Statements
Statements express how a process or function in a system works. They define what is done and in which order. Many statements use data for their decisions, which is stored in local variables. The combined local variables and statements are called 'body' with the following syntax.
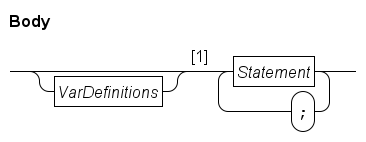
Data values available to the process are the global constants (see Constant definitions) and enumeration values (see Enumeration definitions). The formal parameters of the surrounding process definition (explained in Process definitions) or the surrounding function definition (explained in Function definitions) are added as well.
Data storage that can be modified by the process are the local variables, defined by the VarDefinitions block in the Body diagram above (variable definitions are explained below in Local variables).
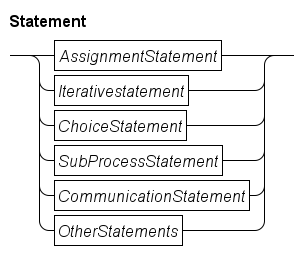
The data values and the modifiable data storage is used by the statements of the Body in the path after 1. For ease of reference they are grouped by kind of statement as shown in the Statement diagram below.
-
The
AssignmentStatementis used to assign new values to the local variables (and explained further in Assignment statement). -
The
IterativeStatementallows repeated execution of the same statements by means of theforandwhilestatements (further explained in Iterative statements). -
The
ChoiceStatementallows selection on which statement to perform next by means of theifstatement (explained in Choice statement). -
The
runandstartstatements of theSubProcessStatementgroup (explained in Sub-process statements) start new processes. -
Communication with other processes using channels is done with send, receive, and
selectstatements inCommunicationStatement(explained in Communication statements) -
Finally, the
OtherStatementsgroup contains several different statements (explained further in Other statements). The more commonly used statements in that group are thedelaystatement, thewritestatement, and thereturnstatement.
The syntax diagram of Body states that statements are separated from each other with a semicolon (;). The compiler allows more freedom. Semicolons may be omitted before and after a end keyword, and a semicolon may be added after the last statement.
Local variables
Local variables are introduced in a process or function using the following syntax.
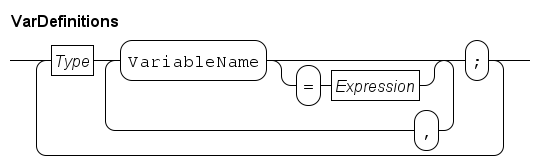
Variable definitions start with a Type node (its syntax if explained in Types), followed by a sequence of variable names where each variable may be initialized with a value by means of the = Expression path. If no value is assigned, the variable gets the default value of the type. Use a semicolon to terminate the sequence of new variables.
Next, another set of variables may be defined by going back to the start of the diagram, and giving another Type node, or the diagram can be ended, and the statements of the process or function can be given.
Assignment statement
An assignment statement assigns one or more values to the local variables. Its syntax is as follows.
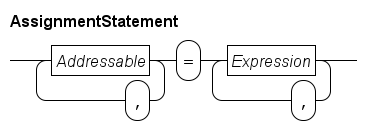
The assignment statement computes the value of every Expression at the right. If there is one expression, its value is also the value to assign. If there are more expressions, a tuple value is constructed, combining all values into one tuple (see Tuple expression for a discussion of tuple values).
At the left, a number of Addressable blocks define where the computed value is assigned to.
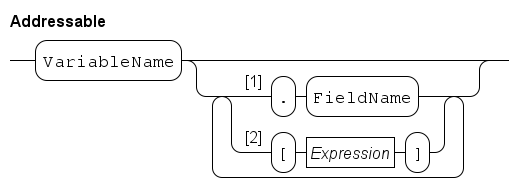
An Addressable is a variable. If the variable has a tuple type (see Tuple type) a field of the tuple may be assigned only using Path 1. Similarly, if the variable is a list (see List type) or a dictionary (see Dictionary type) assignment is done to one element by using Path 2. The Expression here is evaluated before any assignment by this statement is performed. Since selected elements may also have a type that allows selection, element selection can be repeated.
After processing the element selections at the left, it is known where values are assigned to. If there is exactly one addressable at the left, its type must match with the type of the value at the right (which may be a constructed tuple value as explained above). The value gets copied into the variable (or in its element if one is selected). If there are several addressable values at the left, the number of values must be equal to the length of the tuple from the expression(s) at the right, and each field of the right tuple must pair-wise match with the type of the addressed element at the left. In the latter case, all assignments are done at the same moment.
For a few examples, a number of variable declarations are needed:
int x, y;
real r;
list(10) int xs;
tuple(real v; int w) t;
func tuple(real v; int w) (int) f;
... # Initialization of the variables omittedThe variable declarations introduce integer variables x and y, a real number variable r, a list of 10 integers xs, a tuple t with two fields, and a function variable f.
For reasons of clarity, initialization of the variables has been omitted. Also, expressions at the right are simple values. However, you may use all allowed expression operations explained in the next chapter (Expressions) to obtain a value to assign. The first assignments show assignment of values to variables where there is one explicit value for every assigned variable:
x = 3;
t = f(y);
x, y = 4, 5;
xs[0], t.v = x+x, r;The first assignment statement assigns 3 to x. The second assignment assigns the return value of the function call f(y) to tuple t. The third assignment assigns 4 to x and 5 to y at the same time. The fourth assignment assigns the value of x+x to the first element of the list xs, and the value of r to the v field of tuple t.
The next assignments show combining or splitting of tuples:
t = r, y;
r, x = t;
r, x = f(y);The first assignment assigns a new value to every field of tuple t (t.v gets the value of r, while t.w gets the value of y). This is called packing, it 'packs' the sequence of values into one tuple. The opposite operation is demonstrated in the second assignment. The value of each field of t is assigned to a separate variable. The types of the variables at the left have to pair-wise match with the field types of the tuple at the right. This assignment is called unpacking, it 'unpacks' a tuple value into its separate elements. The third assignment does the same as the second assignment, the difference is that the value at the right is obtained from a function call. The origin of the value is however irrelevant to the assignment statement.
To demonstrate the order of evaluation, the following assignment, under the assumption that variable x holds value 3:
x, xs[x-1] = 7, x+2;The assignment first computes all values at the right. Since there are more than one expression, they are combined into a tuple:
x, xs[x-1] = (7, 5);Next, the addressable values are calculated:
x, xs[2] = (7, 5);Finally the values are assigned, x gets a new value 7, while the third element of xs gets the value of expression x+2.
The expressions at the right as well as the expressions to select elements in lists and dictionaries are always evaluated using values from before the assignment.
It is forbidden to assign the same variable or selected element more than once:
x, x = 3, 3 # Error, assigned 'x' twice.
xs[0], xs[1] = 0, 1 # Allowed, different selected elements.
xs[0], xs[x] = 0, 1 # Allowed if x != 0.Iterative statements
The iterative statements are shown below.
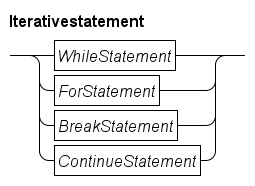
The Chi language has two statements for repeatedly executing a body (a sequence of statements), a while statement and a for statement. The former is the generic iterative statement, the latter simplifies the common case of iterating over a collection of values.
The break and continue statements change the flow of control in the iterative statements.
While loop statement
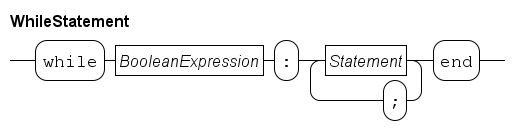
A while loop starts with the keyword while with a boolean condition. Between the colon and the end keyword, the body of statements is given, which is executed repeatedly.
Executing an iterative while statement starts with evaluating the boolean condition. If it does not hold, the while statement ends (and execution continues with the statement following the while statement). If the condition holds, the statements in the body are executed from start to end (unless a break or continue statement is executed, as explained below). After the last statement has been executed, the while statement starts again from the beginning, by evaluating the boolean condition again.
As an example, consider the following code:
int s, i;
while i < 10:
s = s + i
i = i + 1
endAt first, the i < 10 condition holds, and the body of the while statement (two assignment statements) is executed. After the body has finished, i has been incremented, but is still less than 10. The condition again holds, and the body is again executed, etc. This process continues, until the final statement of the body increments i to 10. The condition does not hold, and execution of the while statement ends.
For loop statement
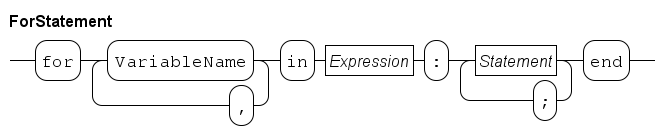
A common case for iterating is to execute some statements for every value in a collection, for example a list:
list int xs;
int x;
int i;
while i < size(xs):
x = xs[i]
...
i = i + 1
endwhere the ... line represents the statements that should be executed for each value x of the list. This is a very common case. Chi has a special statement for it, the for statement. It looks like:
list int xs;
for x in xs:
...
endThis code performs the same operation, the statements represented with ... are executed for each value x from list xs, but it is shorter and easier to write. The advantages are mainly a reduction in the amount of code that must be written.
-
No need to create and update the temporary index variable
i. -
Variable
xis declared implicitly, no need to write a full variable declaration for it.
The behavior is slightly different in some circumstances.
-
There is no index variable
ithat can be accessed afterwards. -
When the
...statements modify the source variable (xsin the example), thewhilestatement above uses the changed value. Theforstatement continues to use the original value of the source variable.
Continuing use of the original source value can be an advantage or a disadvantage, depending on the case. Using the new value gives more flexibility, keeping the old value makes the for statement more predictable, for example indices in the source variable stay valid.
Besides iterating over a list with for, you can also iterate over element values of a set, or over key-value tuples of a dictionary, for example:
dict(int:int) d = {1:10, 2:20};
for k, v in d:
writeln("%s: %s", k, v);
endWhen iterating over a set or a dictionary, the order of the elements is undefined. In the above example, the first pair is either (1, 10) or (2, 20).
Break statement
The break statement may only be used inside the body of a loop statement. When executed, the inner-most loop statement ends immediately, and execution continues with the first statement after the inner-most loop statement. An example:
# Get a slice of the xs list, up-to the position of value x in the list
func get_until(list int xs, int x):
int index;
while index < size(xs):
if xs[index] == x:
break
end;
index = index + 1
end
return xs[:index]
endIn the example, elements of the list xs are inspected until an element with a value equal to x is found. At that point, the loop ends with the break statement, and the function returns a slice of the list.
Continue statement
Another common case when executing the body of an inner-most loop is that the remaining statements of the body should be skipped this time. It can be expressed with an if statement, but a continue statement is often easier.

The syntax of the continue statement is just continue. An example to demonstrate its operation:
int s;
for x in xs:
if x mod 5 == 0:
continue
end
s = s + x
endThe for statement iterates over every value in list xs. When the value is a multiple of 5 (expressed by the condition x mod 5 == 0), the continue is executed, which skips the remaining statements of the body of the for statement, namely the s = s + x assignment. The result is that after executing the for statement, variable s contains the sum of all values of the list that are not a multiple of 5.
Choice statement
The choice statement, also known as 'if statement', selects one alternative from a list based on the current value of a boolean expression. The alternatives are tried in turn, until a boolean expression one an alternative yields true. The statements of that alternative are executed, and the choice statement ends. The choice statement also ends when all boolean expressions yield false. The boolean expression of the else alternative always holds.
The syntax of the choice statement is as follows.
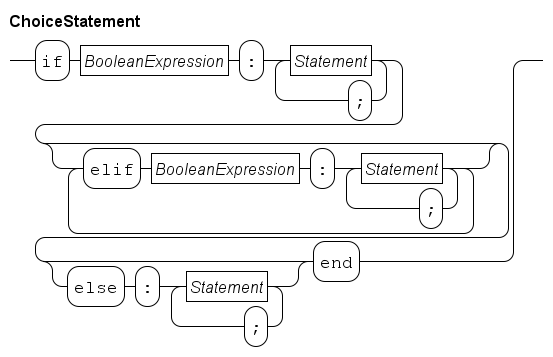
Processing starts with evaluating the BooleanExpression behind the if. If it evaluates to true, the statements behind it are executed, and the choice statement ends.
If the boolean expression behind the if does not hold, the sequence elif alternatives is tried. Starting from the first one, each boolean expression is evaluated. If it holds, the statements of that alternative are performed, and the choice statement ends. If the boolean expression does not hold, the next elif alternative is tried.
When there are no elif alternatives or when all boolean expressions of the elif alternatives do not hold, and there is an else alternative, the statements behind the else are executed and the choice statement ends. If there is no else alternative, the choice statement ends without choosing any alternative.
An example with just one alternative:
if x == 1:
x = 2
endwhich tests for x == 1. If it holds, x = 2 is performed, else no alternative is chosen.
An longer example with several alternatives:
if x == 1:
y = 5
elif x == 2:
y = 6; x = 6
else:
y = 7
endThis choice statement first tests whether x is equal to 1. If it is, the y = 5 statement is executed, and the choice statement finishes. If the first test fails, the test x == 2 is computed. If it holds, the statements y = 6; x = 6 are performed, and the choice statement ends. If the second test also fails, the y = 7 statement is performed.
The essential points of this statement are:
-
The choice is computed now, you cannot wait for a condition to become true.
-
Each alternative is tried from the top down, until the first expression that yields true.
The second point also implies that for an alternative to be chosen, the boolean expressions of all previous alternatives have to yield false.
In the above example, while executing the y = 7 alternative, you know that x is neither 1 nor 2.
Sub-process statements
The sub-process statements deal with creating and managing of new processes. The statement may only be used in Process definitions and Model definitions.

The RunStartStatement block creates new processes (see Run and start statements for details), while the FinishStatement waits for a process to end (further explanation at Finish statement).
Run and start statements
The run and start commands take a sequence of process instance as their argument.
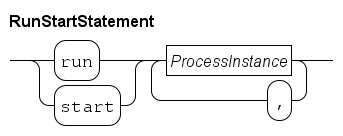
Both statements start all instances listed in the sequence. The start statement ends directly after starting the processes, while the run statement waits until all the started instances have ended. Using run is generally recommended for creating new processes.
A process instance has the following syntax.
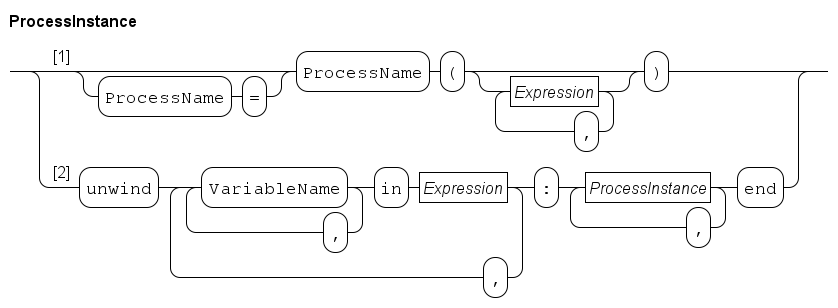
The elementary process instance is created using Path 1. It consists of a process name (which must be one of the names of the Process definitions), followed by a sequence of actual parameters for the process between parentheses. The number of actual parameters and their types must match pair-wise with the number and type of the formal parameters of the referenced process definition. Channel directions of the formal parameters must be a sub-set of the channel directions of the actual parameters.
The optional assignment of the process to a process variable (which must be of type inst, see Instance type) allows for checking whether the started process has ended, or for waiting on that condition in a select statement (explained in Select statement), or with a finish statement (explained in Finish statement).
For example:
chan c;
inst p, q;
run P(18, c), Q(19, c);
start p = P(18, c), q = Q(19, c);First two processes are completely run, namely the instances P(18, c), and Q(19, c). When both have ended, the start statement is executed, which starts the same processes, and assigned the P process instance to instance variable p and the Q process instance to variable q. After starting the processes, the start ends. Unless one of started processes has already ended, in the statement following the start, three processes are running, namely the process that executed the start statement, and the two started process instances referenced by variables p and q. (There may be more processes of course, created either before the above statements were executed, or the P or Q process may have created more processes.)
Path 2 of the ProcessInstance diagram is used to construct many new processes by means of an unwind loop. Each value in the Expression gets assigned to the iterator variable sequence of VariableName blocks (and this may be done several times as the syntax supports several Expression loops). For each combination of assignments, the process instances behind the colon are created. The end keyword denotes the end of the unwind.
Typical use of unwind is to start many similar processes, for example:
list int xs = [1, 2]
run
unwind i in range(5),
j in range(3),
x in xs: P(i, j, x)
end;This run statement runs 5*3*2 processes: P(0, 0, 1), P(0, 0, 2), P(0, 1, 1), …, P(0, 2, 2), P(1, 0, 1), …, P(4, 2, 2).
Both the run and the start statements can always instantiate new processes that have no exit type specified. (see Process definitions for details about exit types in process definitions). If the definition containing the sub-process statement has an exit type, the statements can also instantiate processes with the same exit type.
This requirement ensures that all exit statements in a model simulation give exit values of the same type.
Finish statement
The finish statement allows waiting for the end of a process instance. The statement may only be used in Process definitions and Model definitions. Its syntax is as follows.
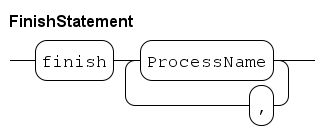
Each process variable must be of type inst (see Instance type for details). The statement ends when all referenced process instances have ended. For example:
chan bool c;
inst p, q;
start p = P(18, c), q = Q(19, c);
finish p, q;During the start statement (see Run and start statements), instance variables p and q get a process instance assigned (this may also happen in different start statements). The finish statement waits until both process instances have ended.
Communication statements
Communication with another process is the only means to forward information from one process to another processes, making it the primary means to create co-operating processes in the modeled system. The statement may only be used in Process definitions and Model definitions.
All communication is point-to-point (from one sender to one receiver) and synchronous (send and receive occur together). A communication often exchanges a message (a value), but communication without exchange of data is also possible (like waving 'hi' to someone else, the information being sent is 'I am here', but that information is already implied by the communication itself). The latter form of communication is called synchronization.
Send and receive does not specify the remote process directly, instead a channel is used (see Channel type and Channel expressions sections for more informations about channels and how to create them). Using a channel increases flexibility, the same channel can be used by several processes (allowing communication with one of them). Channels can also be created and exchanged during execution, for even more flexibility.
Setting up a communication channel between two processes is often done in the following way:
chan void sync; # Synchronization channel
chan int dch; # Channel with integer number messages
run P(sync, dch), Q(sync, dch);In a parent process, two channels are created, a synchronization channel sync, and a communication channel with data called dch. The channel values are given to processes P and Q through their formal parameters.
The communication statements are as follows.
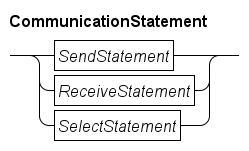
The elementary communication statements for sending and receiving at a single channel are the Send statement and the Receive statement. The Select statement is used for monitoring several channels and conditions at the same time, until at least one of them becomes available.
Send statement
The send statement send signals or data away through a channel. The statement may only be used in Process definitions and Model definitions. It has the following syntax:
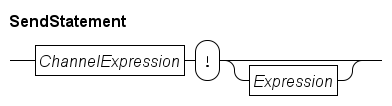
The statement takes a channel value (derived from ChannelExpression), and waits until another process can receive on the same channel. When that happens, and the channel is a synchronization channel, a signal 'Communication has occurred' is being sent, if the channel also carries data, the Expression value is computed and sent to the other process. For example:
proc P(chan void a, chan! int b):
a!;
b!21;
endProcess P takes two parameters, a synchronization channel locally called a and a outgoing channel called b carrying integer values. In the process body, it first synchronizes over the channel stored in a, and then sends the value 21 of the channel stored in b.
Receive statement
The receive statement receives signals or data from a channel. The statement may only be used in Process definitions and Model definitions. It has the following syntax:
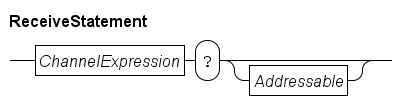
The statement takes a channel value (derived from the ChannelExpression), and waits until another process can send on the same channel. For synchronization channels, it receives just a signal that the communication has occurred, for channels carrying data, the data value is received and stored in the variable indicated by Addressable. For example:
proc Q(chan void a, chan int b):
int x;
a?;
b?x;
writeln("%s", x);
endProcess Q takes a synchronization channel called a and a data channel for integer values called b as parameters. The process first waits for a synchronization over channel a, and then waits for receiving an integer value over channel b which is stored in local variable x.
Select statement
The Send statement and the Receive statement wait for communication over a single channel. In some cases, it is unknown which channel will be ready first. Additionally, there may be time-dependent internal activities that must be monitored as well. The select statement is the general purpose solution for such cases. The statement may only be used in Process definitions and Model definitions.
It has the following syntax:
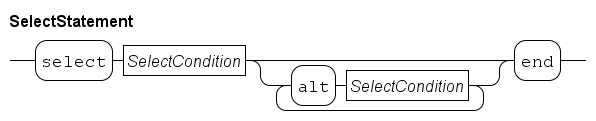
The statement has one or more SelectCondition alternatives that are all monitored. The first alternative is prefixed with select to denote it is a the start of a select statement, the other alternatives each start with alt (which is an abbreviation of 'alternative').
The statement monitors all conditions simultaneously, waiting for at least one to become possible. At that moment, one of the conditions is selected to be executed, and the select statement ends.
The syntax of a SelectCondition is:
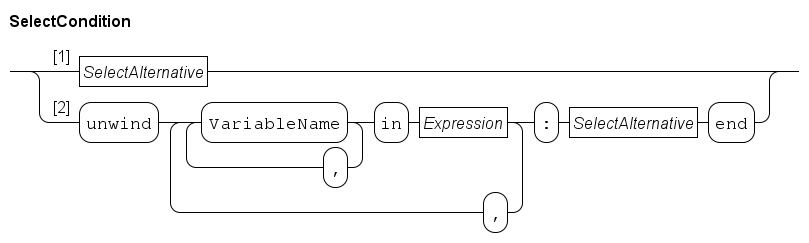
In its simplest form, a SelectCondition is a SelectAlternative (taking Path 1). At Path 2, the condition is eventually also an SelectAlternative, but prefixed with an unwind construct, and with an additional end keyword at the end to terminate the unwind.
The unwind construct allows for a compact notation of a large number of alternatives that must be monitored. Examples are provided below.
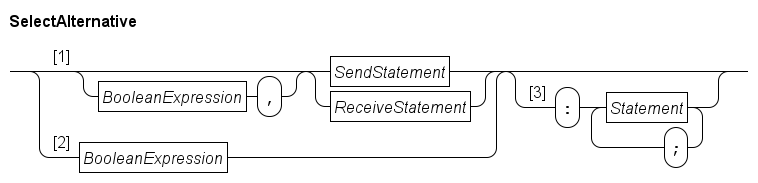
Using Path 1, a SelectAlternative can be a Send statement or a Receive statement, which may optionally have a BooleanExpression condition prefix. Path 2 allows for a condition without a send or receive statement.
The alternative checks the condition and monitors the channel. If the condition holds and the channel has a communication partner, the alternative can be chosen by the select statement. (Of course, omitting a condition skips the check, and not specifying a send or receive statement skips monitoring of the channel.) When an alternative is chosen by the select statement, the send or receive statement are performed (if it was present). If additional statements were given in the alternative using Path 3, they are executed after the communication has occurred (if a send or receive was present).
A few examples to demonstrate use of the select statement:
timer t = timer(5.2);
select
a?
alt
b!7:
writeln("7 sent")
alt
ready(t):
writeln("done")
endThis select waits until it can receive a signal from channel a, it can send value 7 over channel b, or until ready(t) holds (which happens 5.2 time units after starting the select, see Timers for details). If b!7 was selected, the writeln("7 sent") is executed after the communication over channel b. If the ready(t) alternative is chosen, the writeln("done") is executed.
A buffer can be specified with:
list int xs;
int x;
select
a?x:
xs = xs + [x]
alt
not empty(xs), b!xs[0]:
xs = xs[1:]
endThe select either receives a value through channel a, or it sends the first element of list xs over channel b if the list is not empty (the condition must hold and the channel must be able to send an item at the same time to select the second alternative).
After communication has been performed, the first alternative appends the newly received value x to the list (the received value is stored in x before the assignment is executed). In the second alternative, the assignment statement drops the first element of the list (which just got sent away over channel b).
The unwind loop 'unwinds' alternatives, for example:
list(5) chan int cs;
int x;
select
unwind i, c in enumerate(cs):
c?x:
writeln("Received %s from channel number %d", x, i)
end
endHere cs is a list of channels, for example list(5) chan int cs. (See List type for details about lists.) The unwind iterates over the enumerate(cs) (see List expressions for details about enumerate), assigning the index and the channel to local i and c variables. The SelectAlternative uses the variables to express the actions to perform (wait for a receive, and output some text saying that a value has been received).
The above is equivalent to (if list cs has length 5):
select
cs[0]?x:
writeln("Received %s from channel number %d", x, 0)
alt
cs[1]?x:
writeln("Received %s from channel number %d", x, 1)
...
alt
cs[4]?x:
writeln("Received %s from channel number %d", x, 4)The unwind however works for any length of list cs. In addition, the unwind allows for nested loops to unfold for example list list bool ds, or to send one of several values over one of several channels.
Other statements
Finally, there are a number of other useful statements.
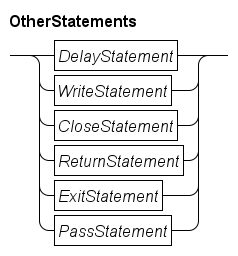
The Delay statement waits for the given amount of time units, the Write statement outputs text to the screen or a file, the Close statement closes a file, the Return statement returns a value from a function. the Exit statement ends the execution of all processes, and the Pass statement does nothing.
Delay statement
The delay statement is useful to wait some time. The statement may only be used in Process definitions and Model definitions. It has the following syntax:
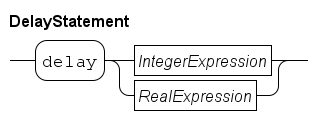
The IntegerExpression or RealExpression is evaluated, and is the amount of time that the statement waits. The value of the expression is computed only at the start, it is not evaluated while waiting. Changes in its value has thus no effect. A negative value ends the statement immediately, you cannot go back in time.
Examples:
delay 1.5 # Delay for 1.5 time units.Write statement
The write statement is used to output text to the screen or to a file. It has the following syntax:

The format string at 2 is a literal string value (further explained at String expressions) which defines what gets written. Its text is copied to the output, except for two types of patterns which are replaced before being copied. Use of the writeln (write line) keyword causes an additional \n to be written afterwards.
The first group of pattern are the back-slash patterns. They all start with the \ character, followed by another character that defines the character written to the output. The back-slash patterns are listed in the table below.
| Pattern | Replaced by |
|---|---|
|
|
The new-line character (U+000A) |
|
|
The tab character (U+0009) |
|
|
The double-quote character (U+0022) |
|
|
The back-slash character (U+005C) |
The second group of patterns are the percent patterns. Each percent pattern starts with a % character. It is (normally) replaced by the (formatted) value of a corresponding expression listed after the format string (the first expression is used as replacement for the first percent pattern, the second expression for the second pattern, etc). How the value is formatted depends on the format specifier, the first letter after the percent character. Between the percent character and the format specifier may be a format definition giving control on how the value is output.
The format definition consists of five parts, each part is optional.
-
A
-character, denoting alignment of the value to the left. Cannot be combined with a0, and needs a width. -
A
+character, denoting the value with always be printed with a sign, only for formatting decimal integers, and real numbers. -
A
0character, denoting the value will be prefixed with zeros, only for integer numbers. Cannot be combined with-, and needs a width. -
A width as decimal number, denoting the minimal amount of space used for the value. The value will be padded with space (or zeros if the
0part has been specified). -
A
.and a precision as decimal number, denoting the number of digits to use for the fraction, only for real numbers.
The format definition is a single letter, the table below lists them and their function.
| Definition | Description |
|---|---|
|
|
Output boolean value. |
|
|
Output integer value as decimal number. |
|
|
Output integer value as hexadecimal number. |
|
|
Output real value as number with a fraction. |
|
|
Output real value in exponential notation. |
|
|
Output real value either as |
|
|
Output value as a string (works for every printable value) |
|
|
Output a |
Close statement
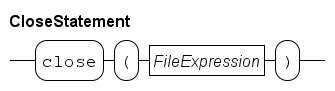
The close statement takes a value of type file as argument (see File type for details about the file type). It closes the given file, which means that the file is no longer available for read or write. In case data was previously written to the file, the close statement ensures that the data ends up in the file itself.
Note that a close of a file is global in the system, none of the processes can use the file any longer.
In Reading from a file and Writing to a file, use of the close statement is shown.
Return statement
The return statement may only be used in a Function definitions. It has the following syntax:
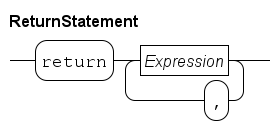
The statement starts with a return keyword, followed by one or more (comma-separated) expressions that form the value to return to the caller of the function.
The value of the expressions are calculated, and combined to a single return value. The type of the value must match with the return type of the function. Execution of the function statements stops (even when inside a loop or in an alternative of an if statement), and the computed value is returned to the caller of the function.
Examples:
return 4 # Return integer value 4 to the caller.
return true, 3.7 # Return value of type tuple(bool b; real r).Exit statement
The exit statement may only be used in Process definitions and Model definitions. It has the following syntax:
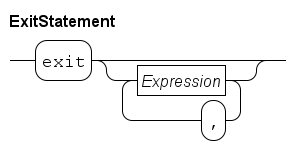
The exit statement allows for immediately stopping the current model simulation. The statement may be used in Process definitions and Model definitions. If arguments are provided, they become the exit value of the model simulation. Such values can be processed further in an Simulating several scenarios, see also Experiment definitions on how to run a model in an experiment.
The type of the combined arguments must match with the exit type of the process or model that uses the statement. If no arguments are given, the exit type must be a void type (see also Void type).
If an experiment is running, execution continues by returning from the model instantiation call. Otherwise, the simulation as a whole is terminated.
Pass statement
The pass statement does nothing. Its purpose is to act as a place holder for a statement at a point where there is nothing useful to do (for example to make an empty process), or to explicitly state nothing is being done at some point:
if x == 3:
pass
else:
x = x + 1
endHere, pass is used to explicitly state that nothing is done when x == 3. Such cases are often a matter of style, usually it is possible to rewrite the code and eliminate the pass statement.