed in way that requires reparsing the file, the underlying resource is completely unloaded and loaded again. By this the also the elements at the Xtext index are recreated again, belonging to this resource (i.e. new entries for new elements in the resource, update index elements of changed elements, delete index entries for deleted elements).
When Eclipse is closed the Xtext index is serialized in a file.
When starting Eclipse again, the Xtext index is restored from this file:
