Benchmarks#
This page gathers benchmark results produced by Aidge exports on embedded and edge targets. The goal is not only to report numbers, but to show the kind of deployment trade-offs Aidge can make visible.
Using FP32 is the starting point when bringing a model to a new target: it preserves the original numerical behavior and makes the first export straightforward to inspect. On microcontrollers, however, FP32 is rarely the best final deployment format. Embedded systems have tight memory budgets, limited cache, lower memory bandwidth, and less floating-point throughput than desktop or server platforms. A model that is comfortable in FP32 on a workstation can become too large, too slow, or too energy hungry once it runs on a microcontroller.
Aidge therefore supports quantized deployments. Quantization stores and computes values with smaller integer formats, typically int8, which can reduce memory use and unlock faster integer kernels.
Below, we have gathered a few benchmark results on the following targets:
Target |
Description |
|---|---|

|
STM32H743
|

|
Raspberry Pi 4 Model B
|

|
NVIDIA Jetson Nano
|

|
NVIDIA Jetson AGX Xavier
|
This is possible thanks to Aidge’s feature of on-board benchmarking and reporting, which generates detailed performance and accuracy metrics as part of the export process. These results show how Aidge can help you quantize and optimize your model for embedded deployment, while maintaining near the same accuracy as the original FP32 model.
Aidge can also select different compute kernels for the exported network.
The arm kernel shown in several benchmarks is an Aidge kernel that
optimizes selected calculations with vector instructions. Aidge also
supports CMSIS kernels, developed by Arm for Arm microcontrollers. This
lets the same model be evaluated across different implementation paths,
which is especially useful when choosing the fastest or most portable
backend for a product.
How to Read the Results
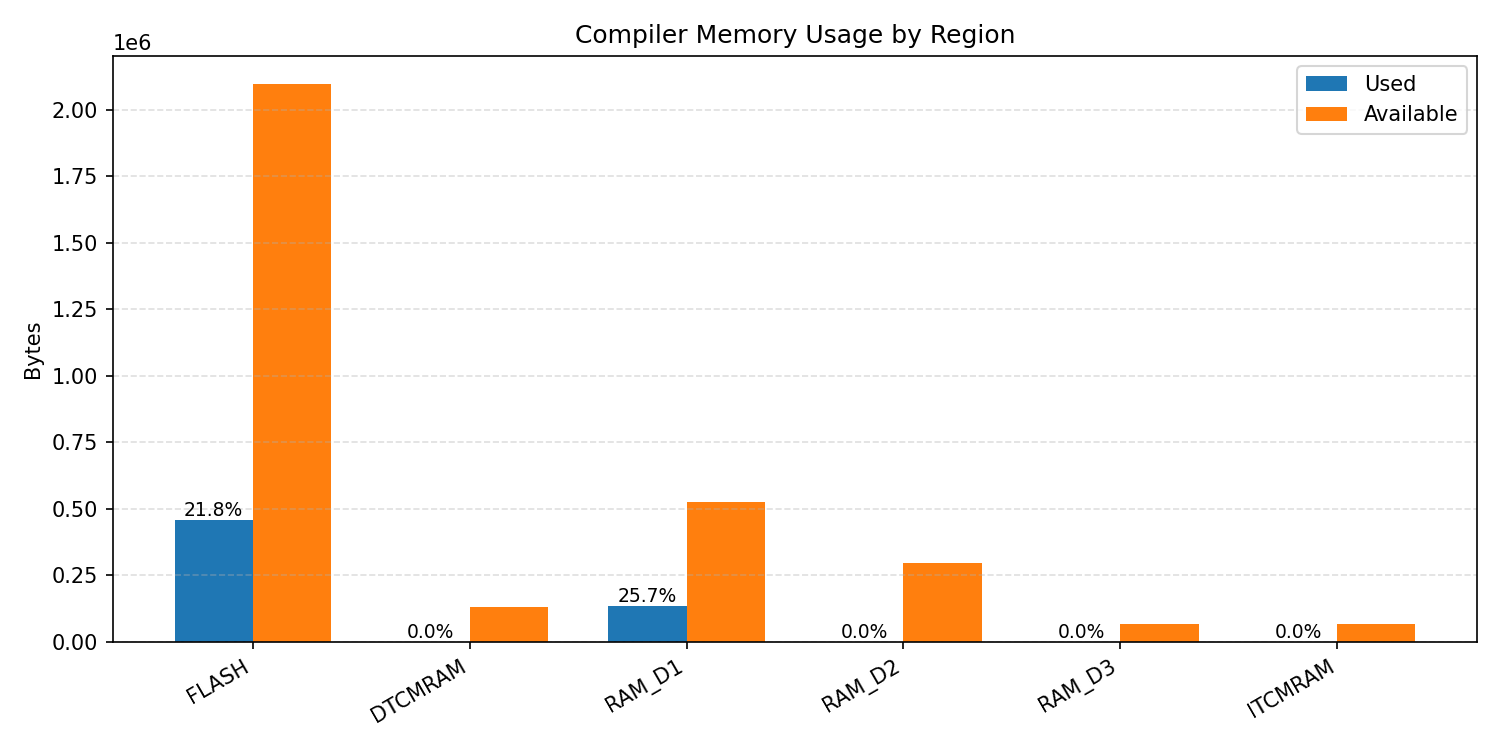
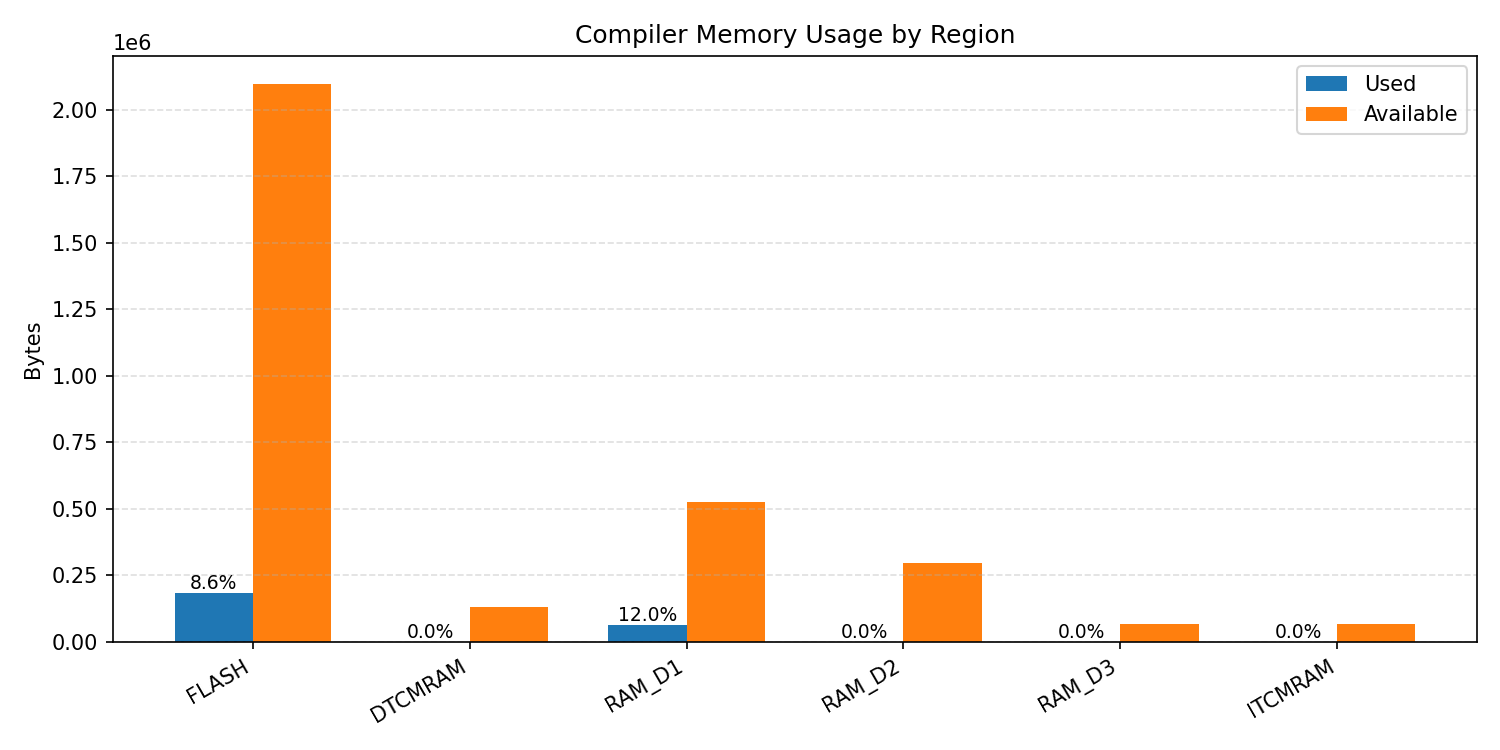
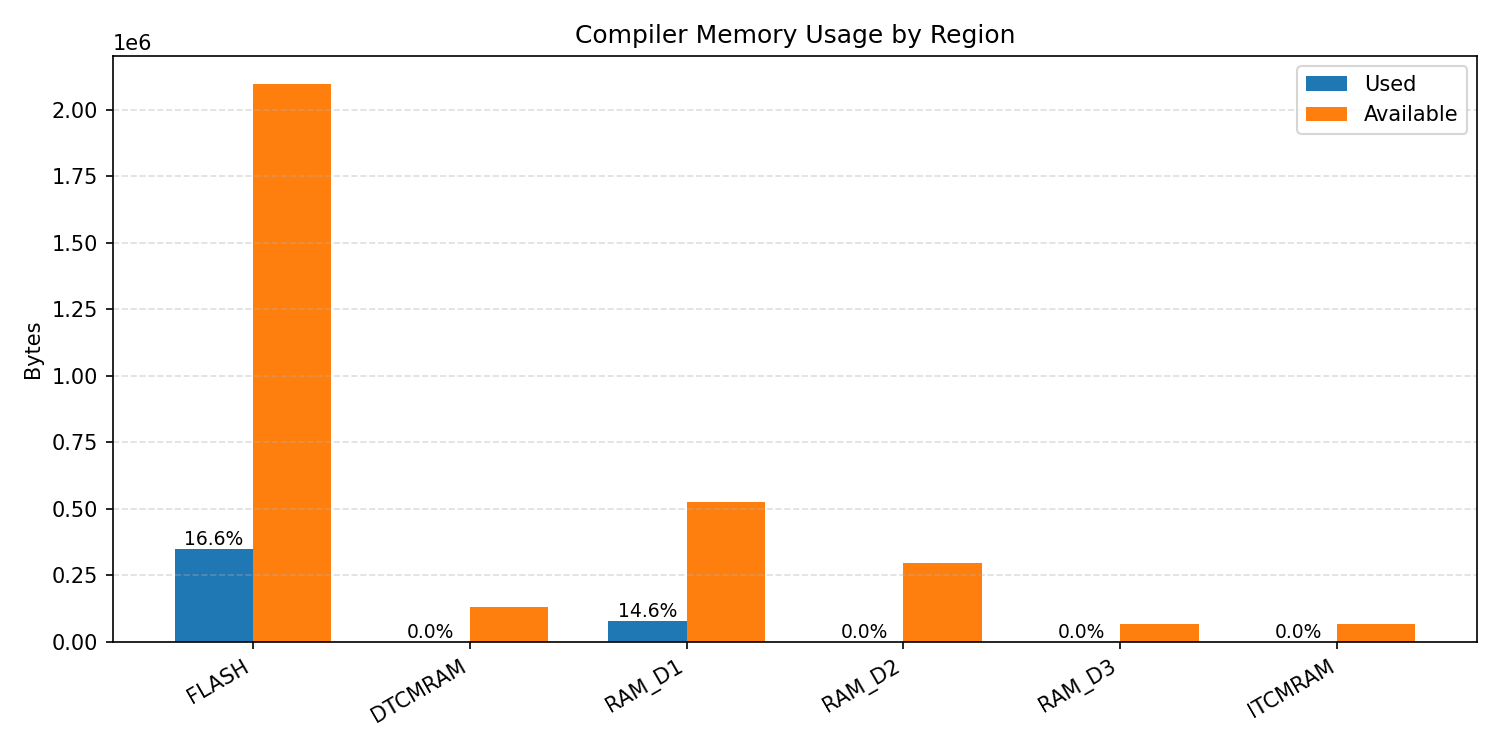
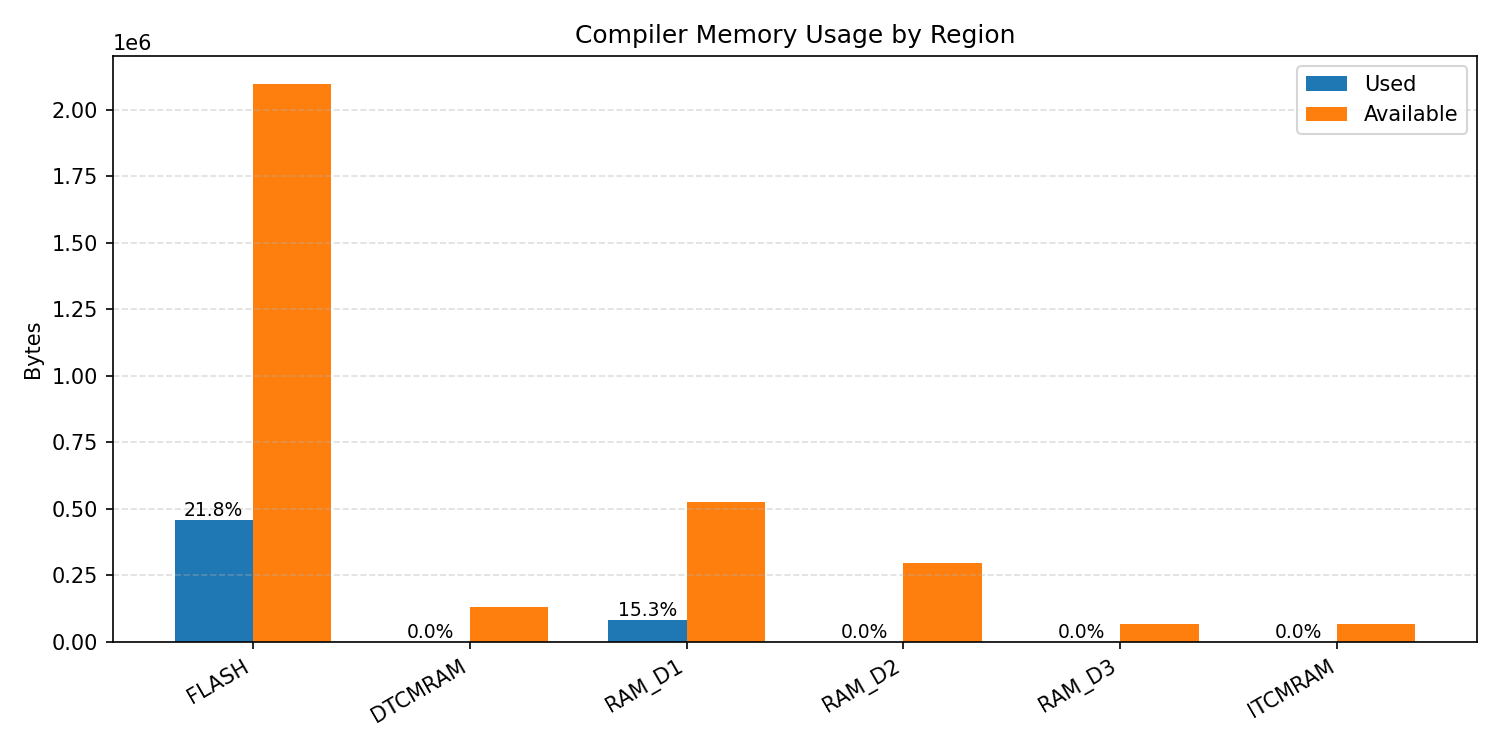
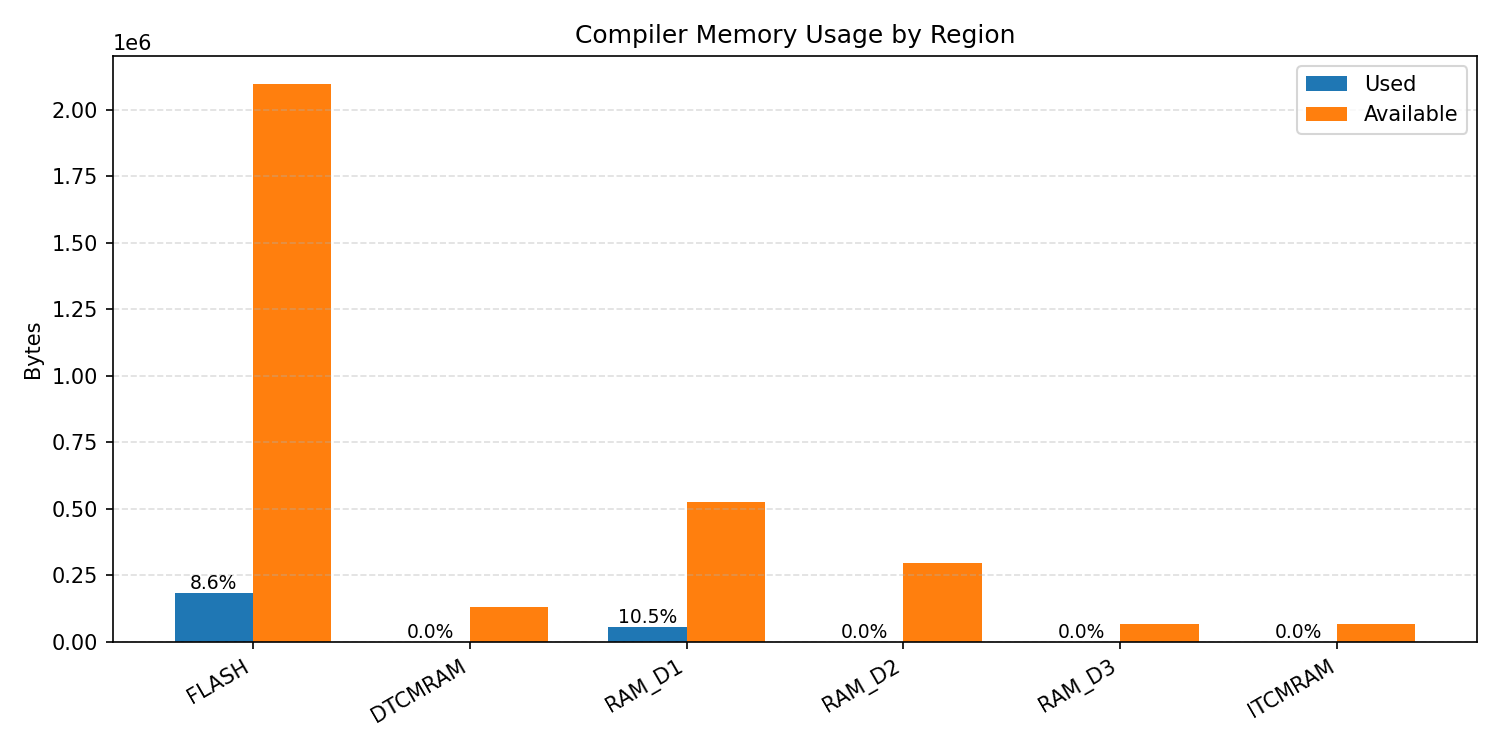
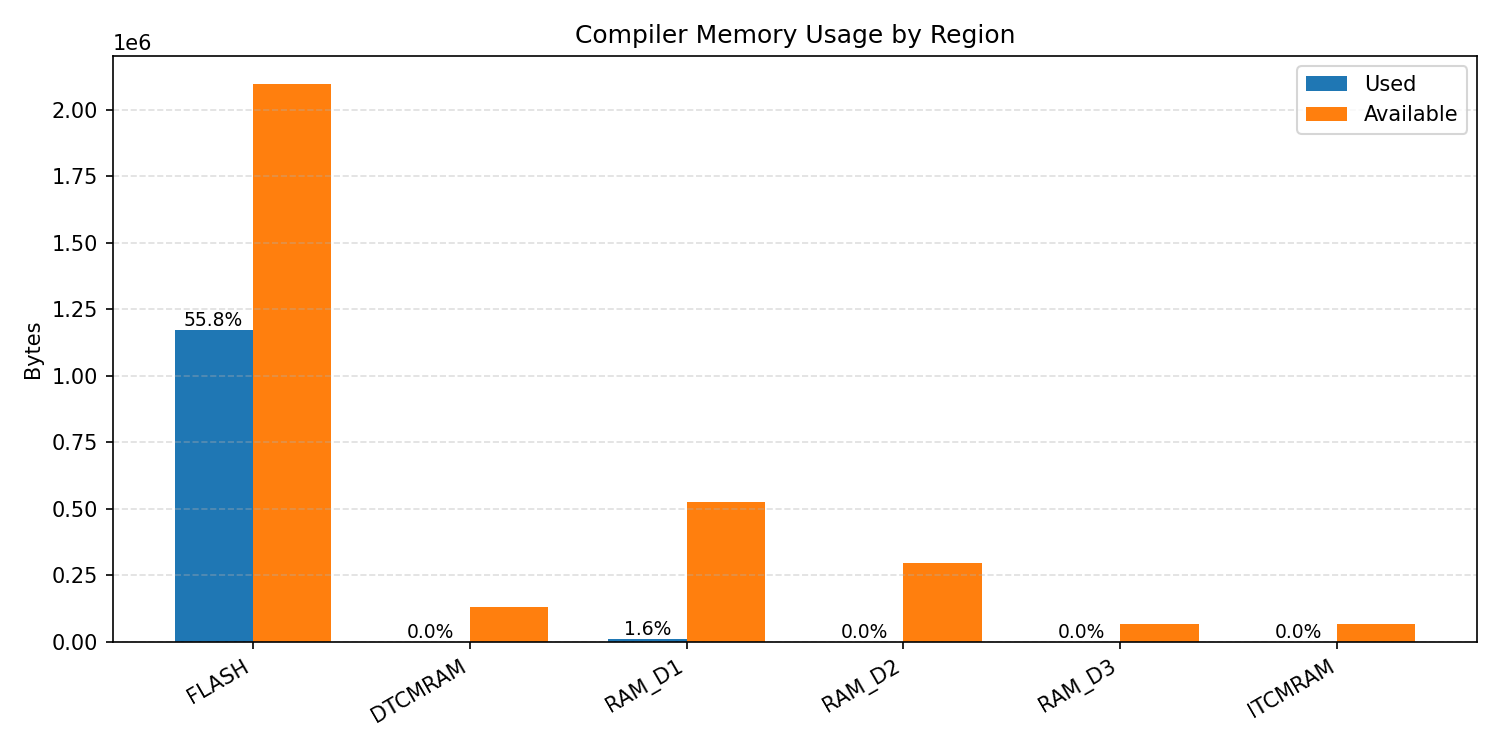
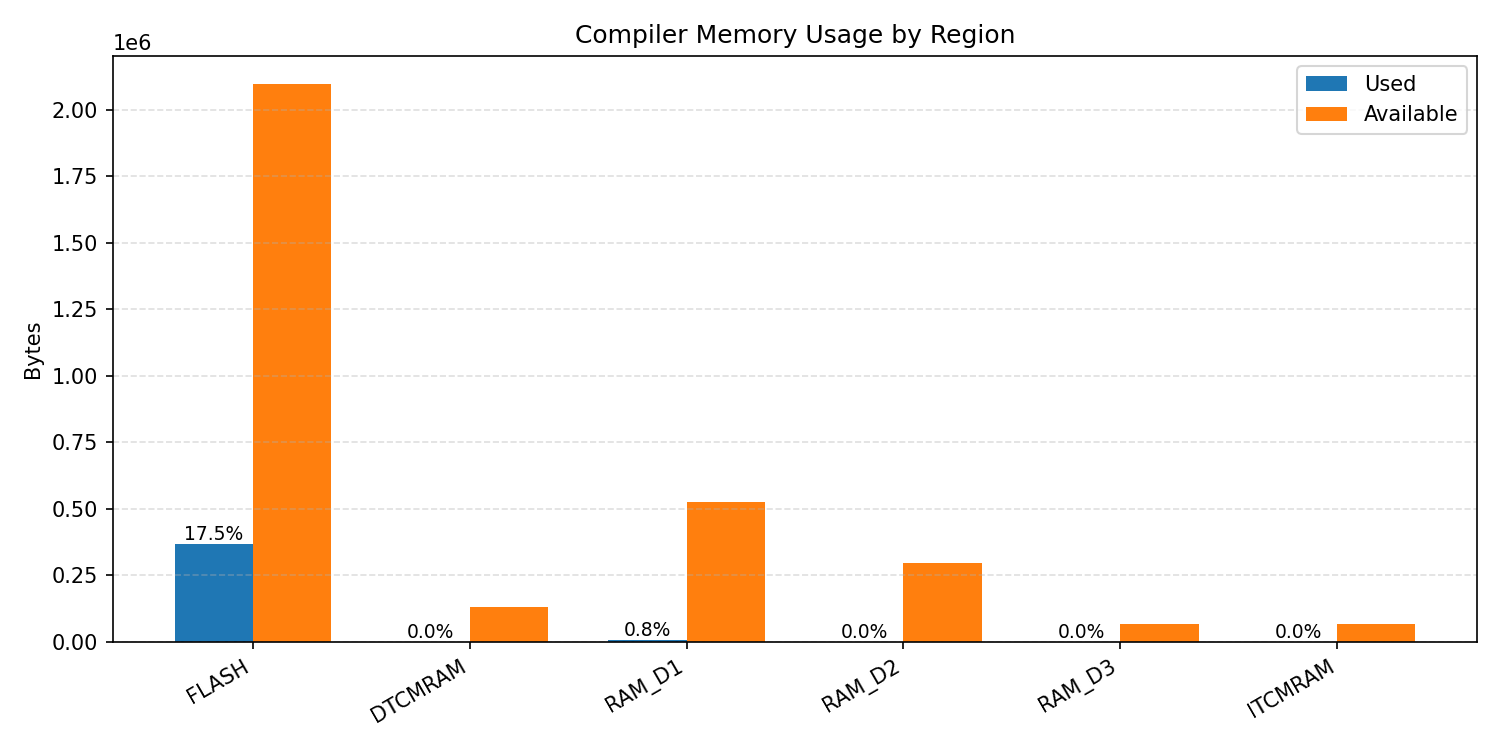
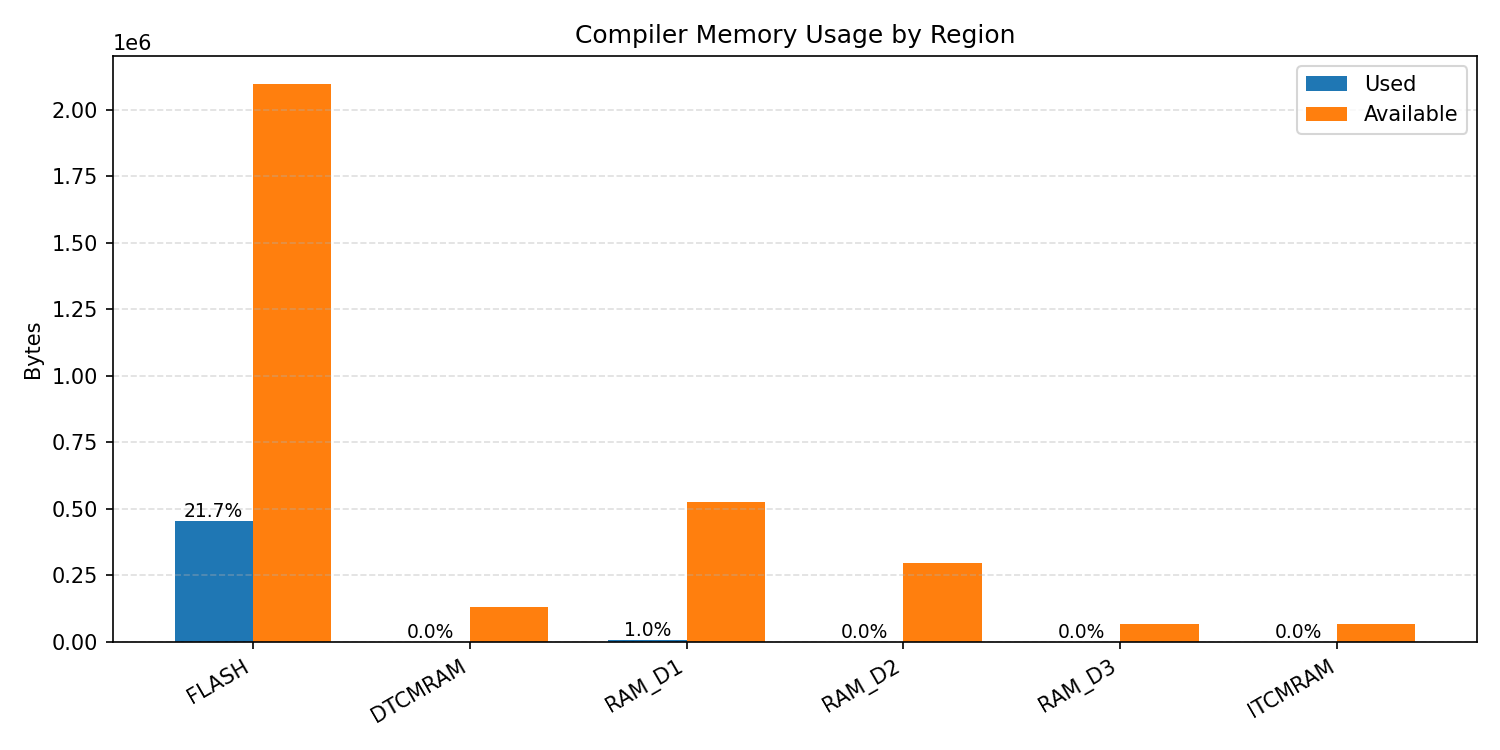
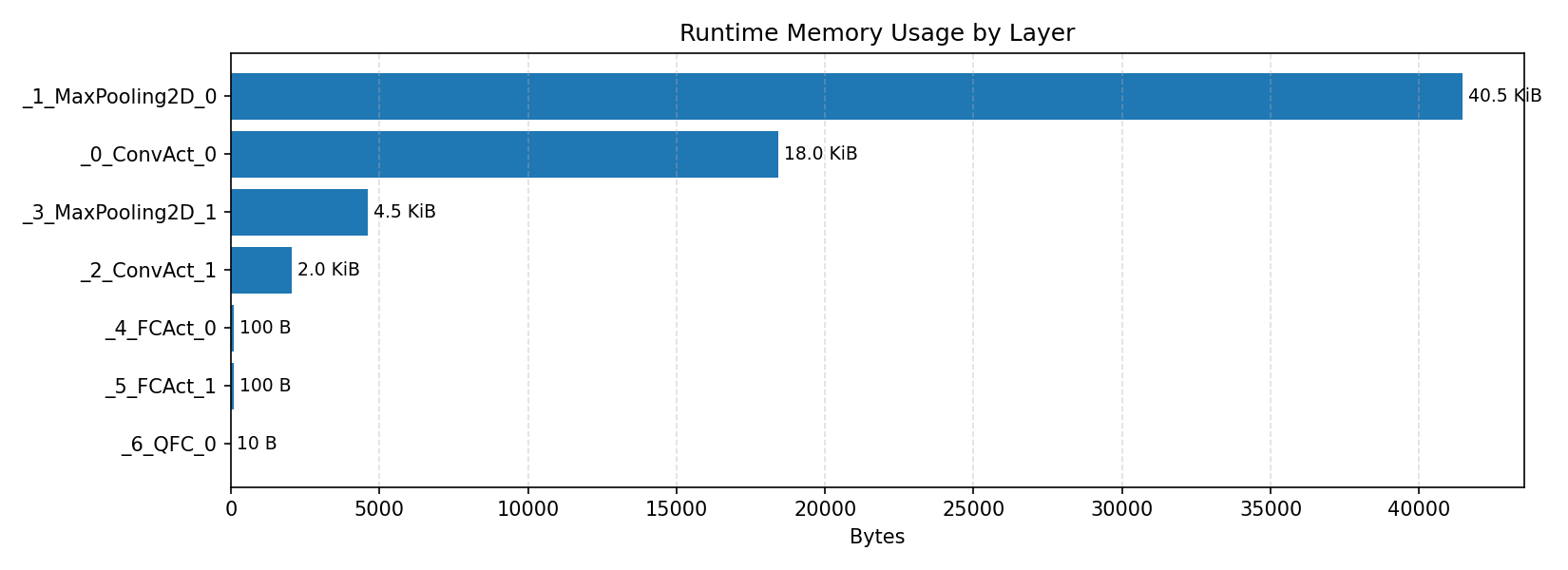
Compiler memory usage shows whether the generated application fits into target memory regions.
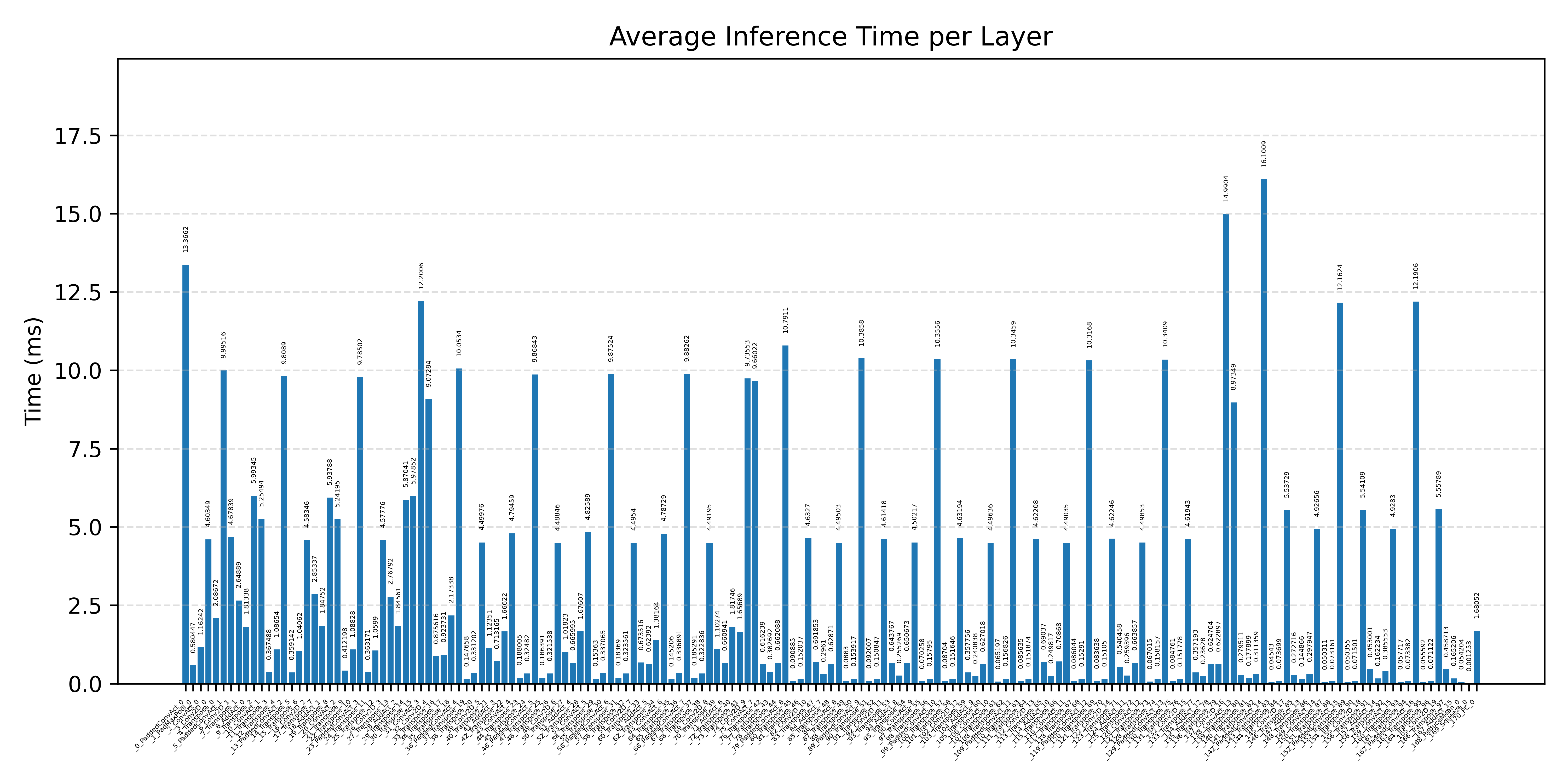
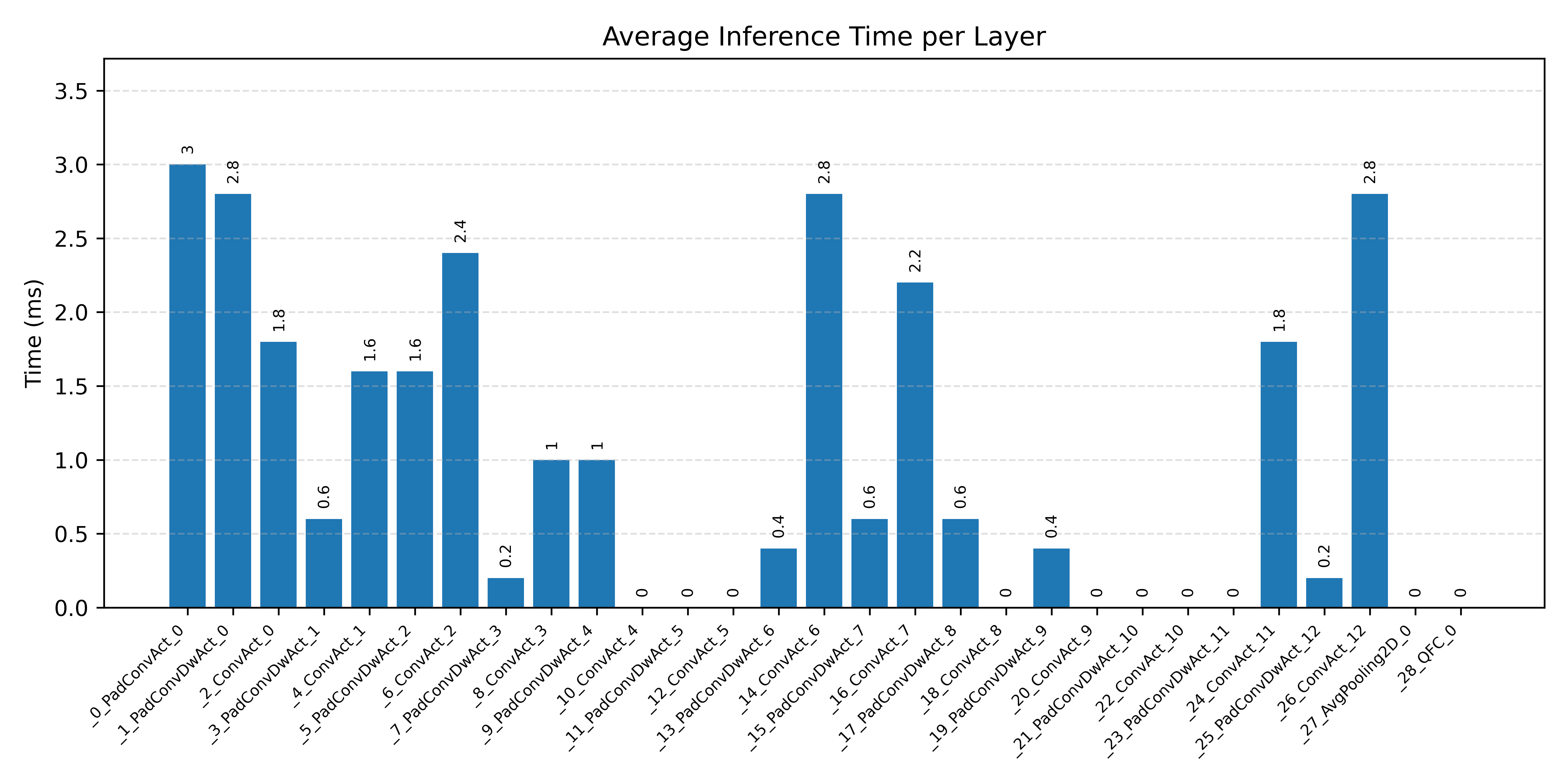
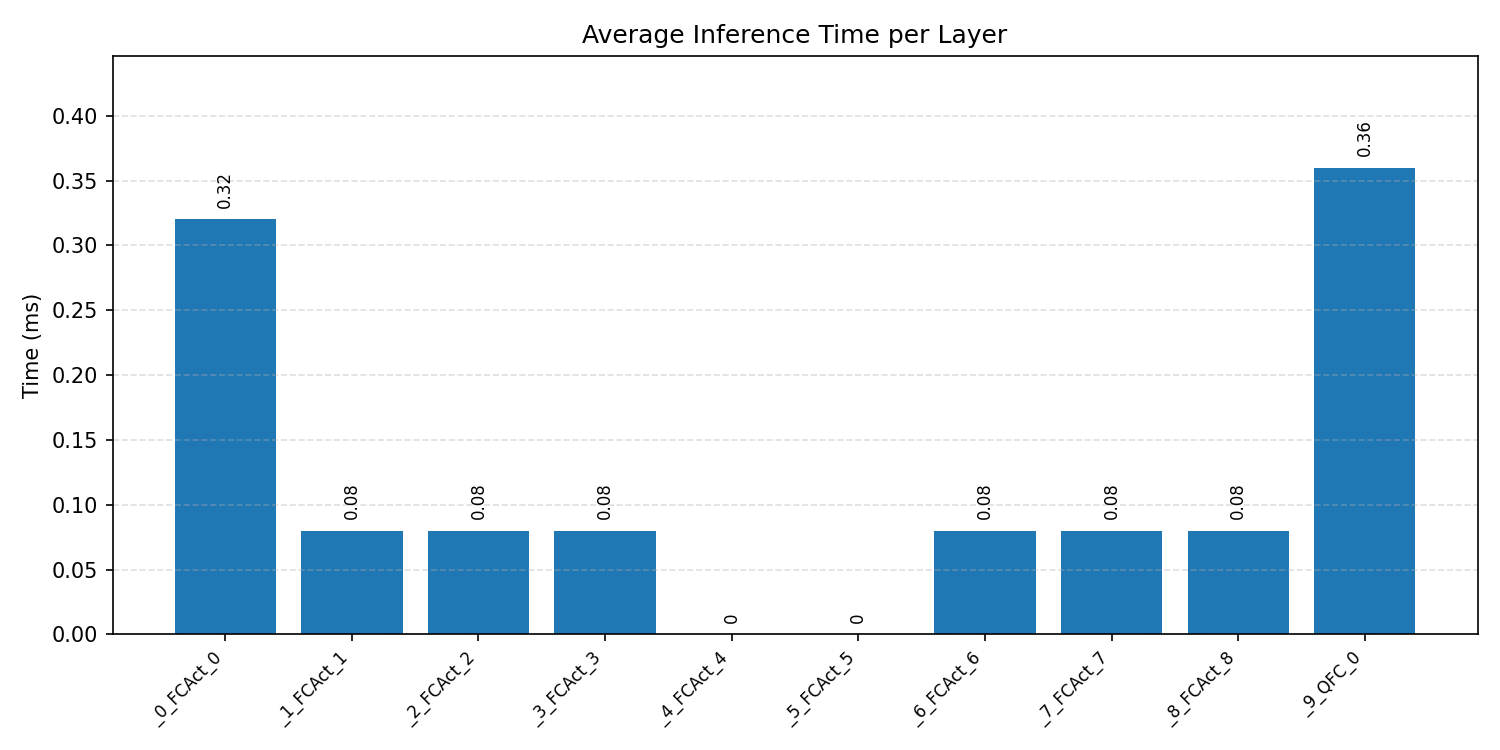
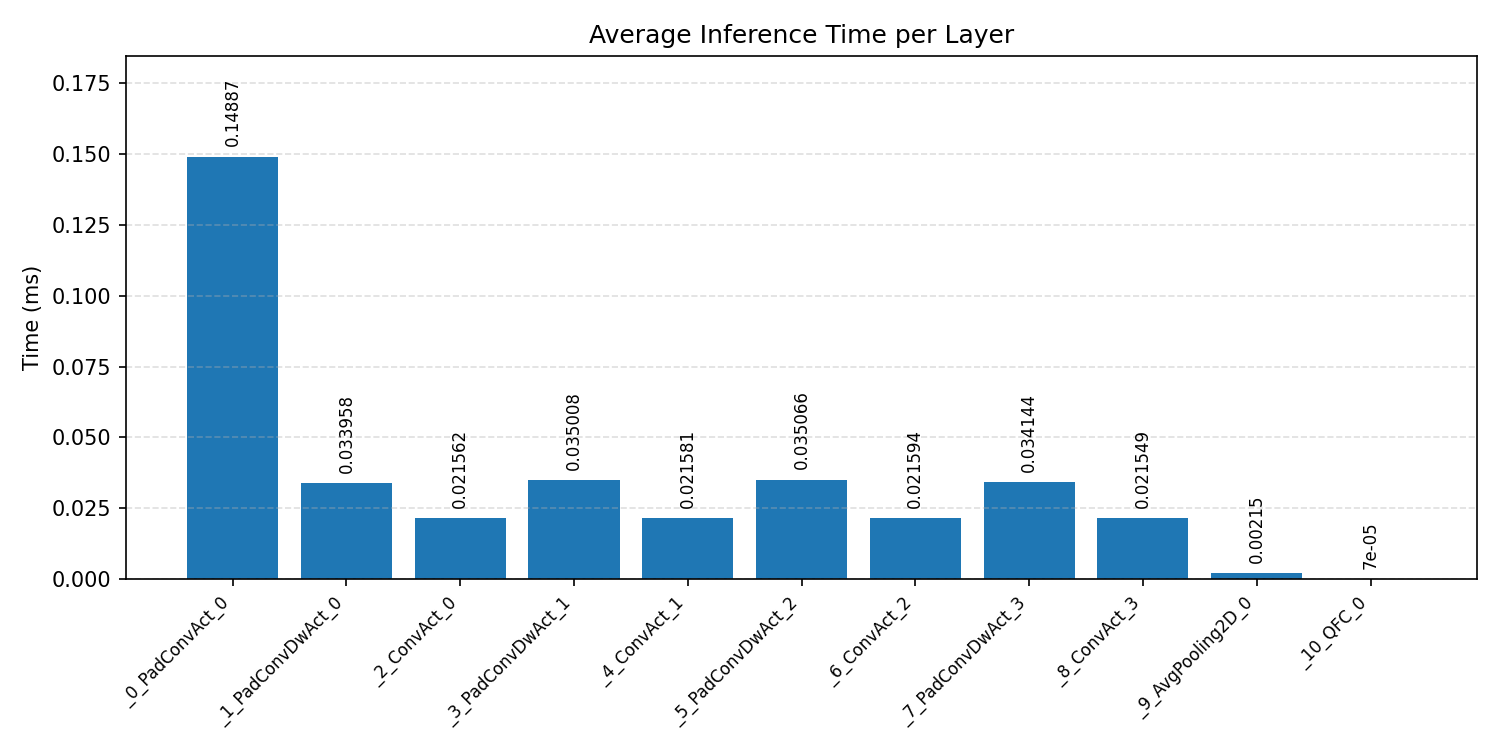
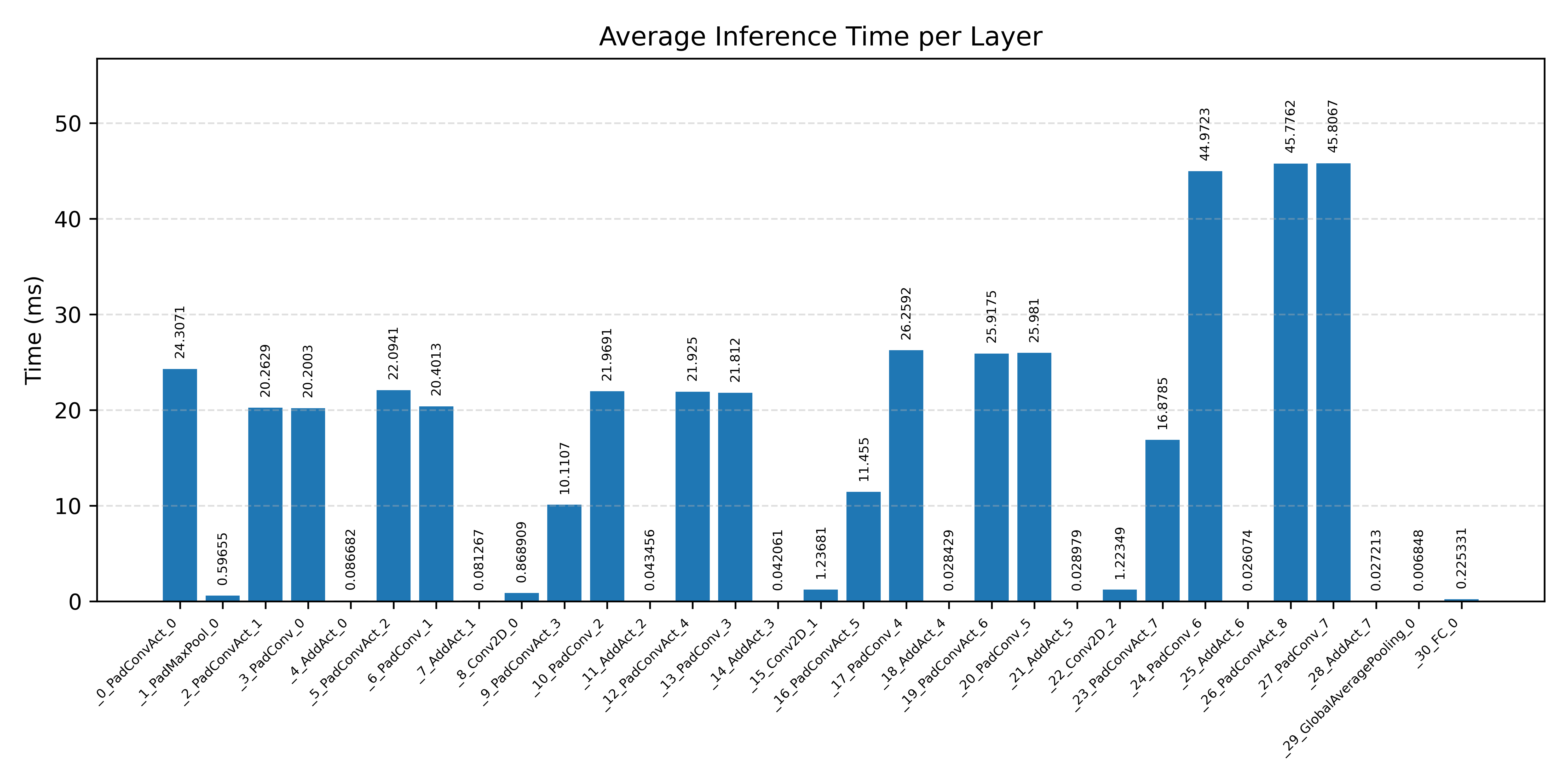
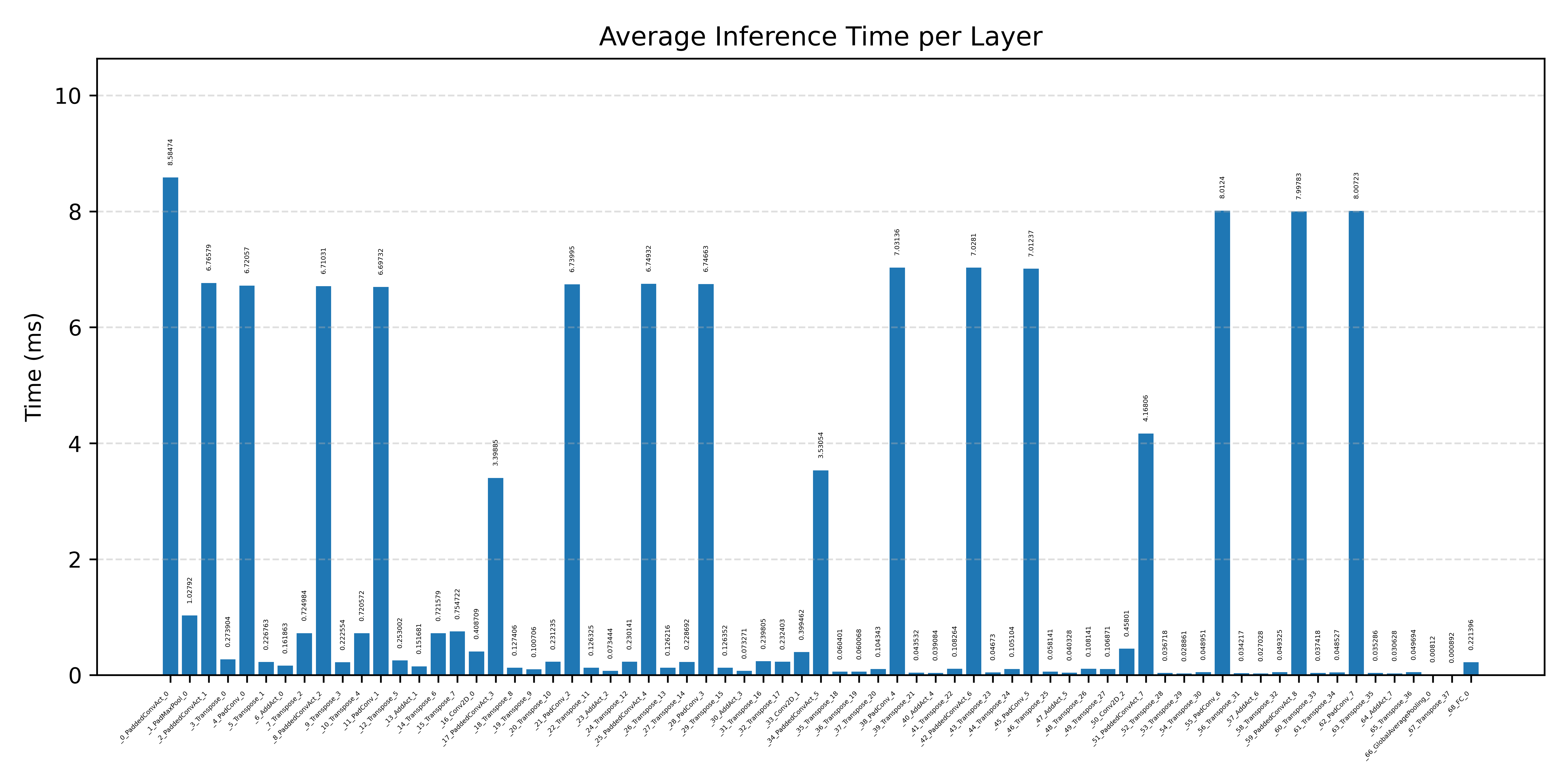
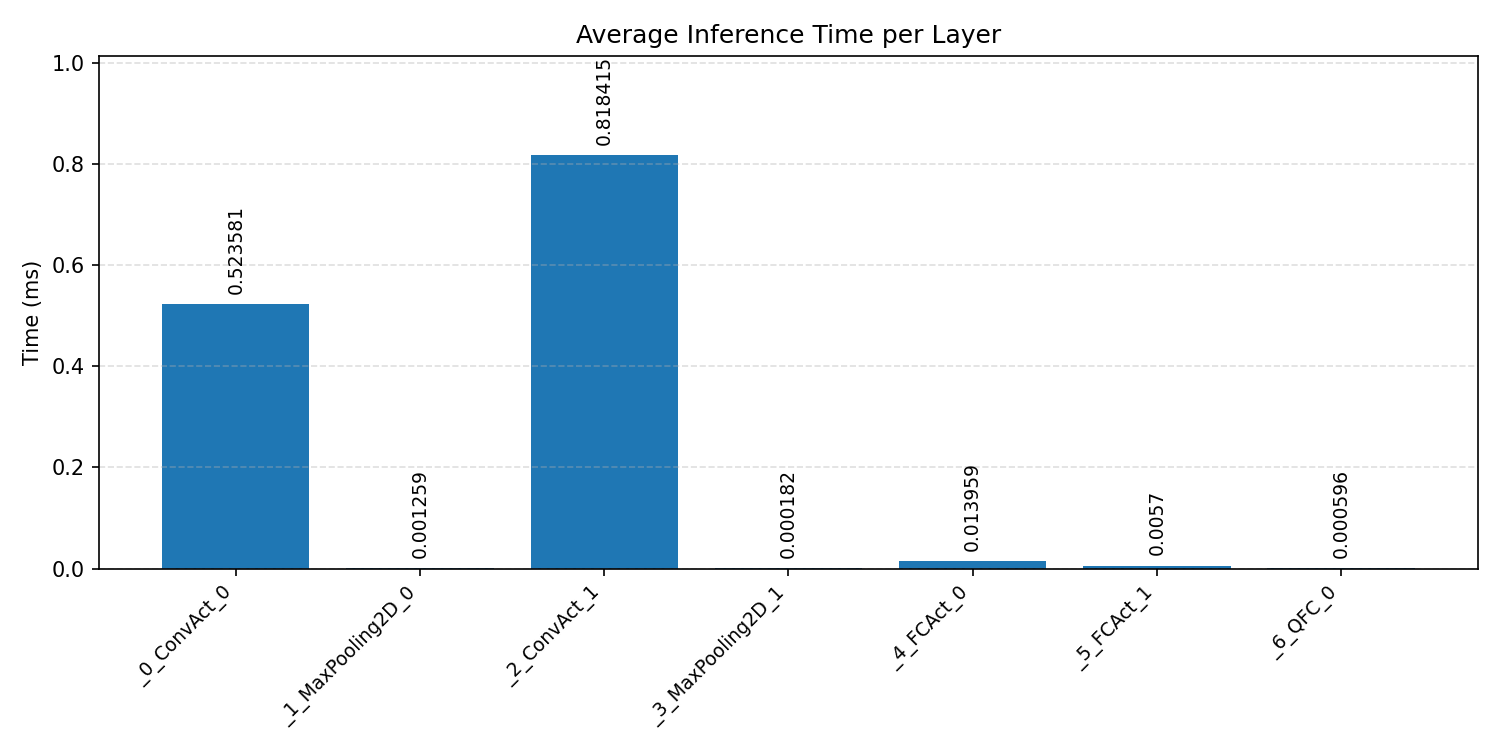
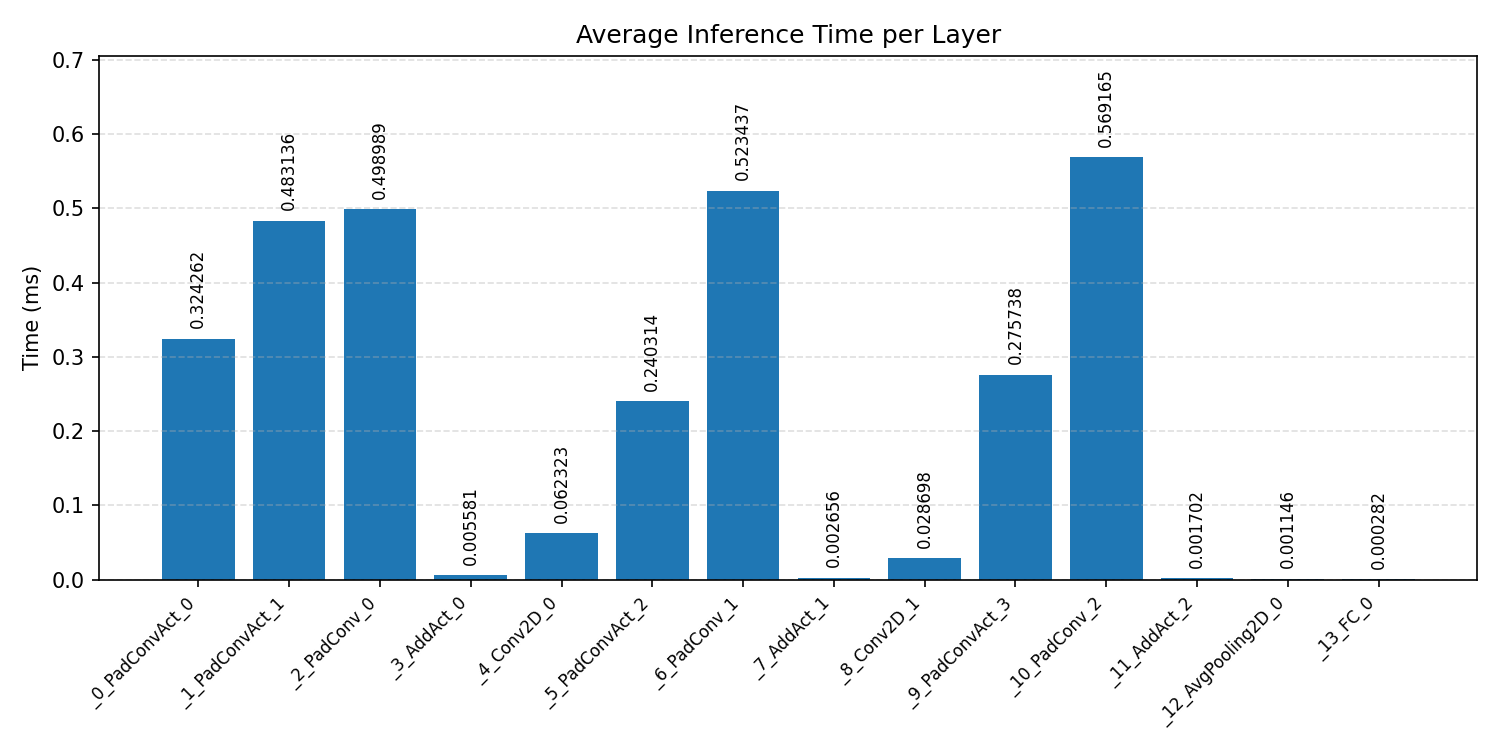
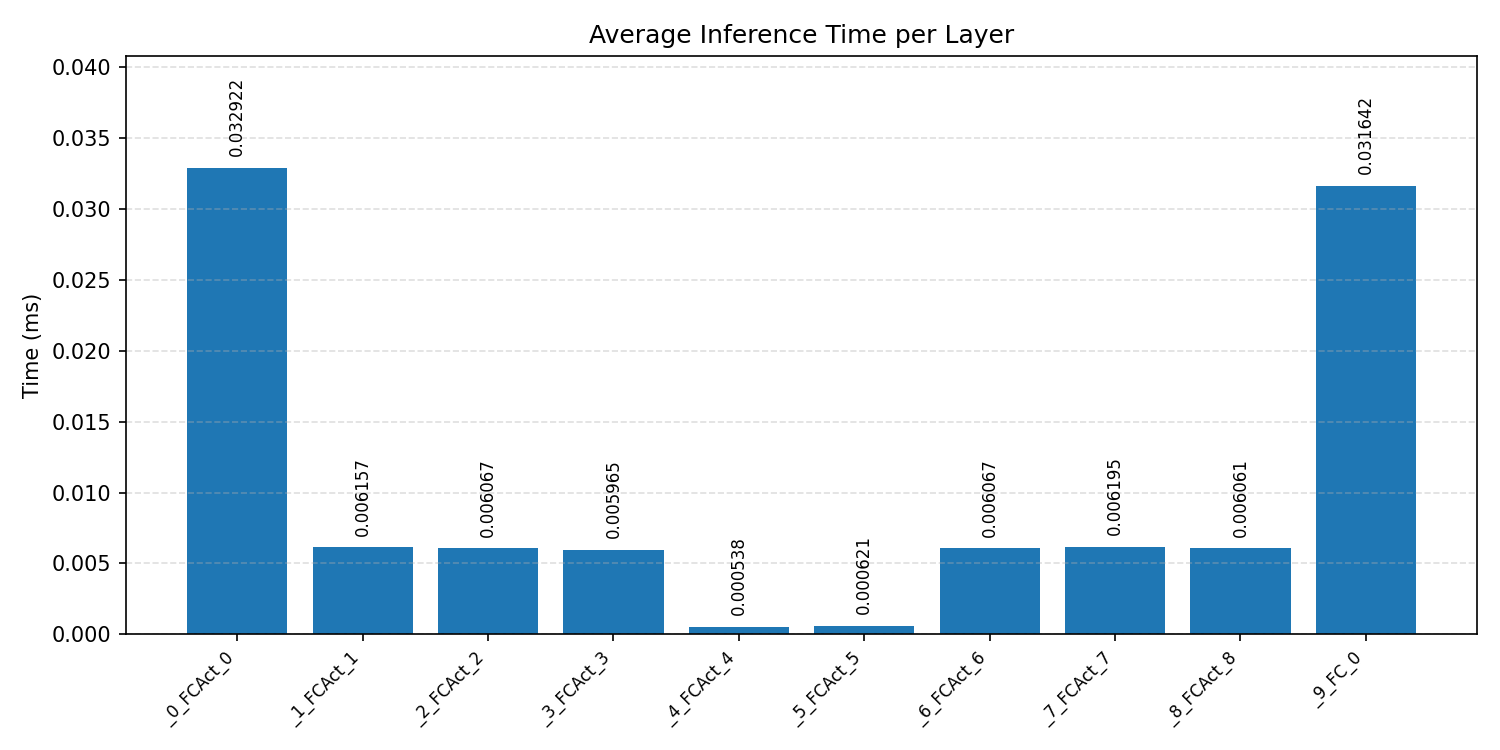
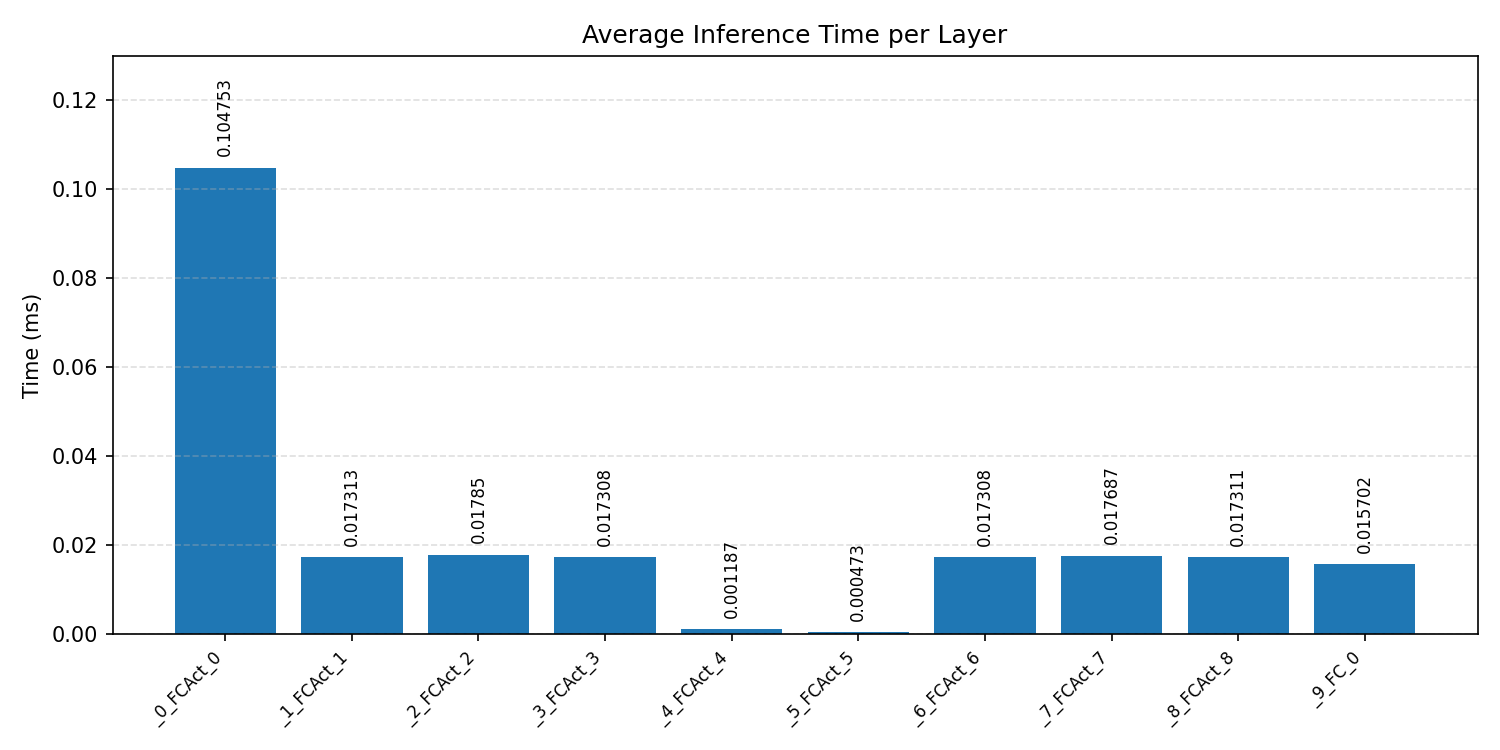
Layer timings and layer cycles identify the operators that drive latency and reveal where kernel selection matters most.
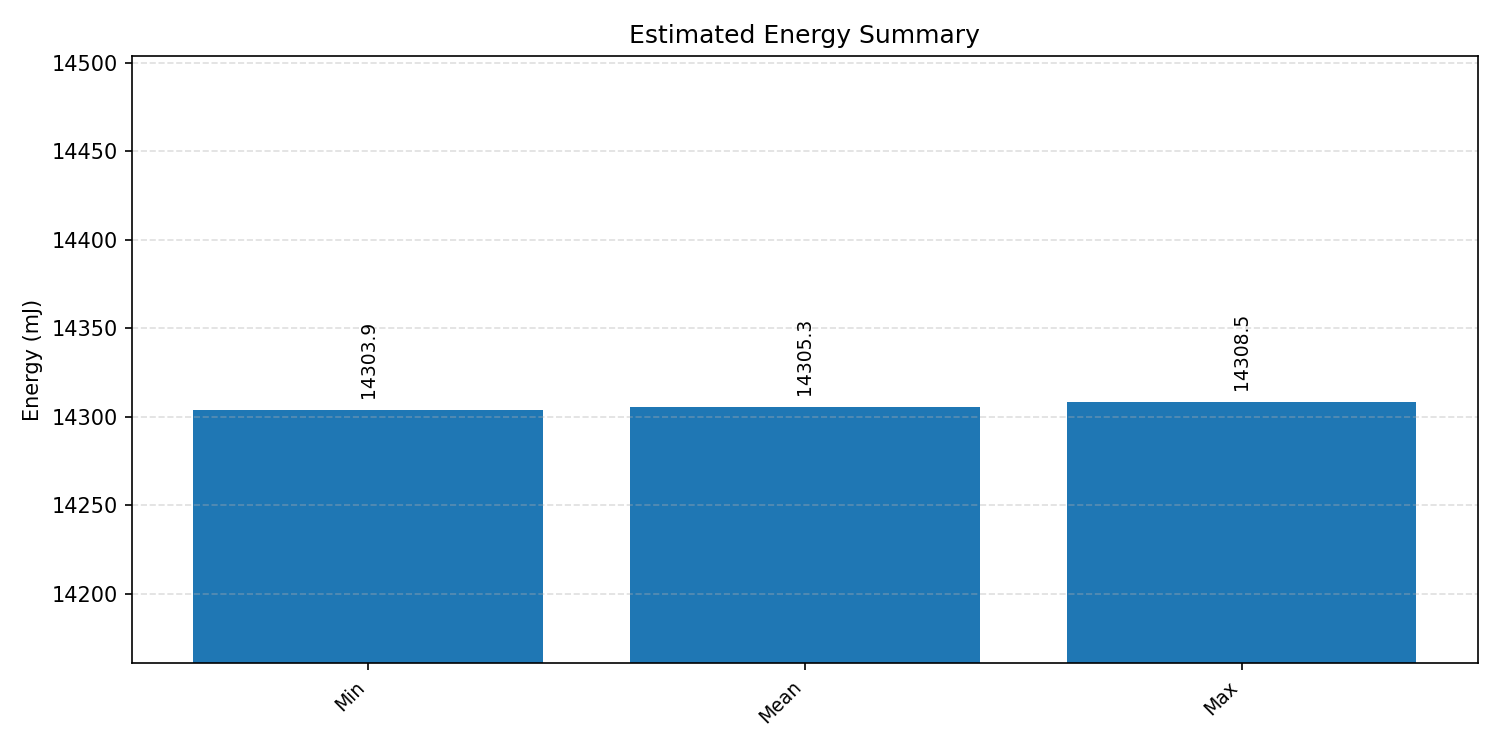
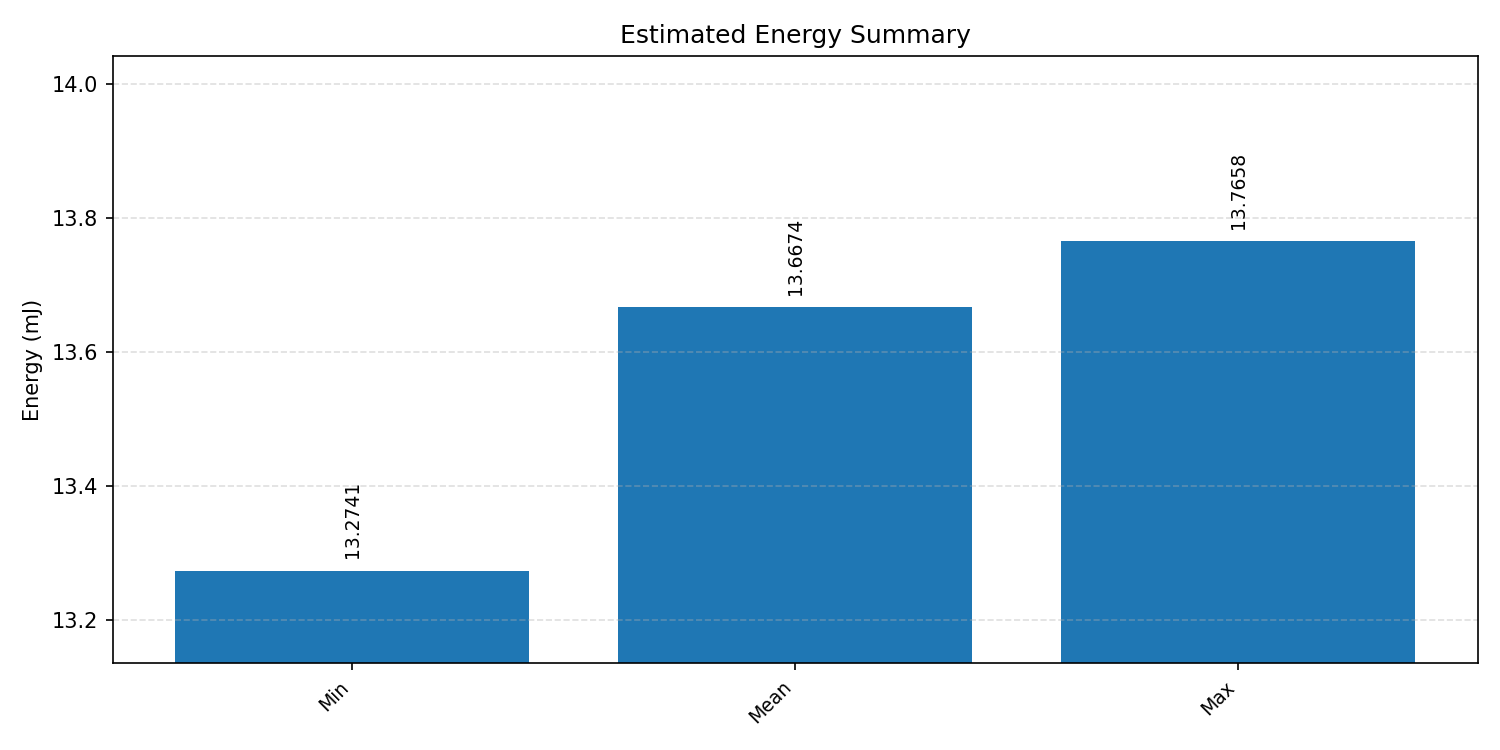
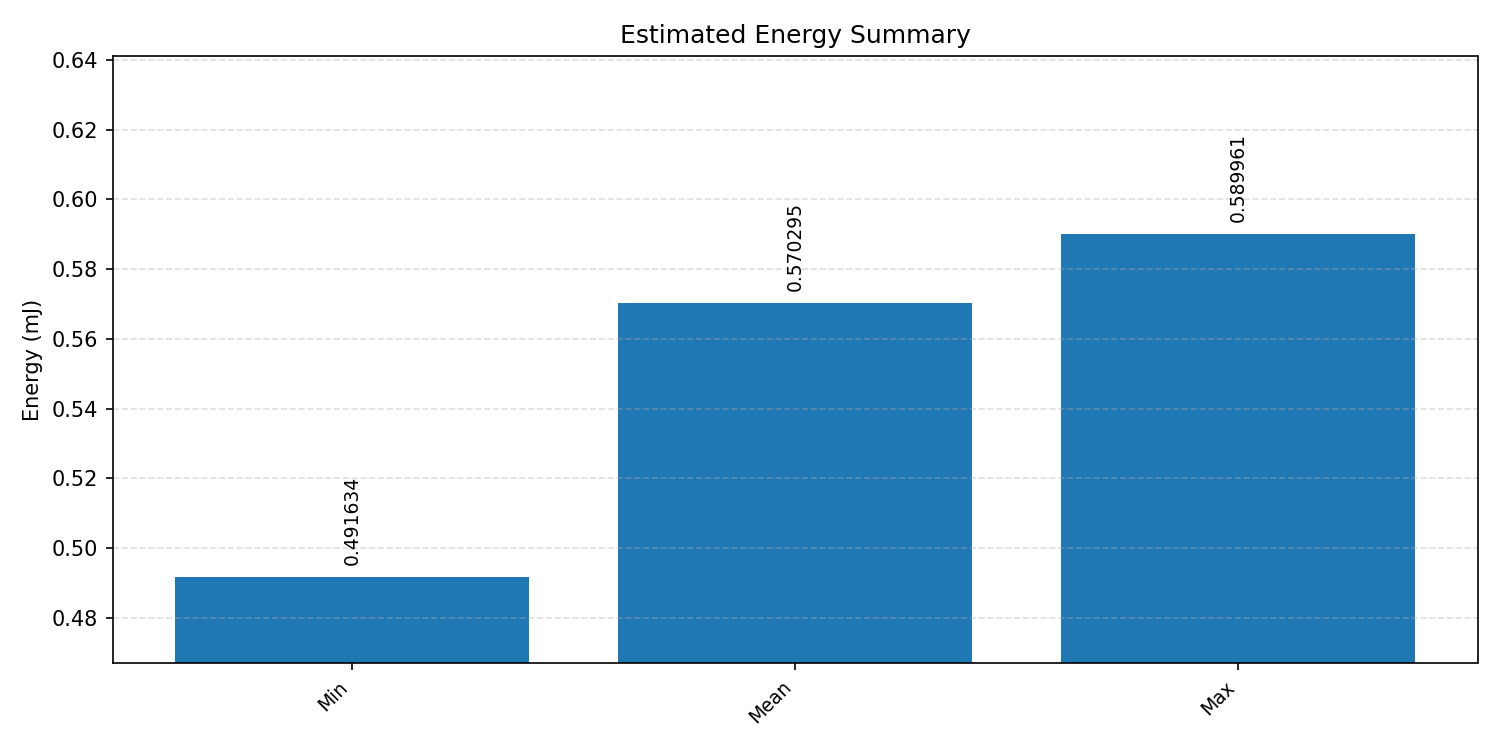
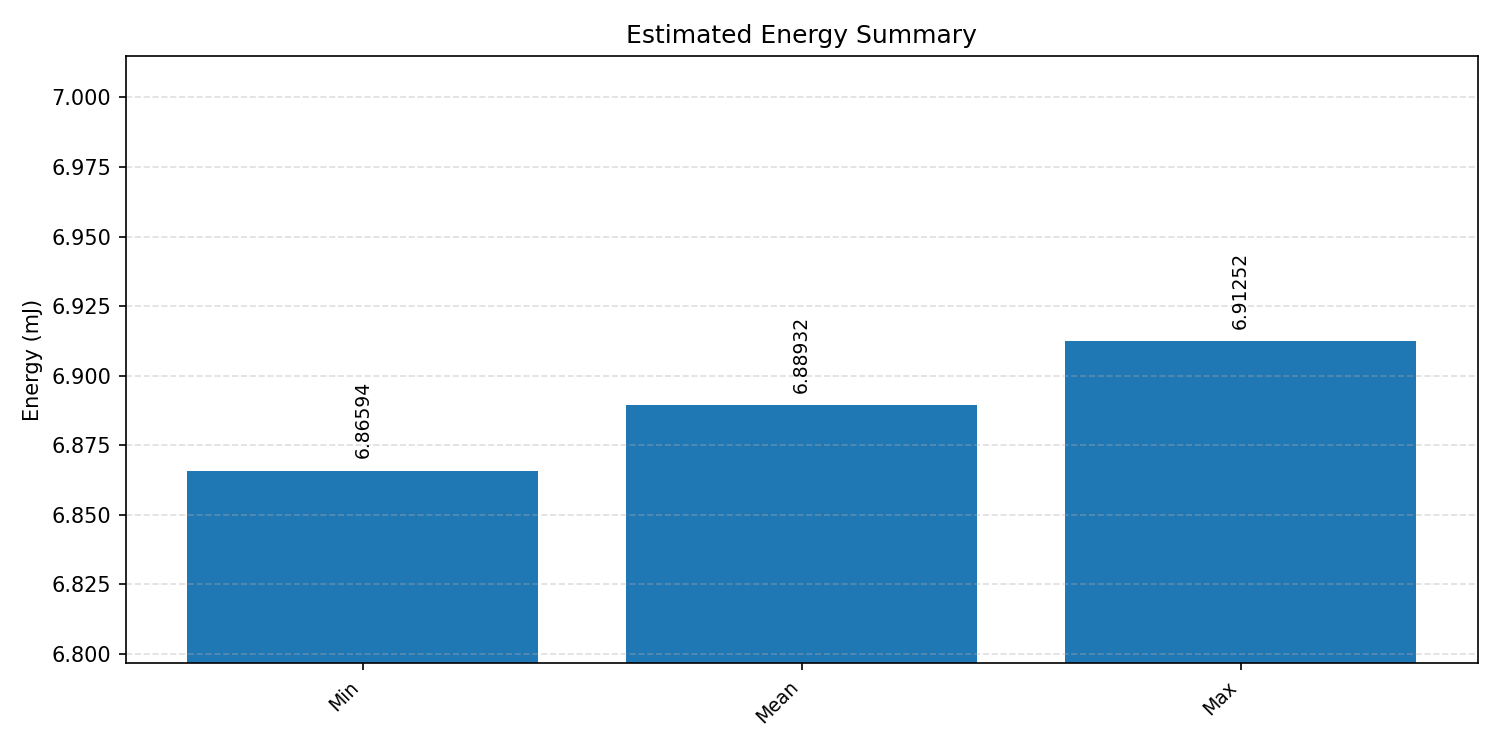
Energy summaries estimate the energy consumed by one inference.
Validation accuracy summarizes the prediction quality of the exported model on representative samples.
#1. STM32H7 Embedded Benchmarks#
#1.1 LeNet MNIST#
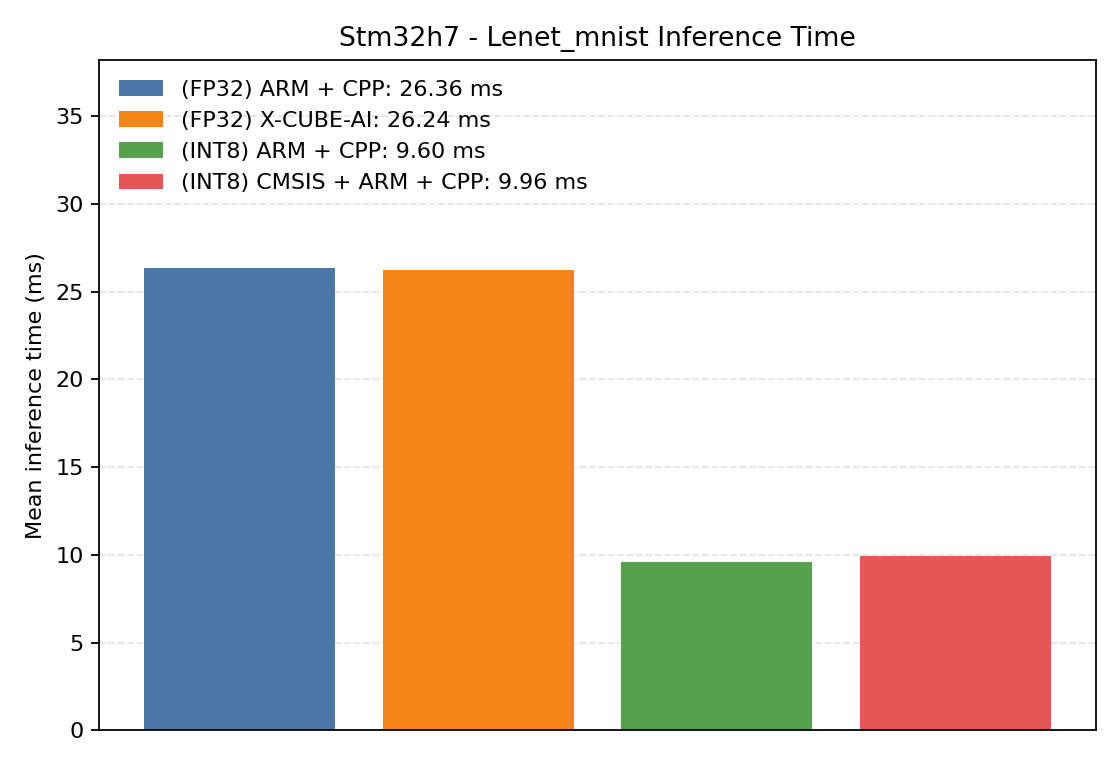
LeNet is a compact image-classification model and a useful first check for
export correctness. It is shown in FP32, int8 with the Aidge arm kernel,
and int8 with CMSIS kernels so the backend choice can be compared directly.
Comparison Chart
#1.1.1 (FP32) ARM + CPP#
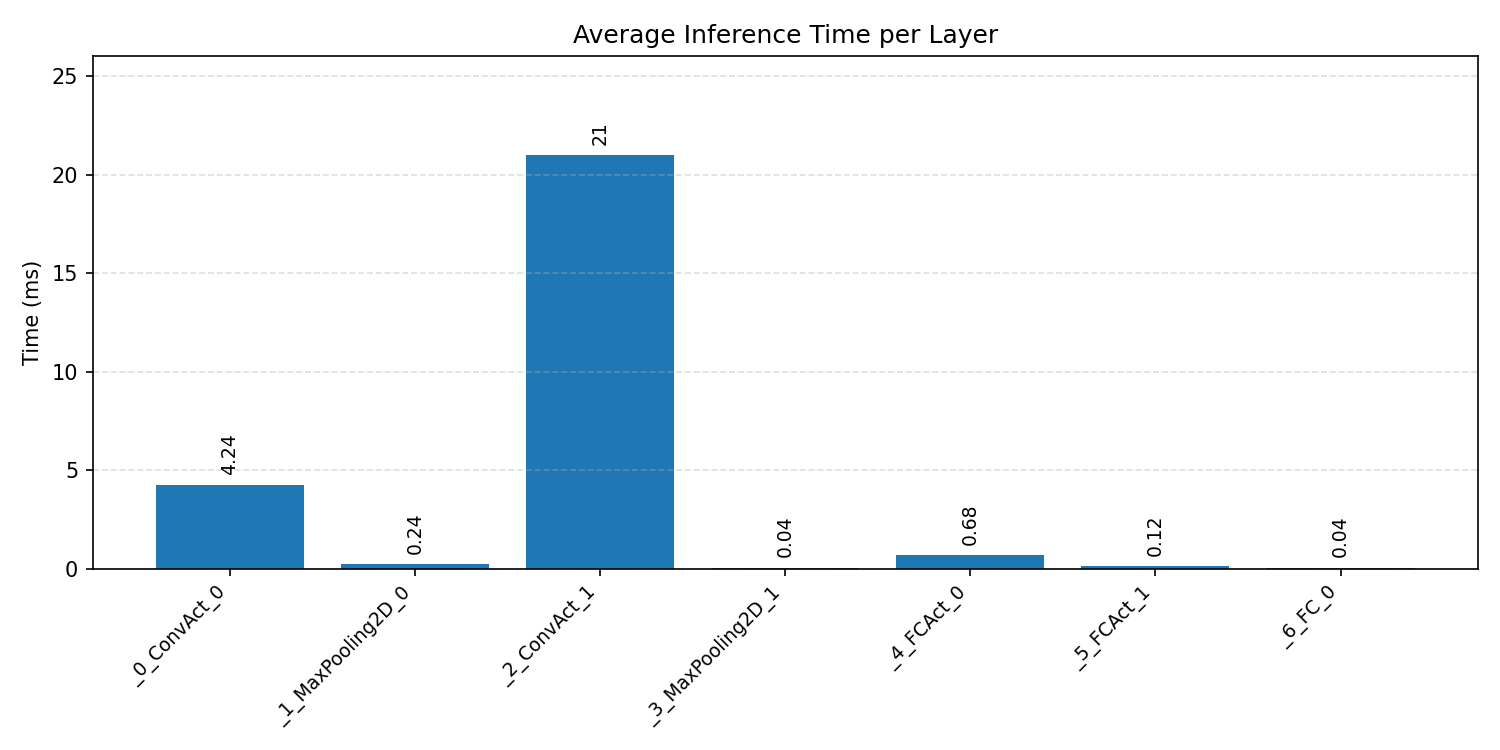
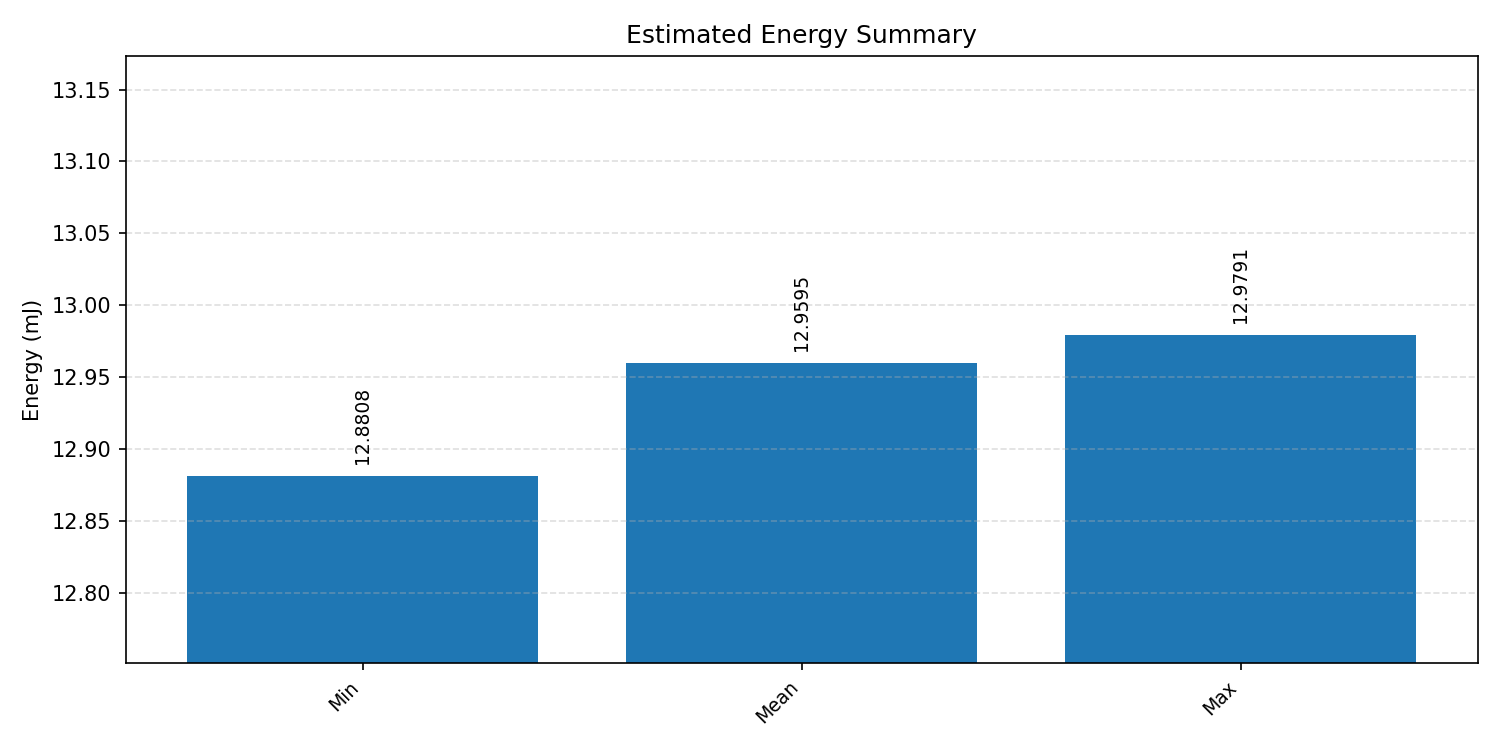

#1.1.2 (INT8) ARM + CPP#
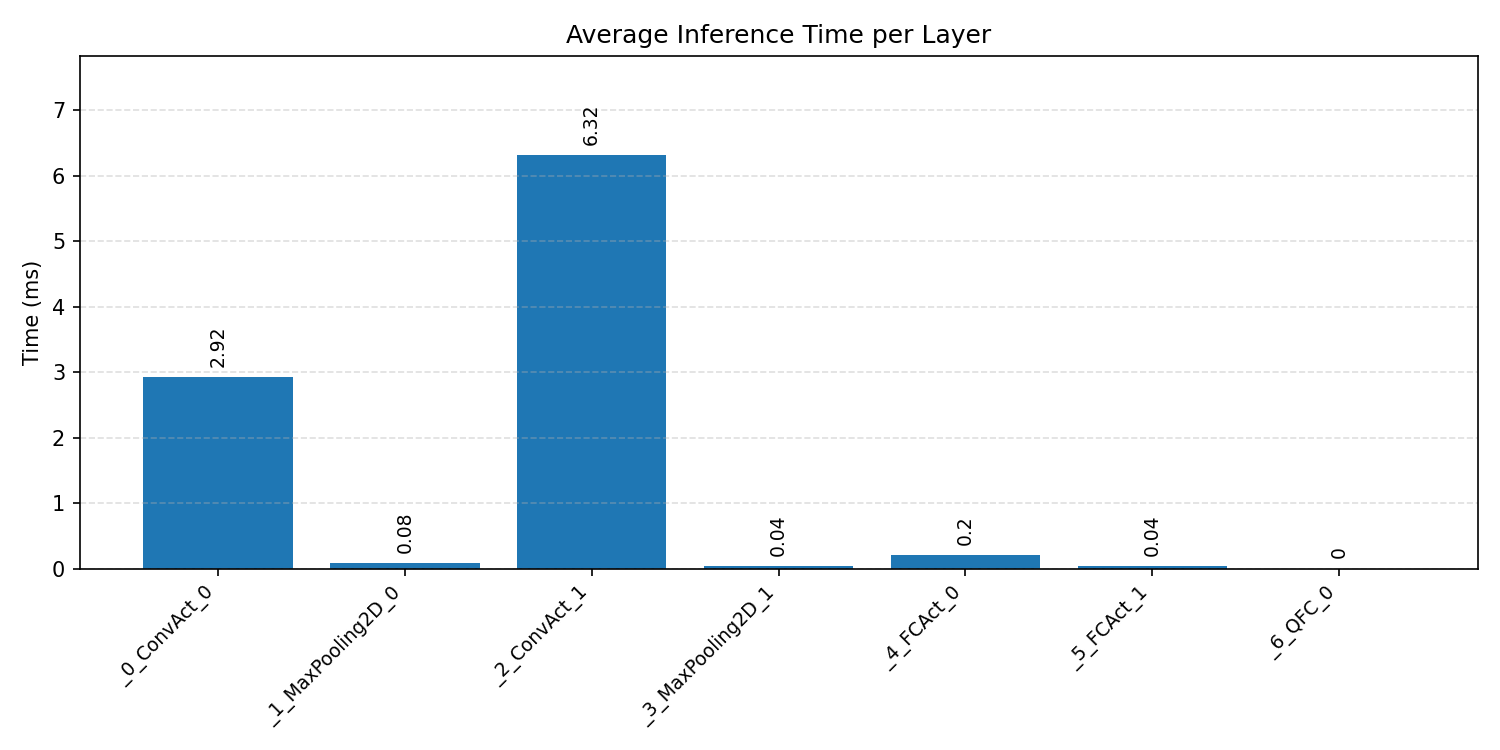
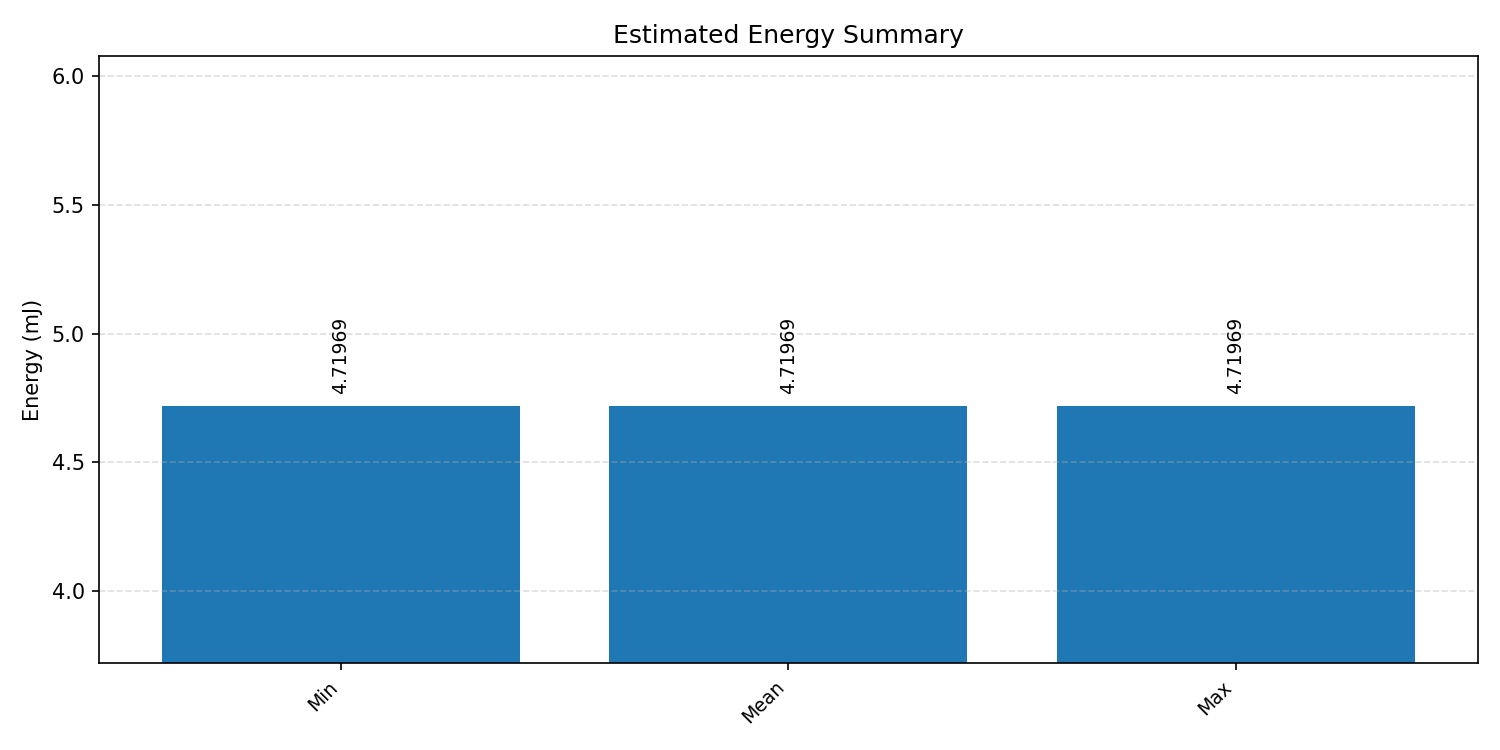

#1.1.3 (INT8) CMSIS + ARM + CPP#
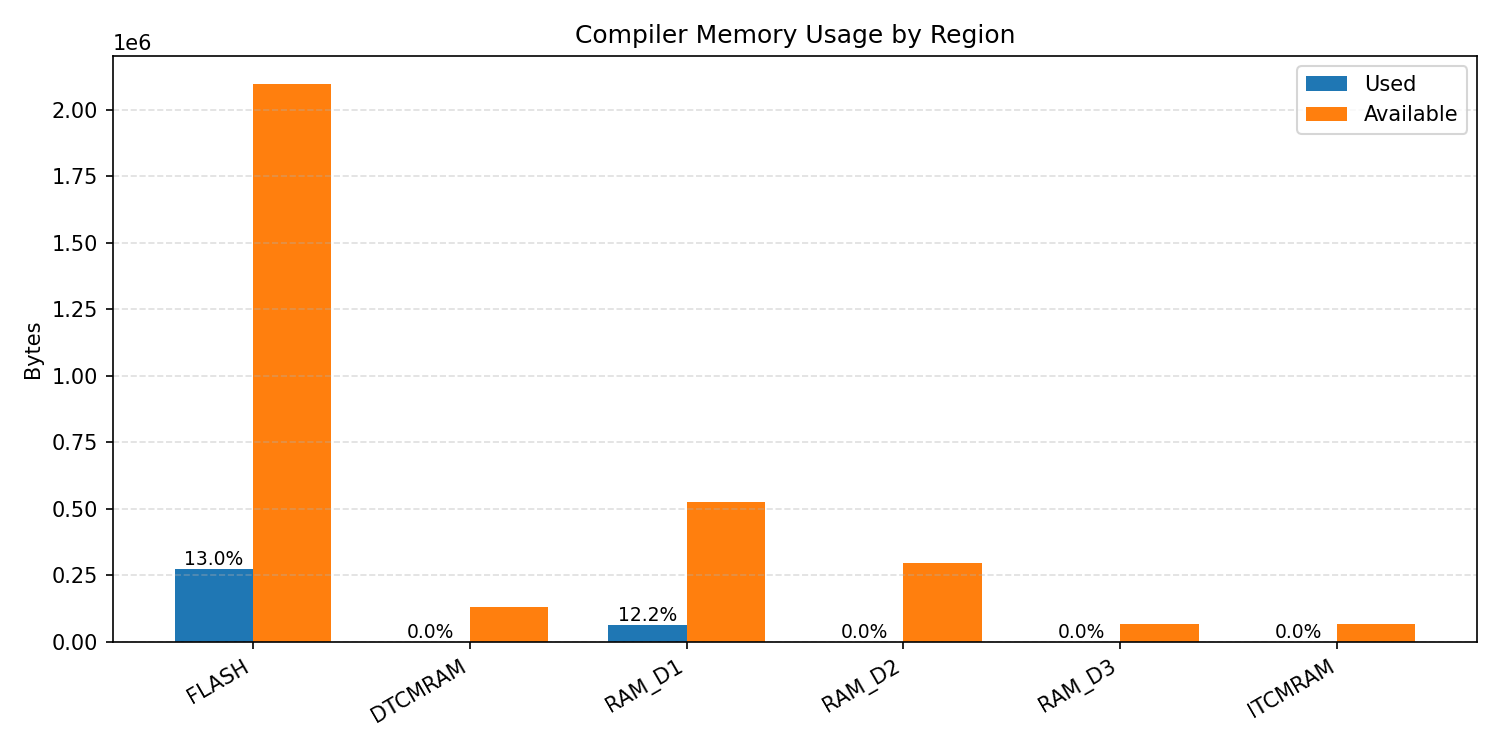
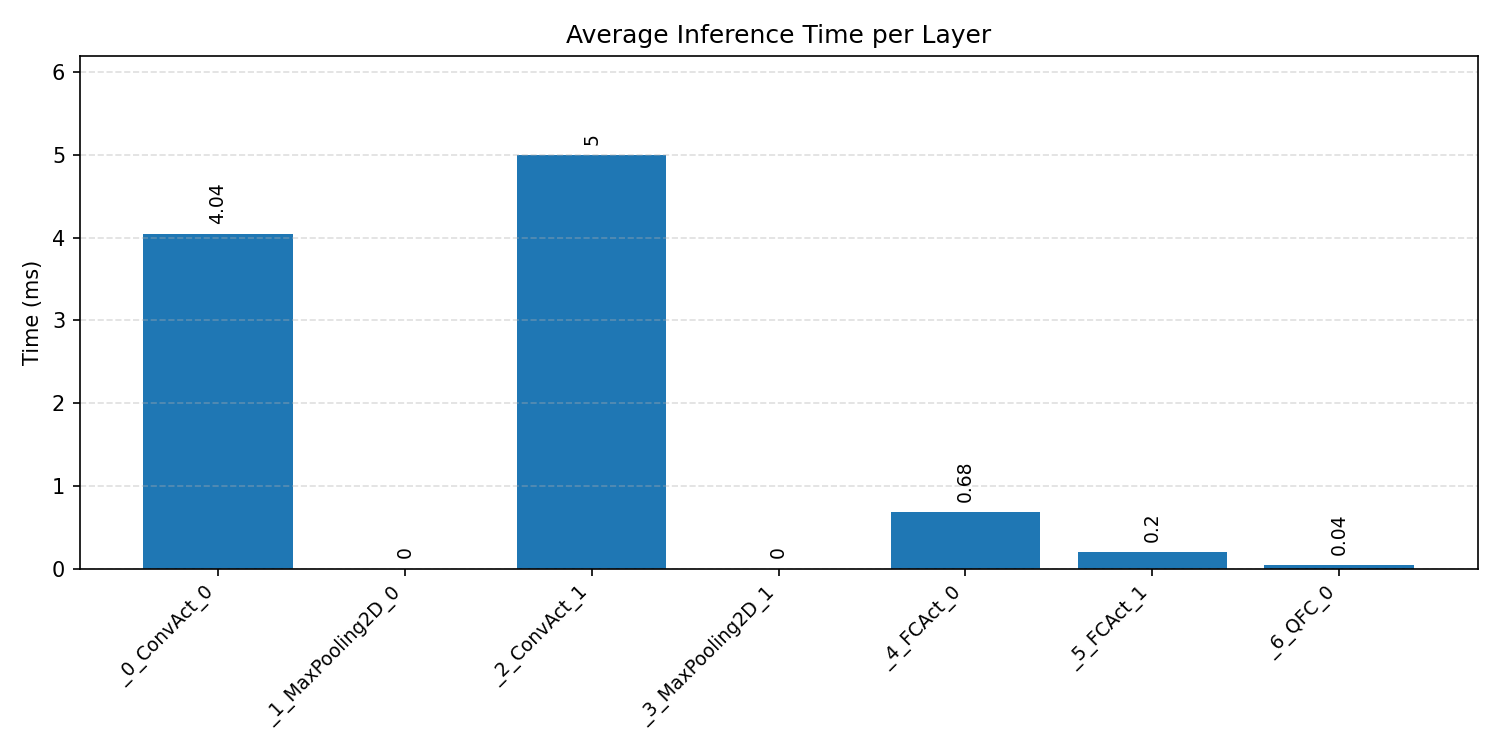
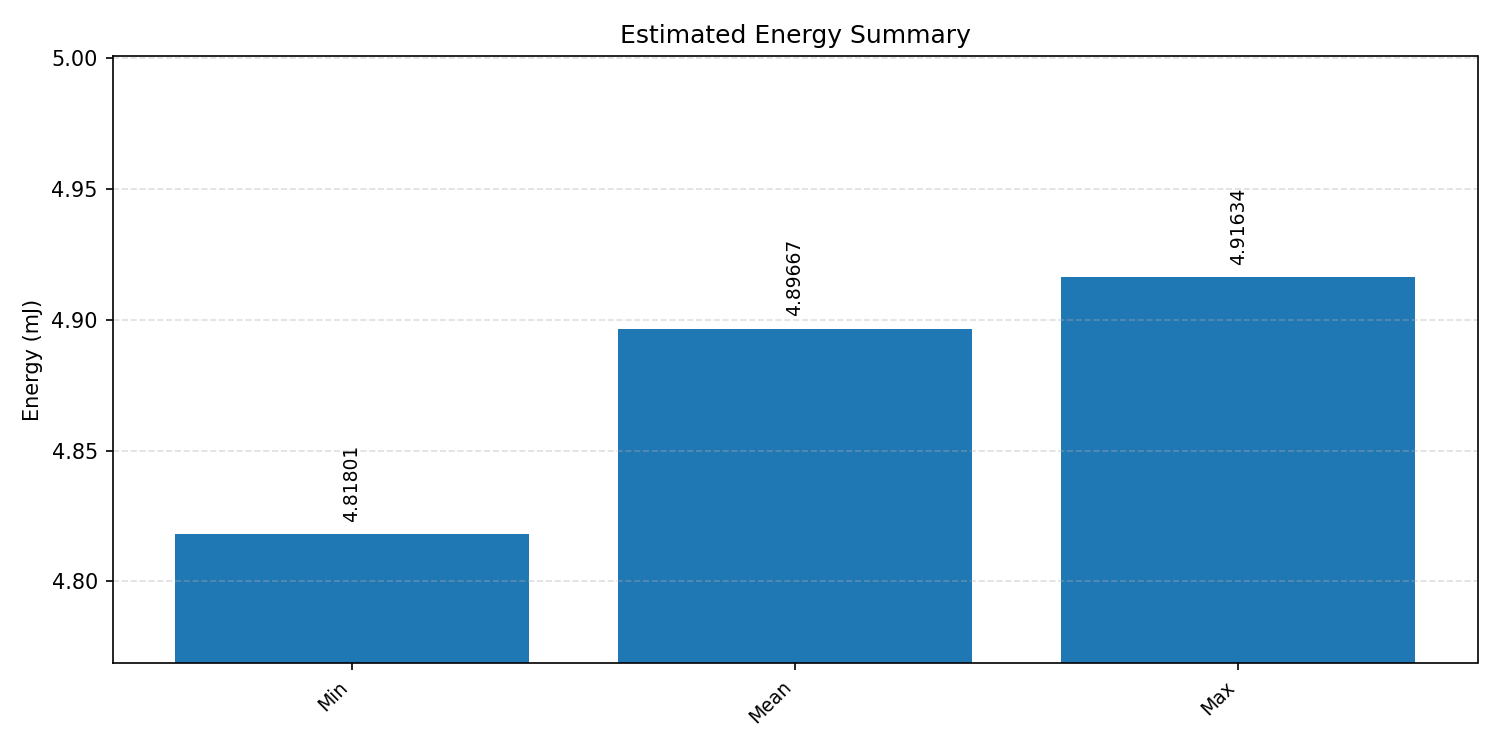

#1.2 MobileNet V1 VWW#
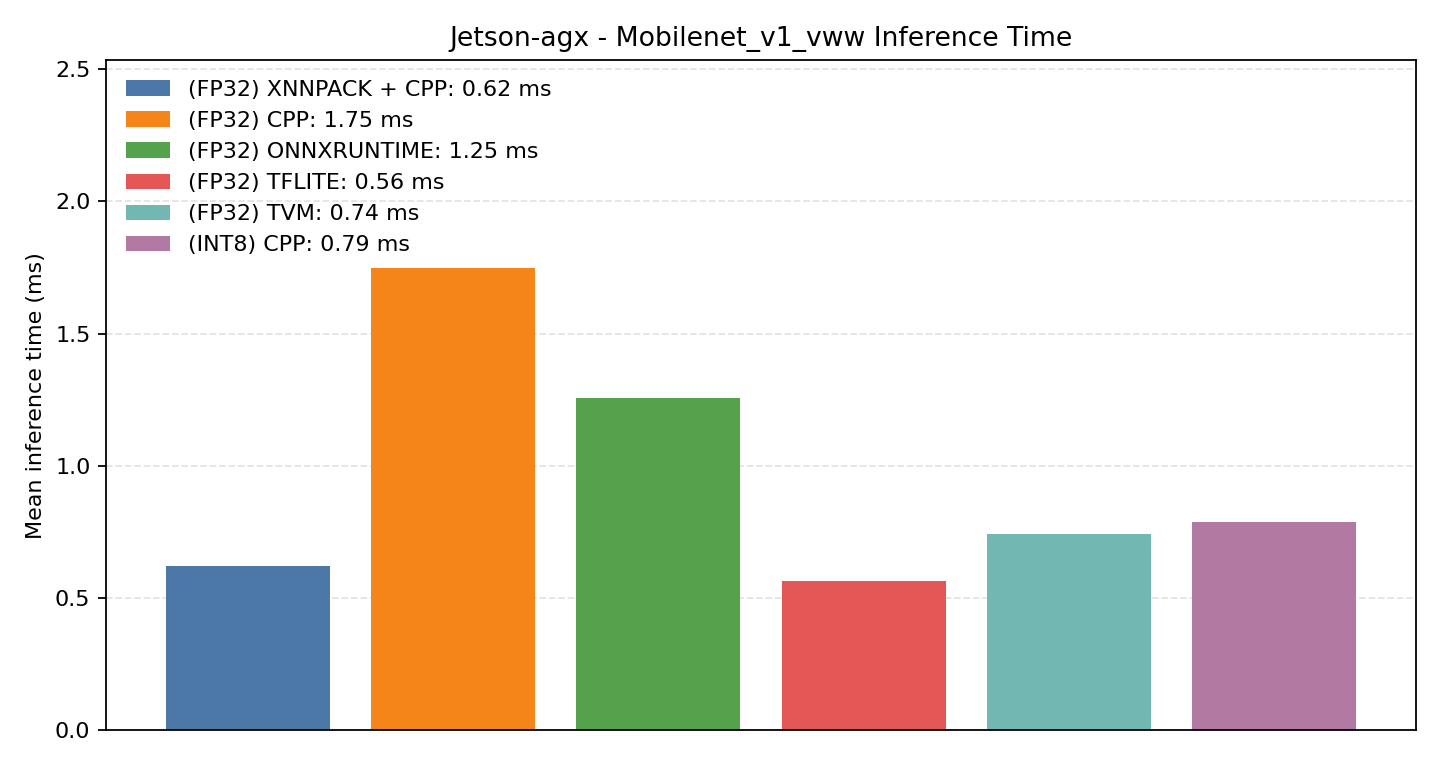
MobileNet V1 for visual wake words is a larger convolutional workload. It is a good benchmark for inspecting how Aidge’s kernel selection can optimize a more complex graph.
Comparison Chart
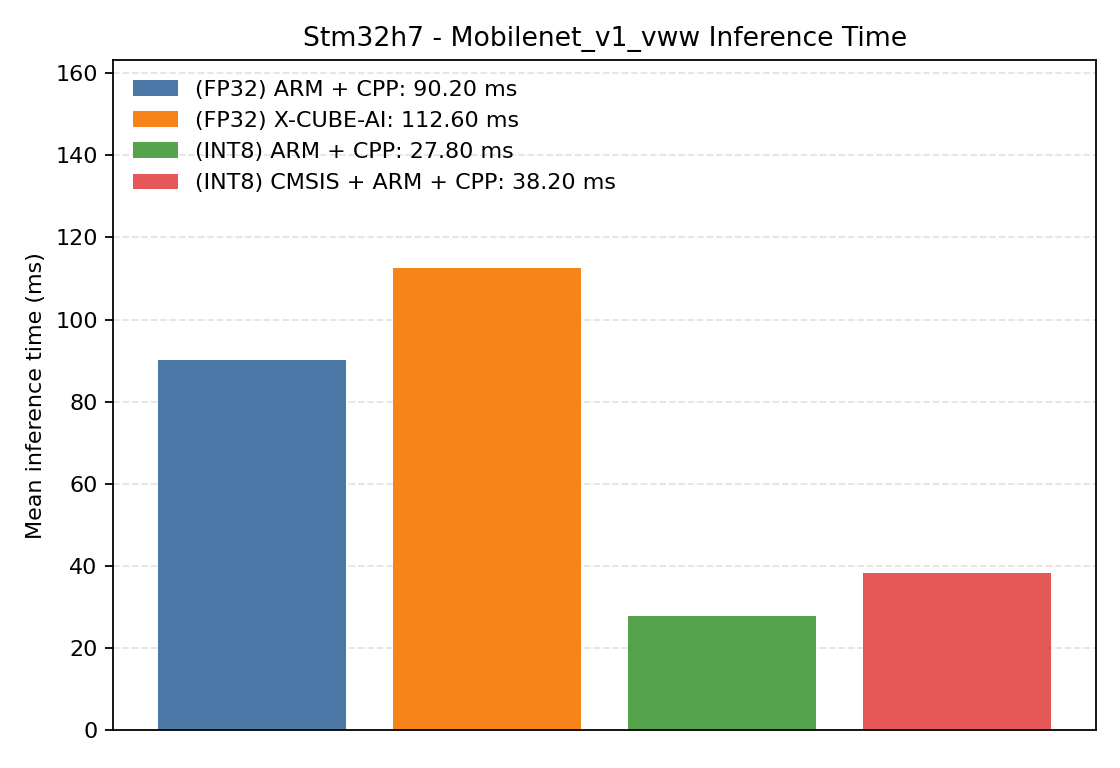
#1.2.1 (FP32) ARM + CPP#
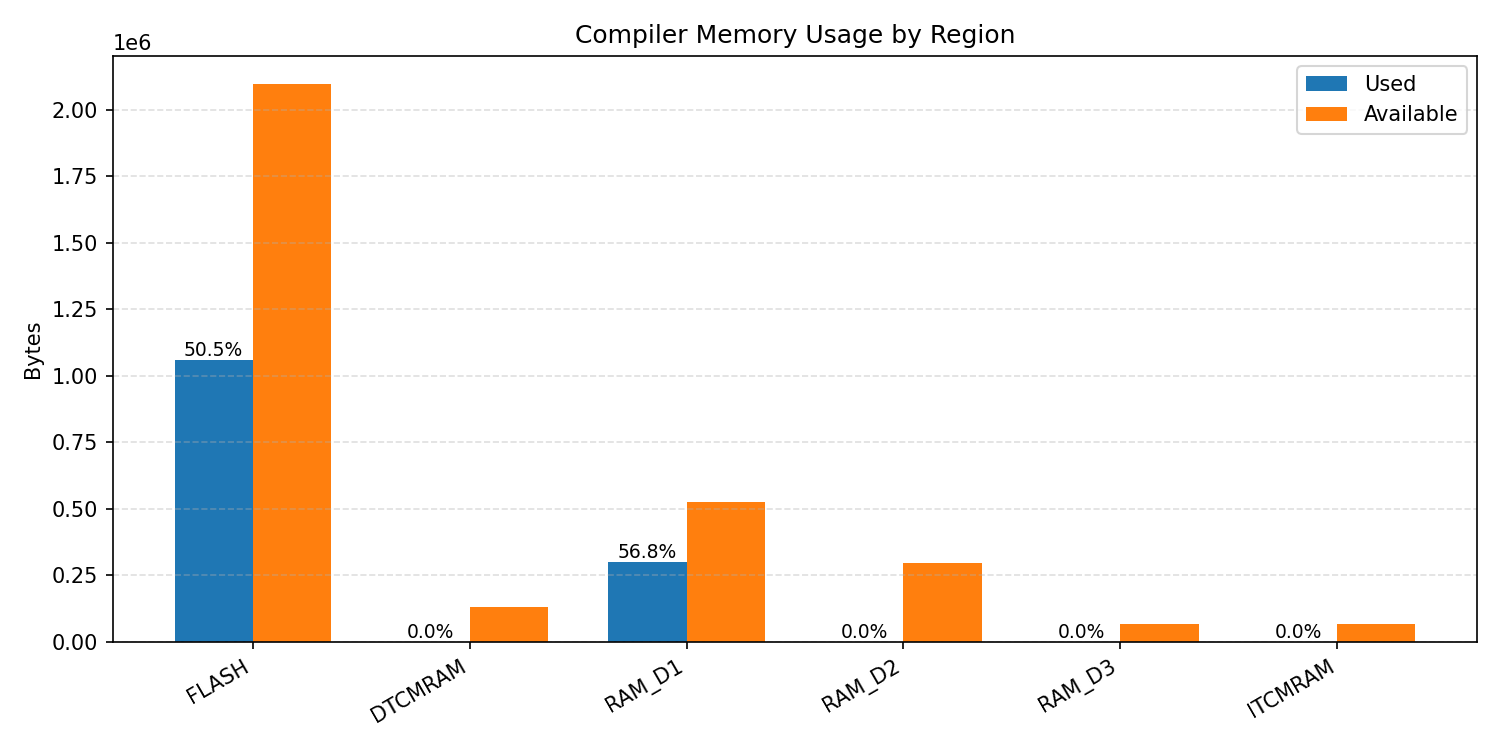
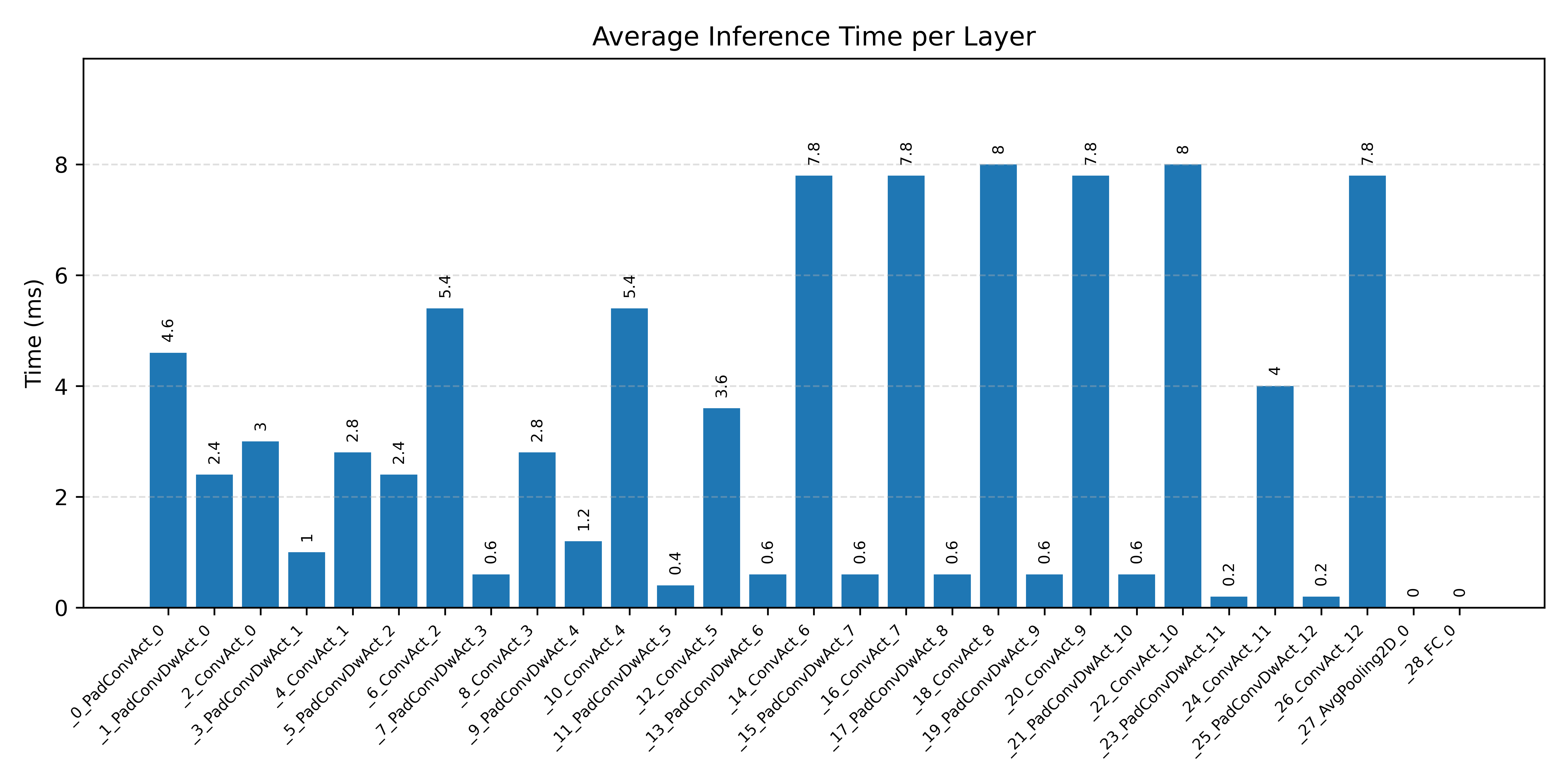
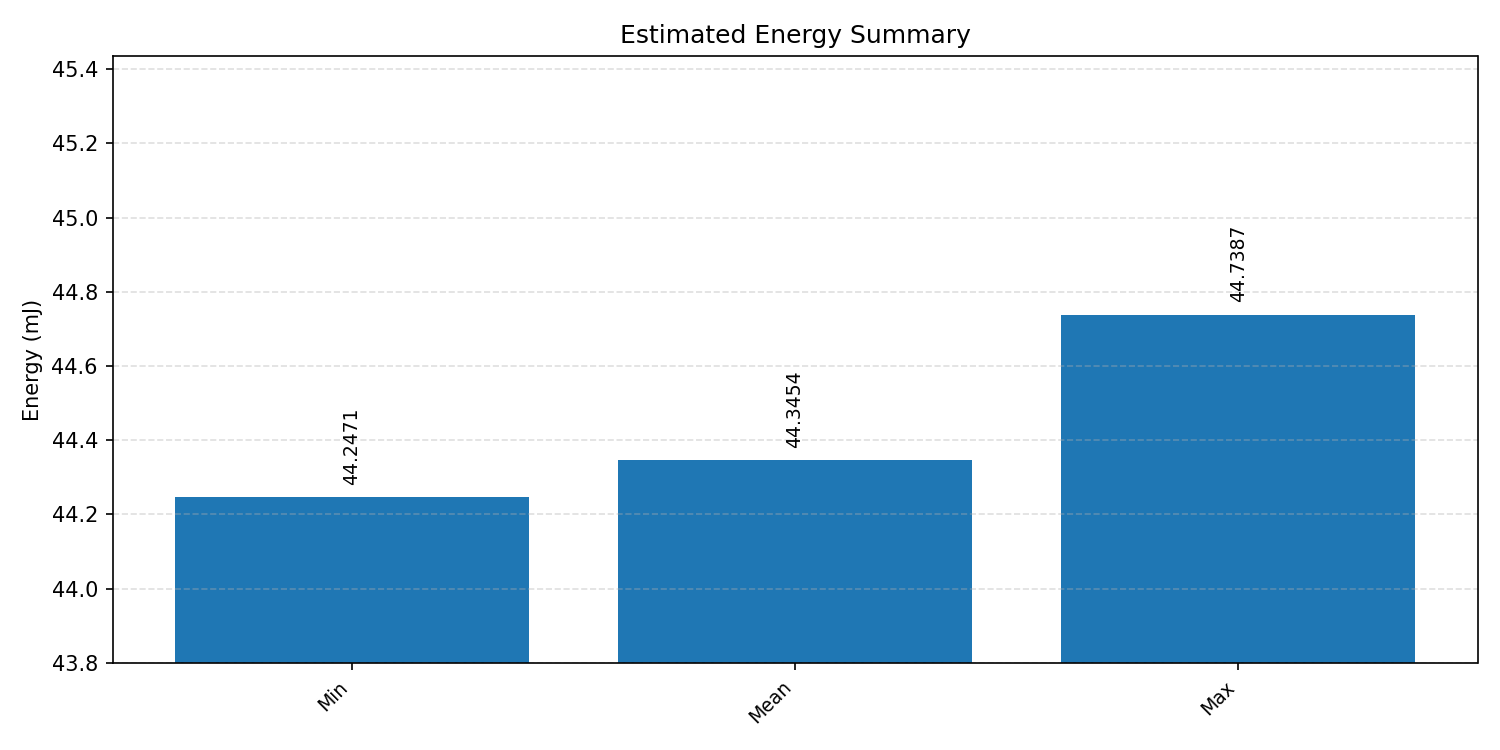

#1.2.2 (INT8) ARM + CPP#

#1.2.3 (INT8) CMSIS + ARM + CPP#
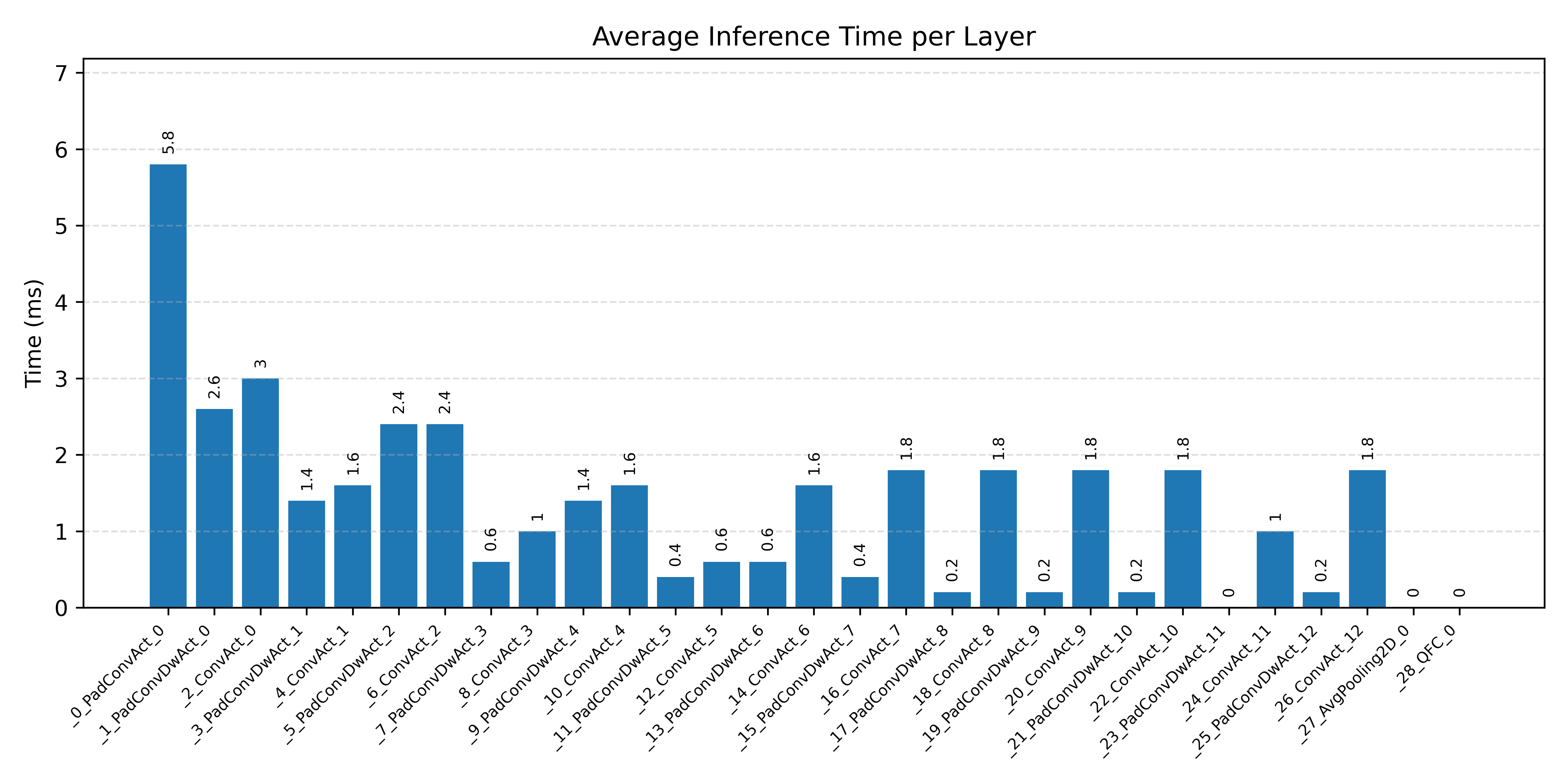
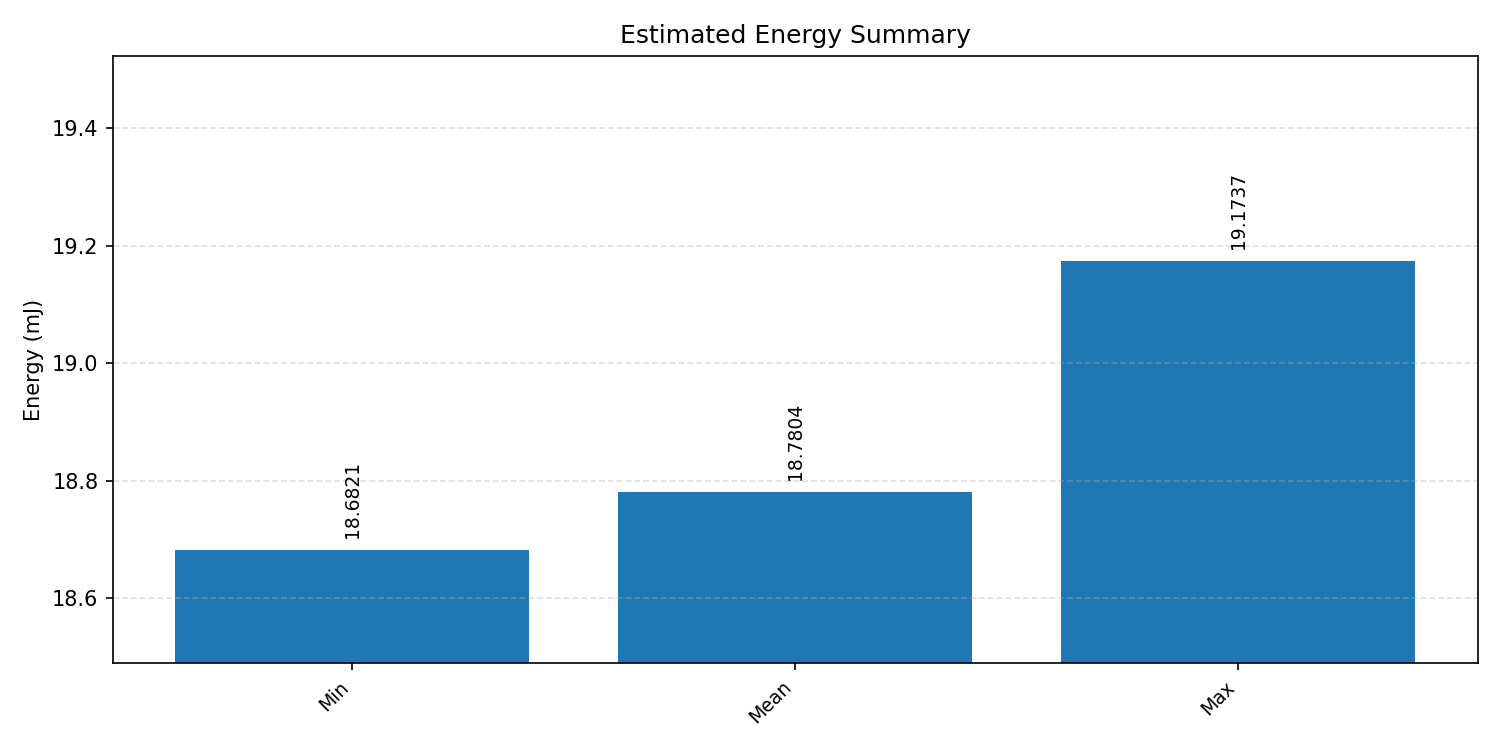

#1.3 ResNet8 CIFAR-10#
ResNet8 adds residual connections and a deeper convolutional structure. It is a good benchmark for seeing how scheduling and memory reuse behave on a less linear graph.
Comparison Chart
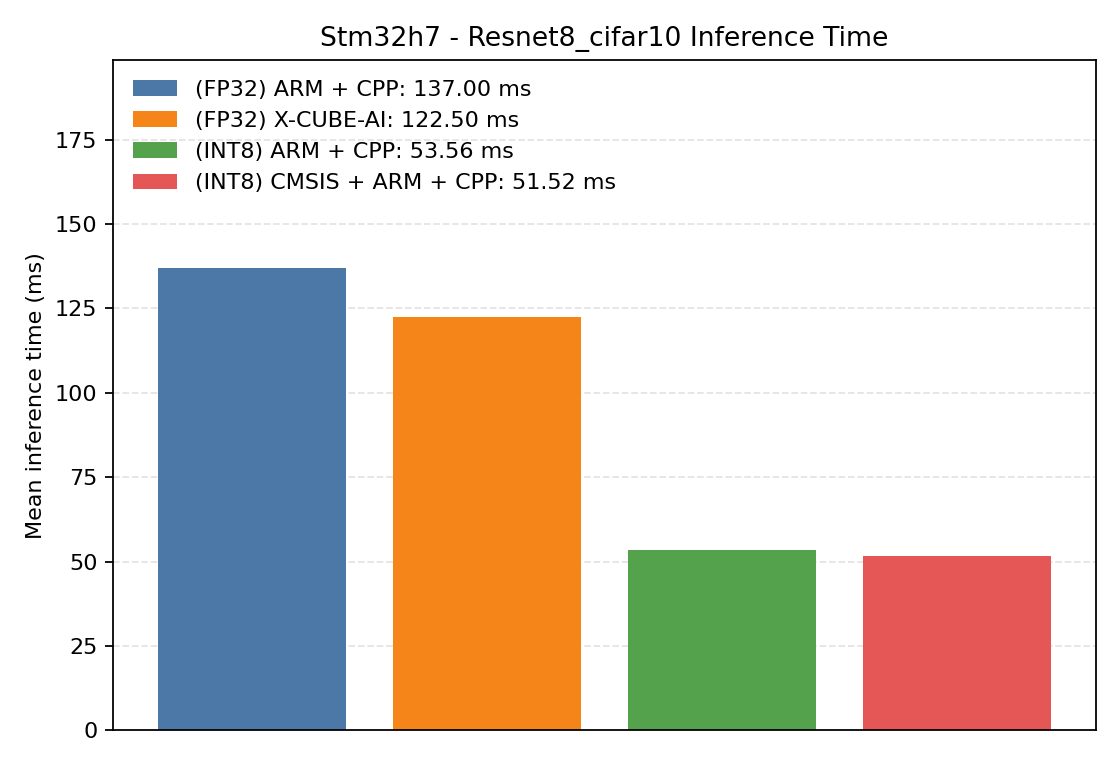
#1.3.1 (FP32) ARM + CPP#
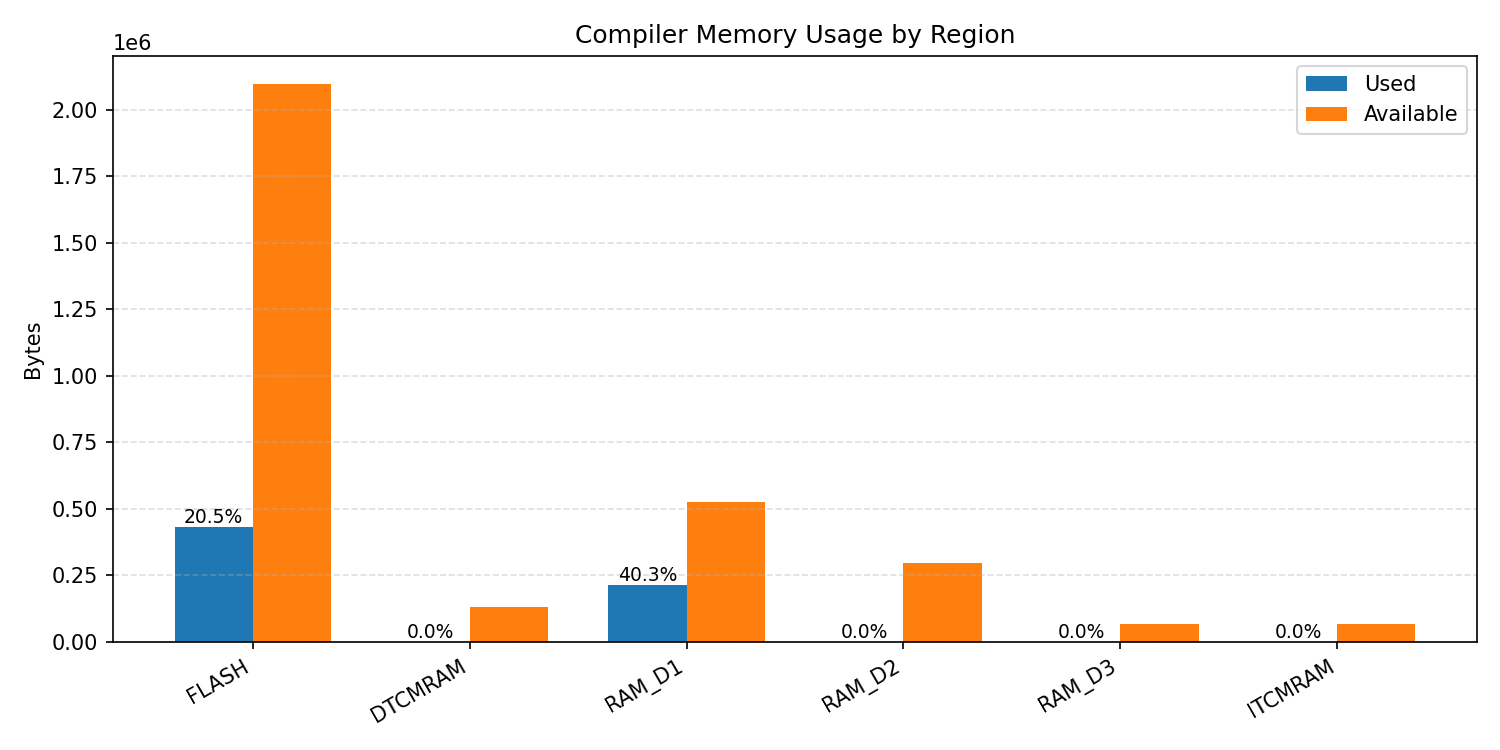
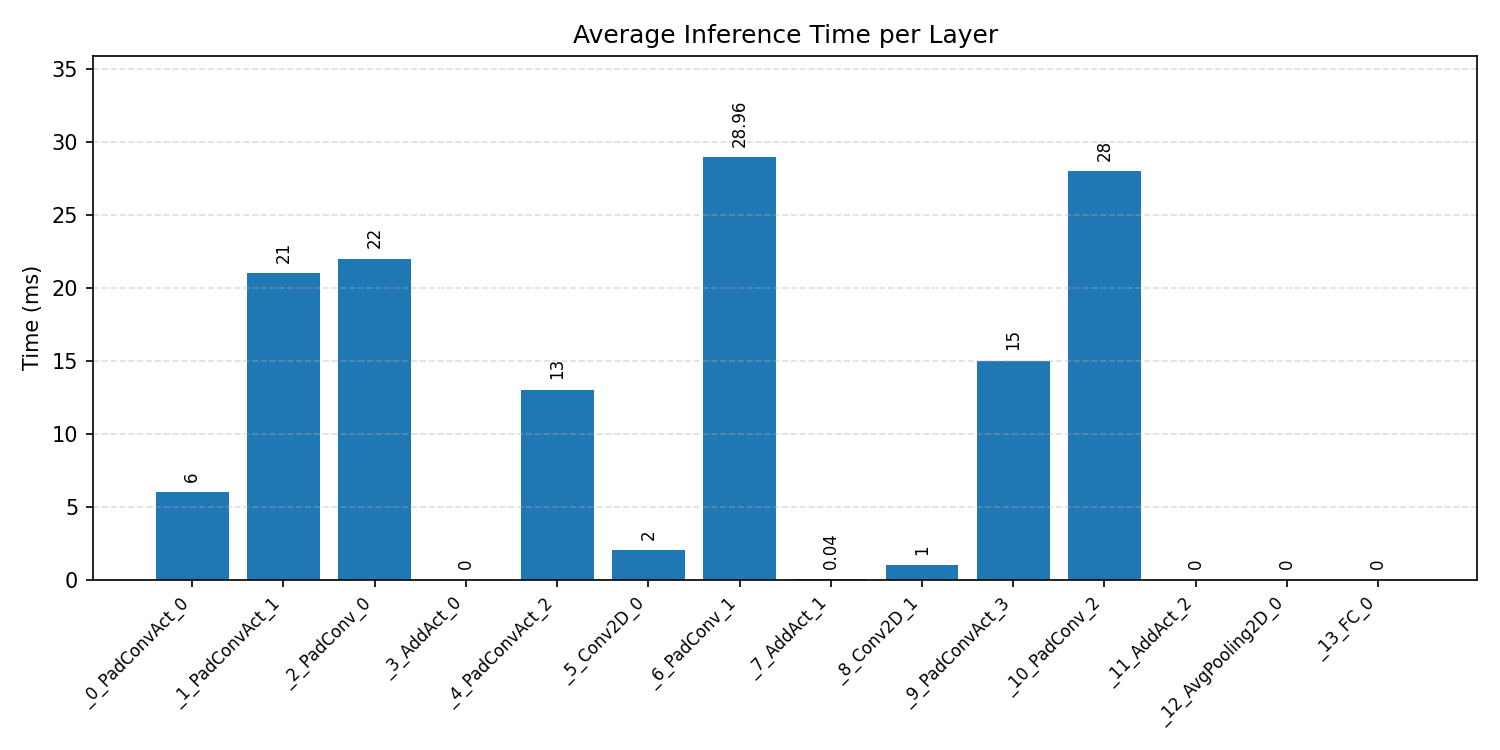
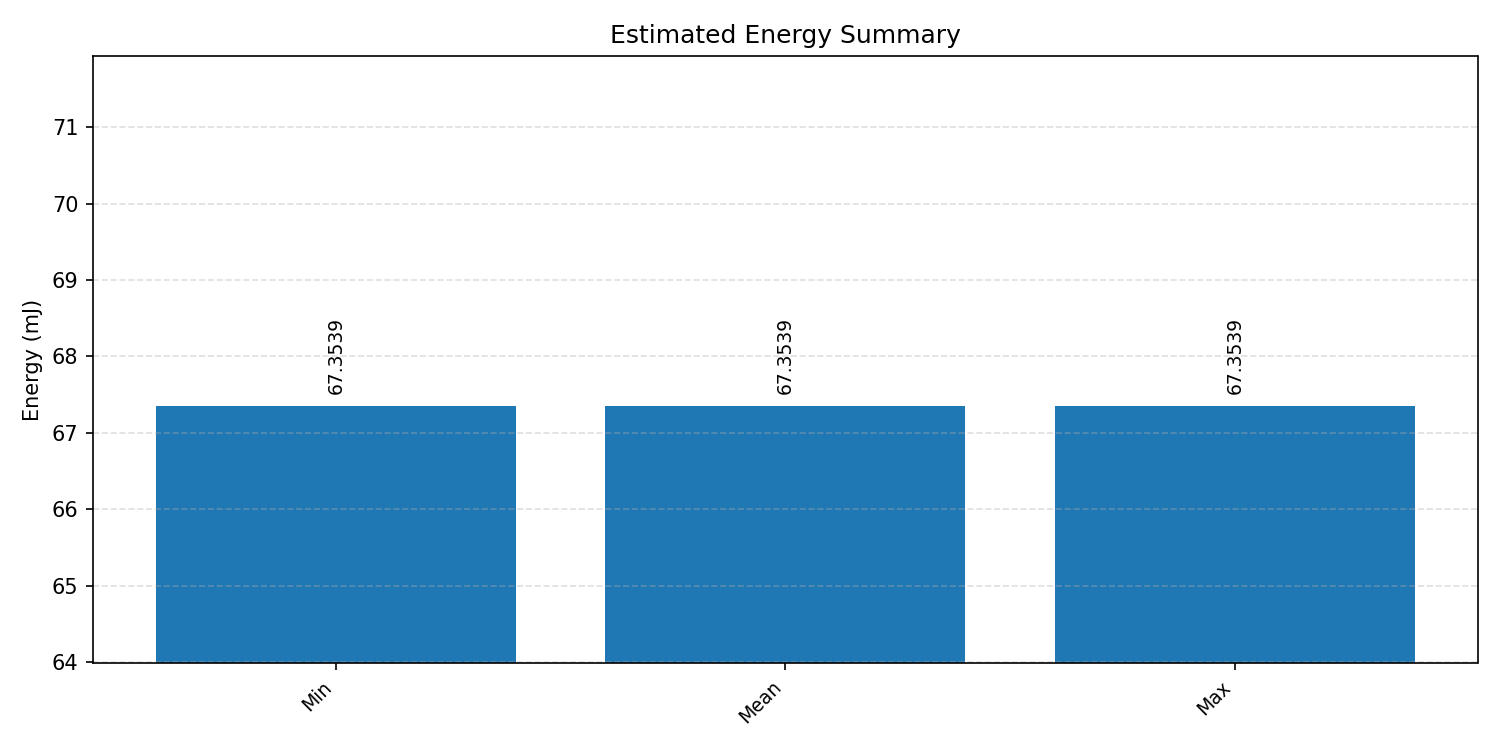

#1.3.2 (INT8) ARM + CPP#
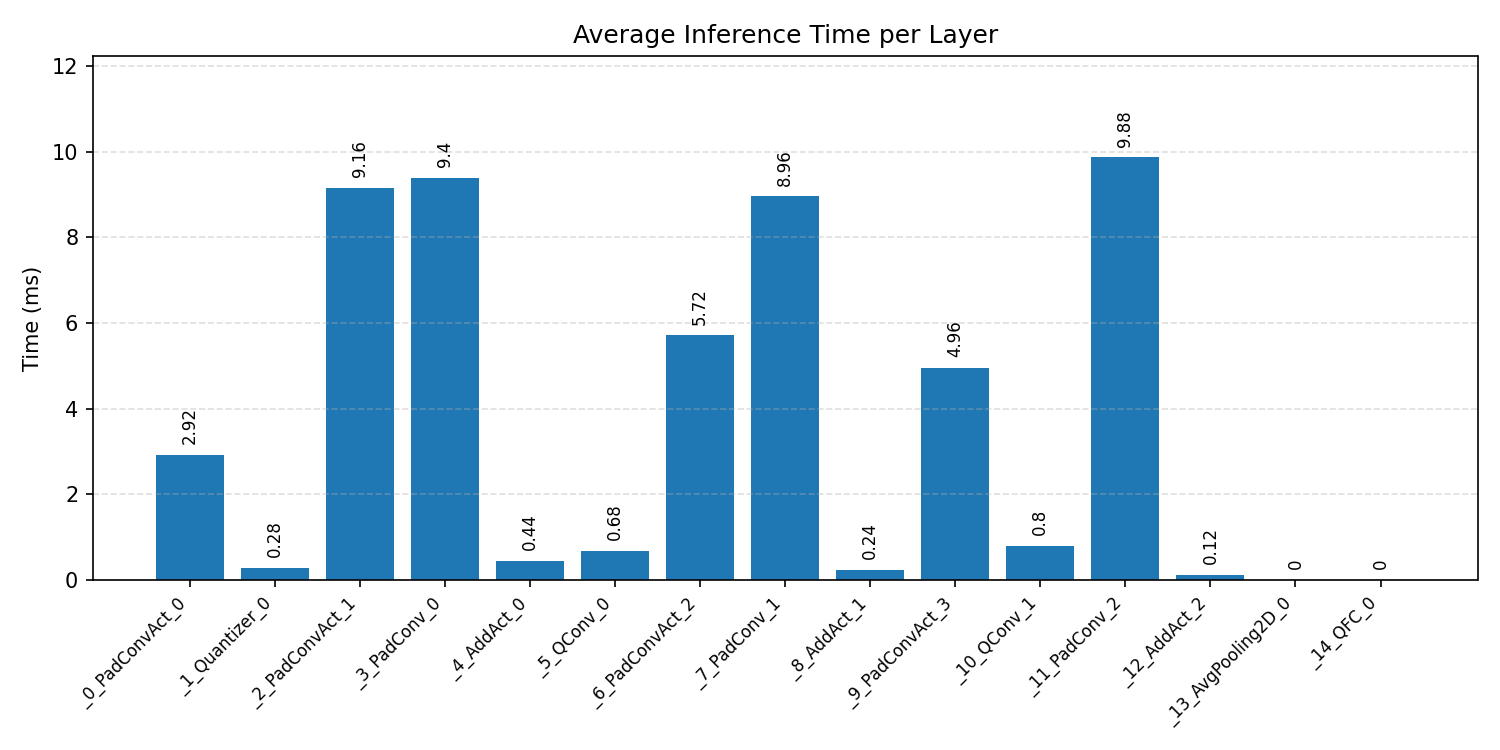
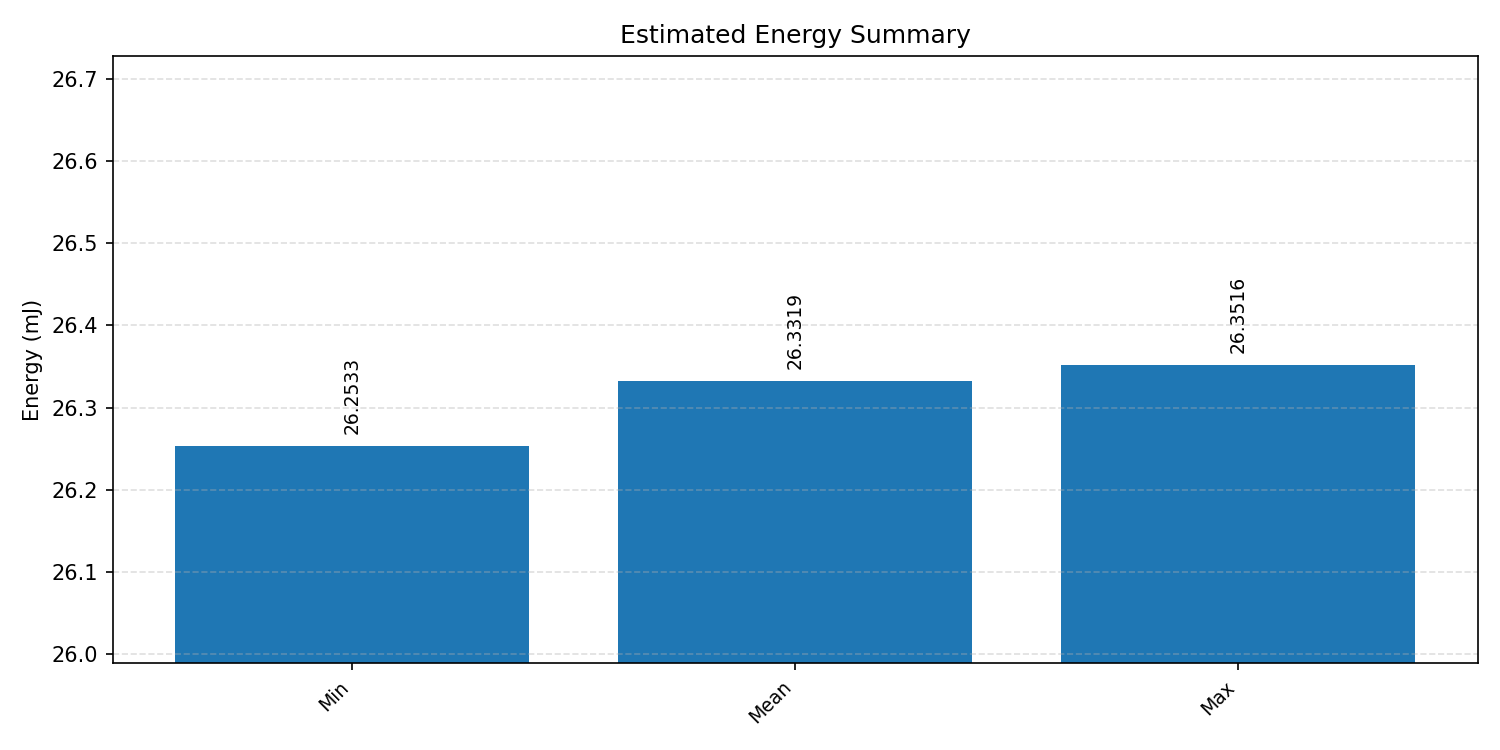

#1.3.3 (INT8) CMSIS + ARM + CPP#
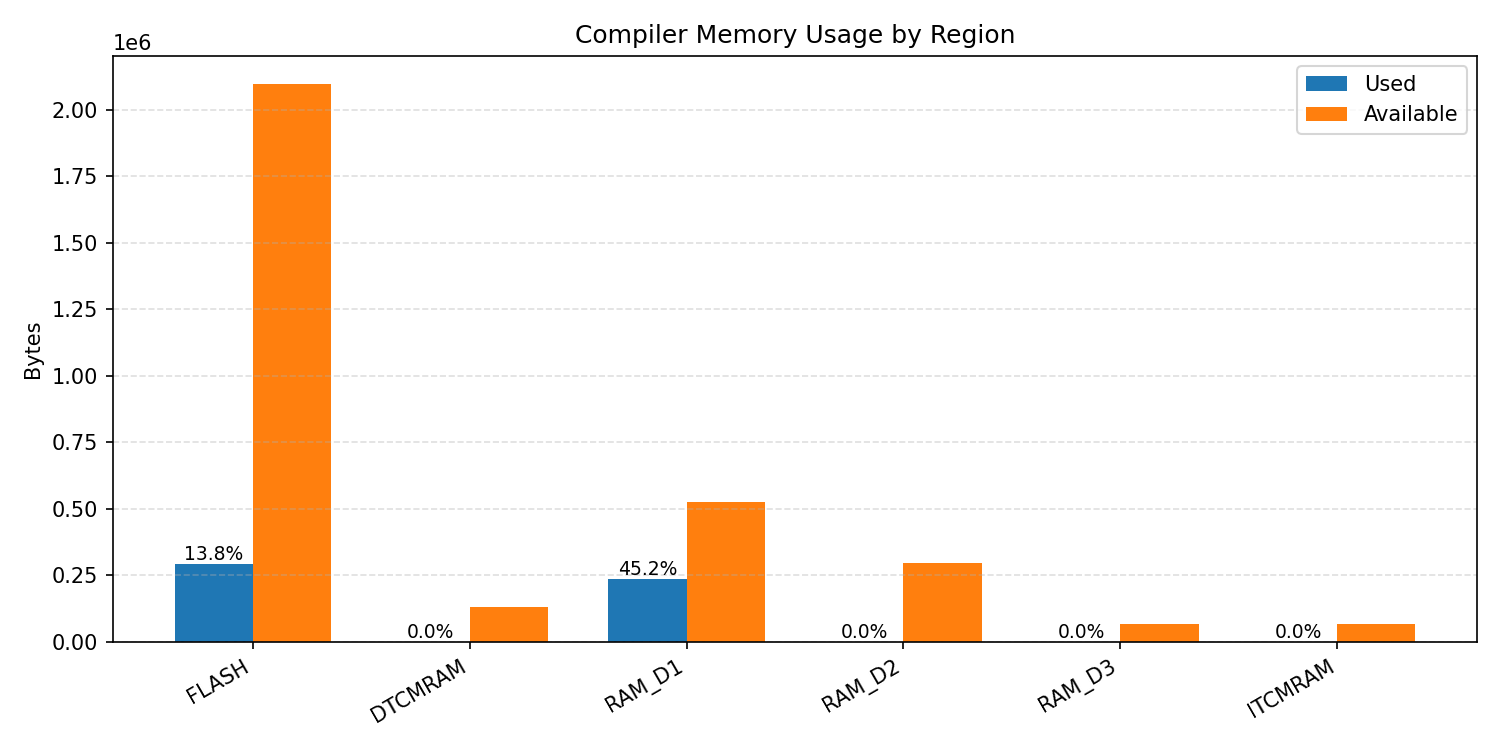
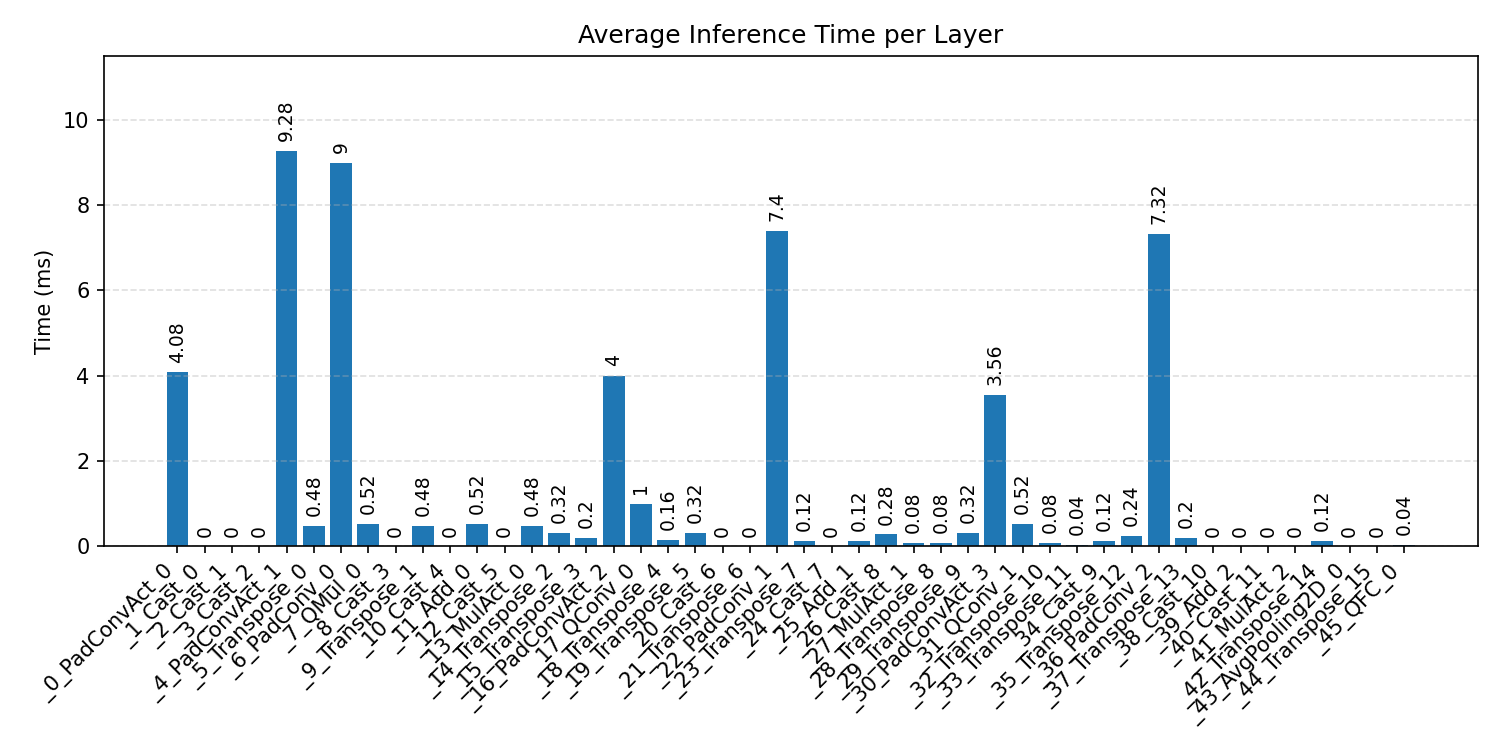
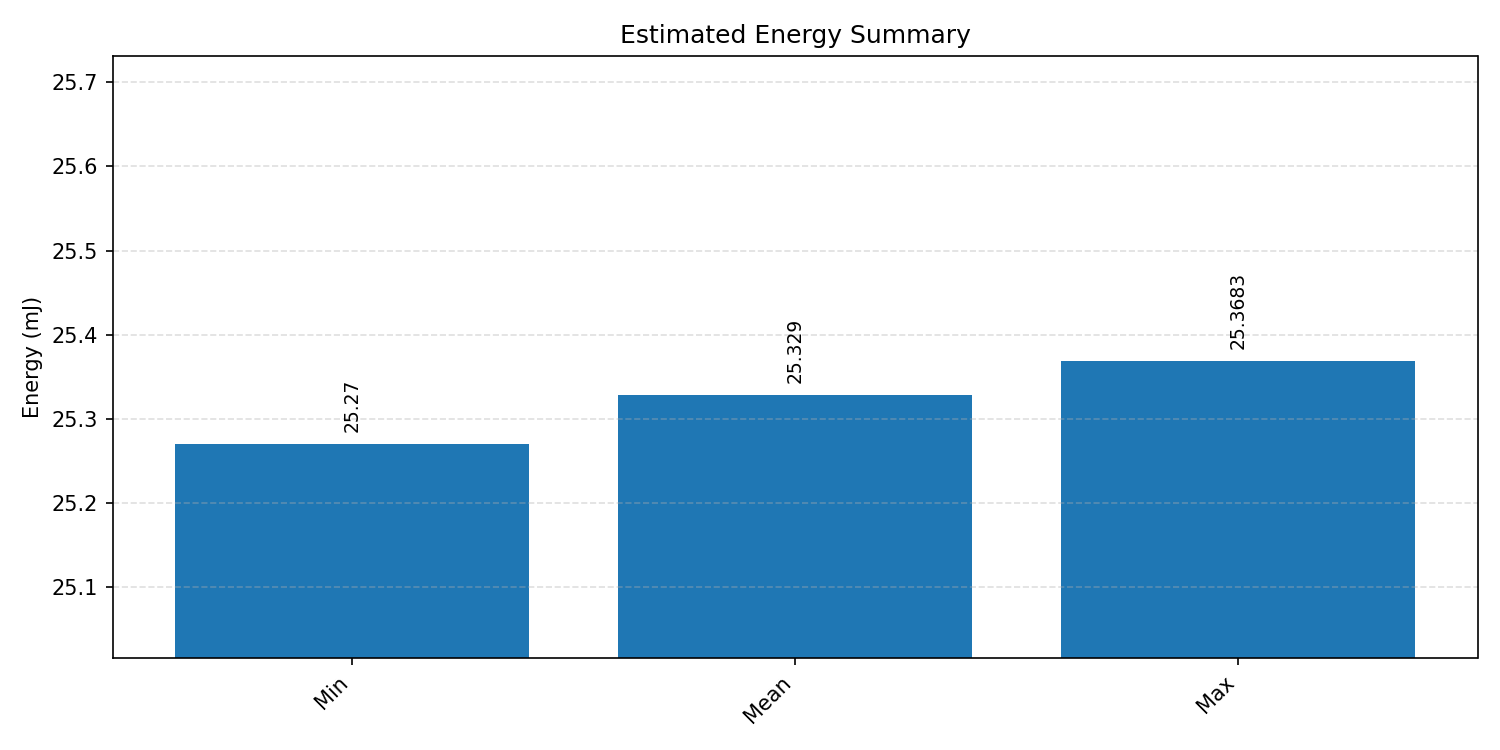

#1.4 DS-CNN#
DS-CNN is a depthwise-separable convolutional network often used for small keyword-spotting style workloads.
Comparison Chart
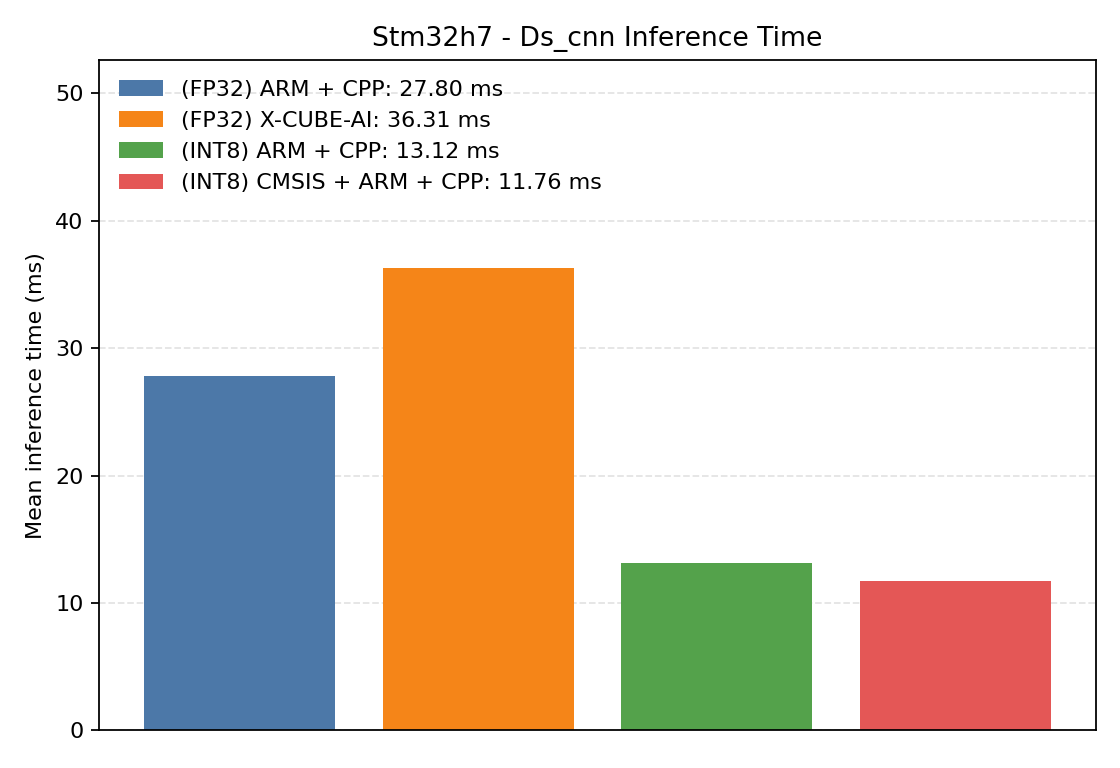
#1.4.1 (FP32) ARM + CPP#
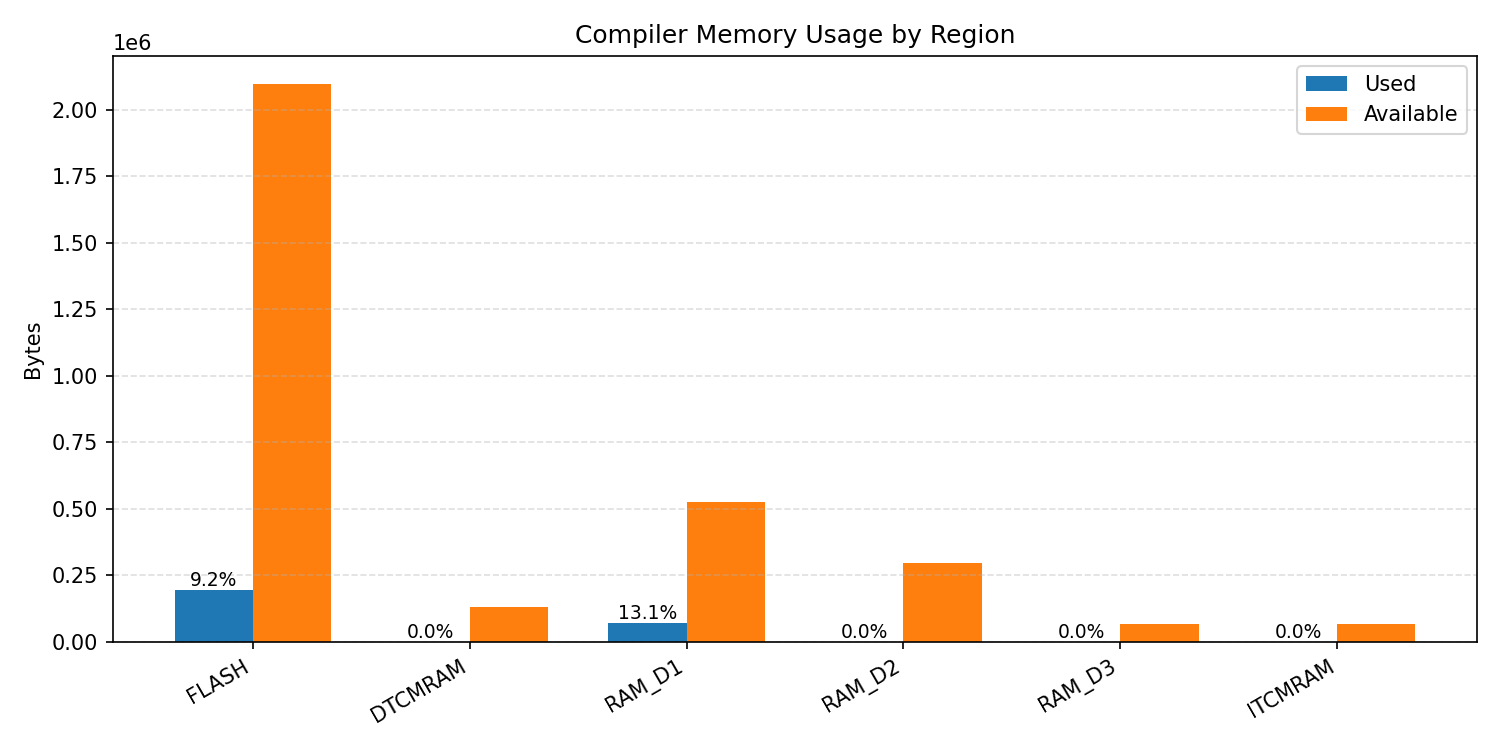
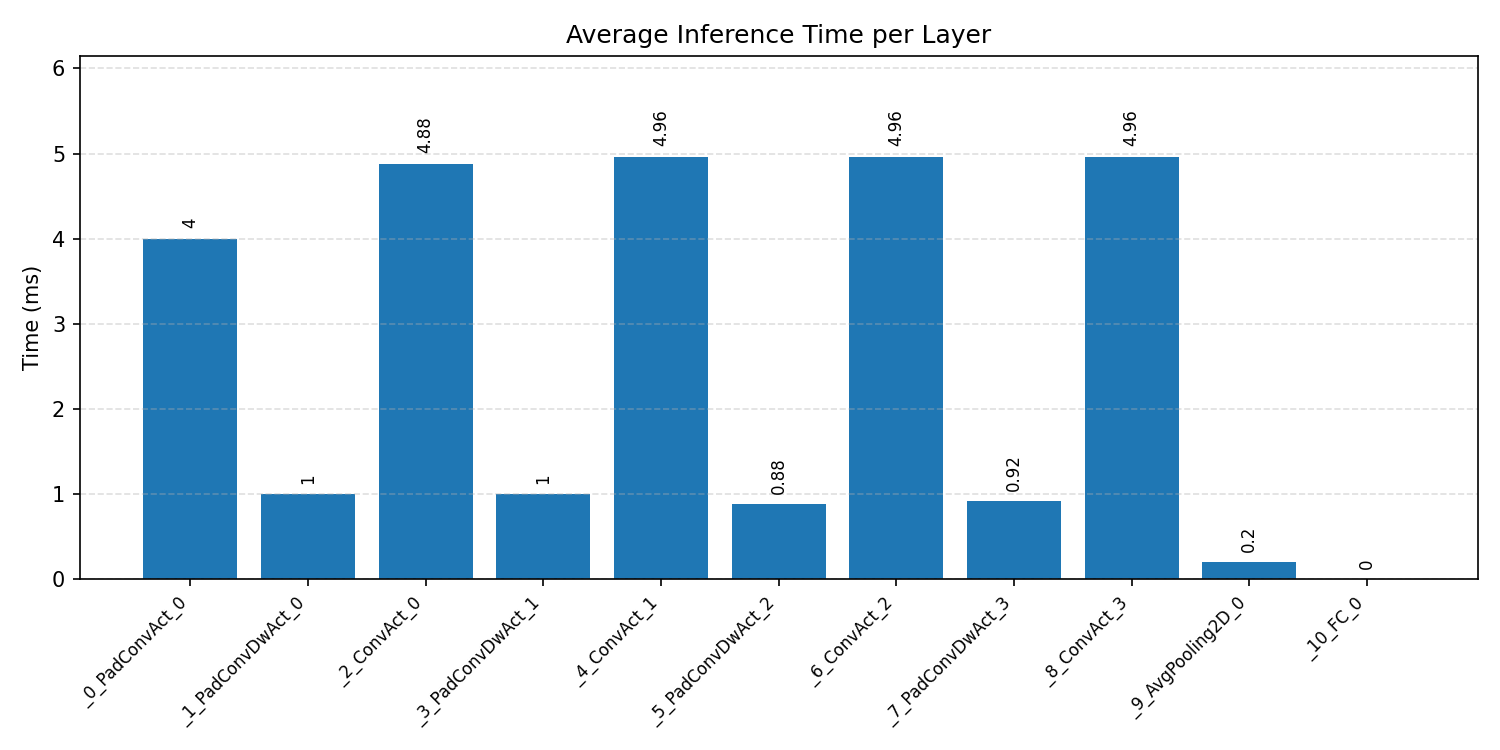
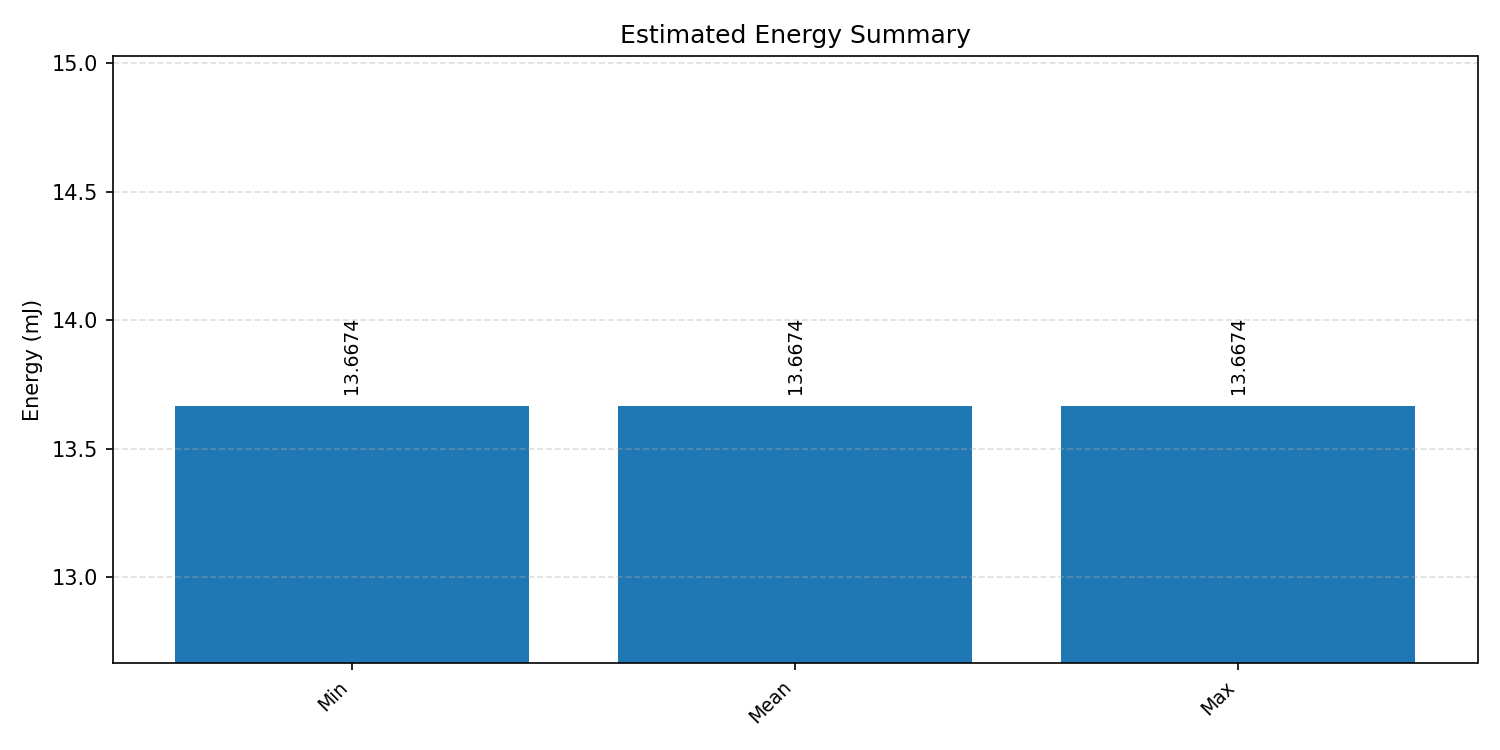
#1.4.2 (INT8) ARM + CPP#
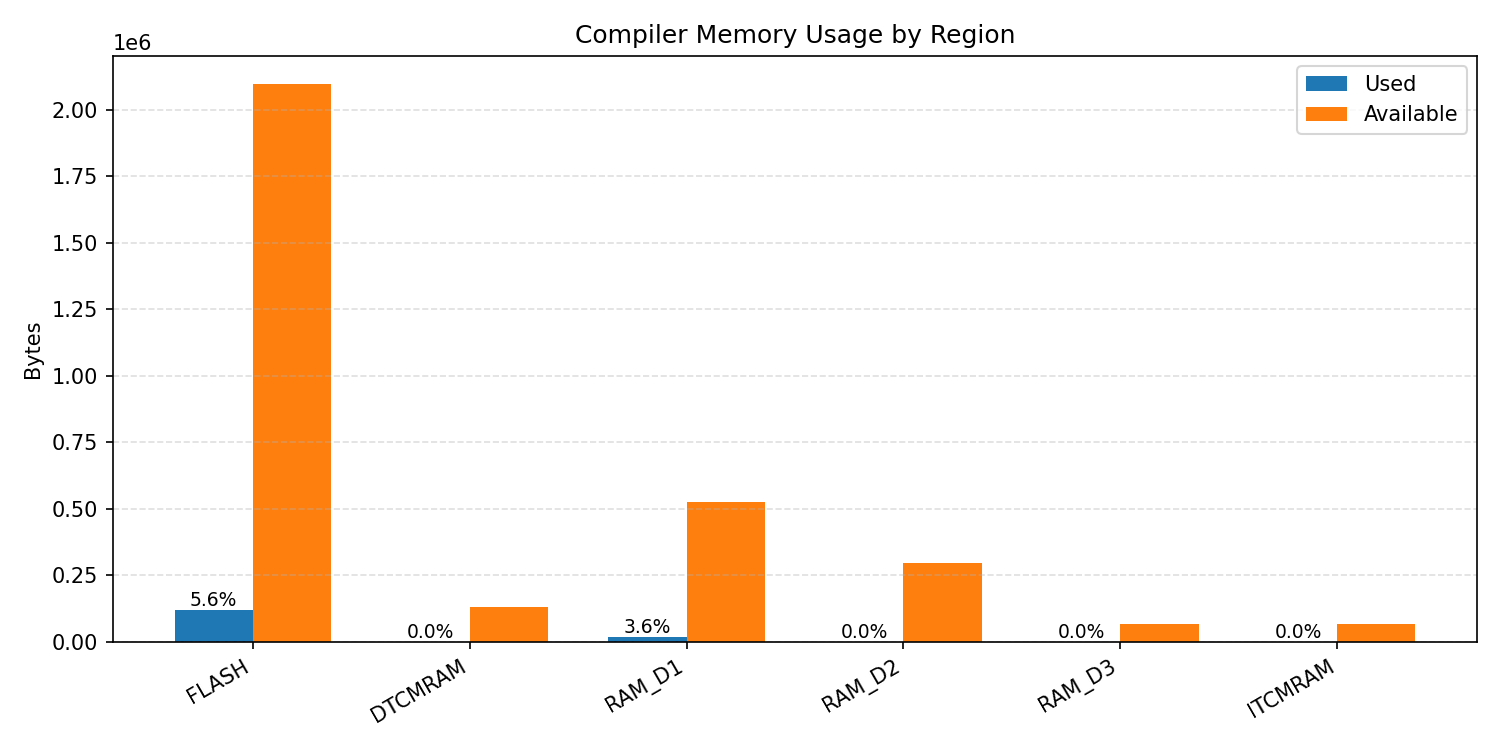
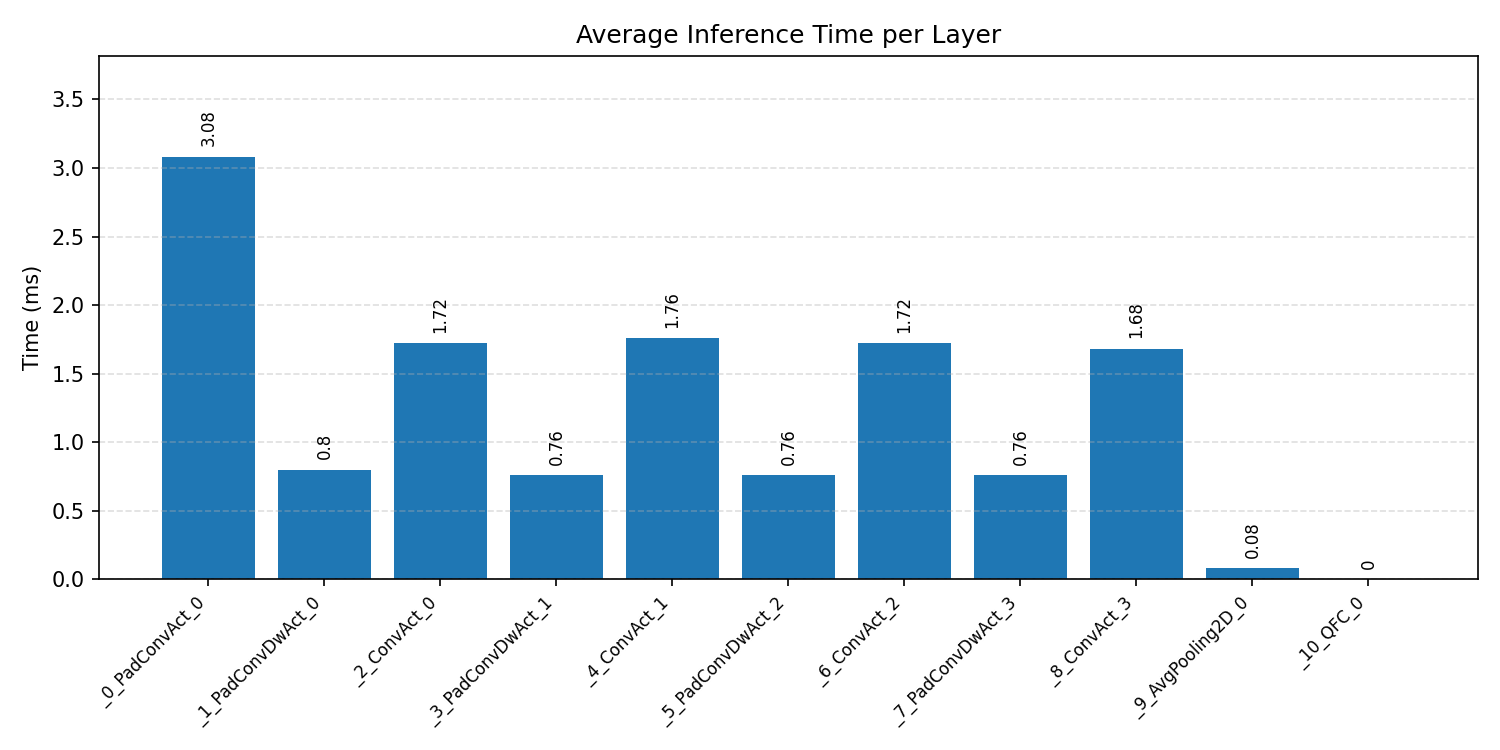
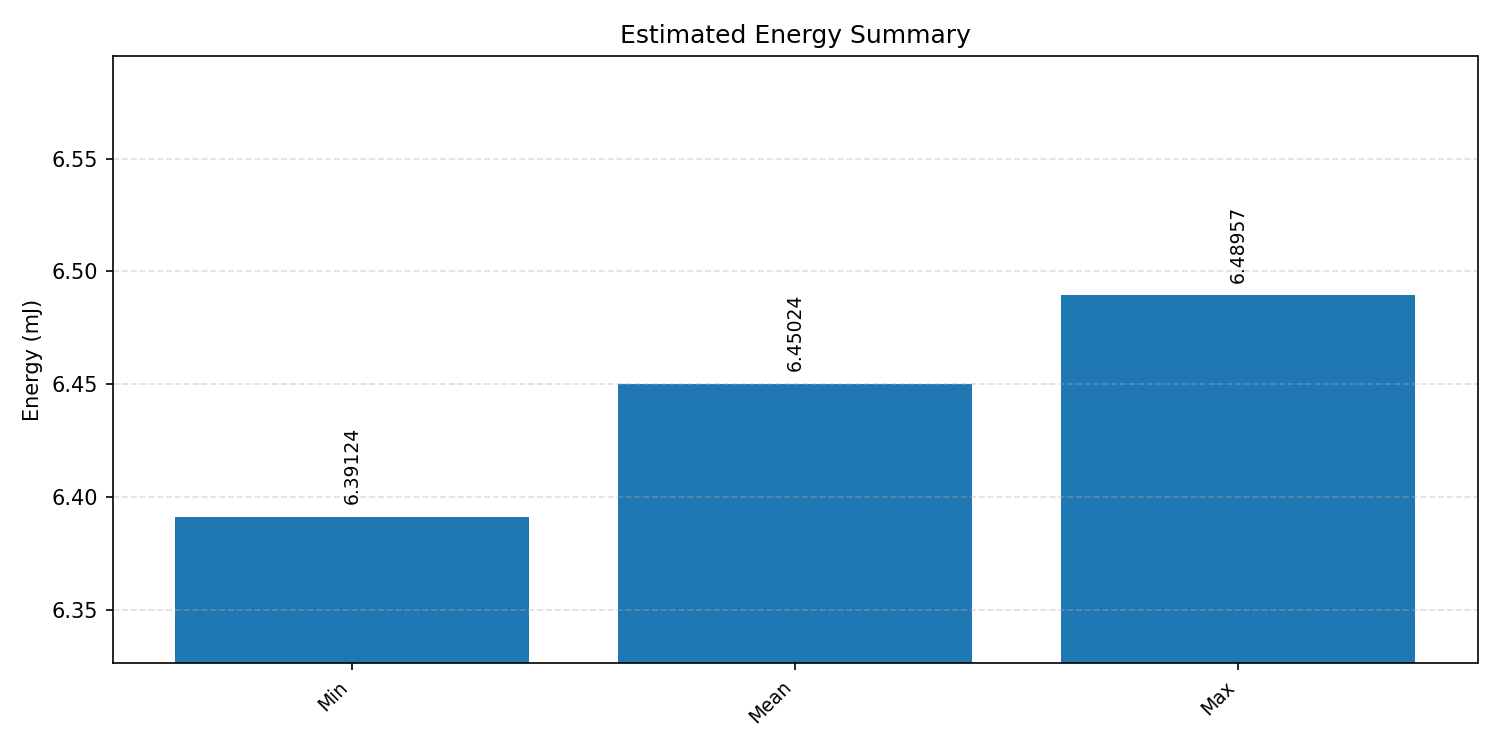
#1.4.3 (INT8) CMSIS + ARM + CPP#
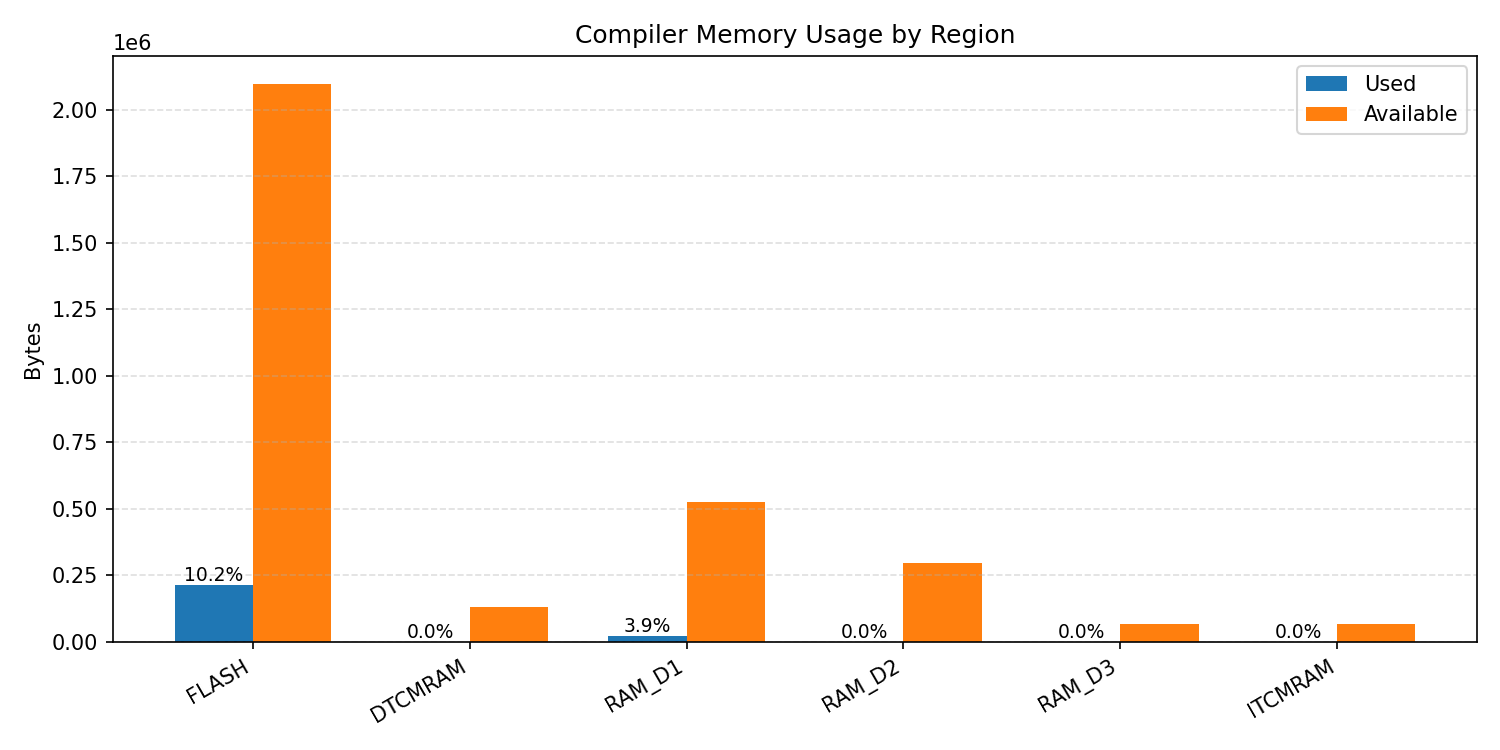
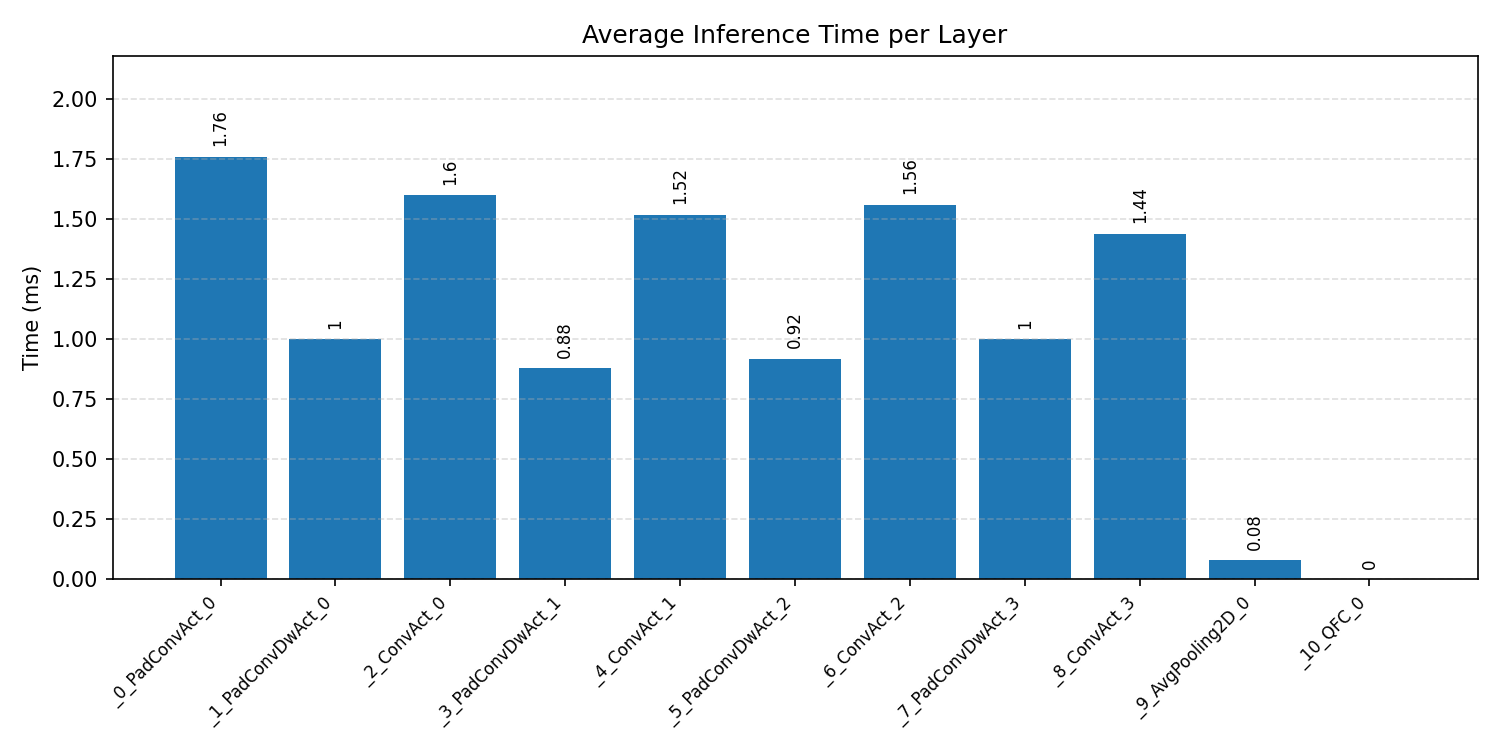
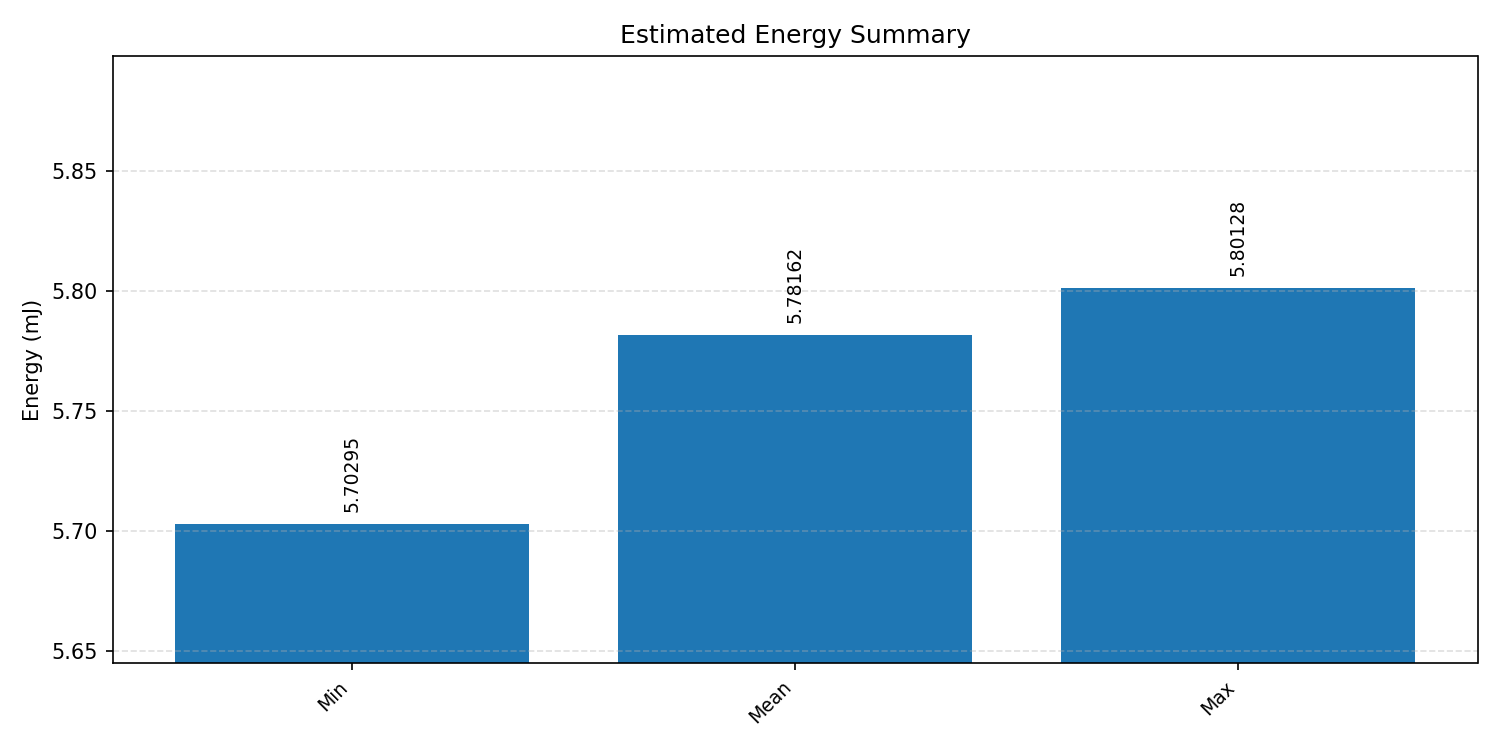
#1.5 Deep Autoencoder#
The deep autoencoder benchmark exercises a different model shape from the classification networks above. It is useful for inspecting runtime memory reuse and latency on encoder-decoder style graphs.
Comparison Chart
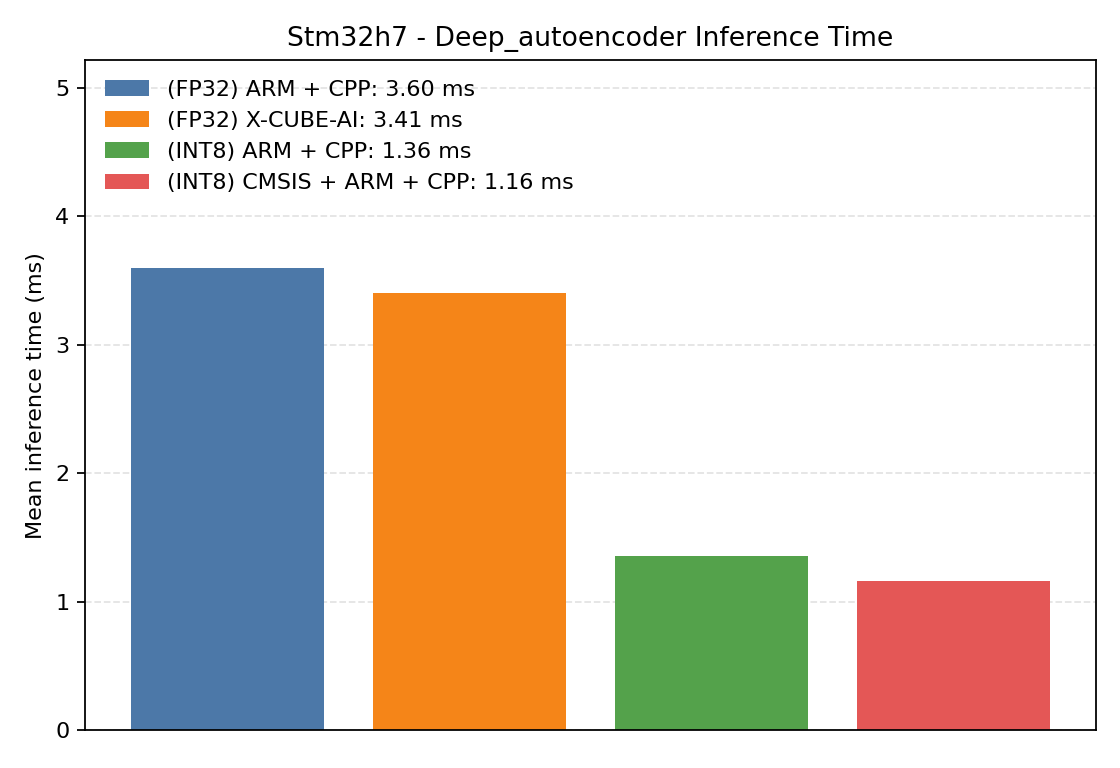
#1.5.1 (FP32) ARM + CPP#
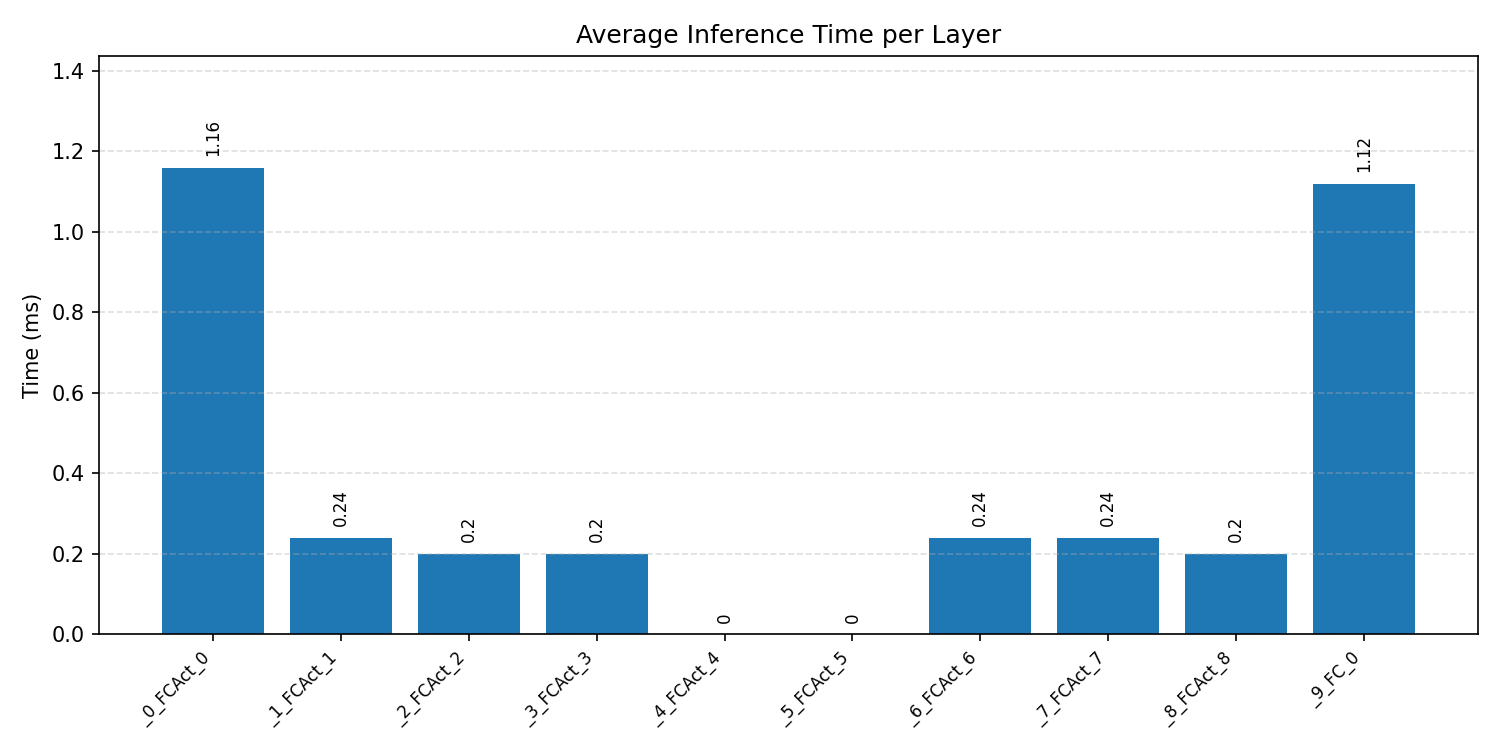
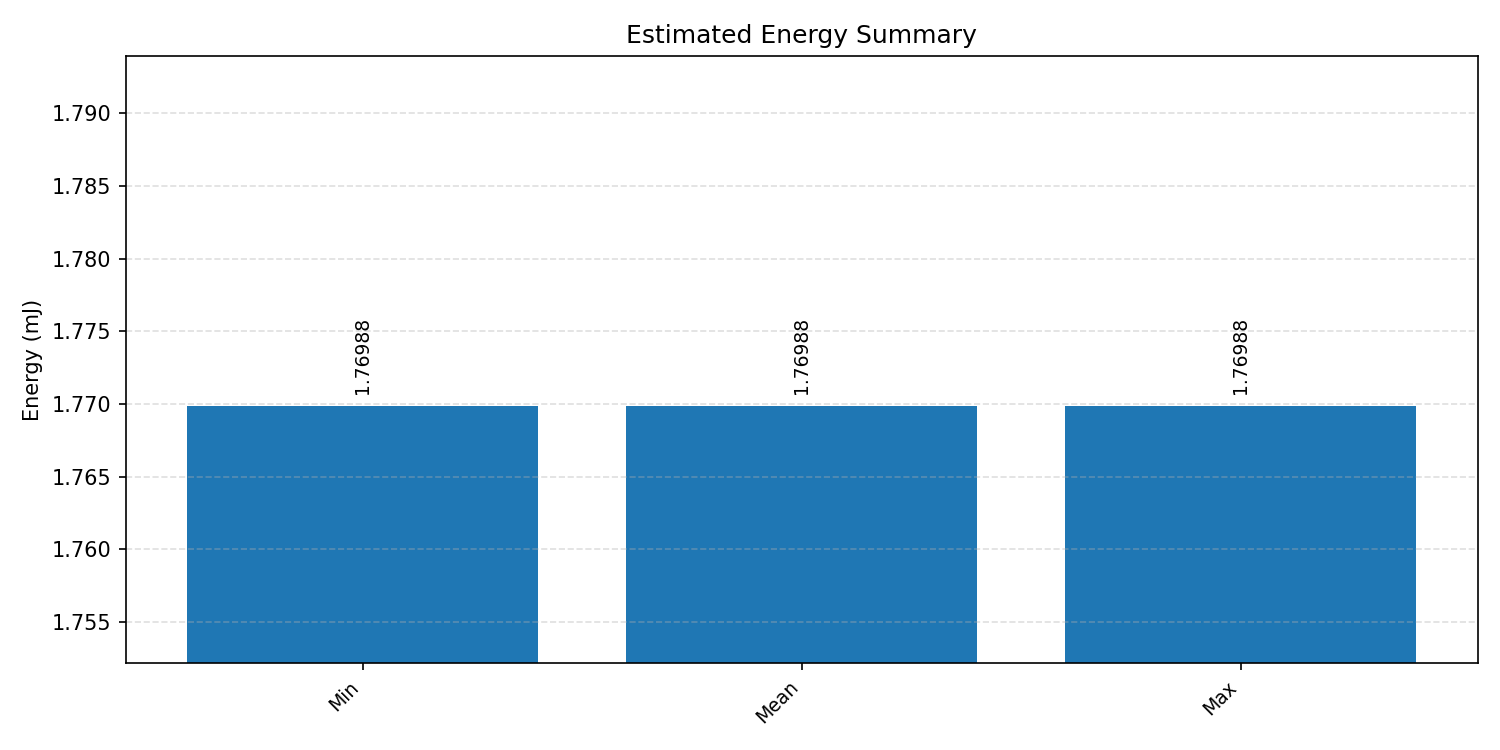
#1.5.2 (INT8) ARM + CPP#
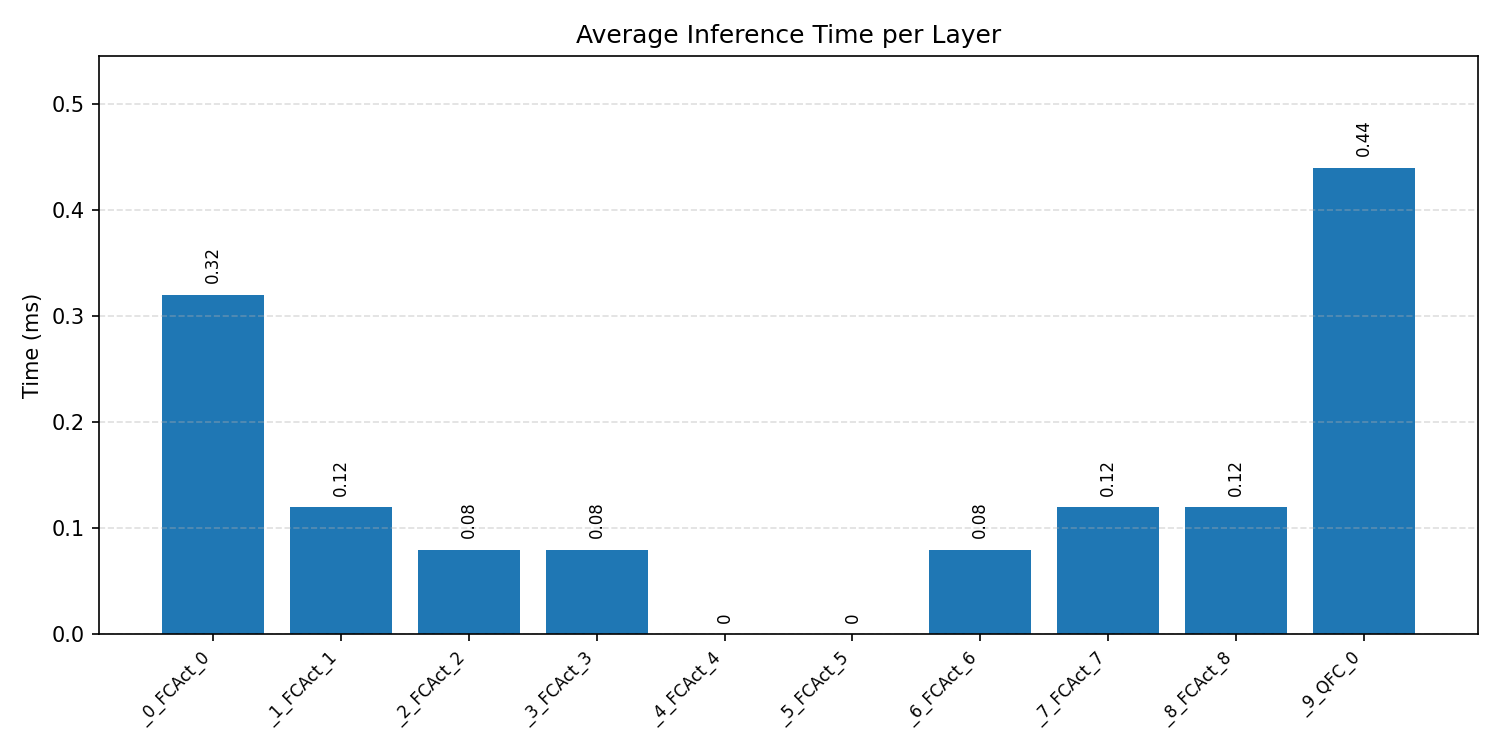
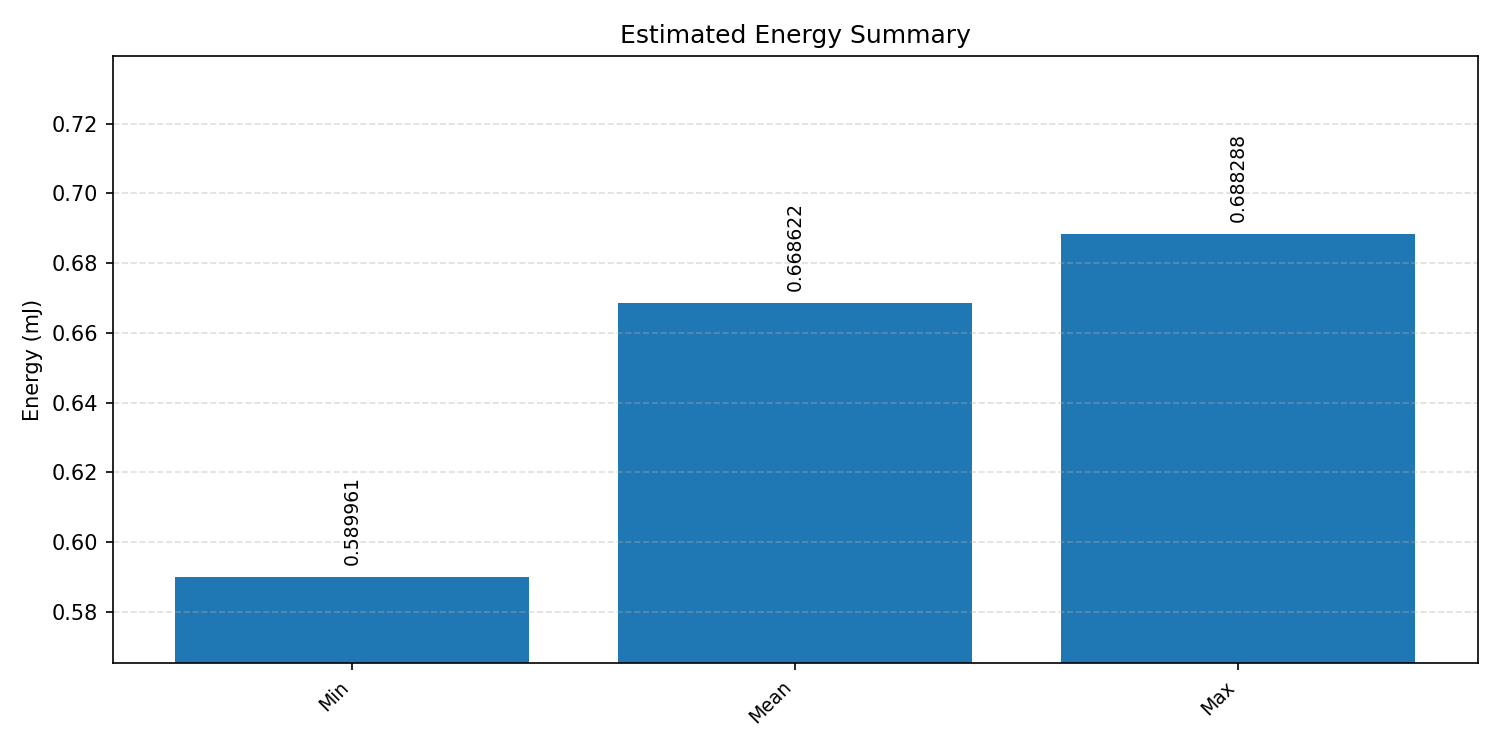
#1.5.3 (INT8) CMSIS + ARM + CPP#
#2. Jetson AGX Embedded Benchmarks#
The Jetson results show how the same models behave on an embedded GPU platform. Each case starts with the compiled Comparison Chart when available, followed by the detailed per-export benchmark graphs.
#2.1 LeNet MNIST#
Comparison Chart
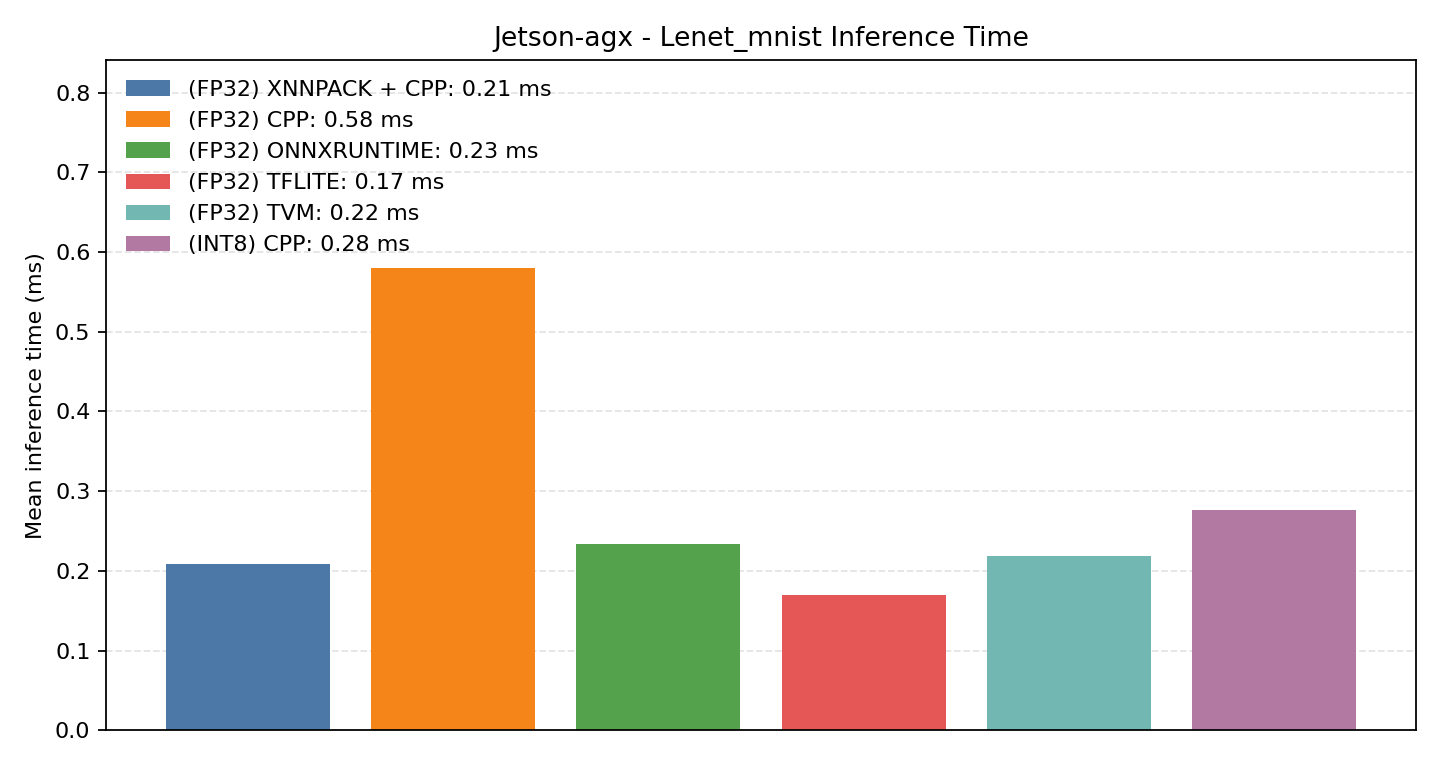
#2.1.1 (FP32) CPP#
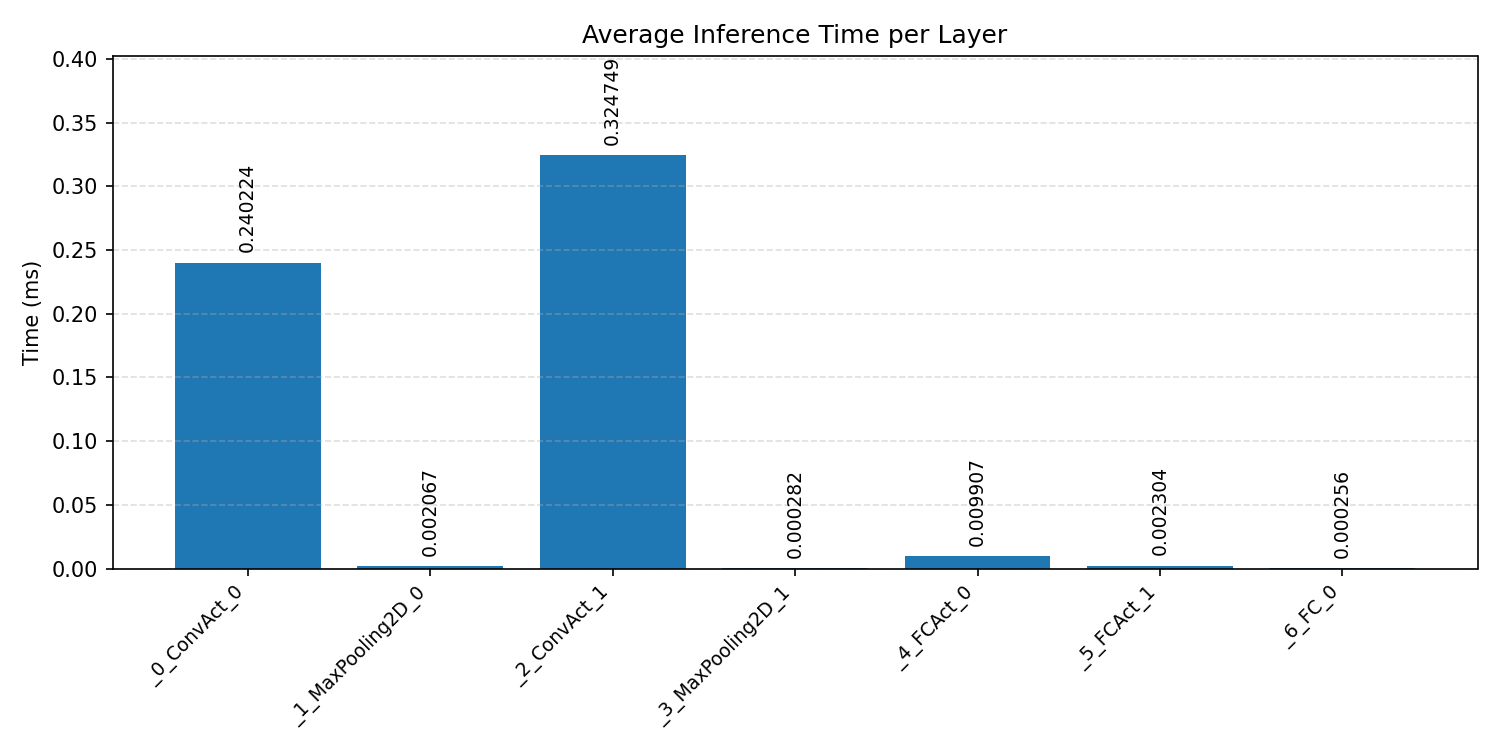
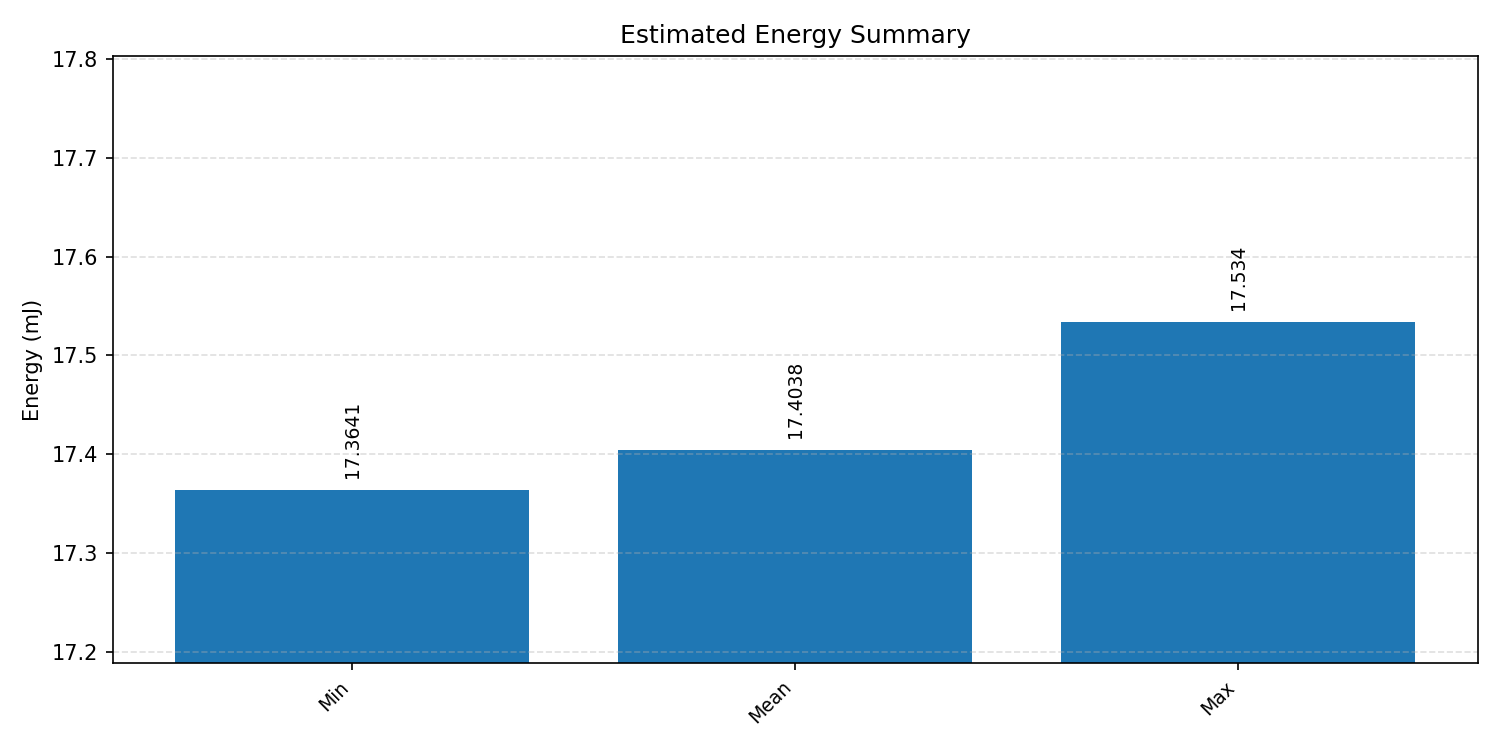
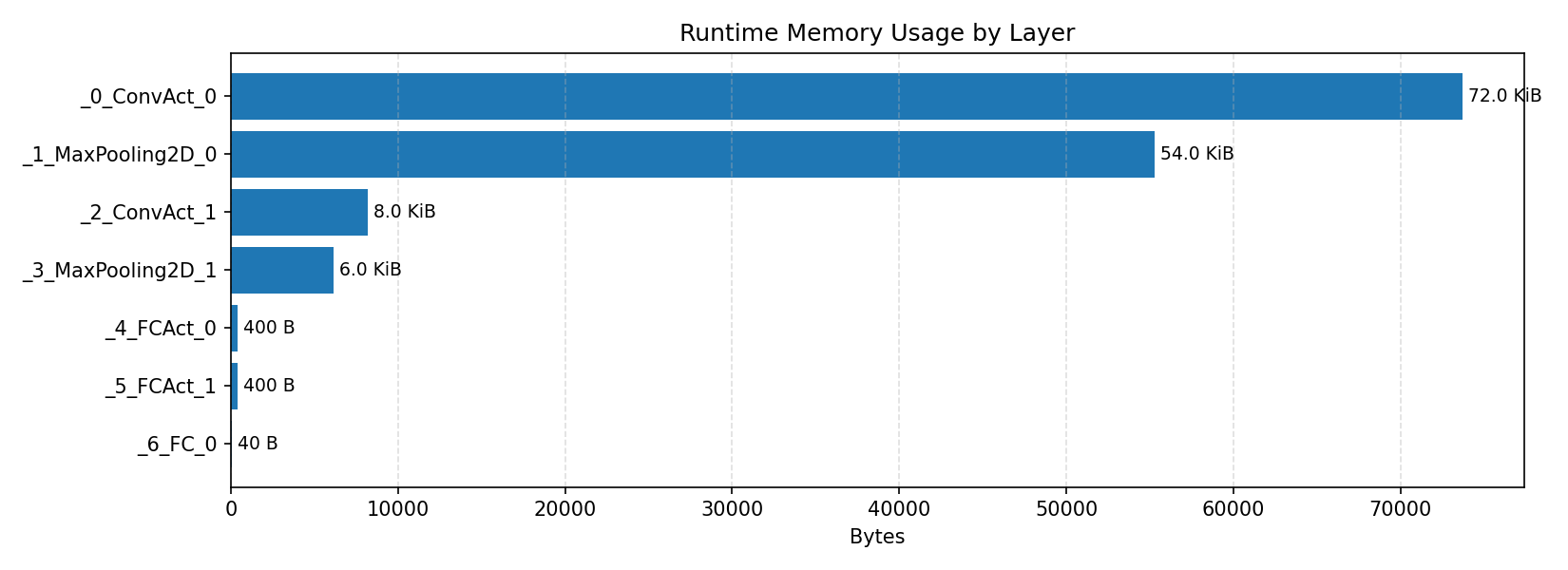
#2.1.2 (FP32) XNNPACK + CPP#
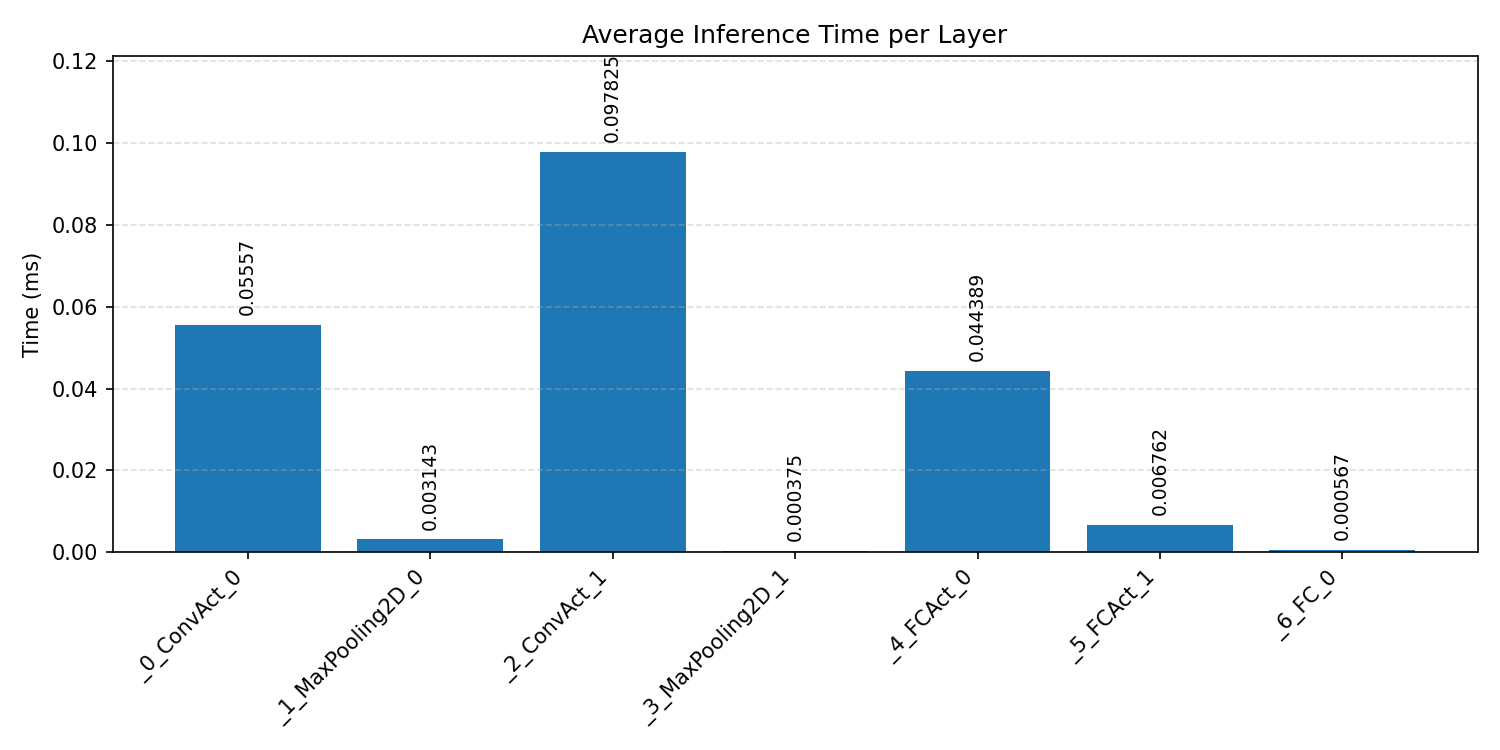
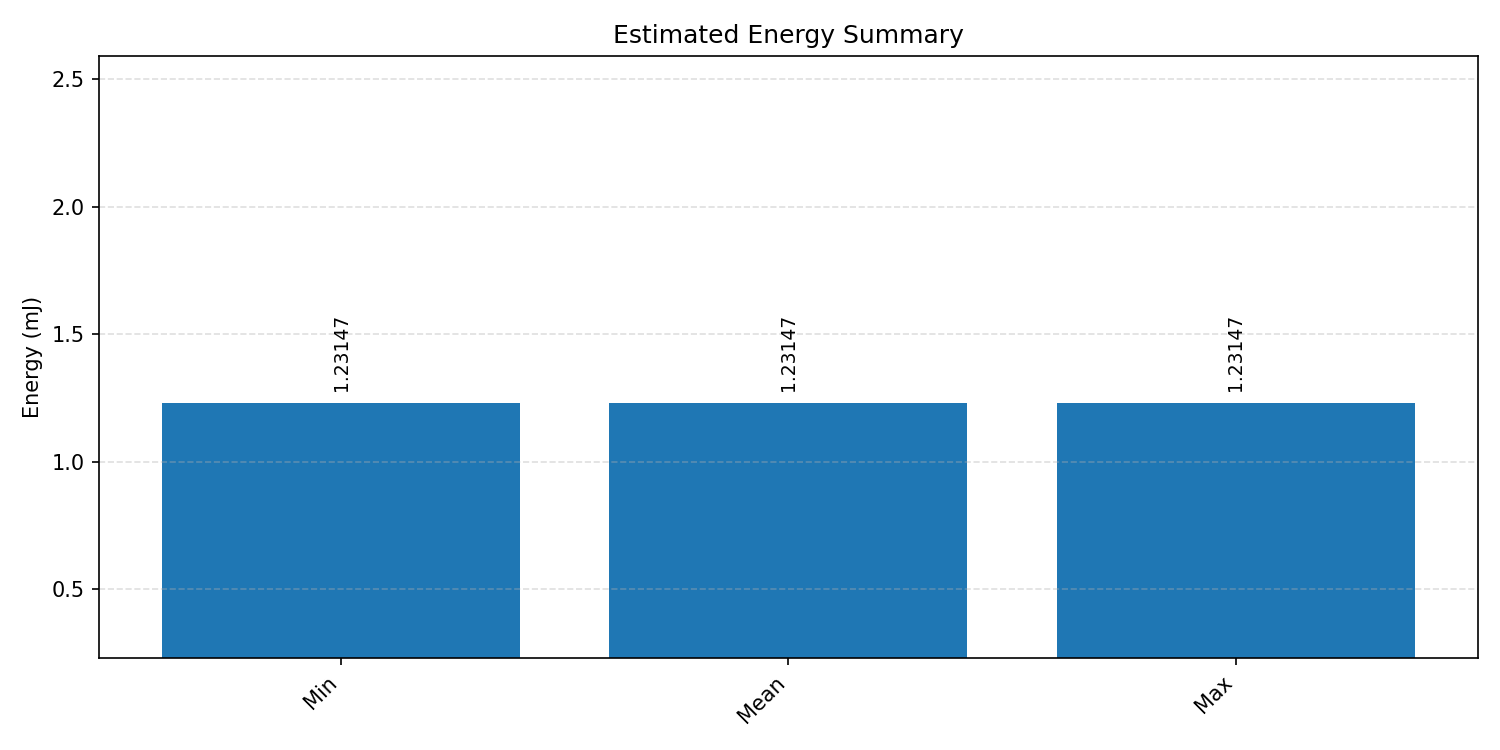
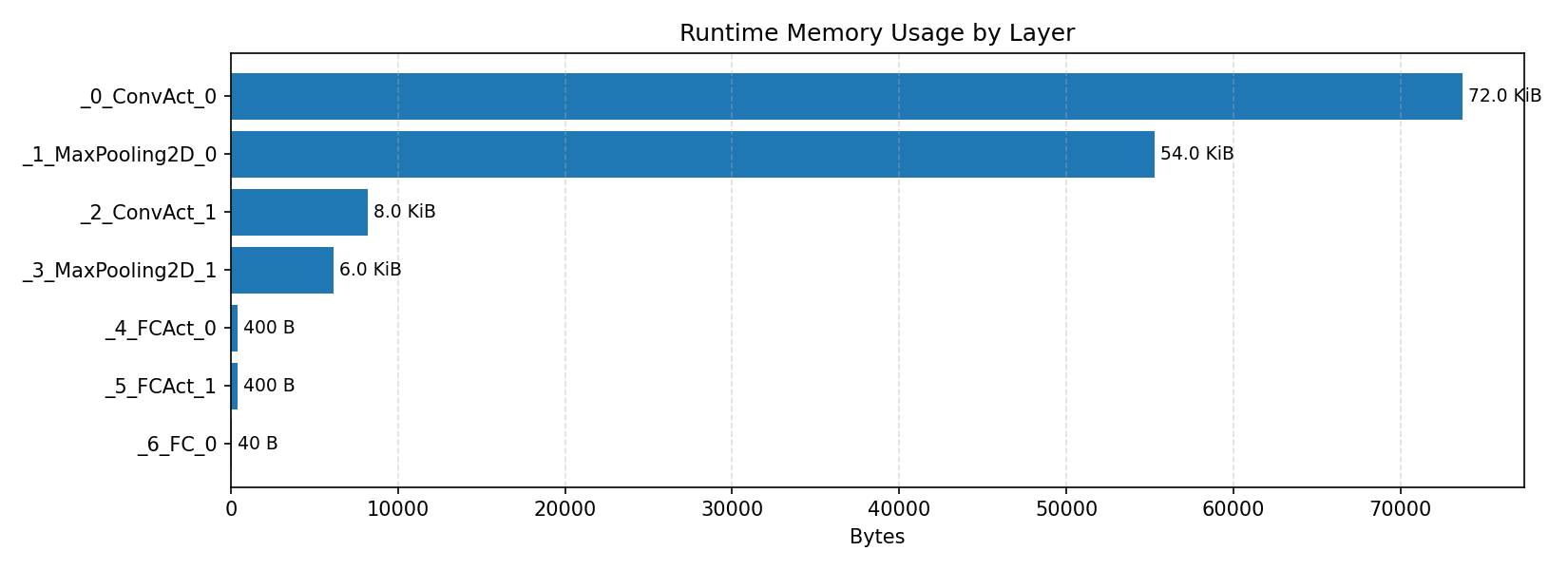
#2.1.3 (INT8) CPP#
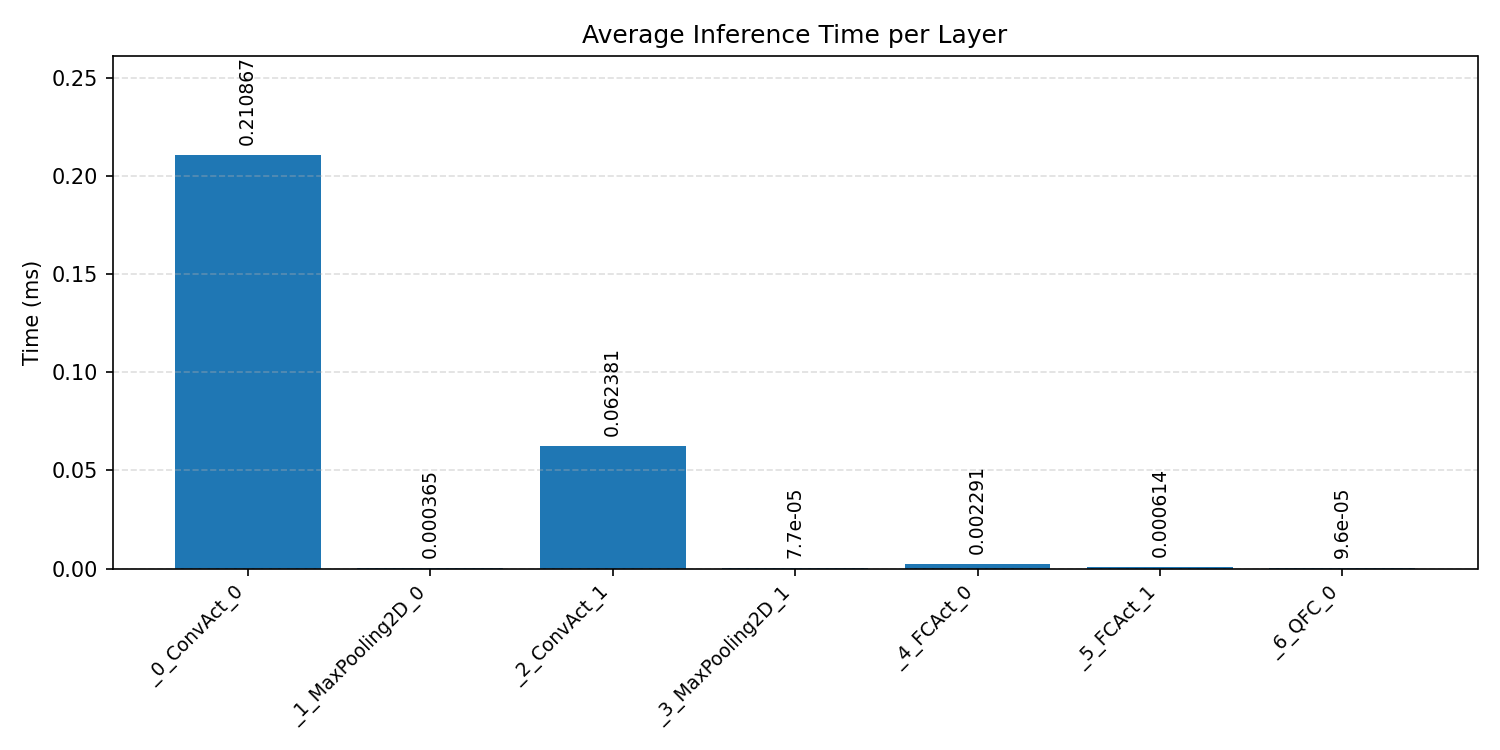
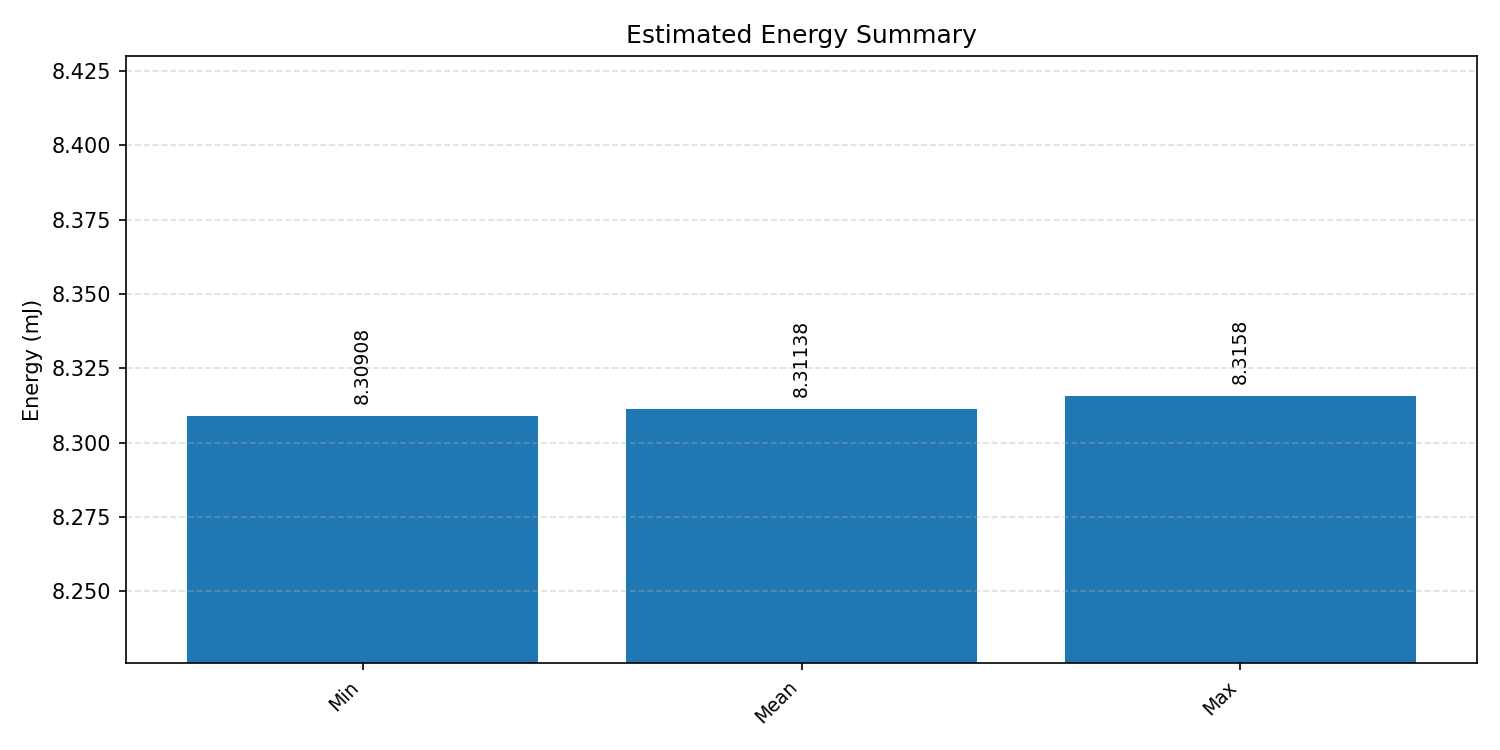
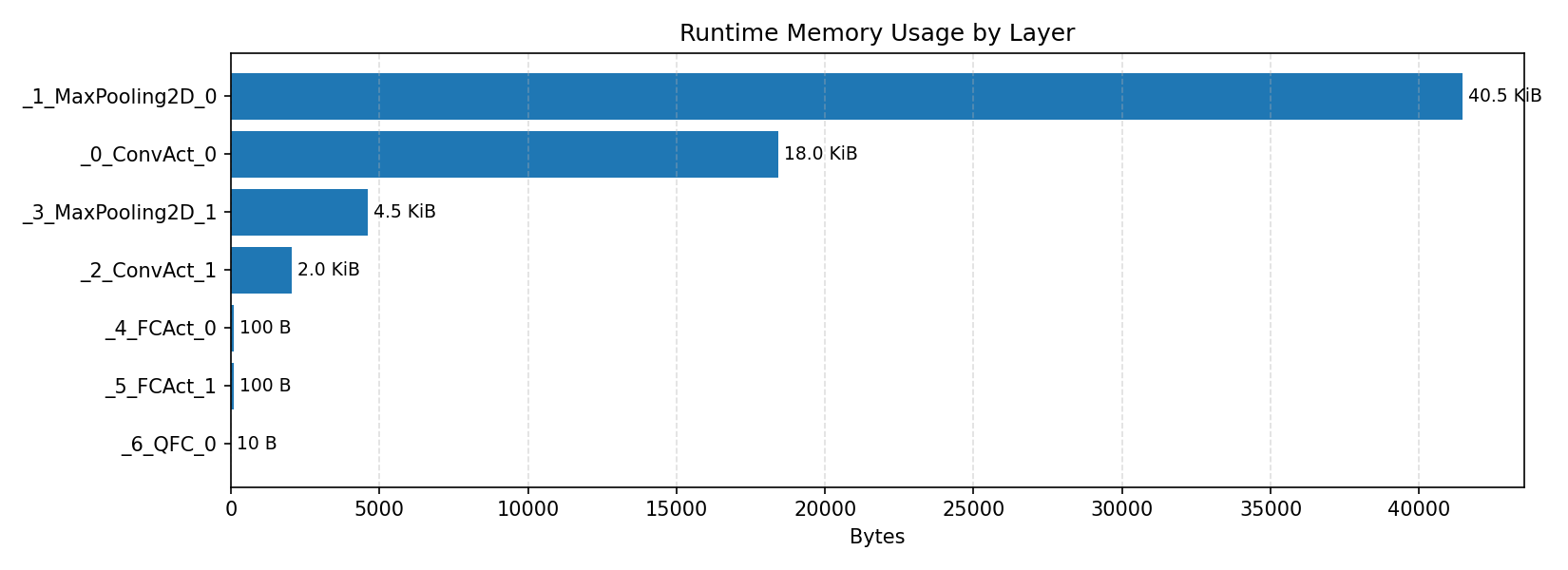
#2.2 MobileNet V1 VWW#
Comparison Chart
#2.2.1 (FP32) CPP#
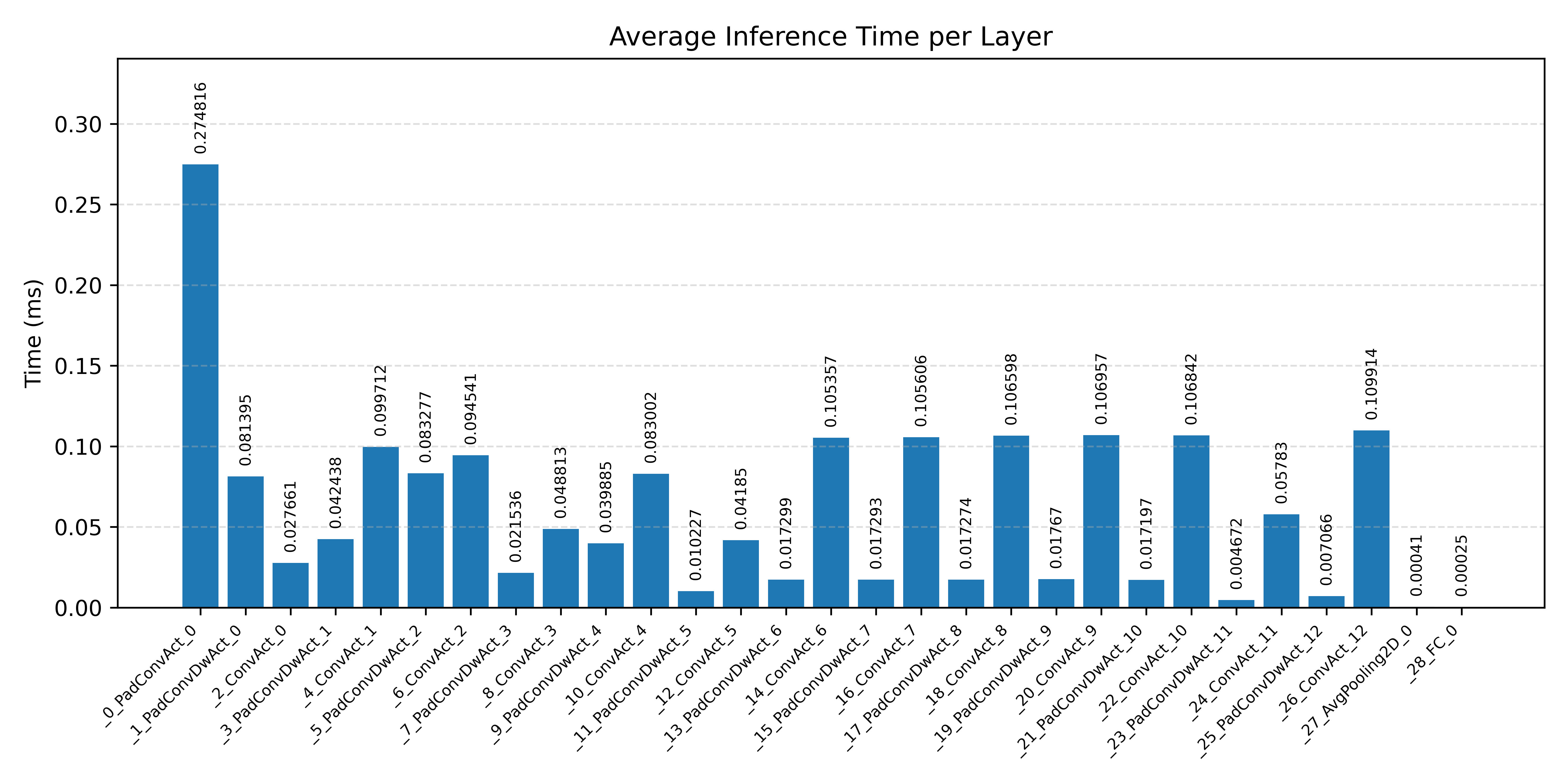
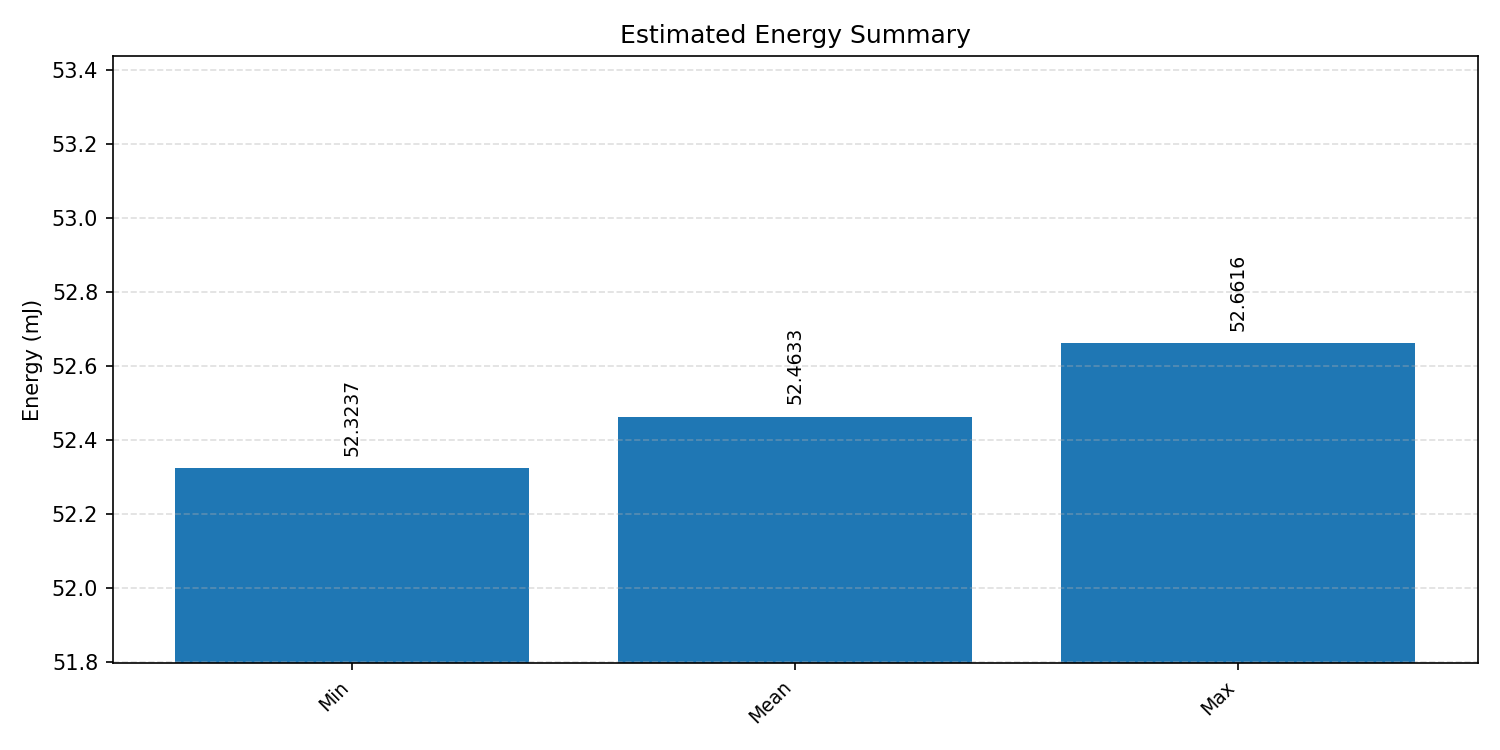
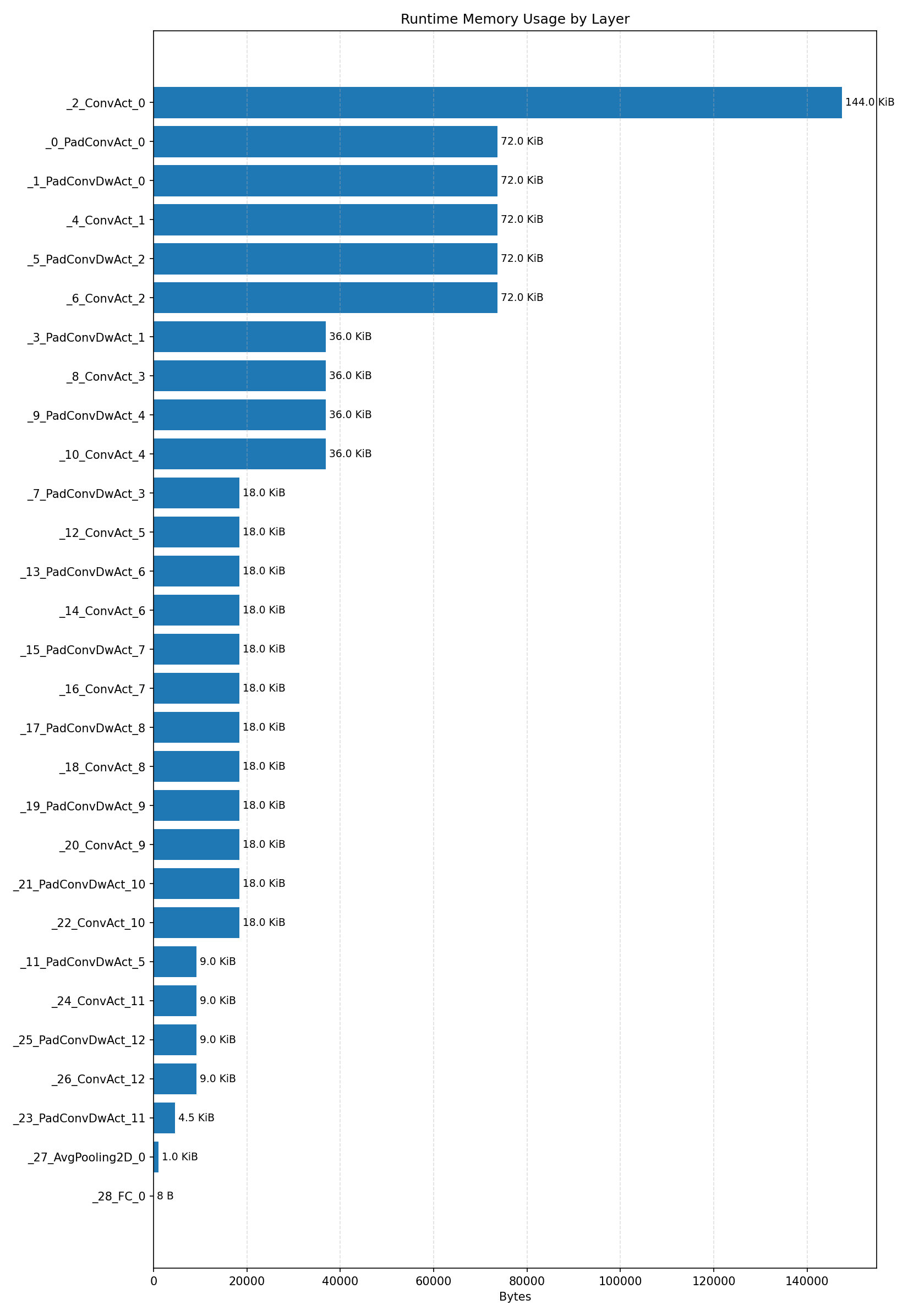
#2.2.2 (FP32) XNNPACK + CPP#
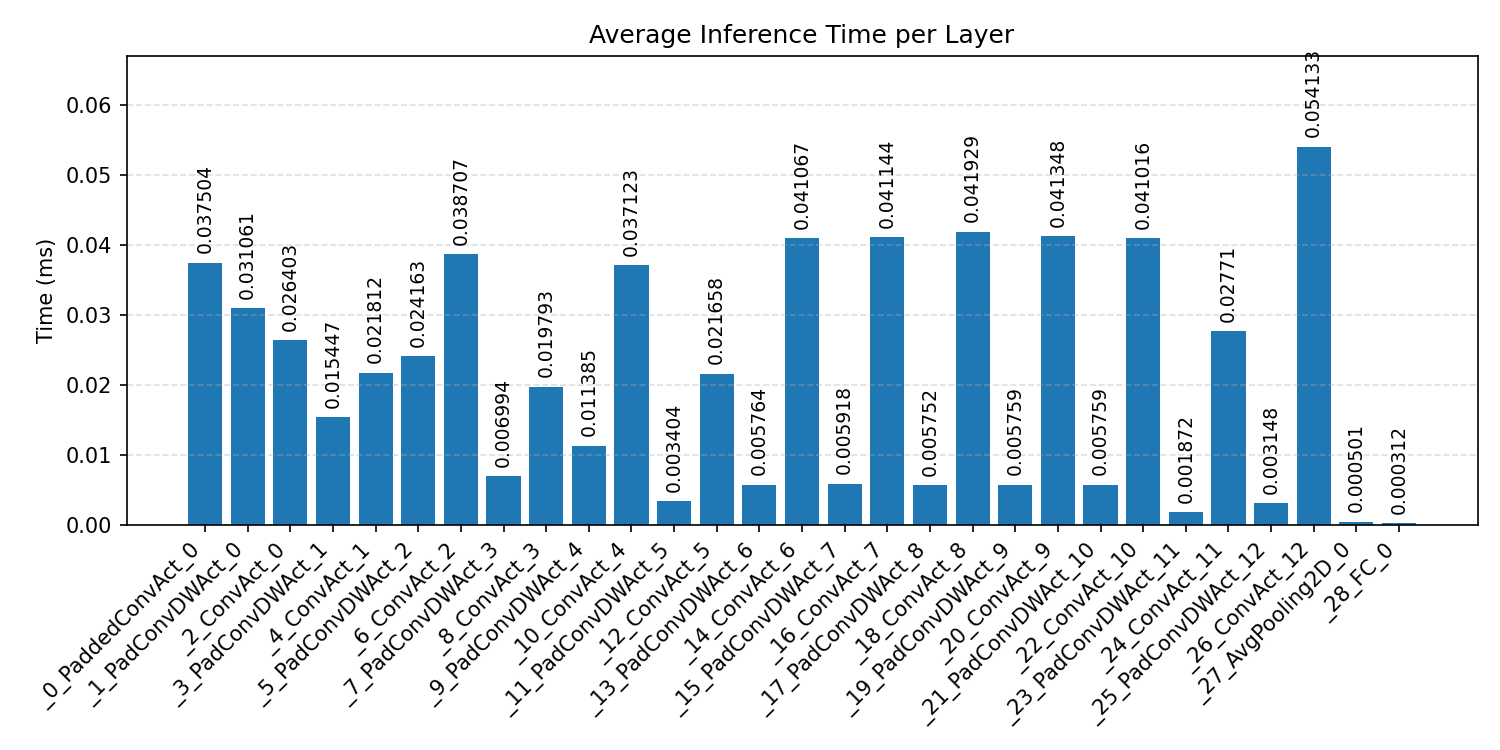
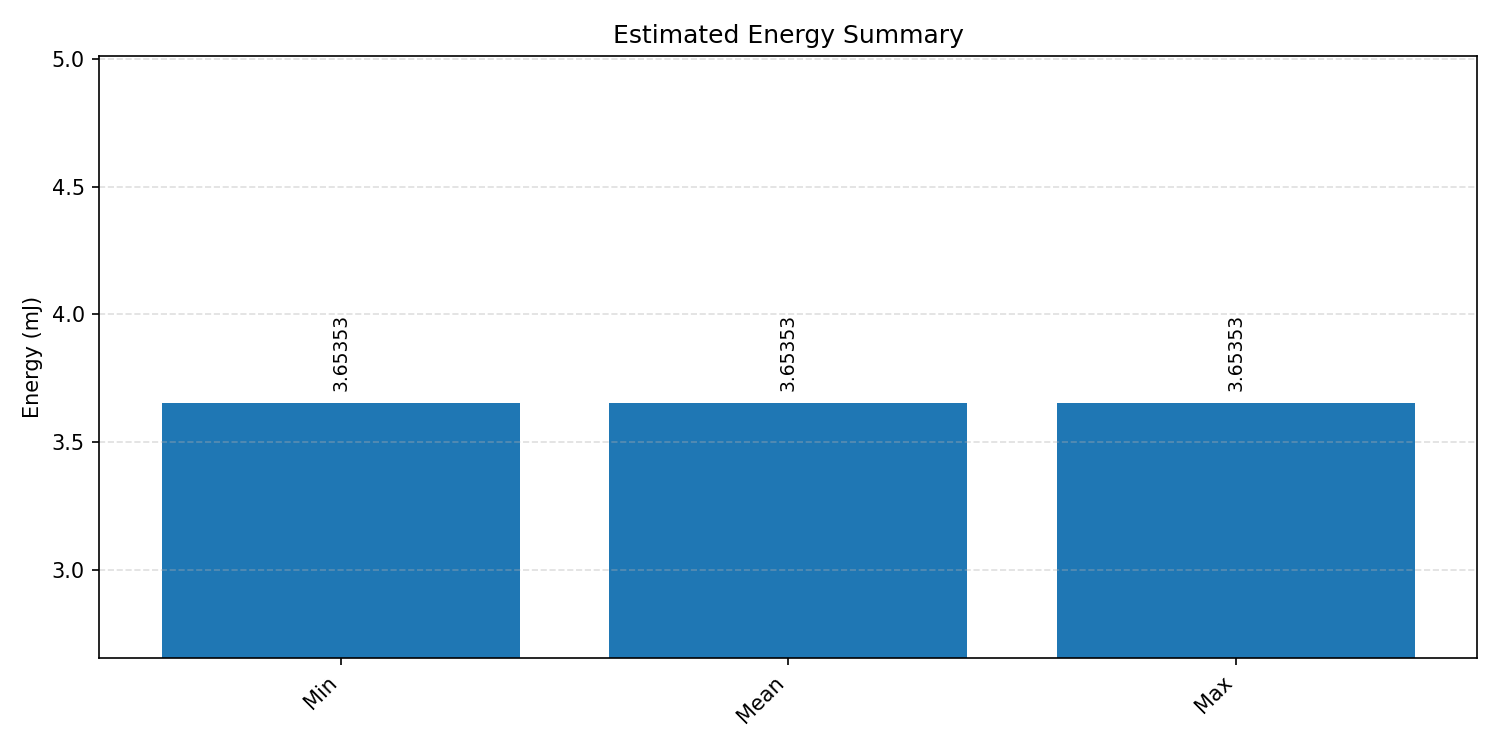
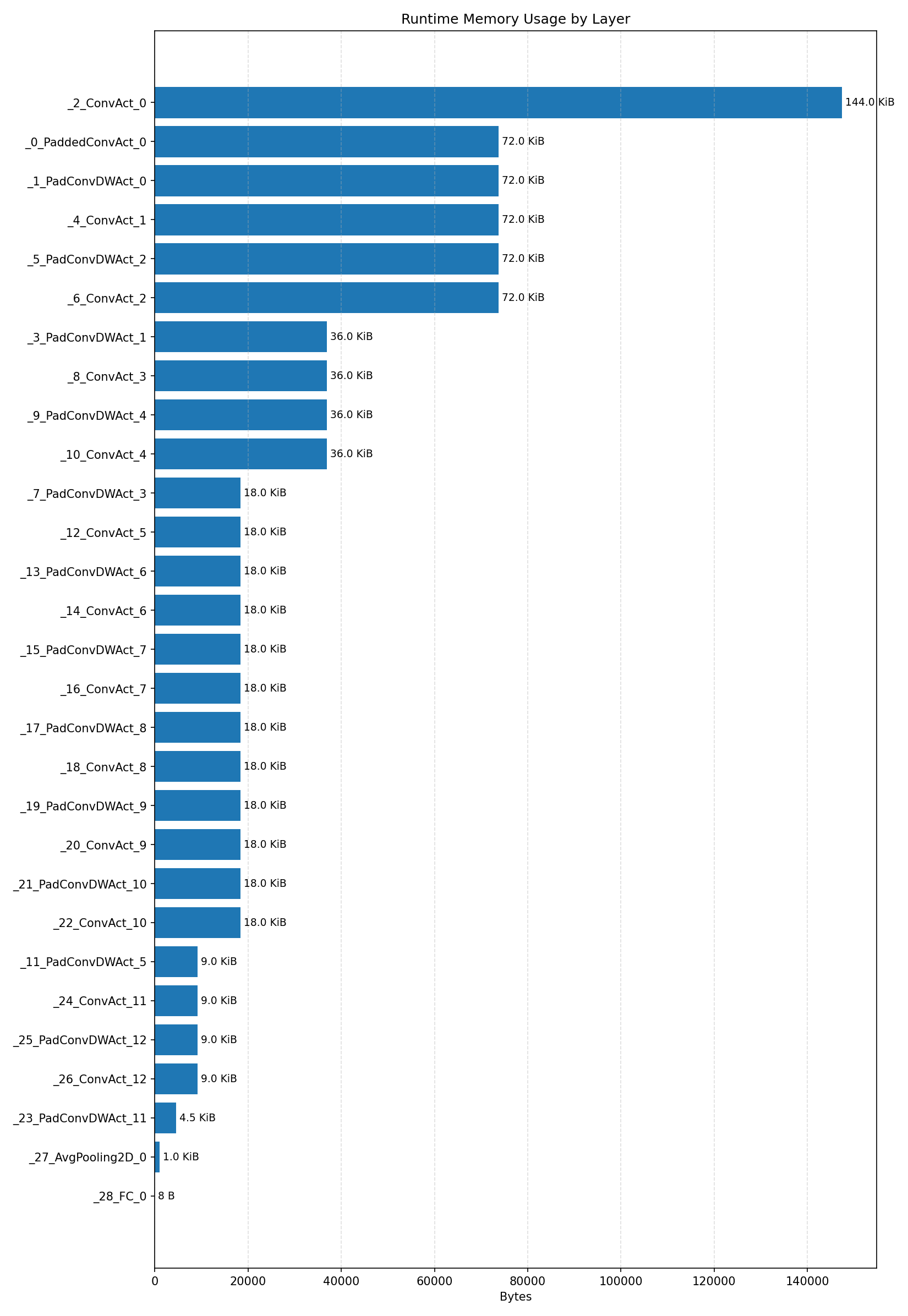
#2.2.3 (INT8) CPP#
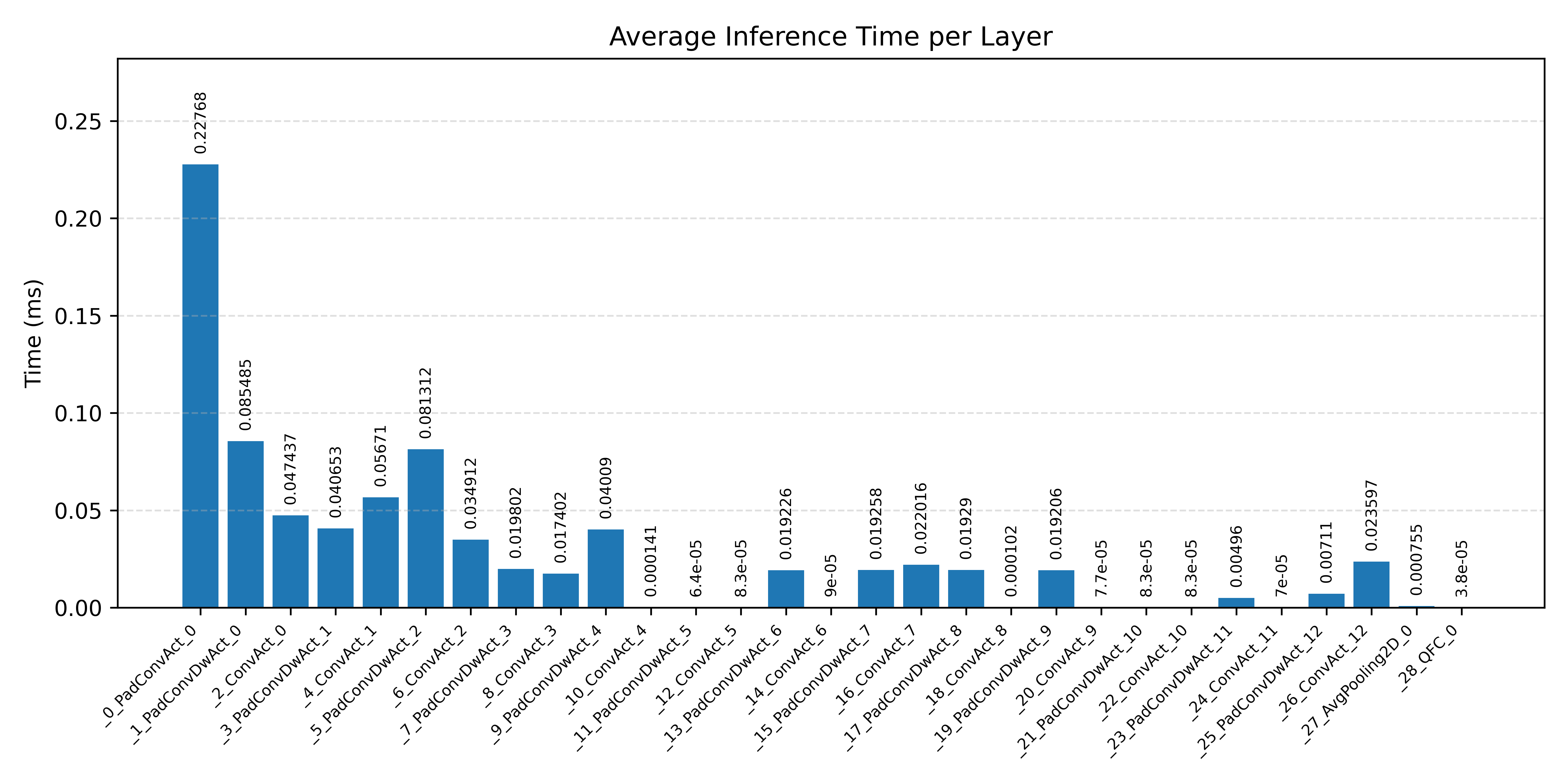
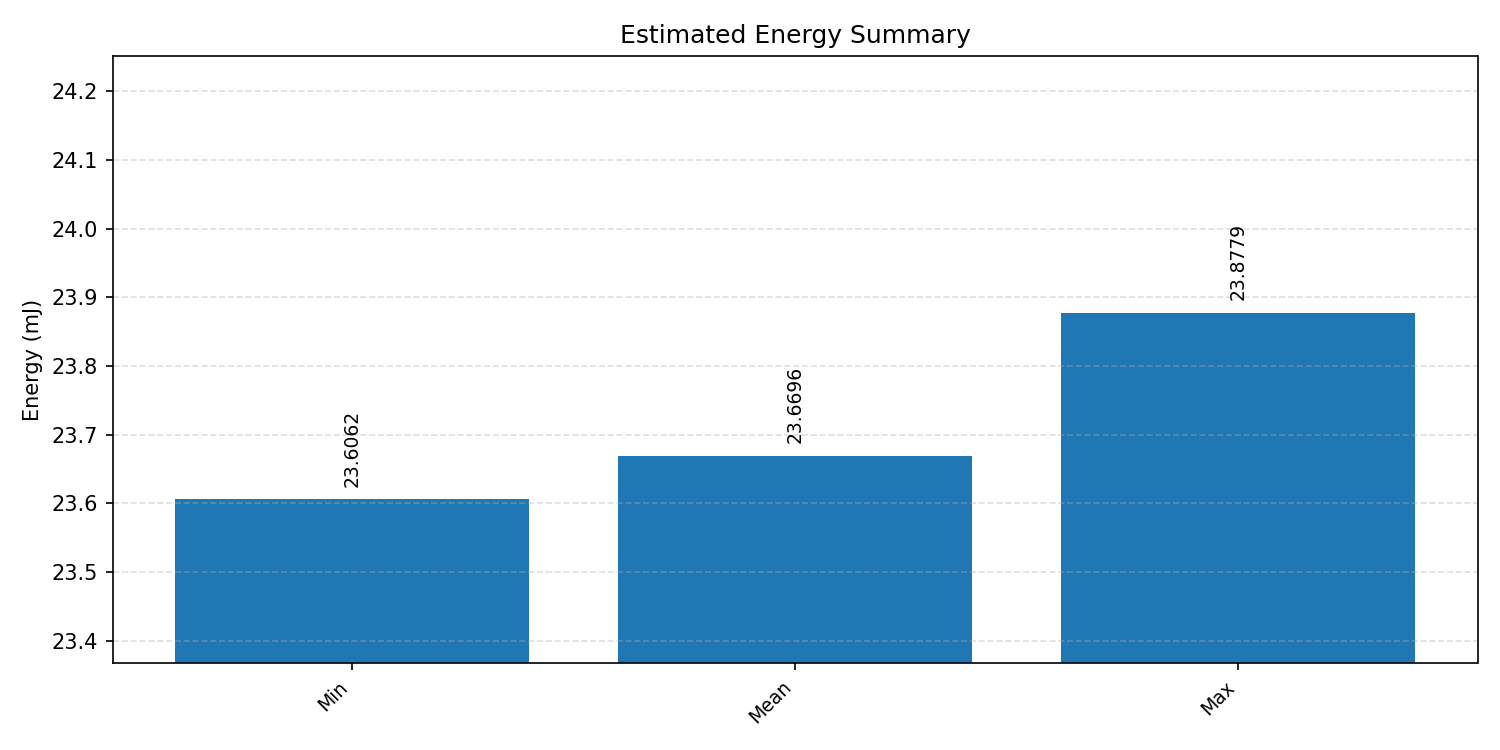
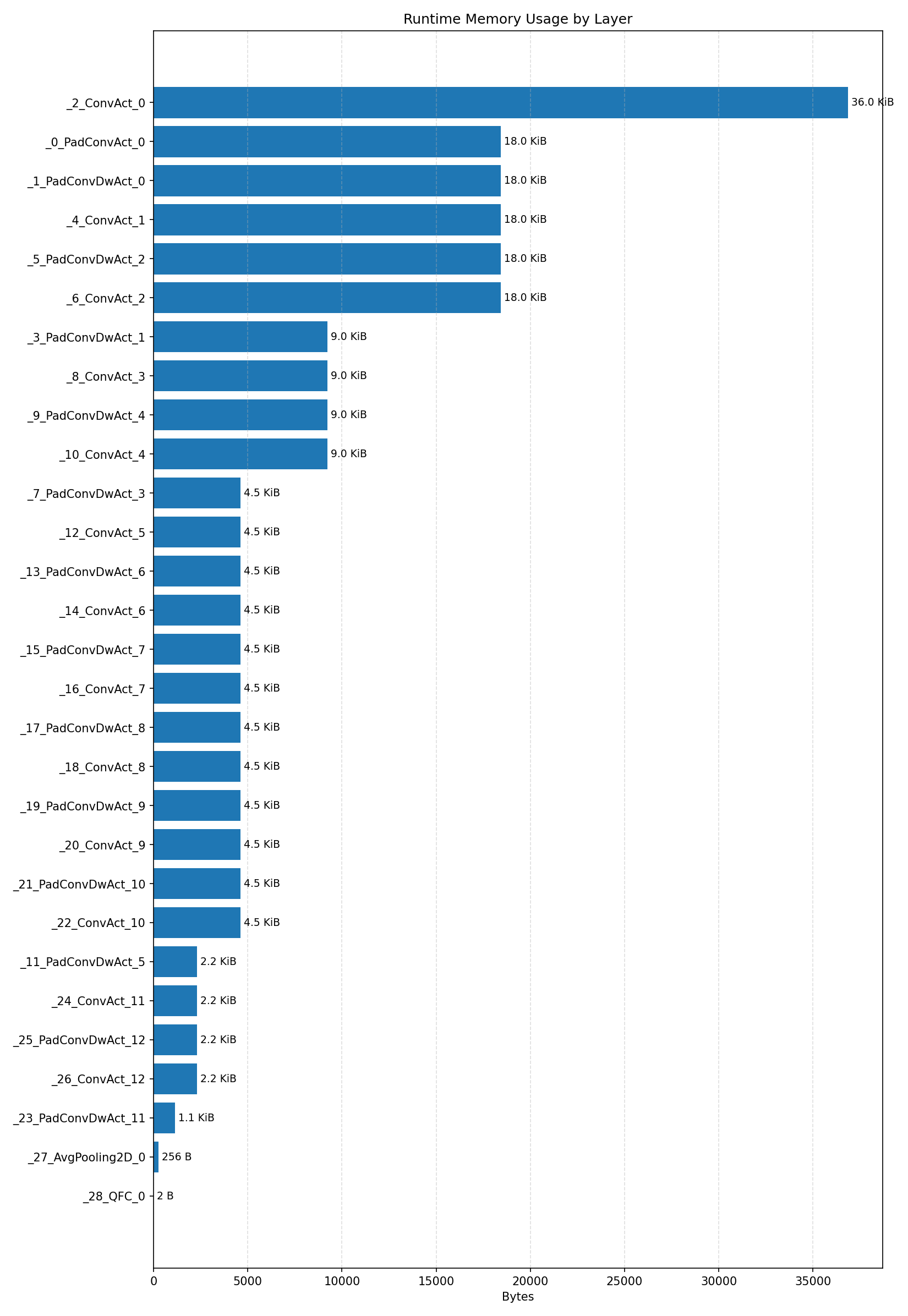
#2.3 ResNet8 CIFAR-10#
Comparison Chart
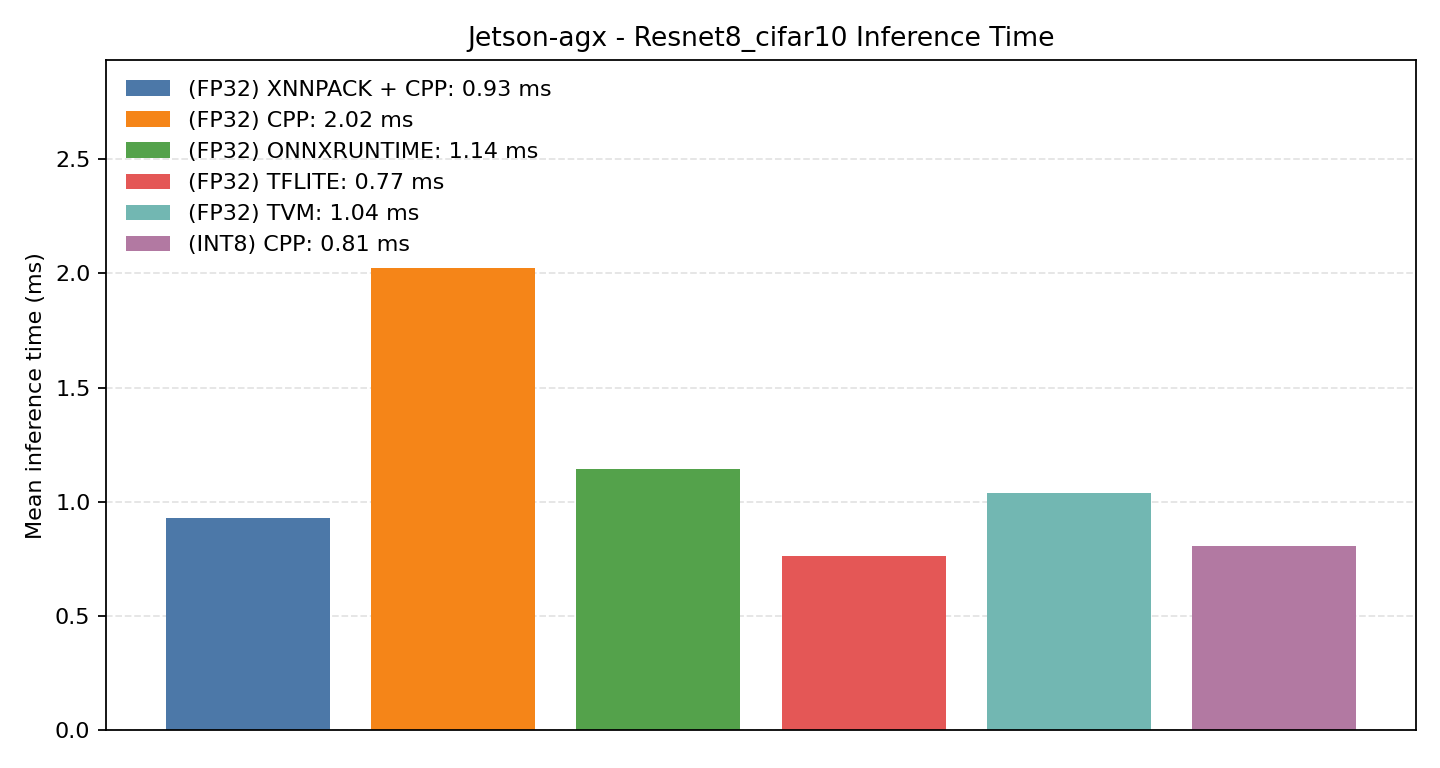
#2.3.1 (FP32) CPP#
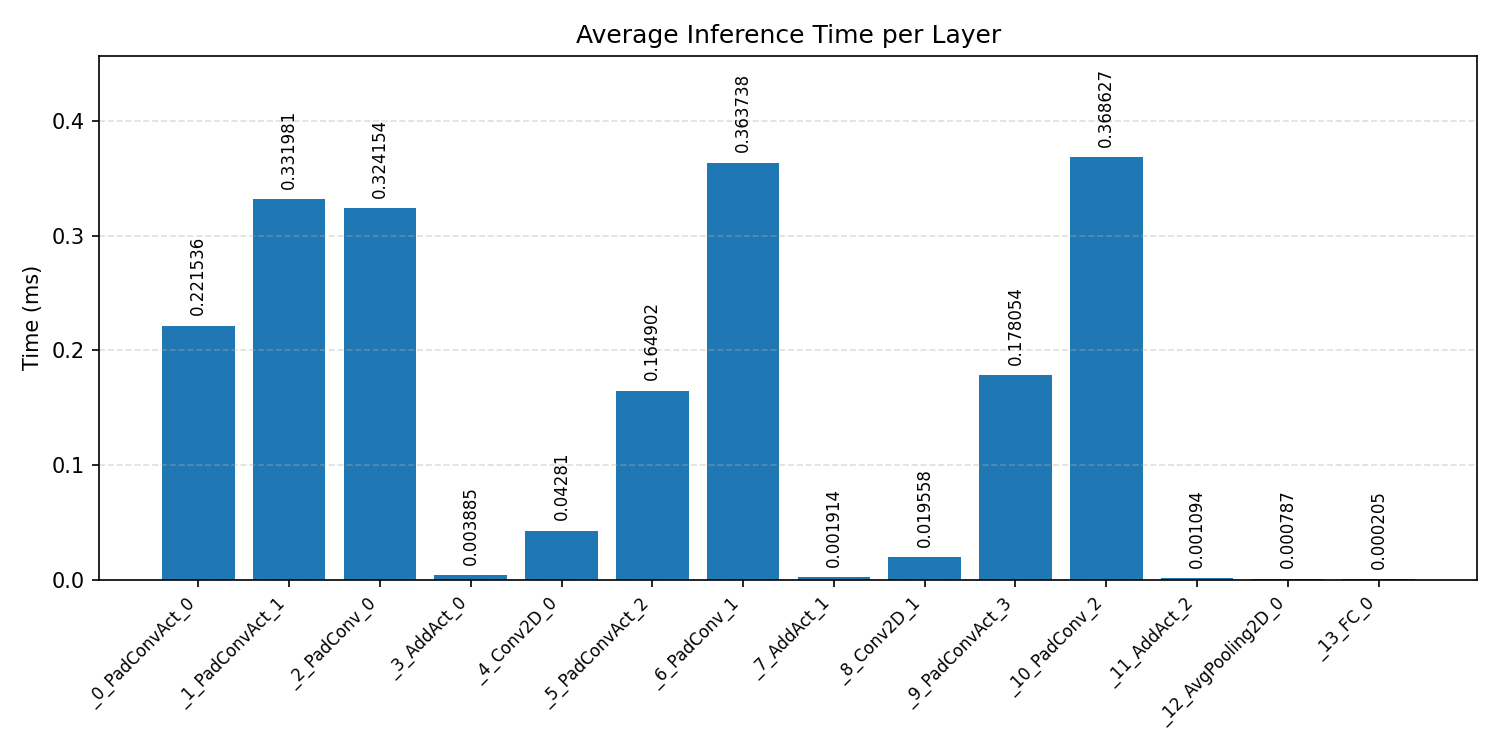
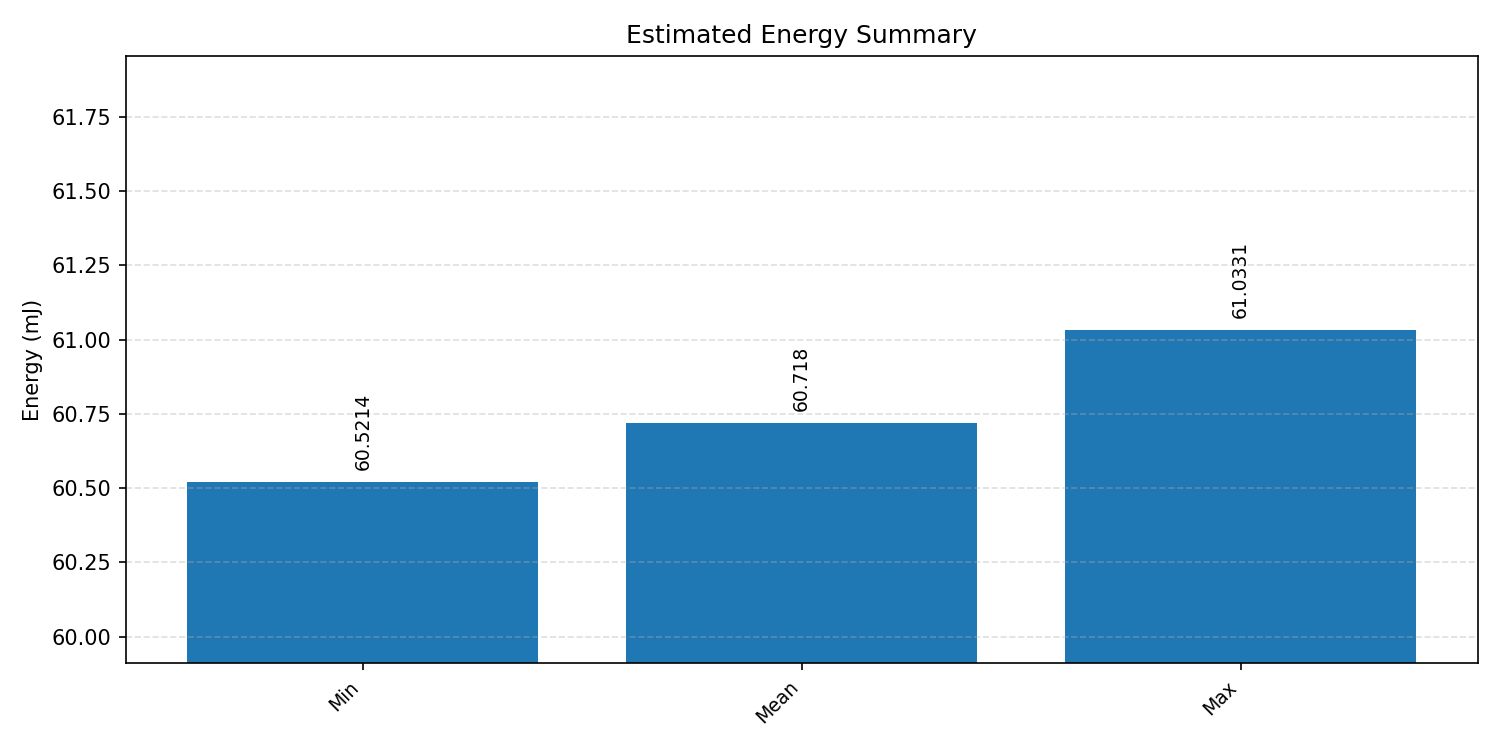
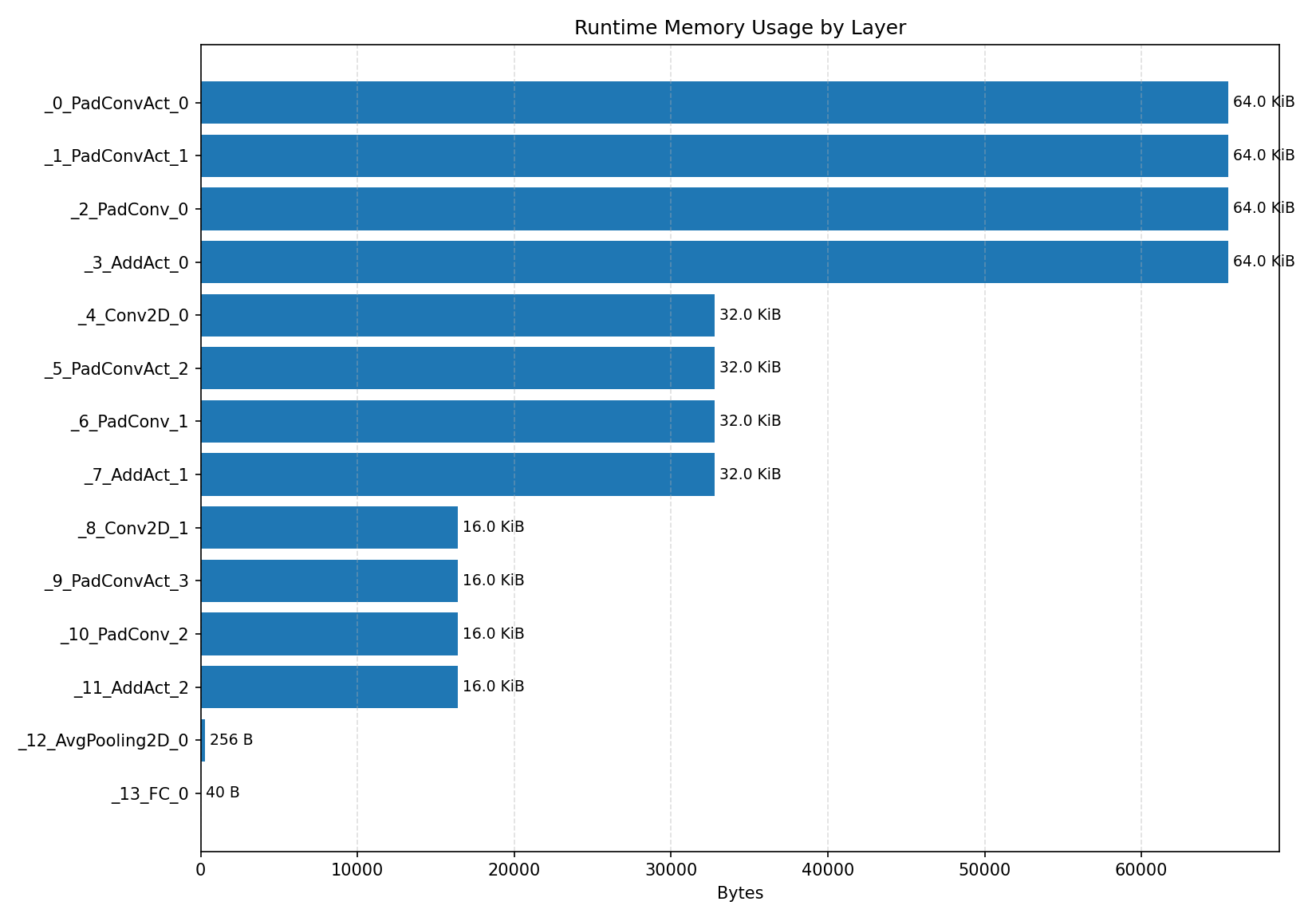
#2.3.2 (FP32) XNNPACK + CPP#
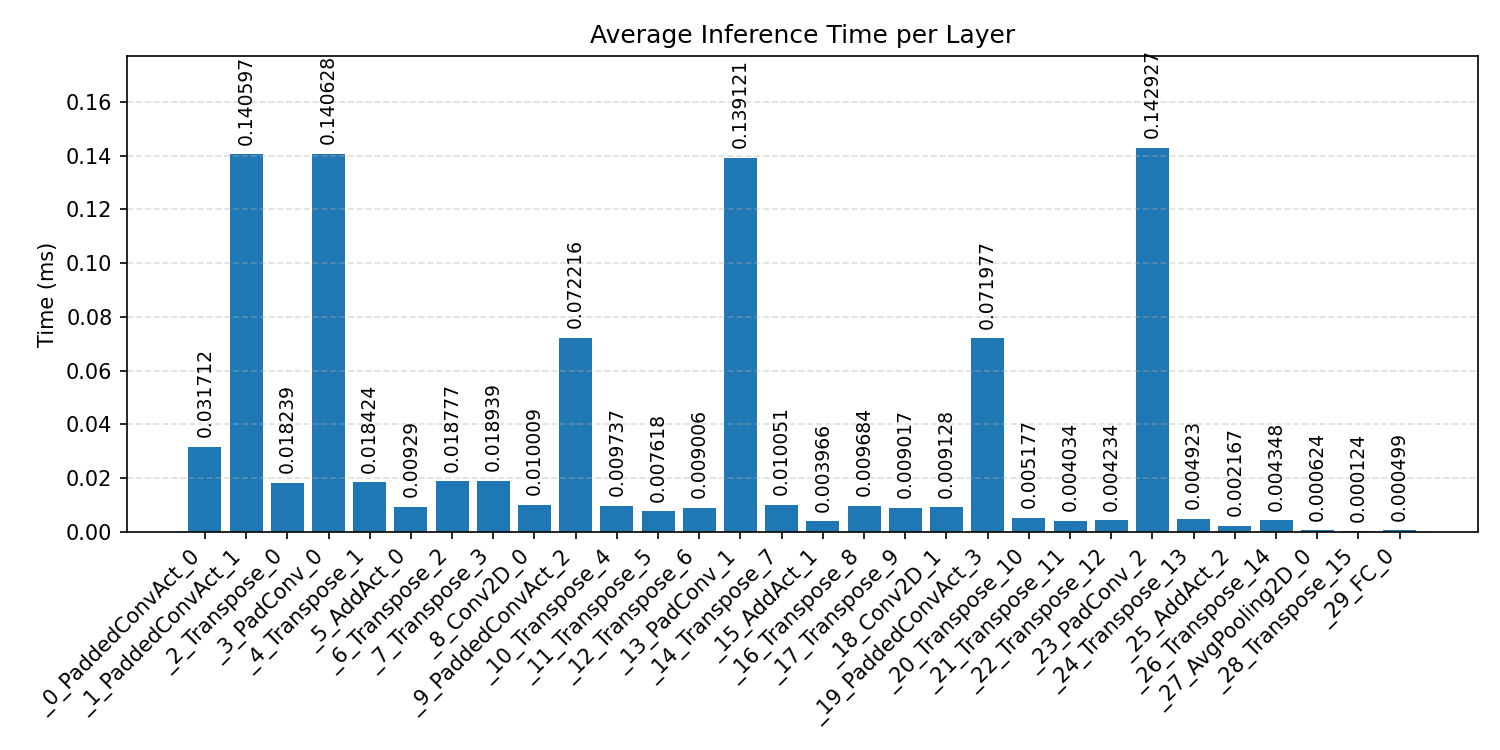
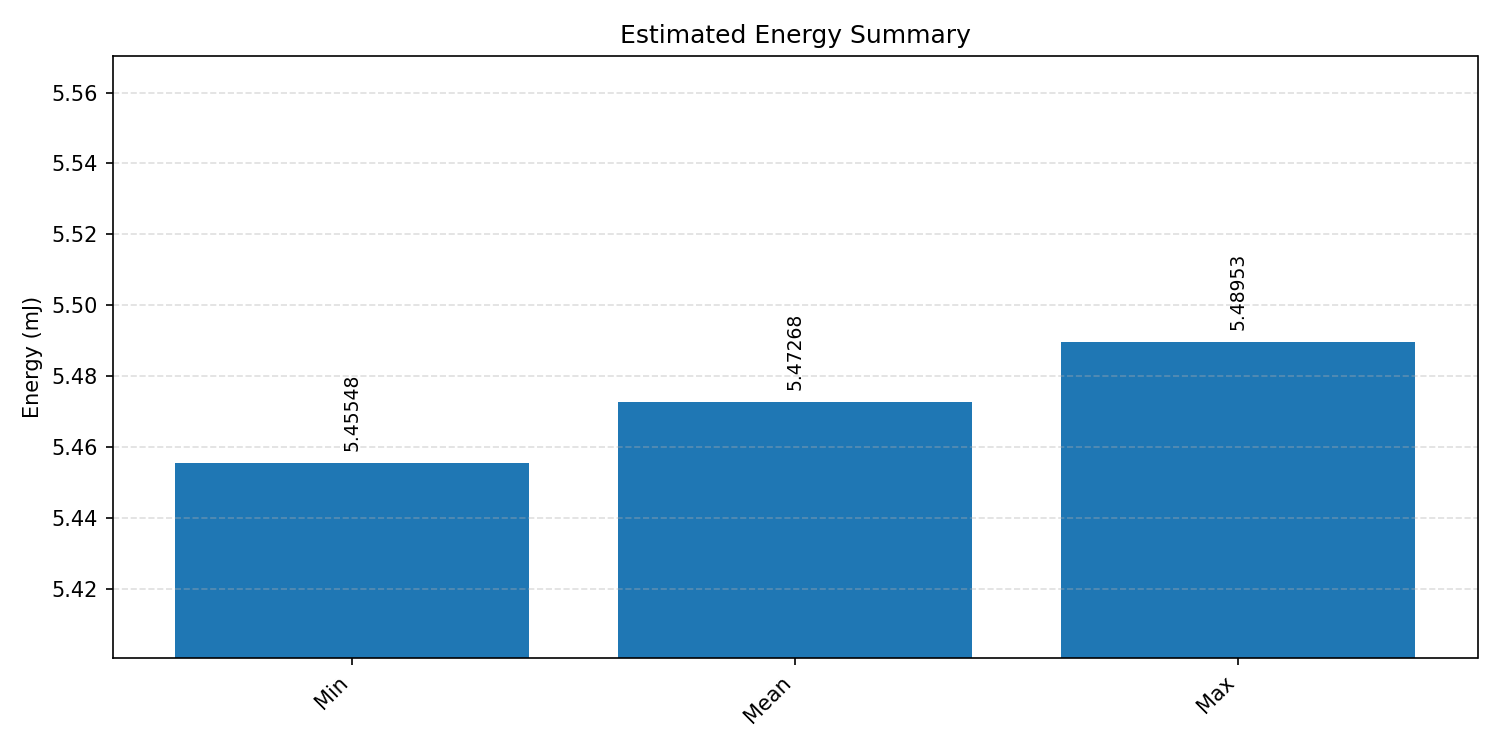
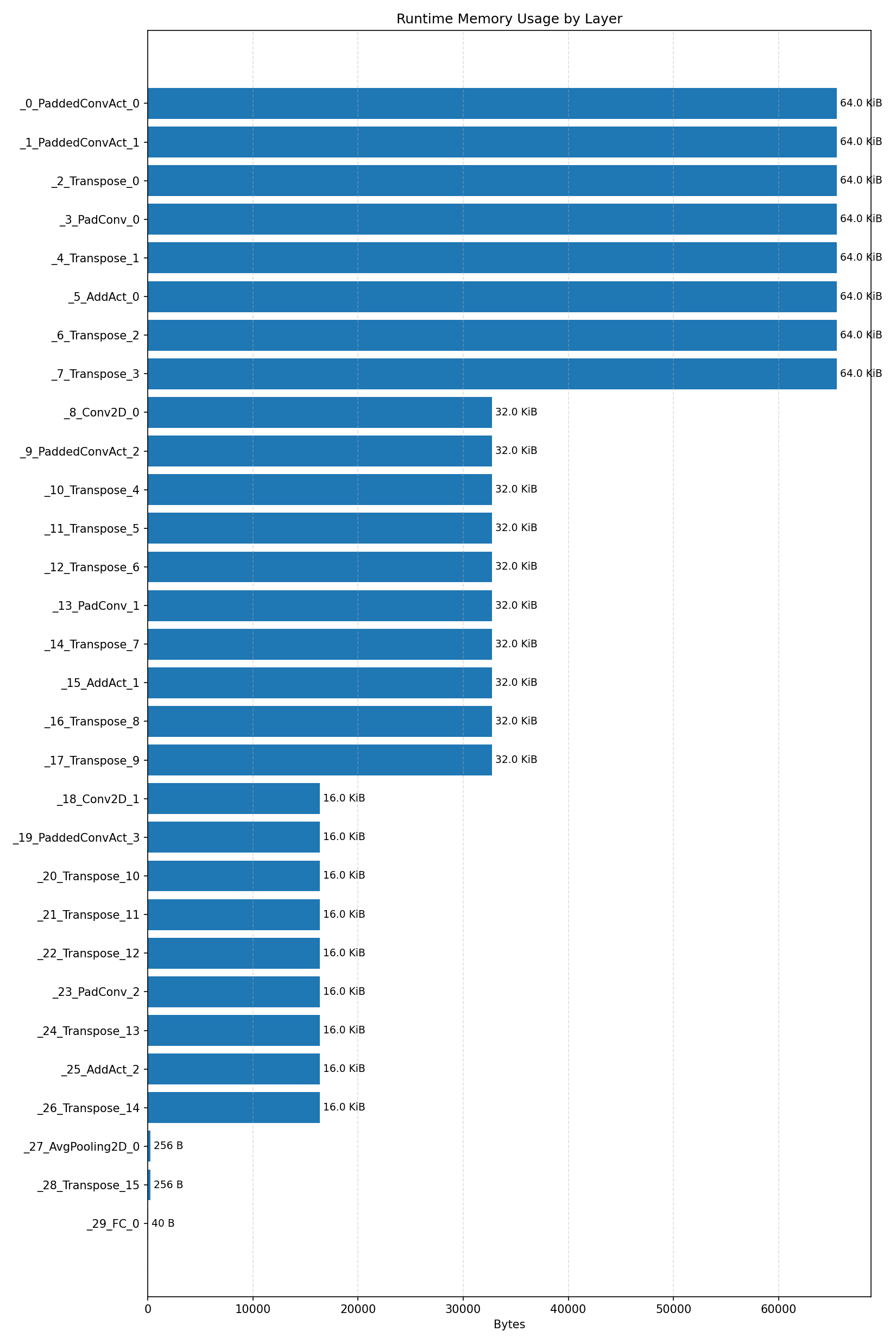
#2.3.3 (INT8) CPP#
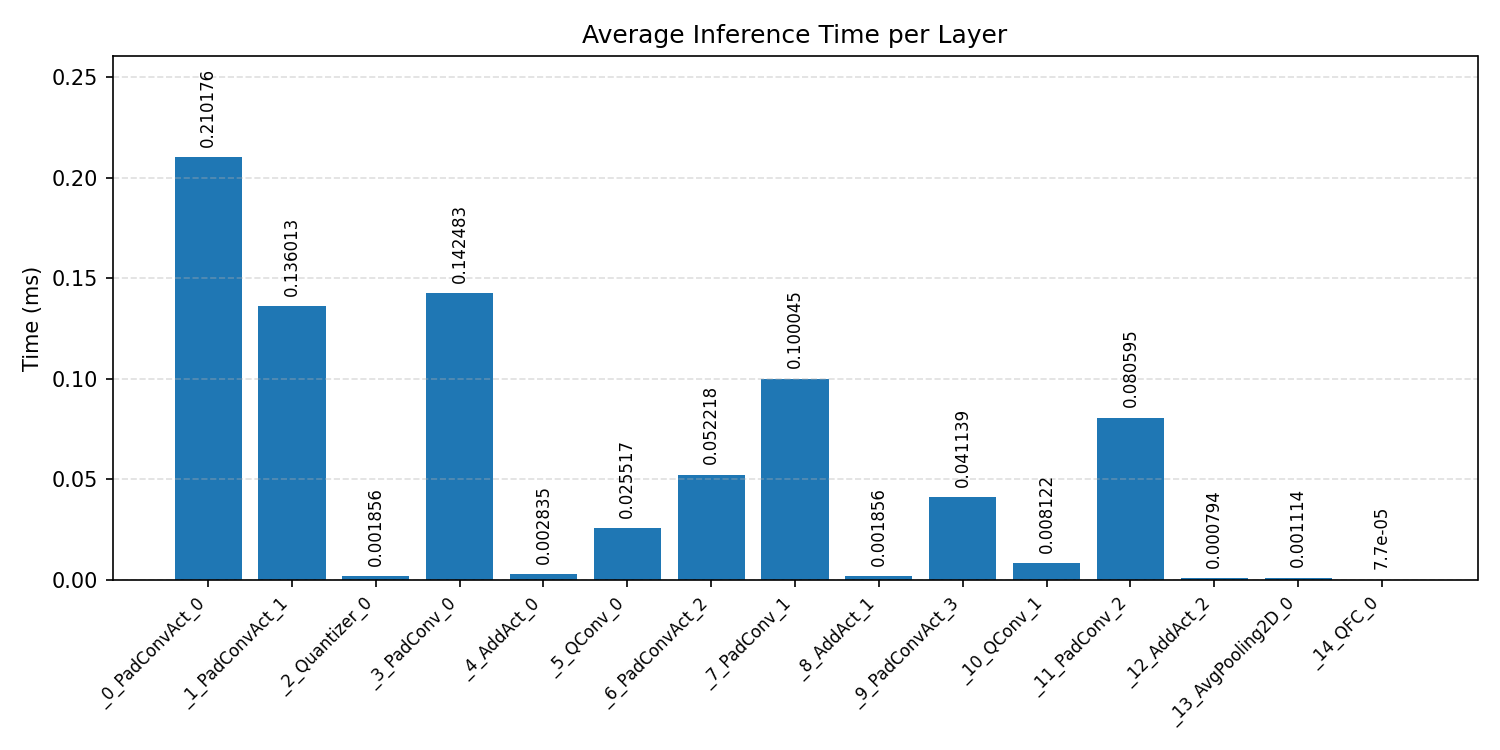
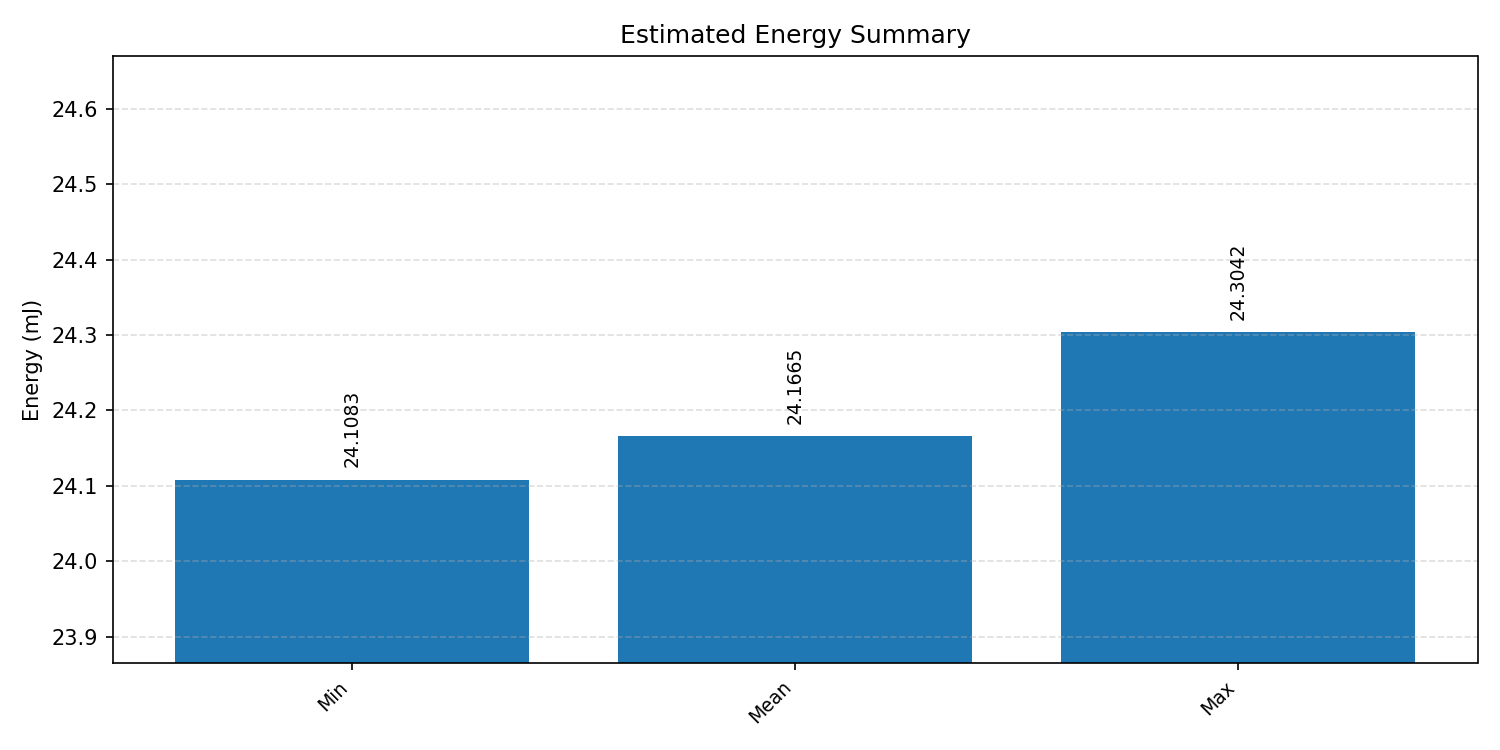
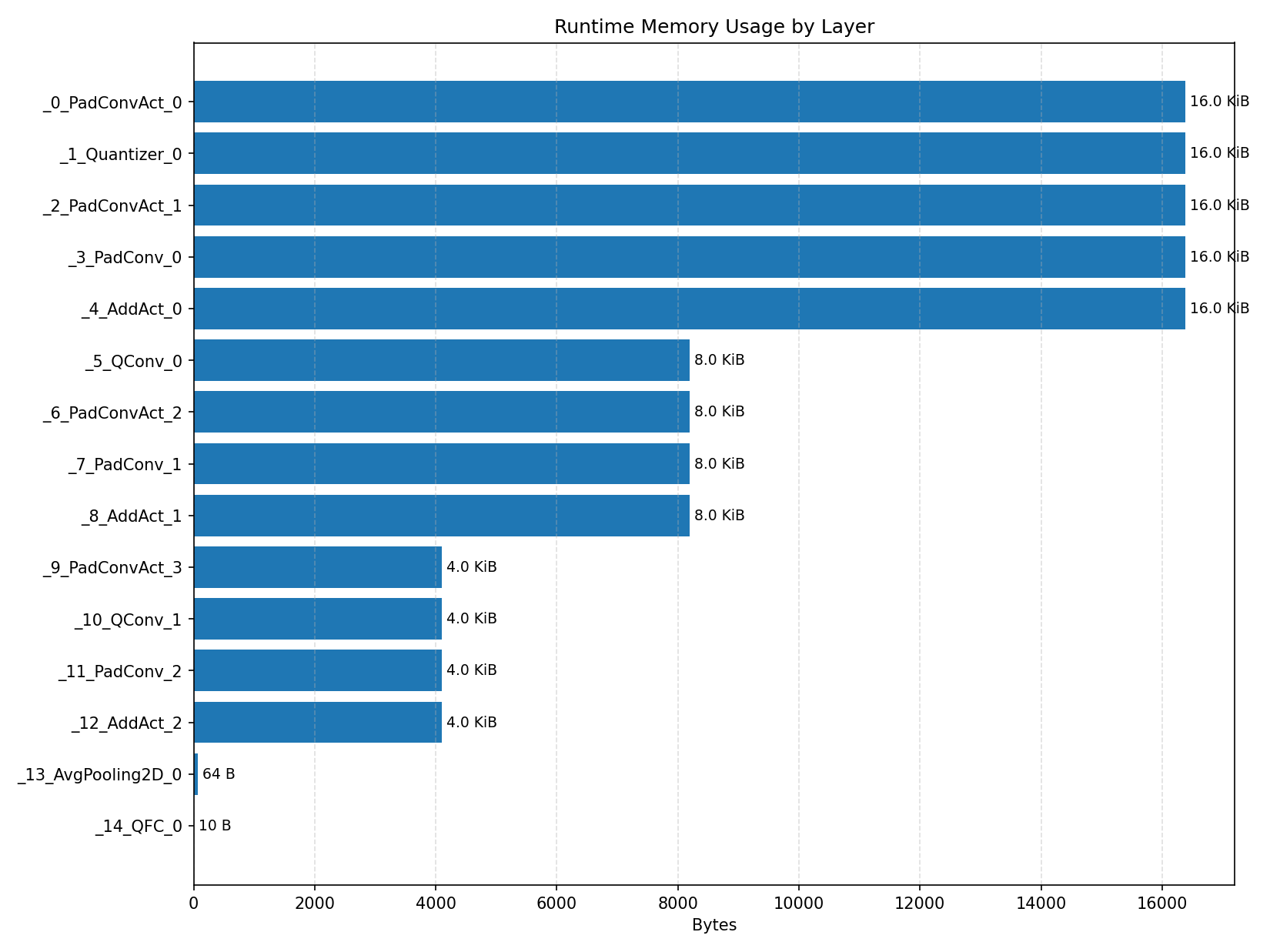
#2.4 DS-CNN#
Comparison Chart
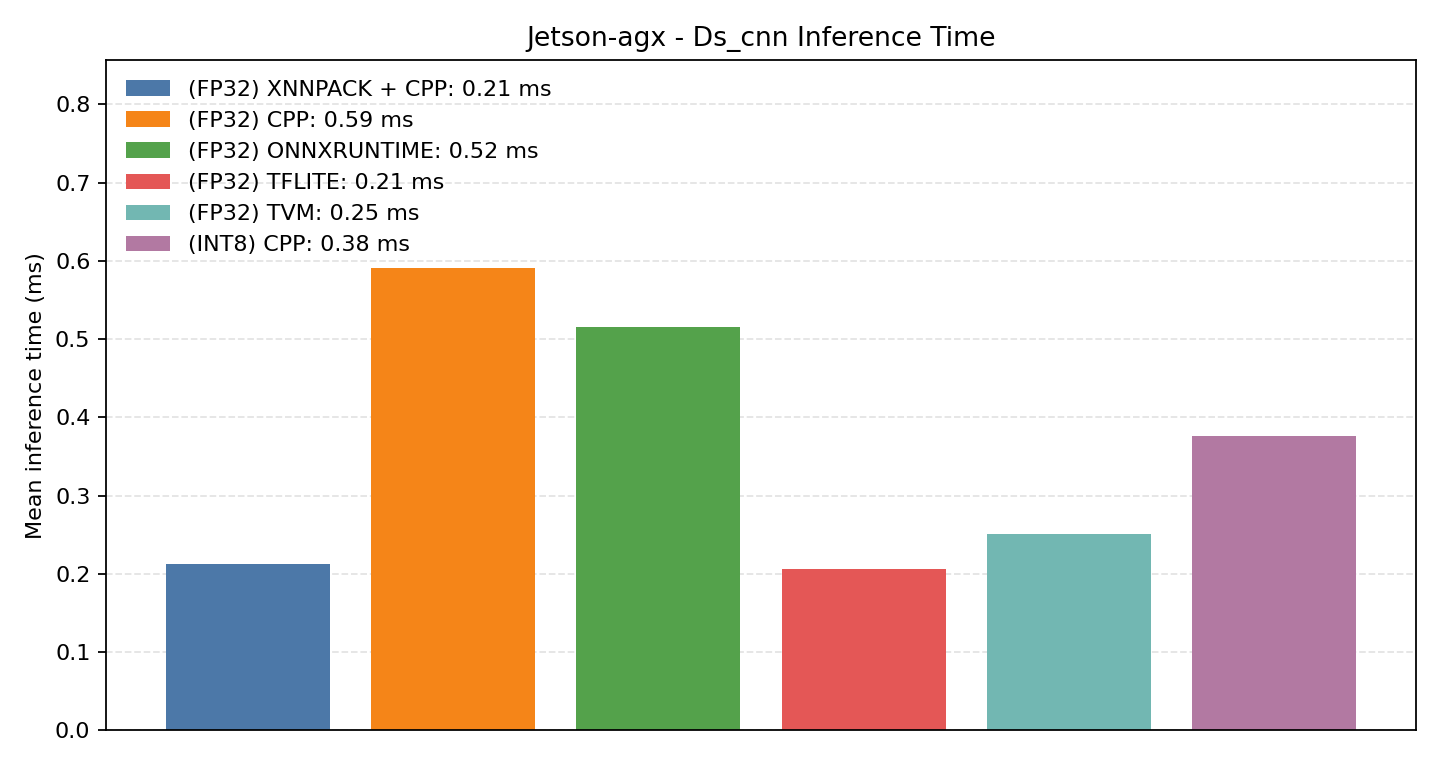
#2.4.1 (FP32) CPP#
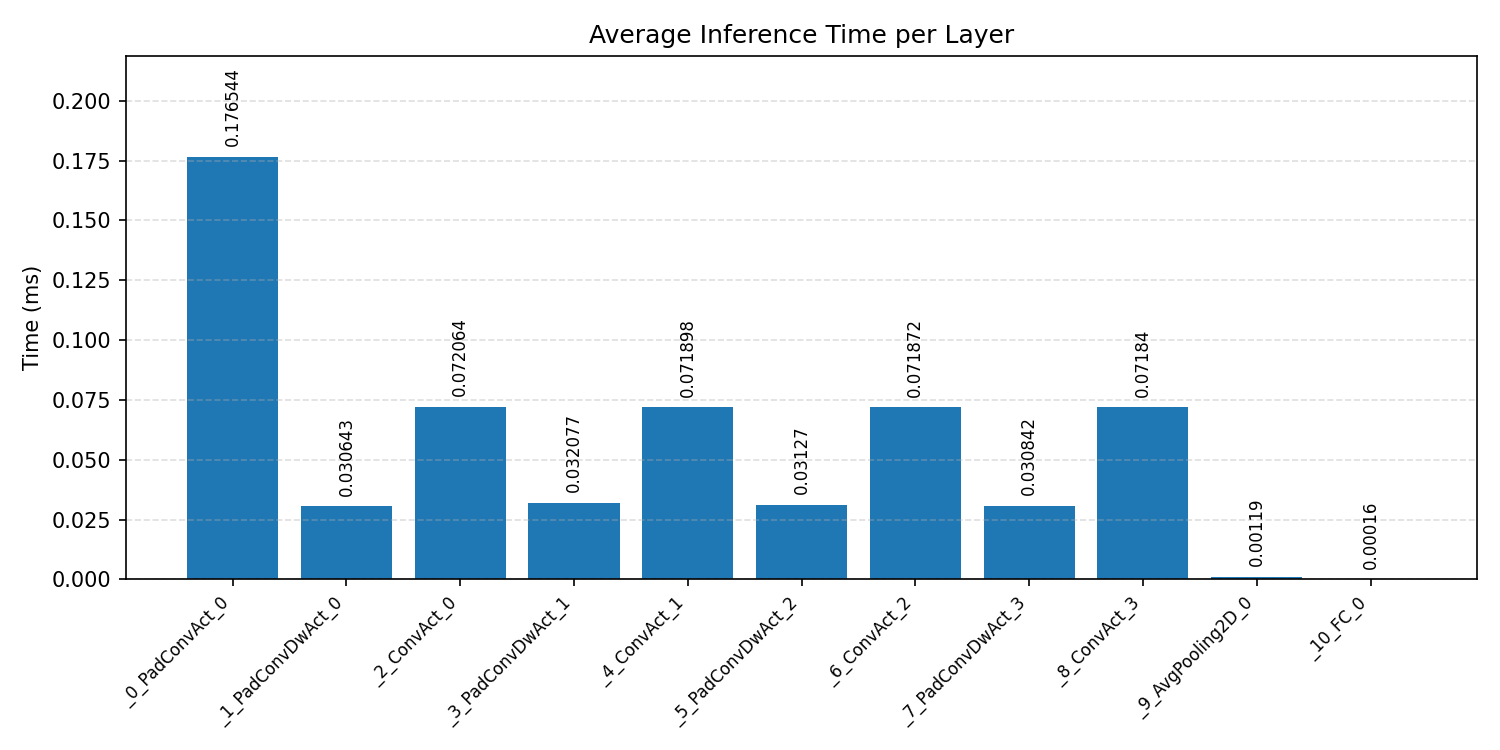
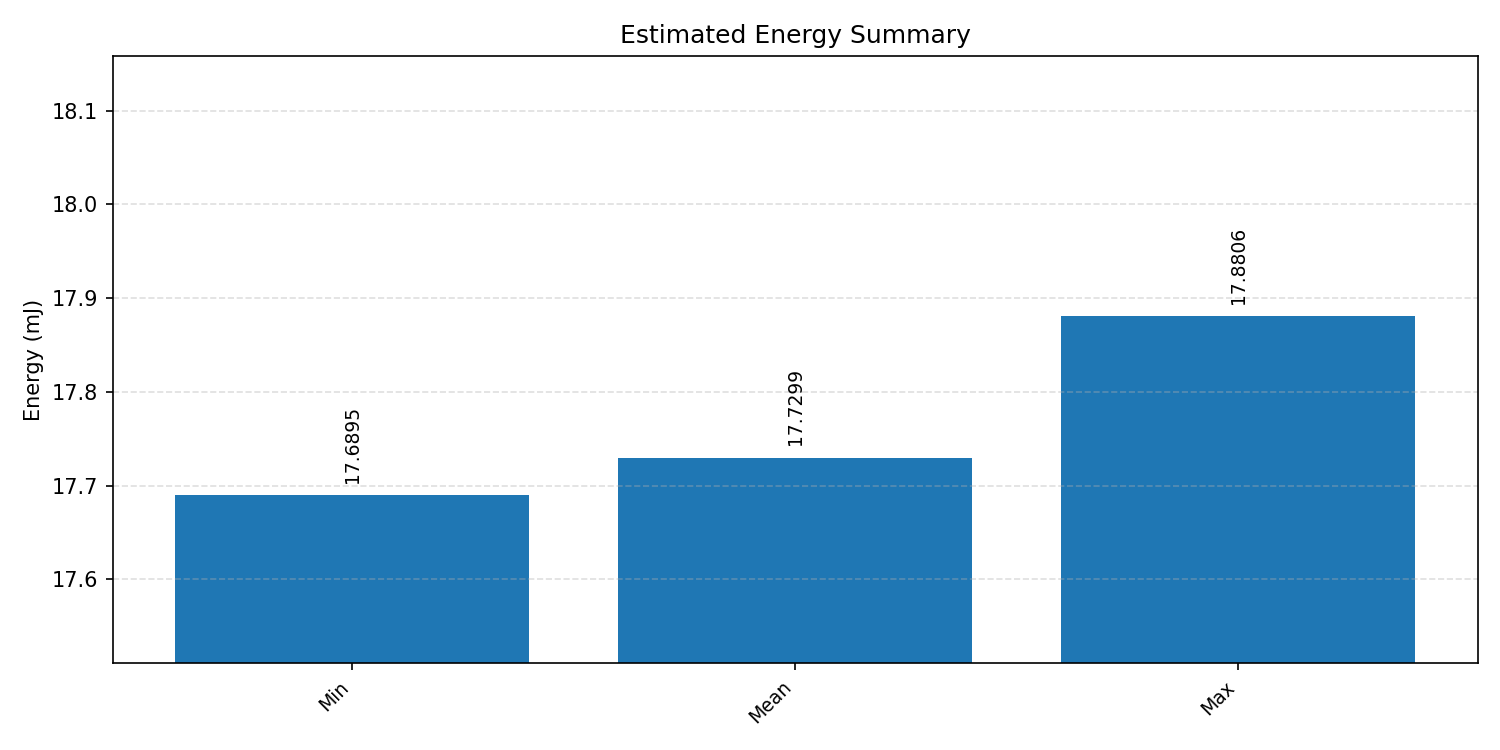
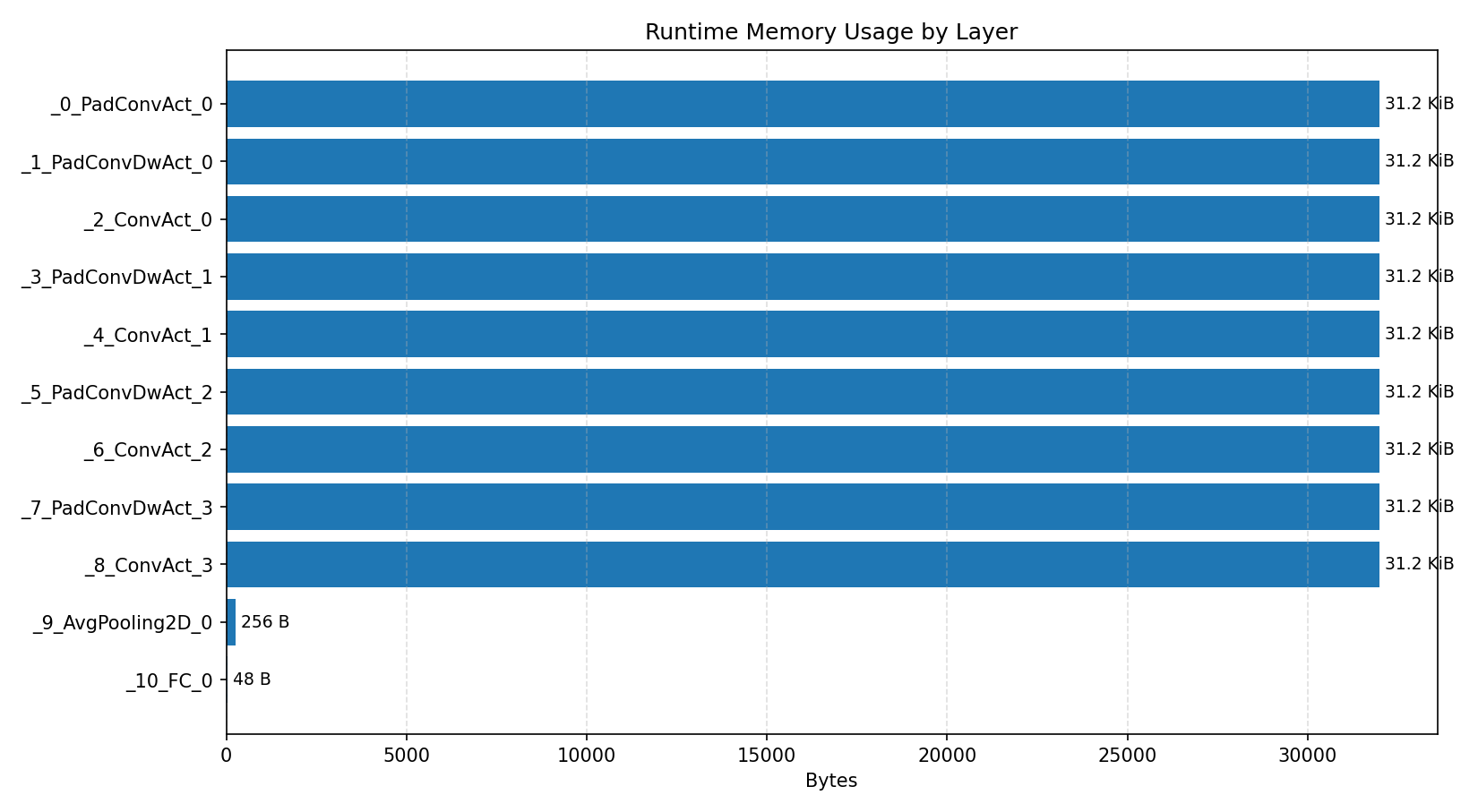
#2.4.2 (FP32) XNNPACK + CPP#
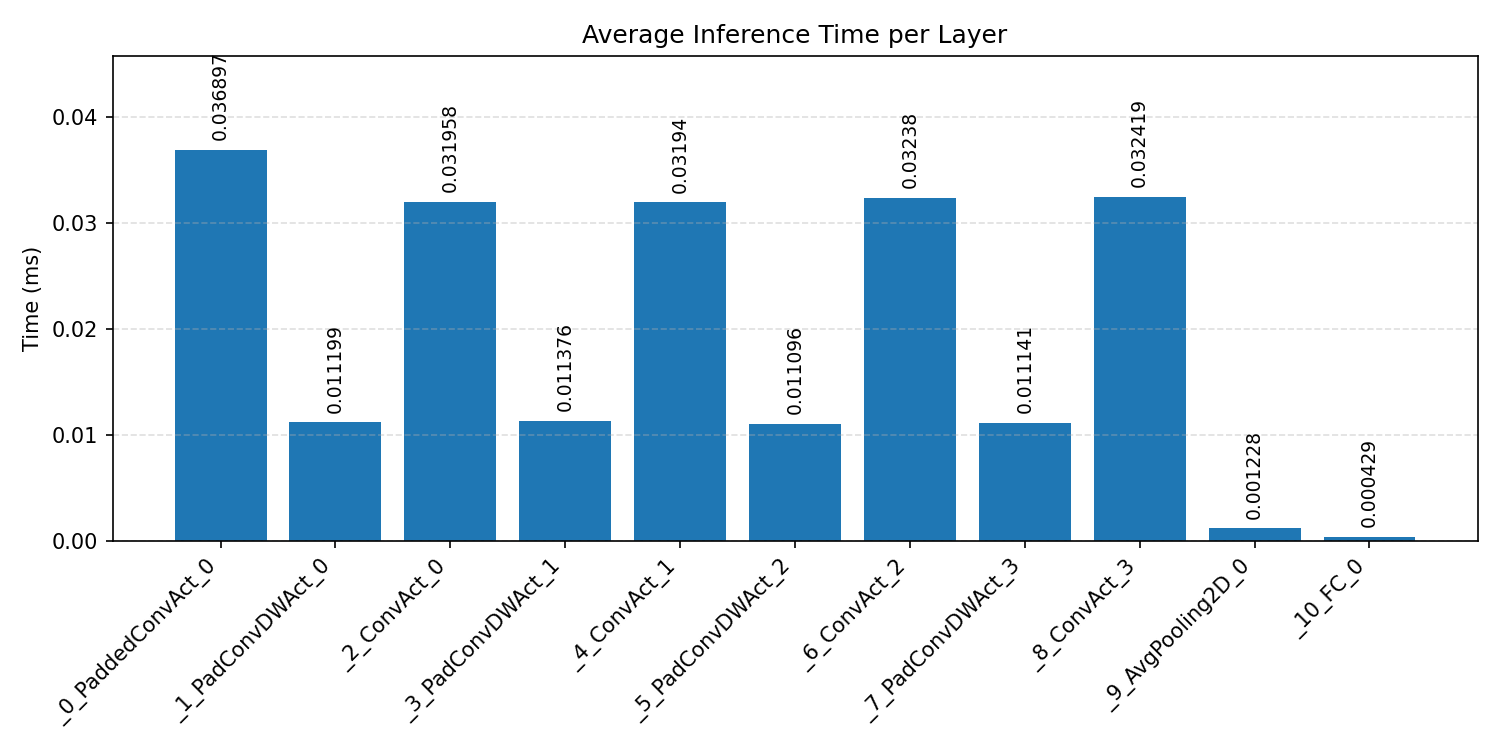
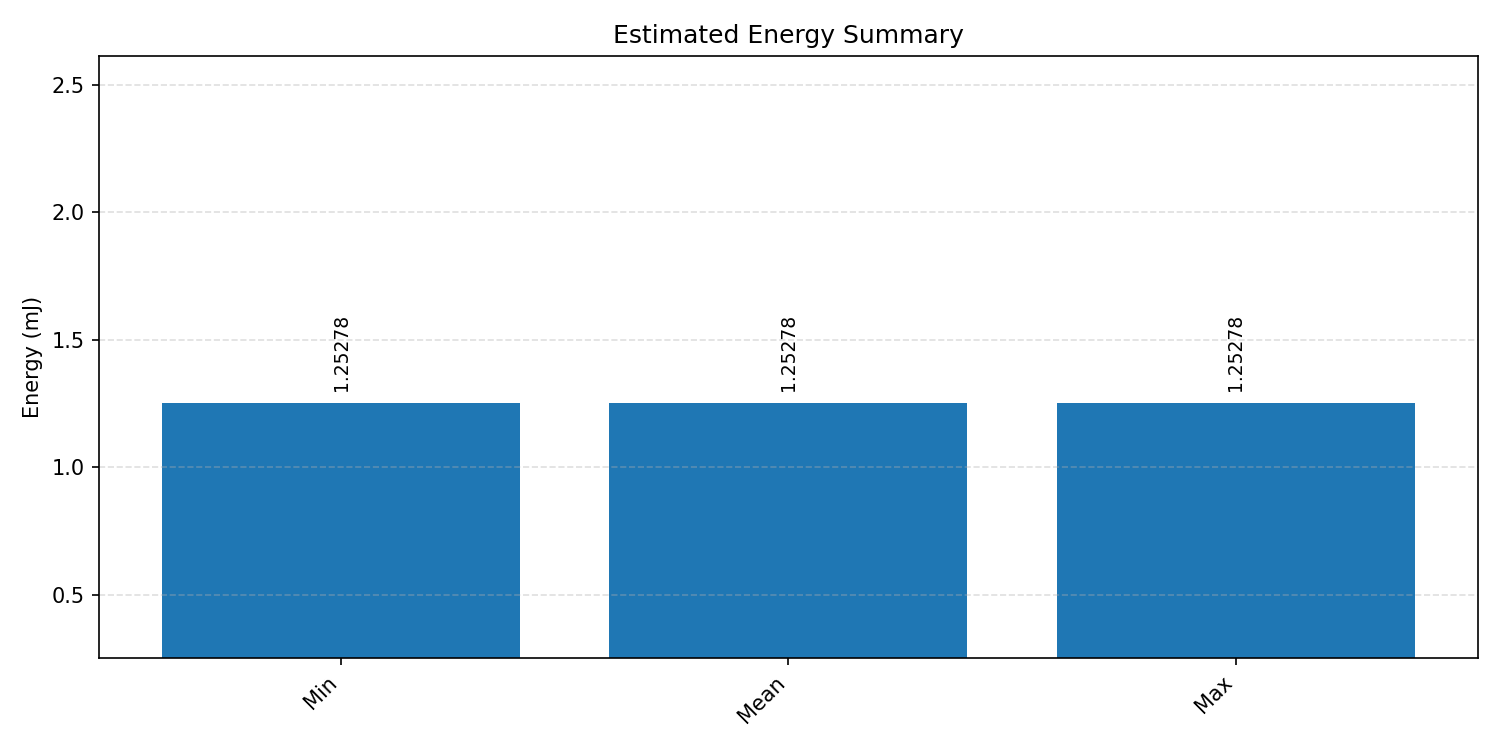
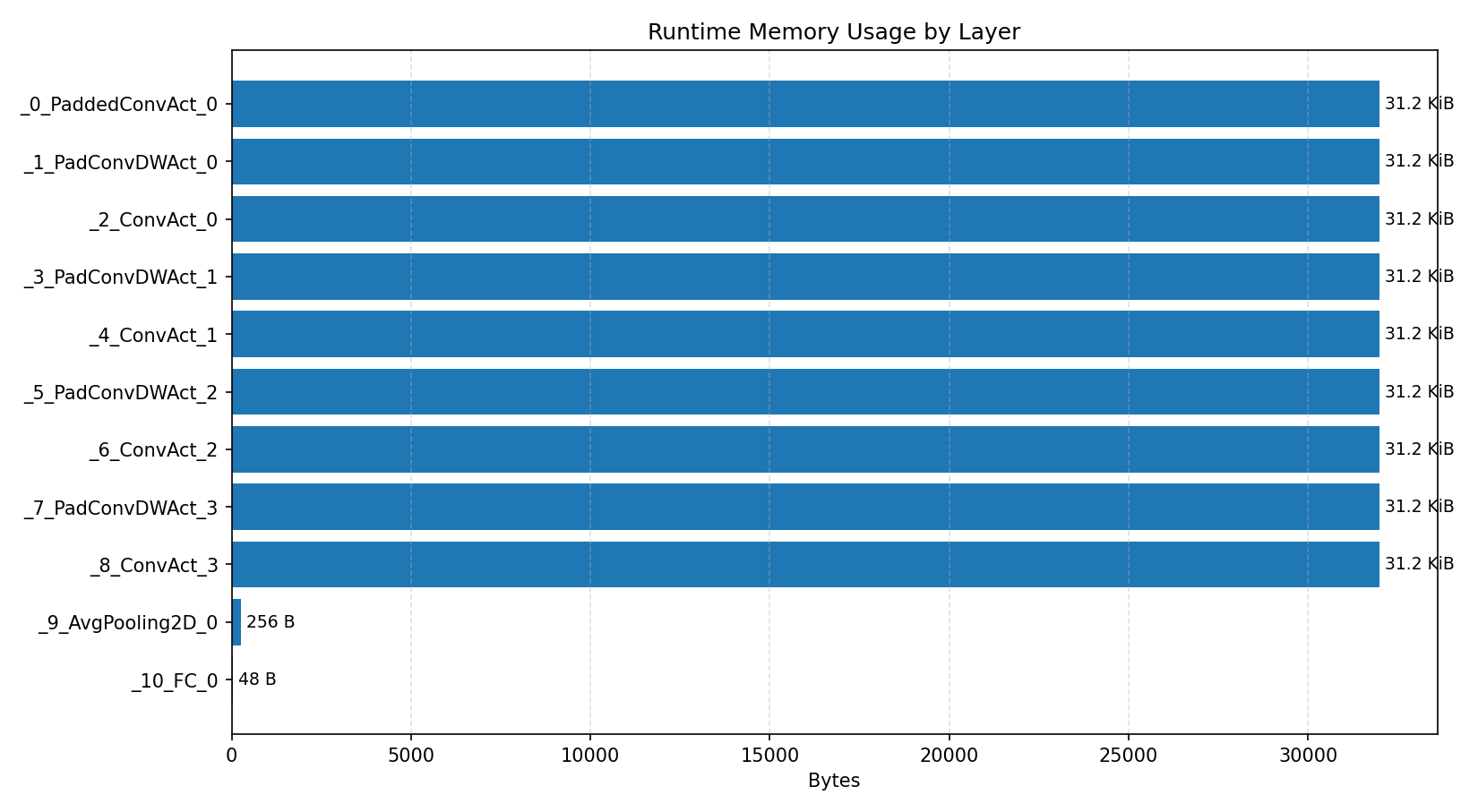
#2.4.3 (INT8) CPP#
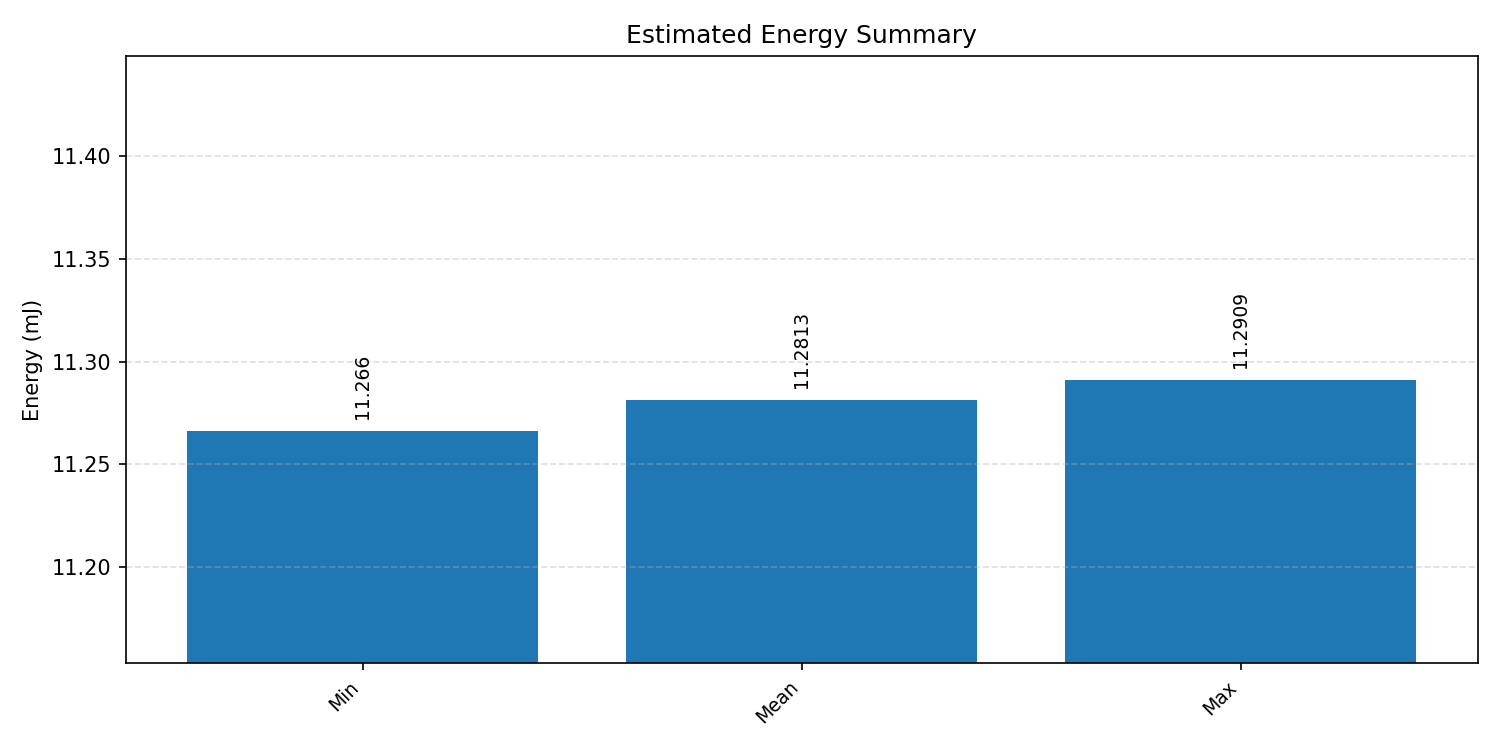
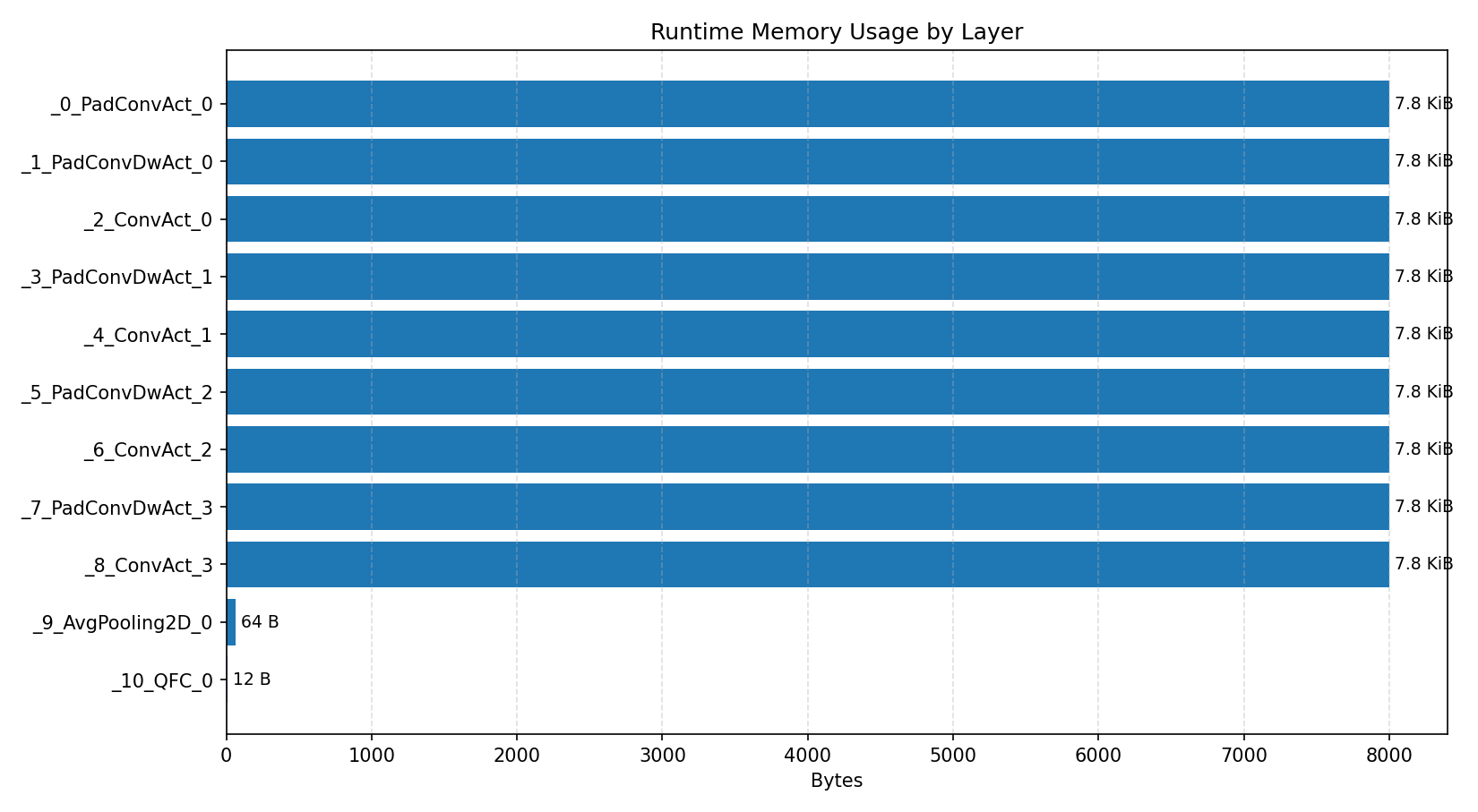
#2.5 Deep autoencoder#
Comparison Chart
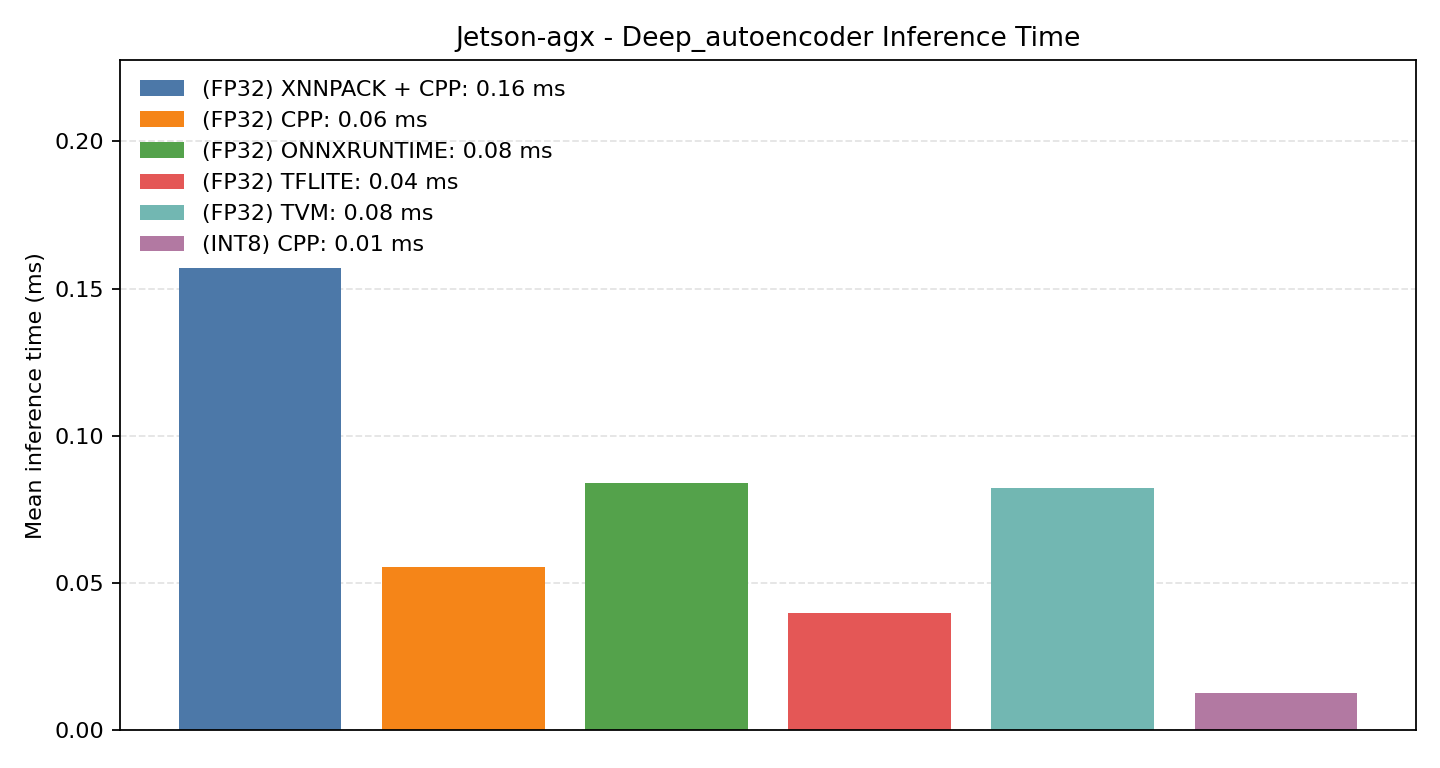
#2.5.1 (FP32) CPP#
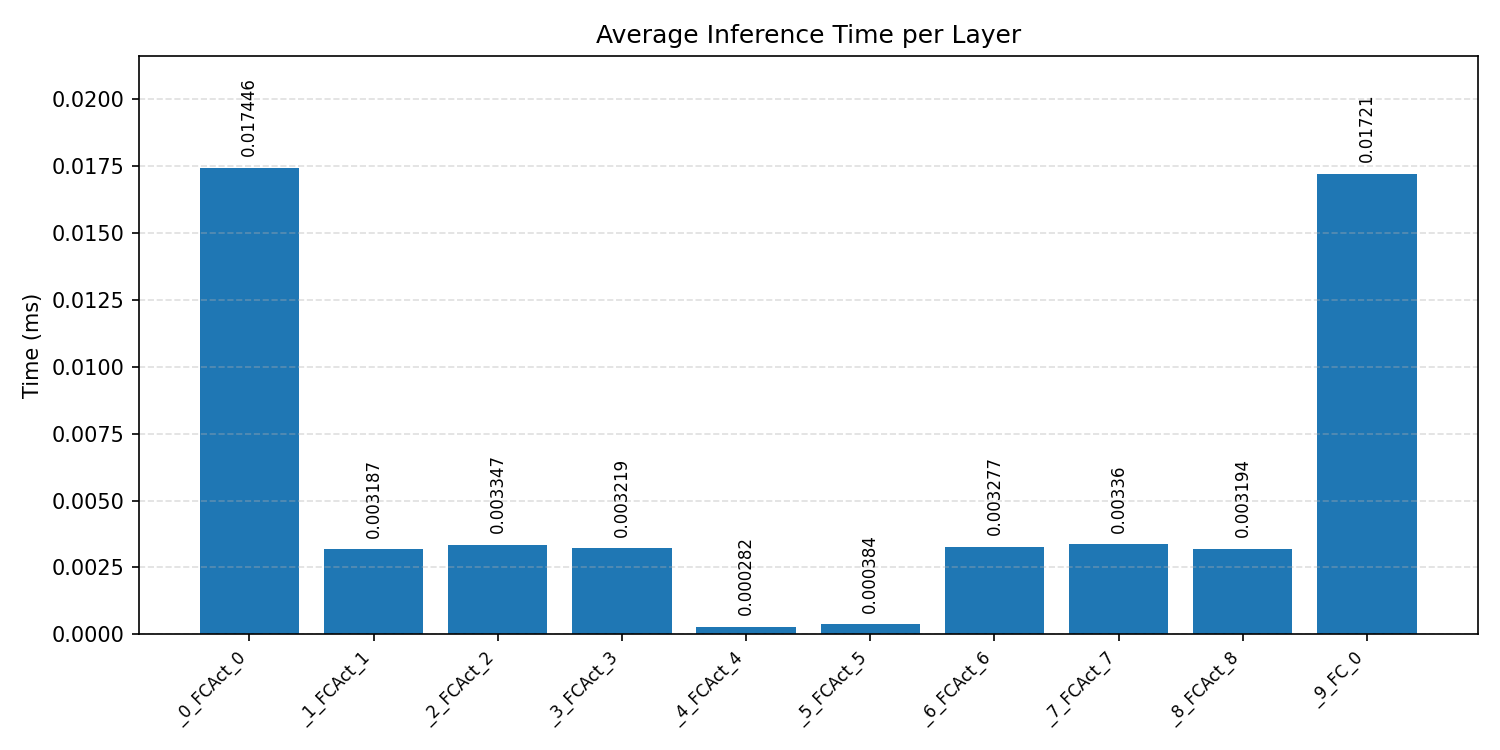
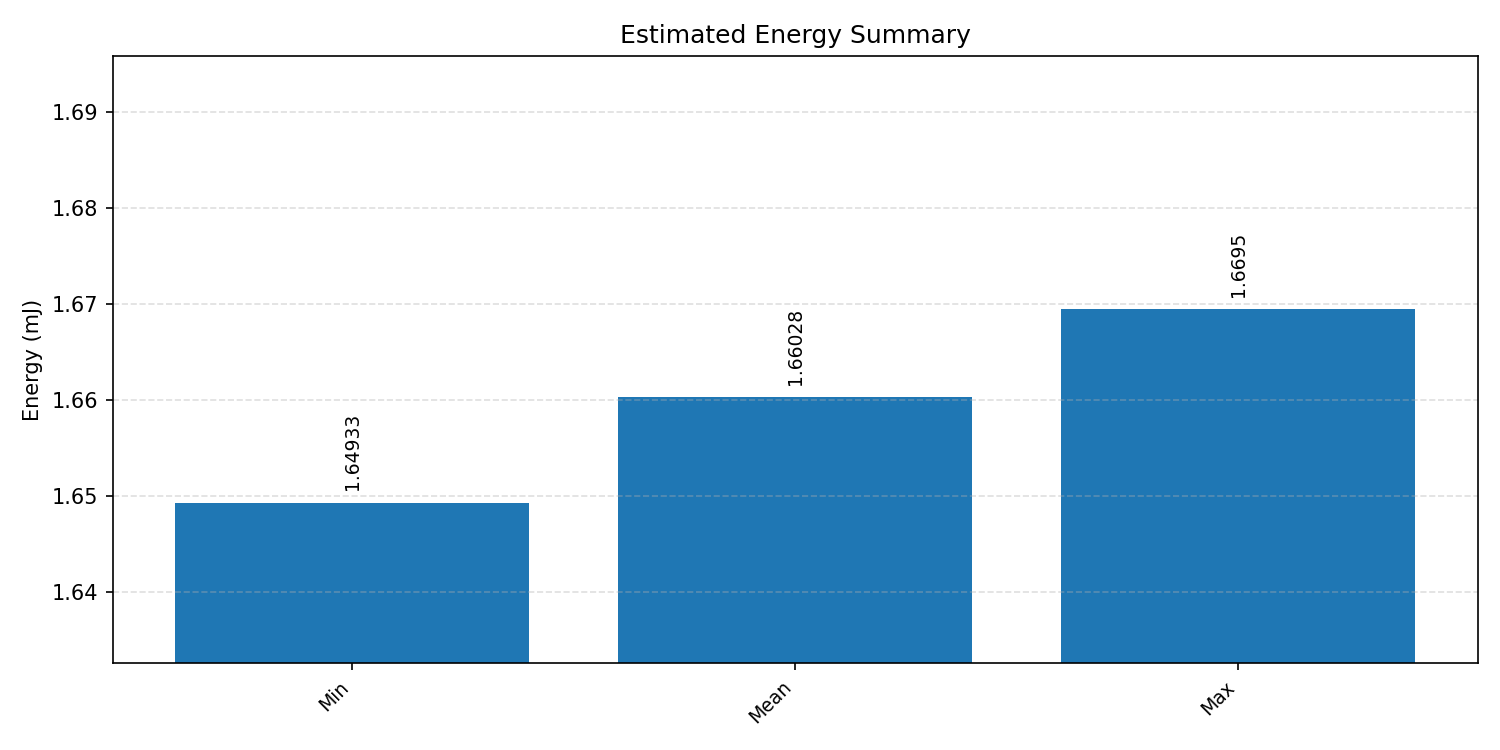
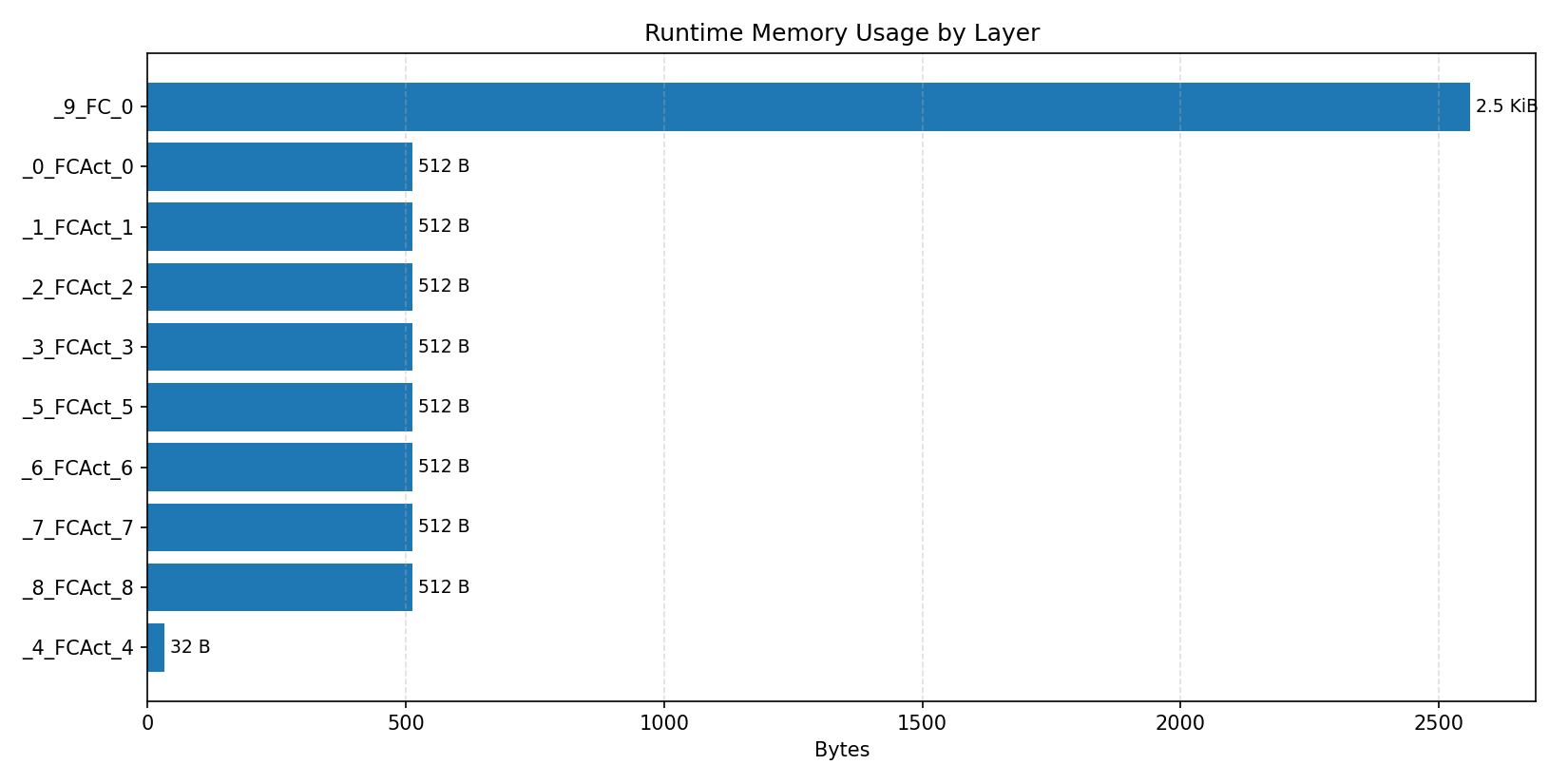
#2.5.2 (FP32) XNNPACK + CPP#
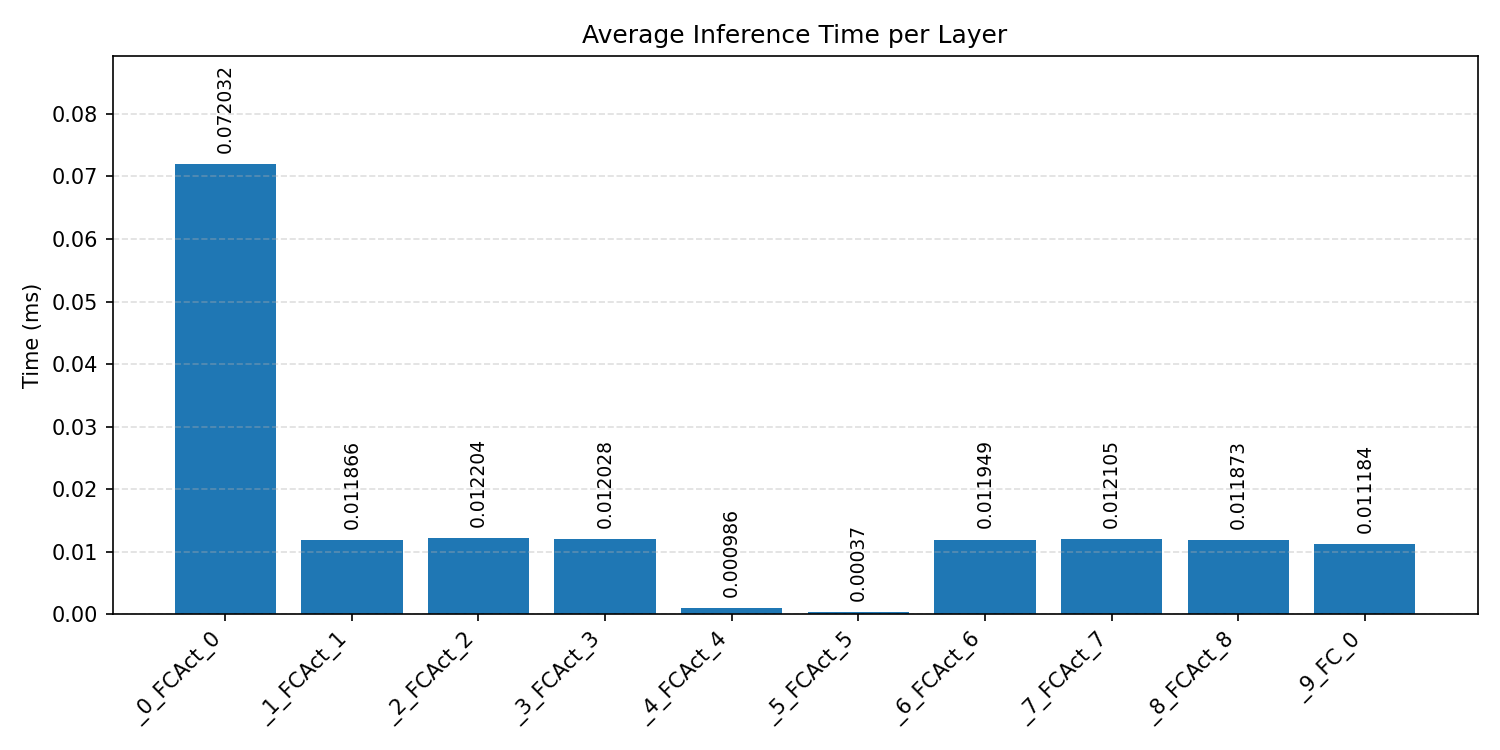
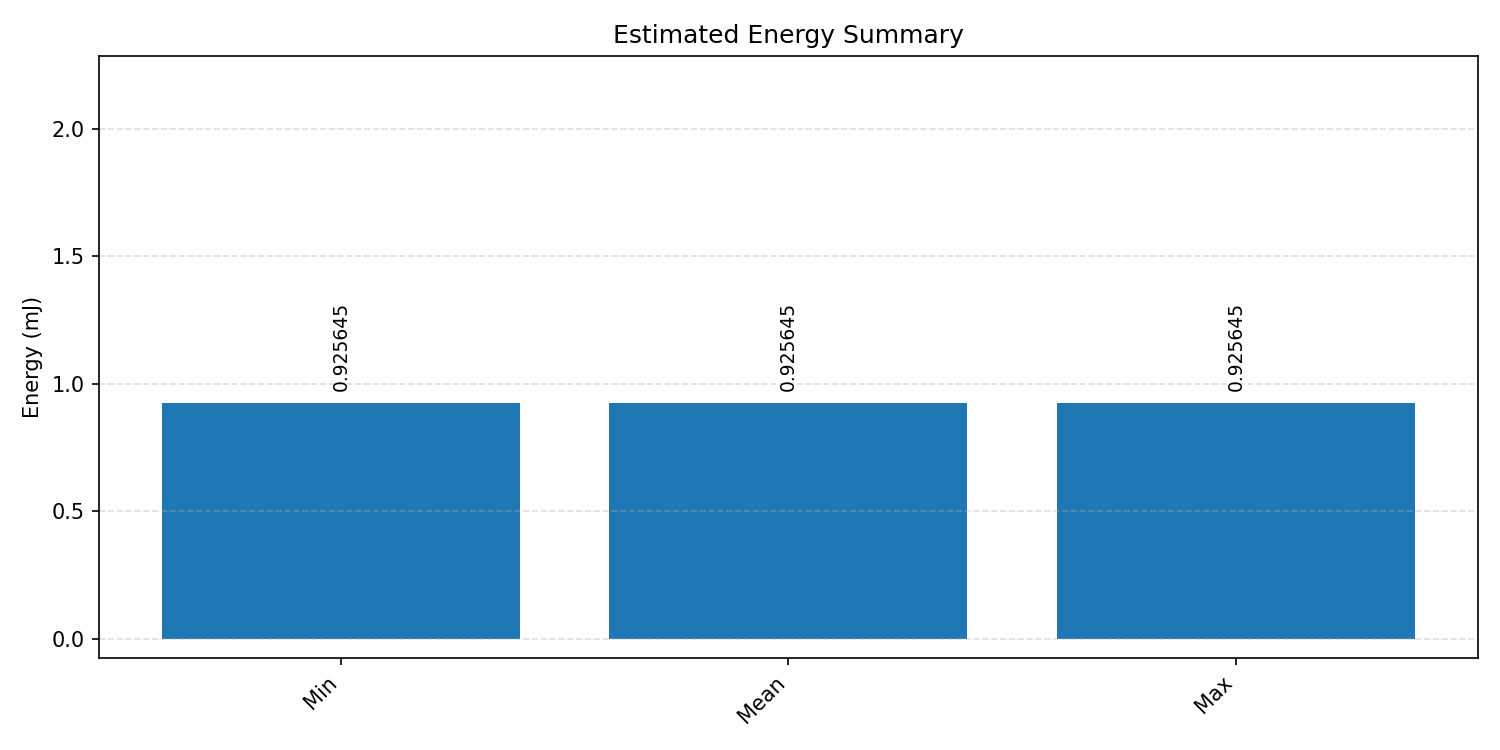
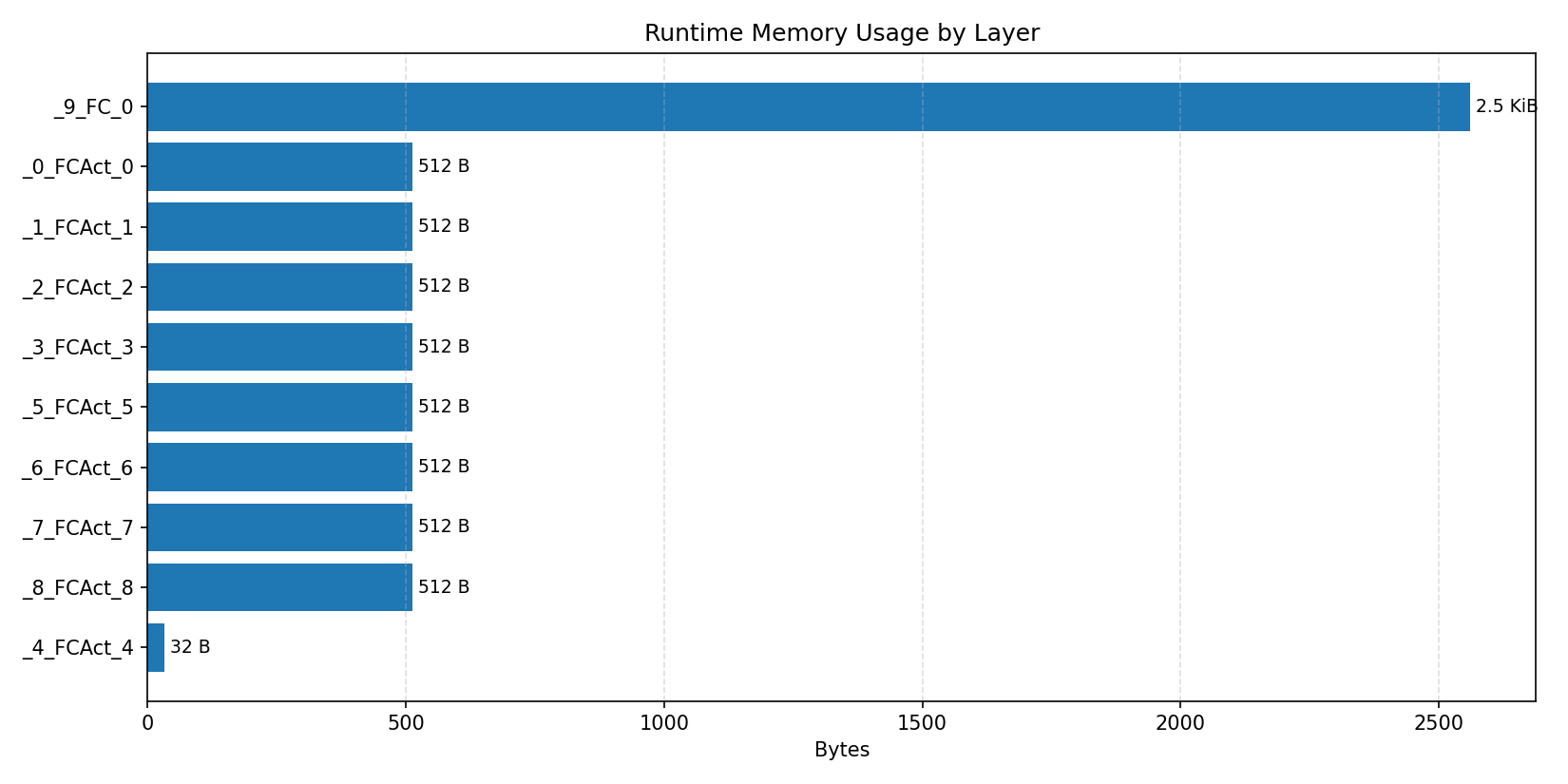
#2.5.3 (INT8) CPP#
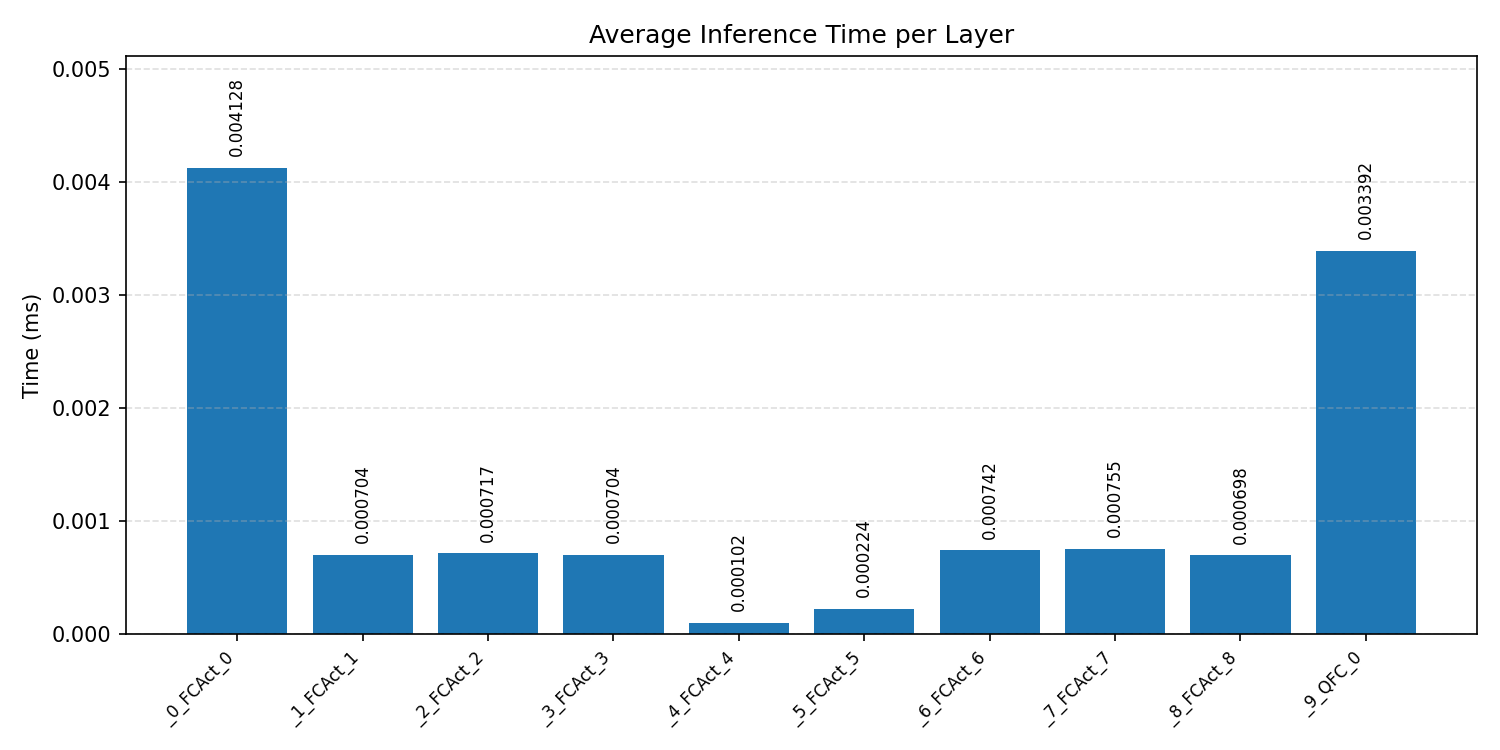
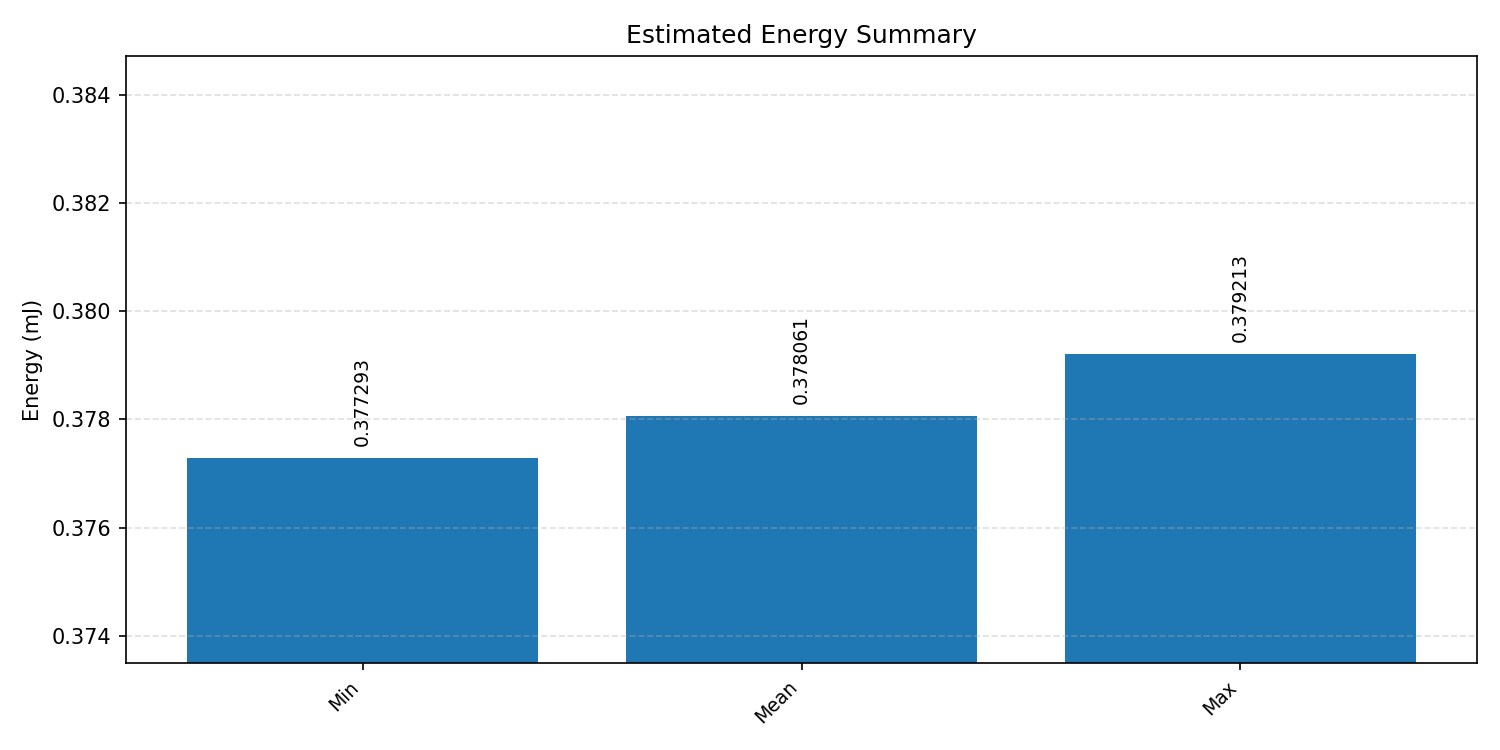
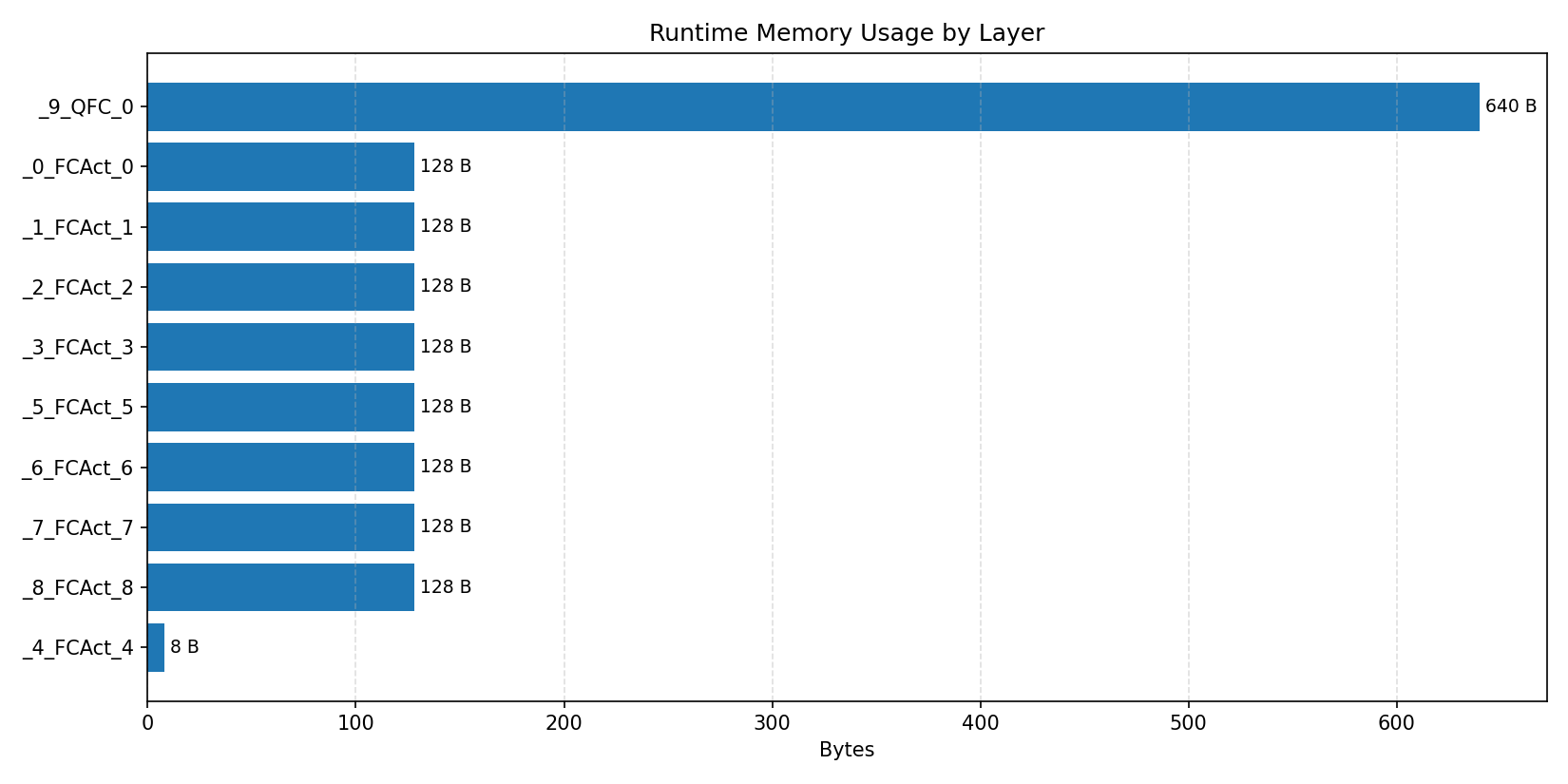
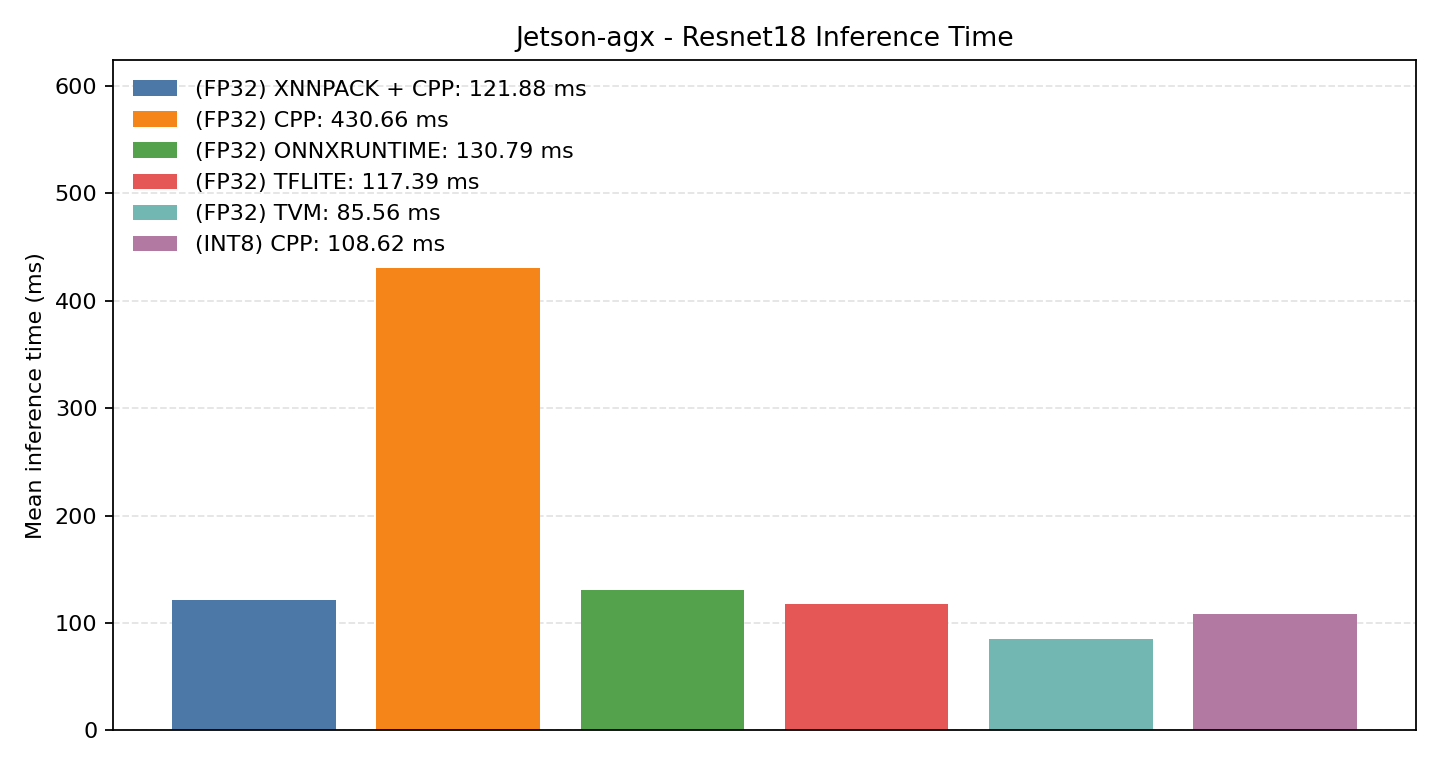
#2.6 ResNet18#
ResNet18 is a larger residual network used here to compare runtime strategies on edge-Linux targets.
Comparison Chart
#2.6.1 (FP32) CPP#
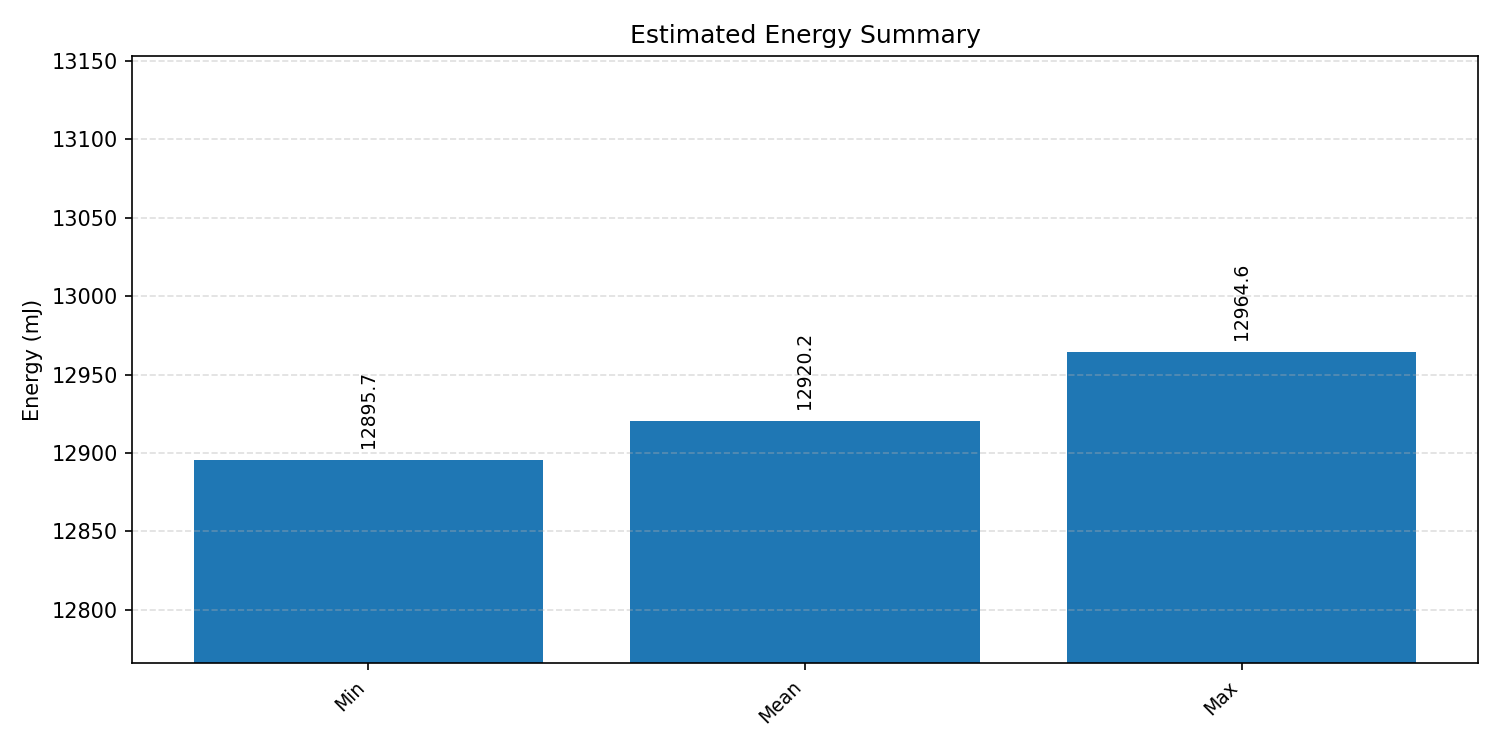
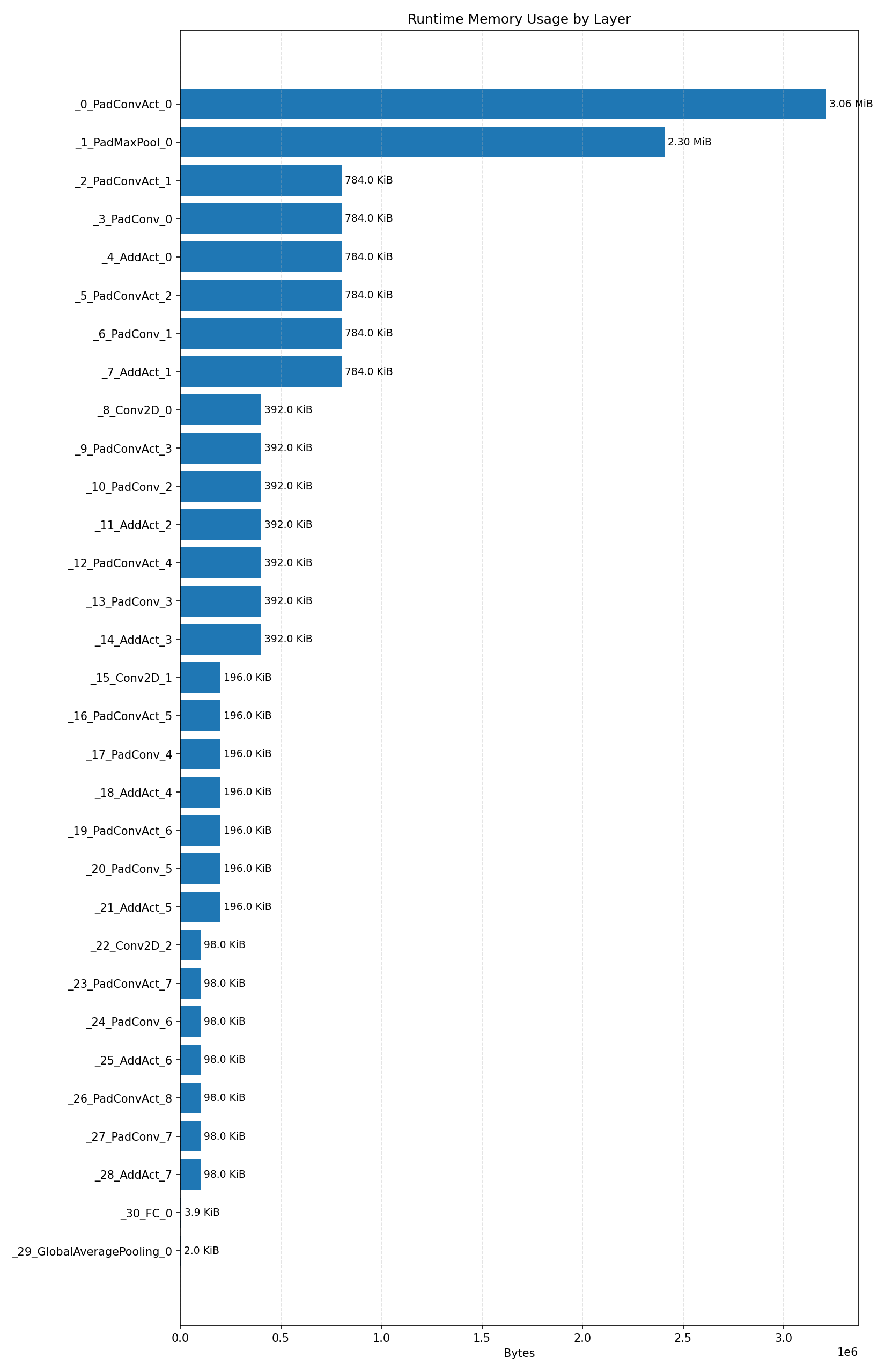
#2.6.2 (FP32) XNNPACK + CPP#
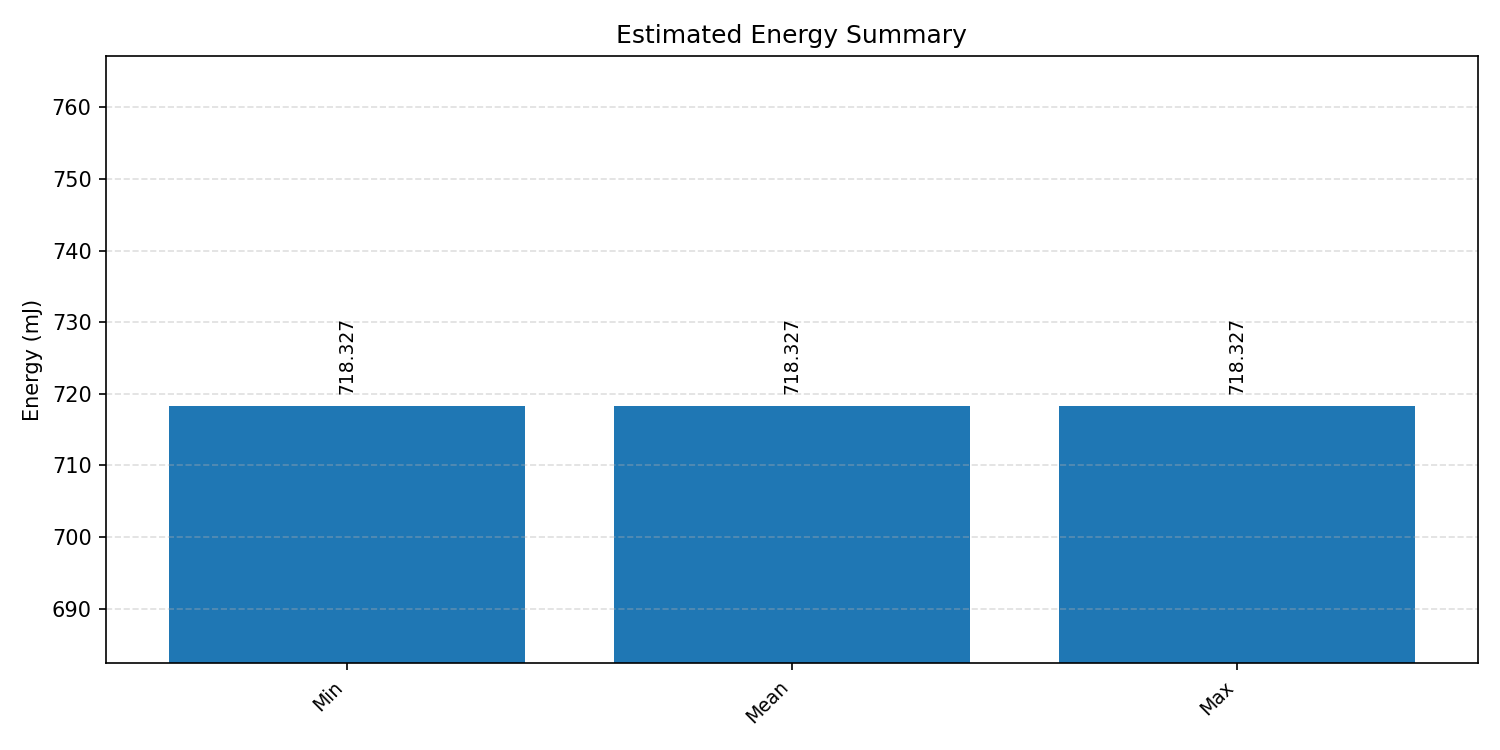
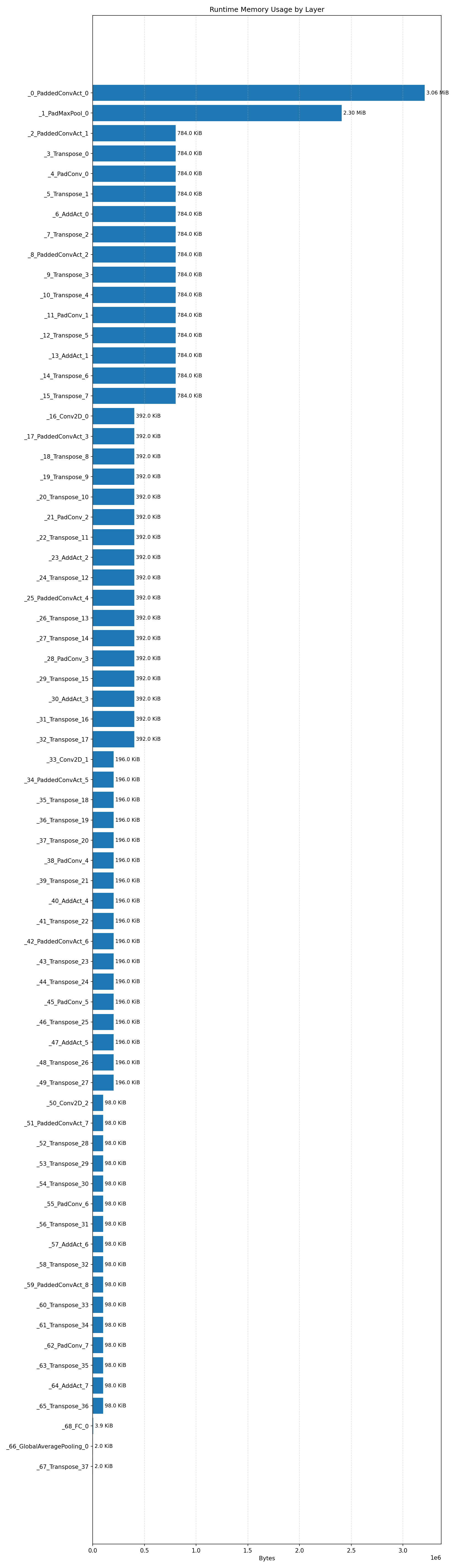
#2.6.3 (INT8) CPP#
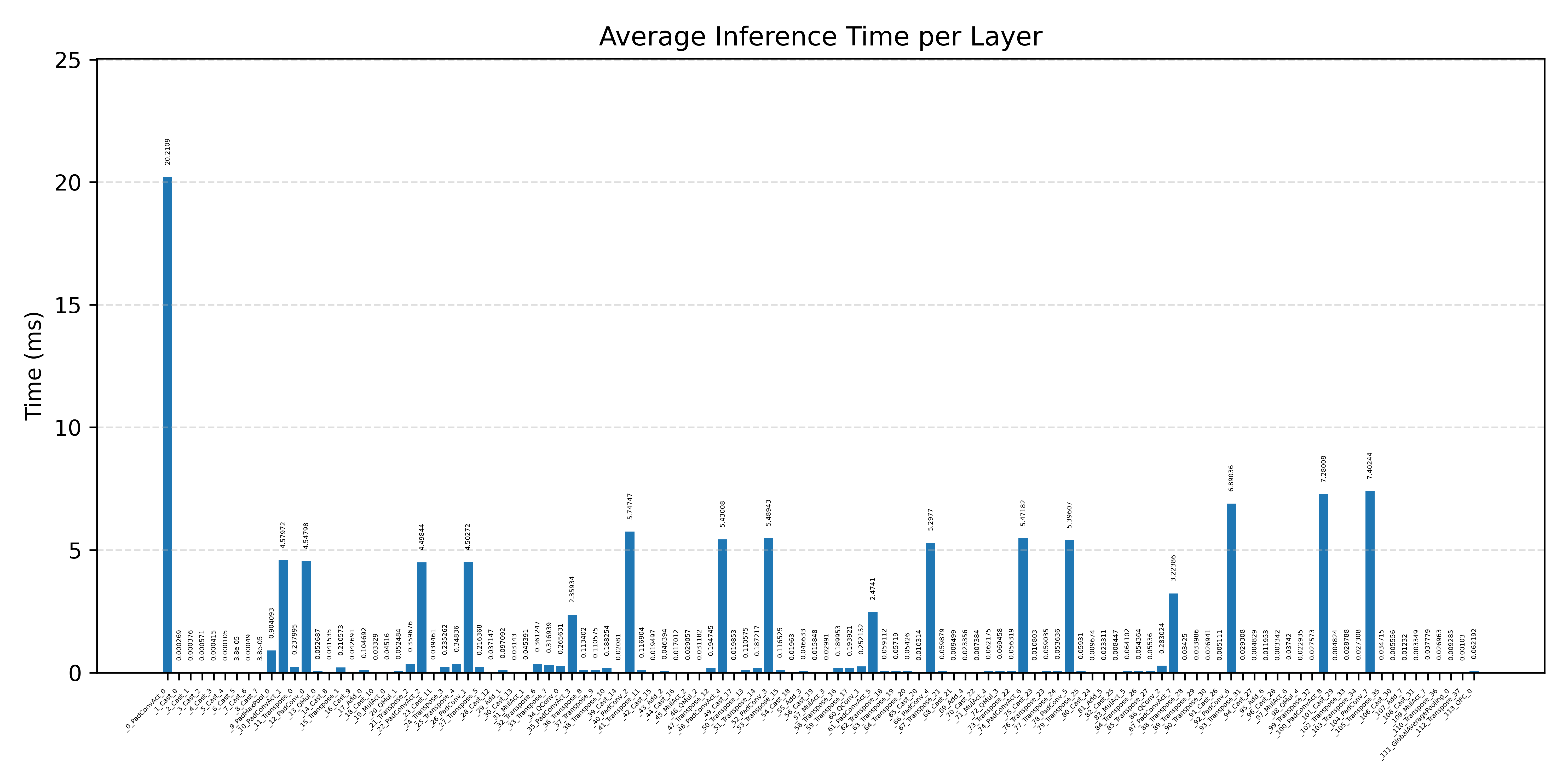
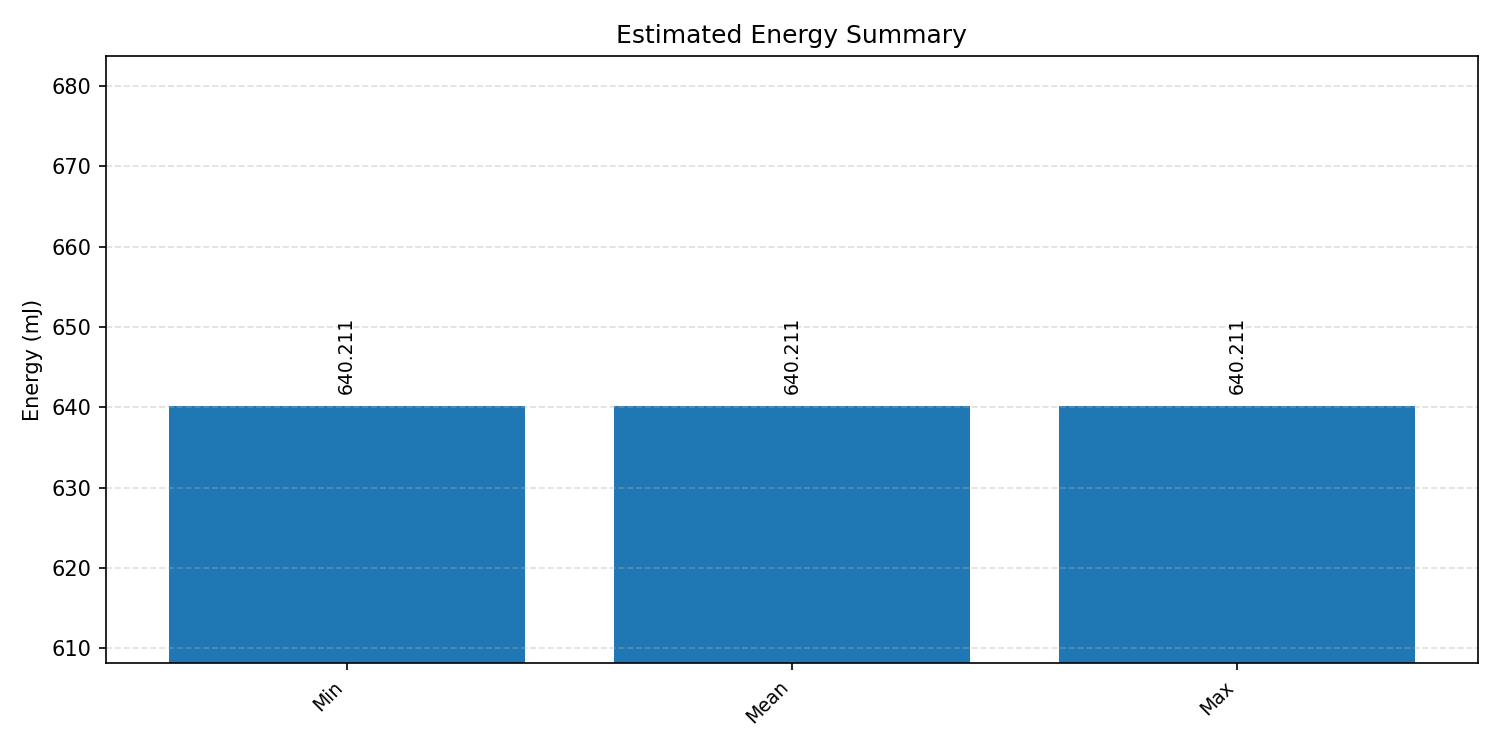

#2.7 ResNet50#
ResNet50 increases model depth and compute load, making backend selection effects easier to inspect.
Comparison Chart
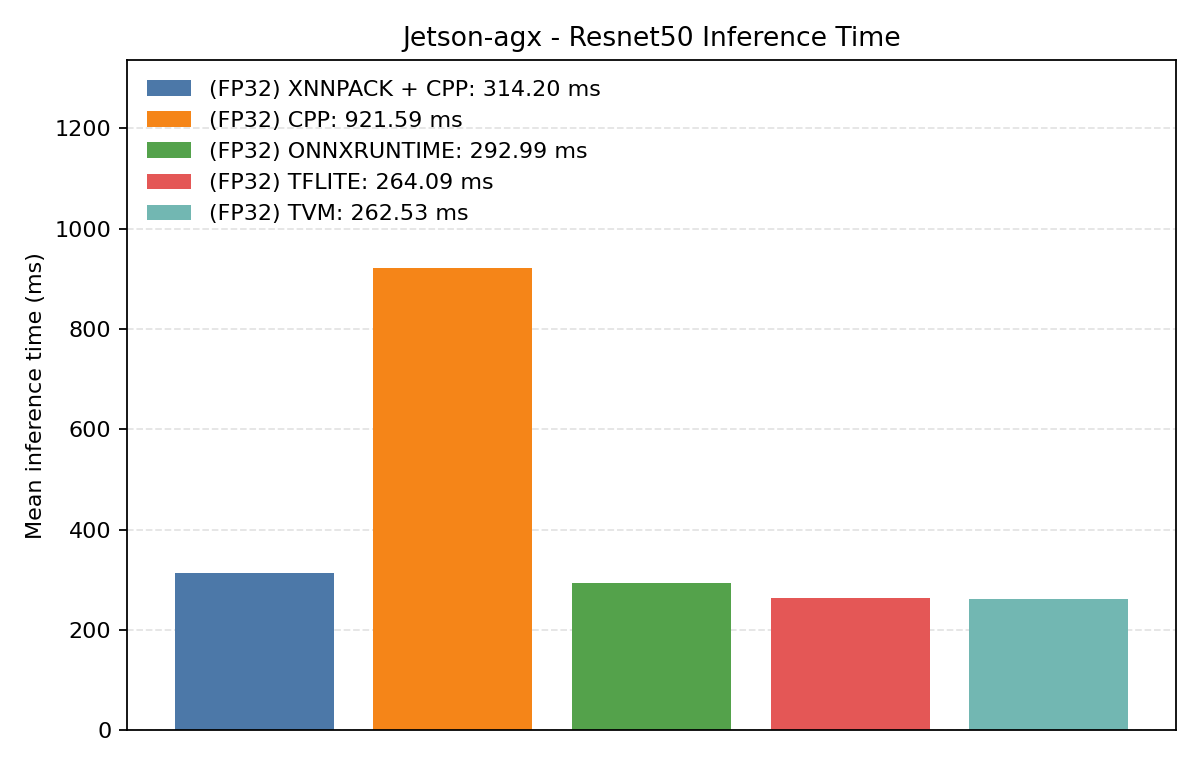
#2.7.1 (FP32) CPP#
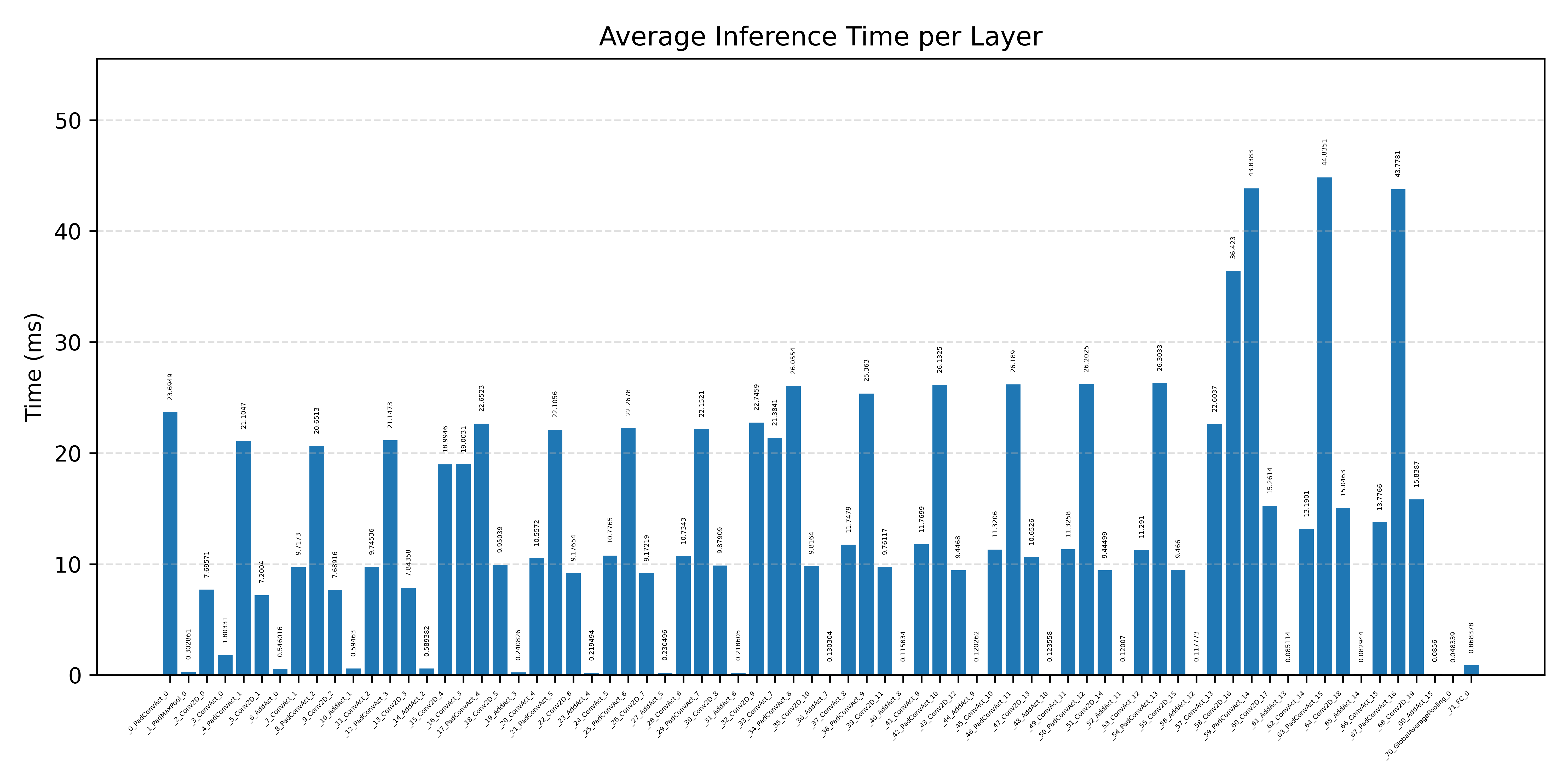
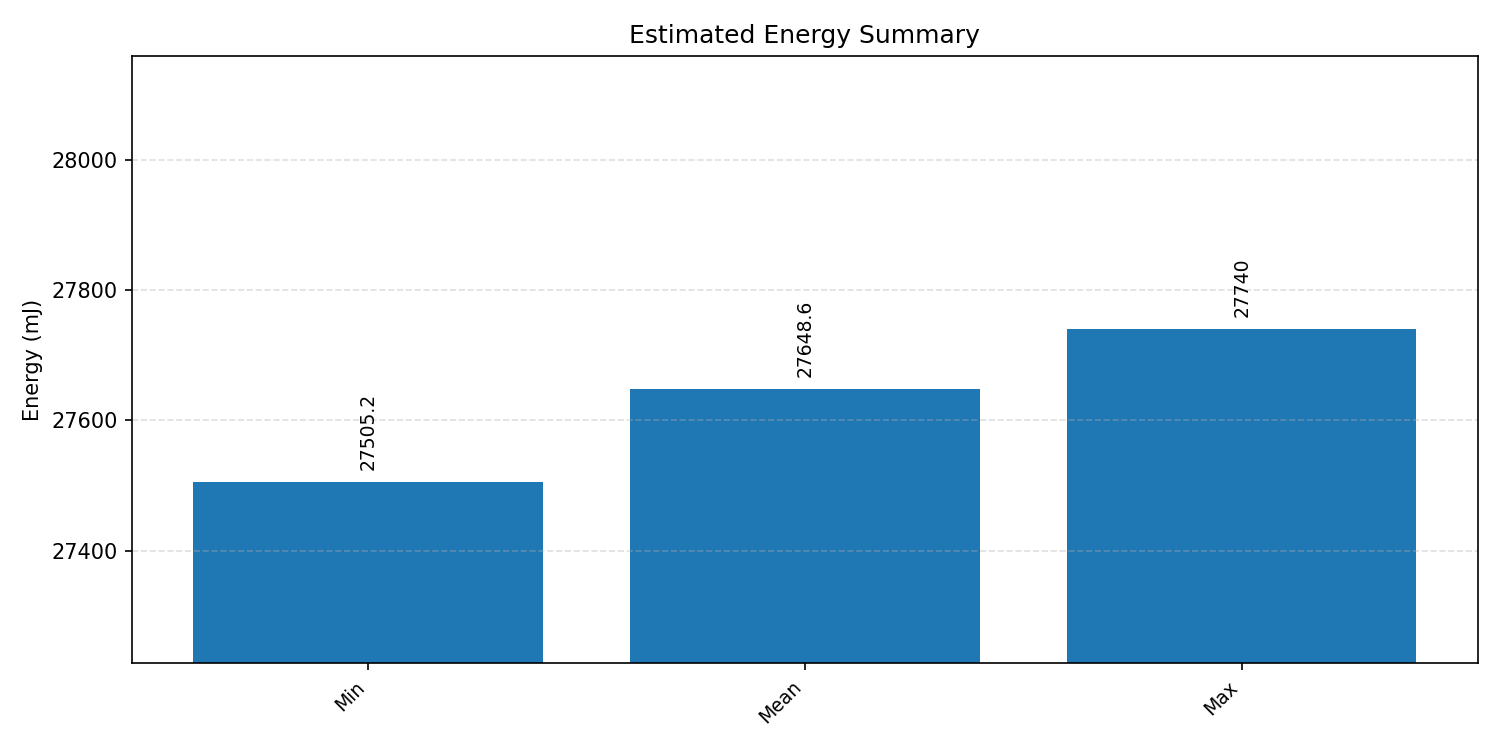
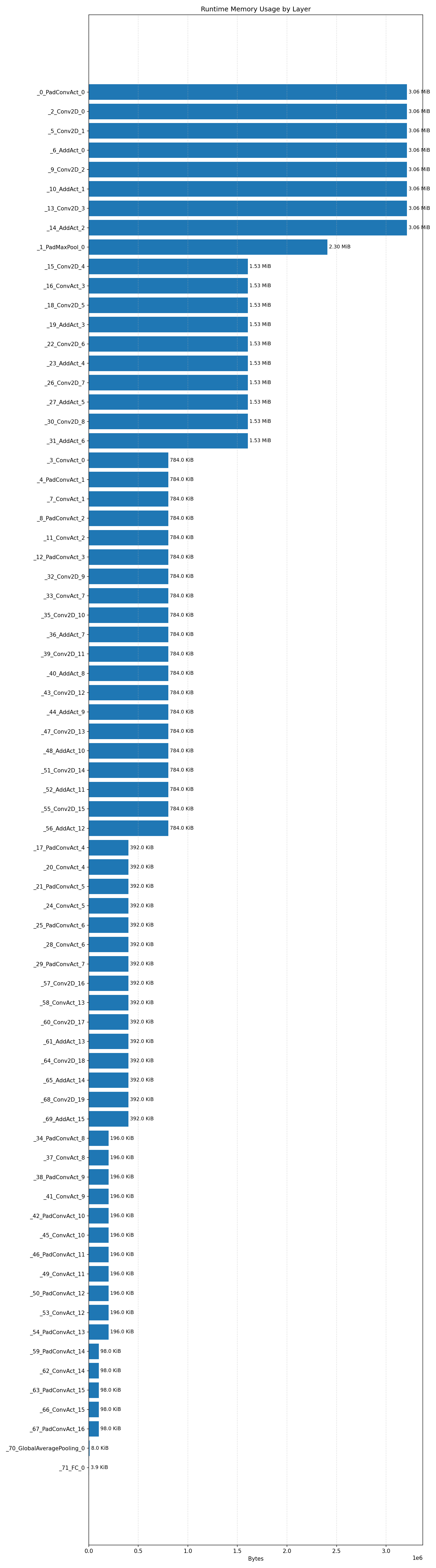
#2.7.2 (FP32) XNNPACK + CPP#
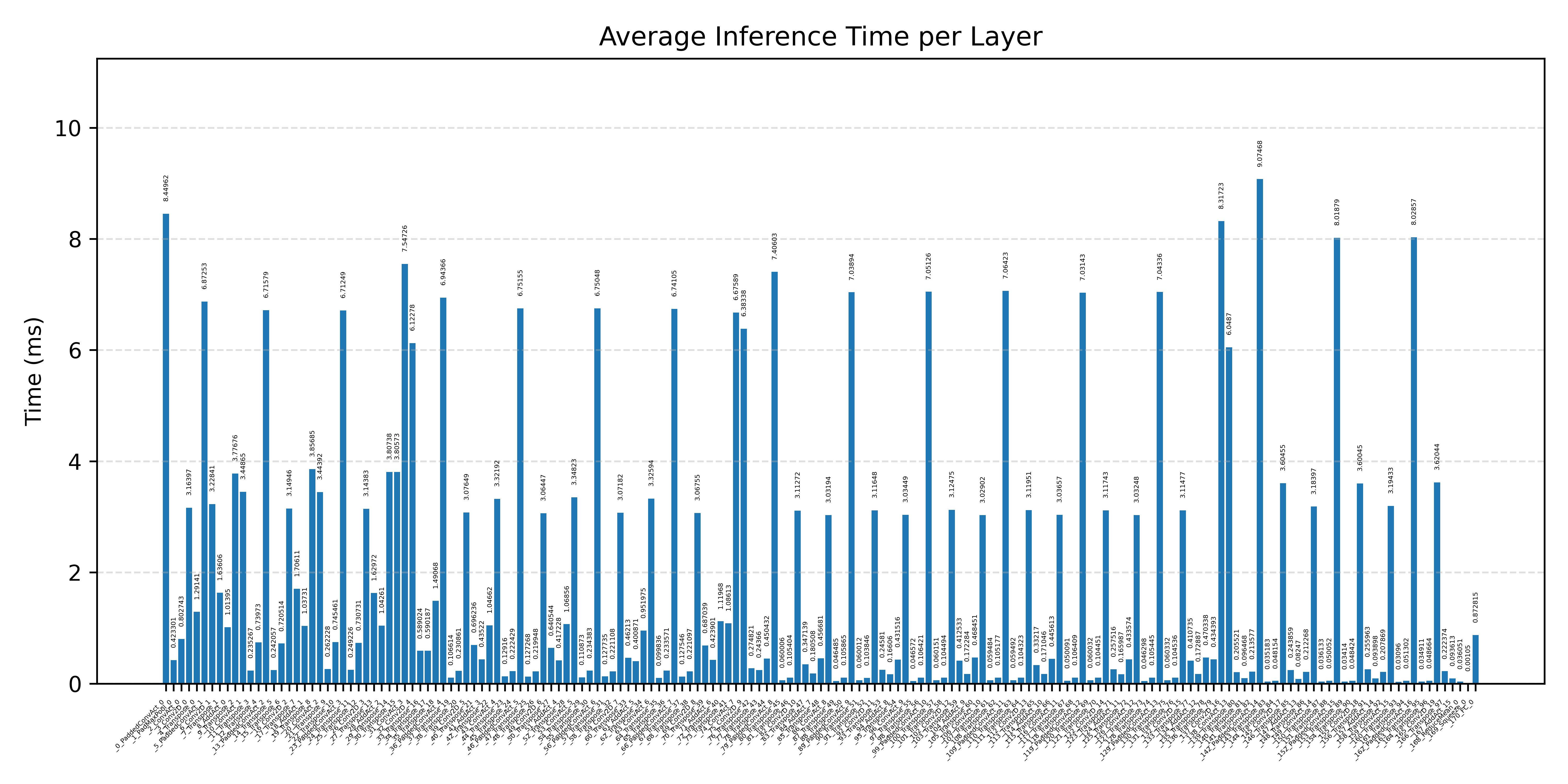
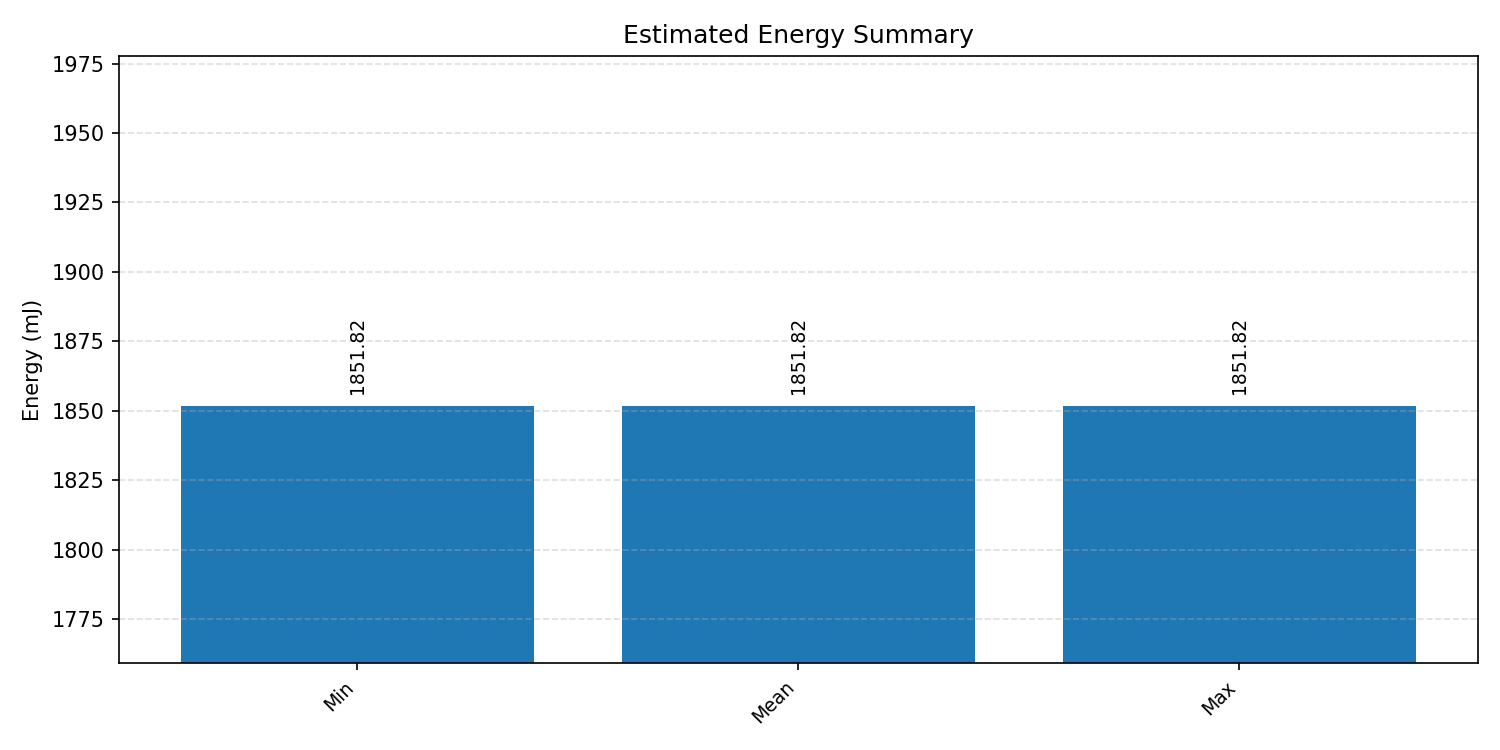

#3. Raspberry Pi Embedded Benchmarks#
The Raspberry Pi results provide an edge-Linux reference point. Each case starts with the compiled Comparison Chart when available, followed by the detailed per-export benchmark graphs.
#3.1 LeNet MNIST#
Comparison Chart
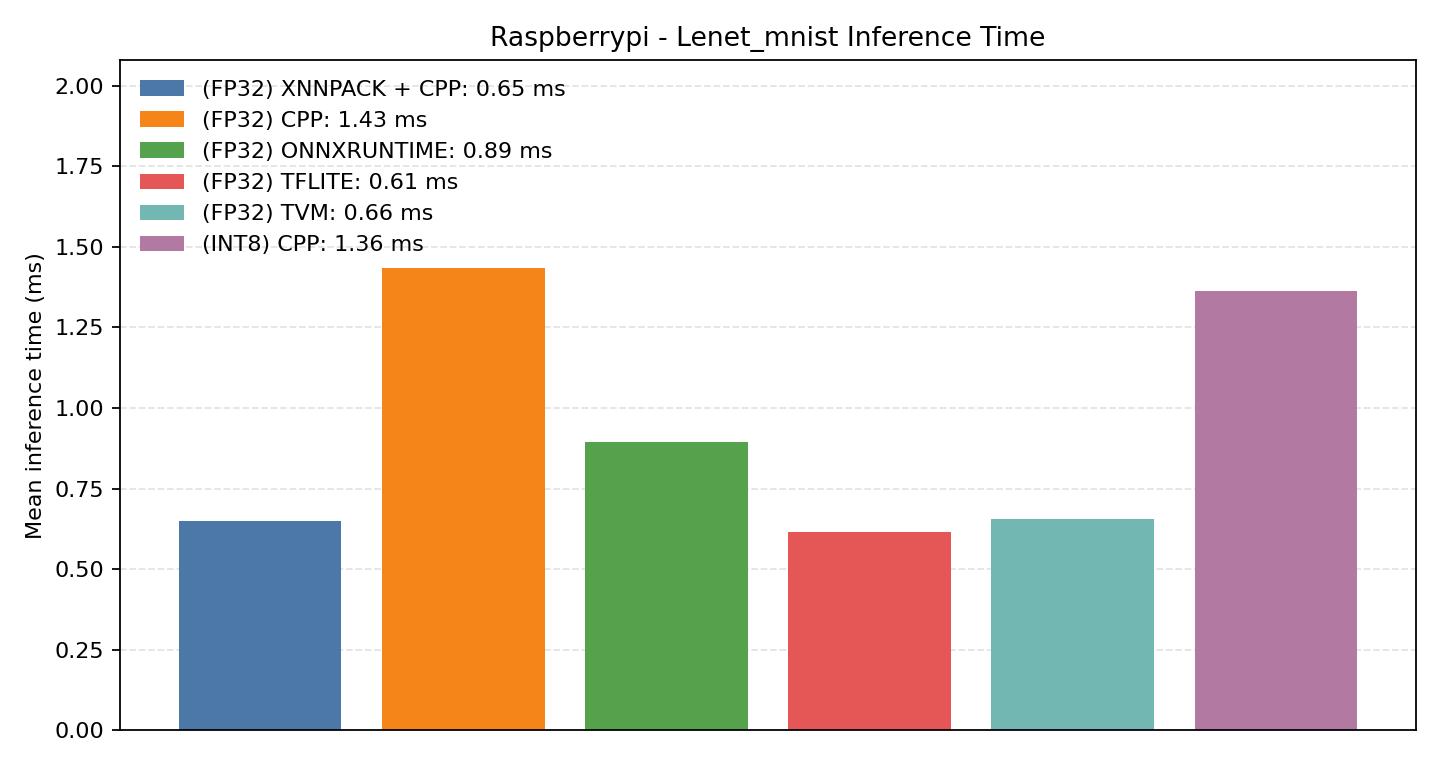
#3.1.1 (FP32) CPP#
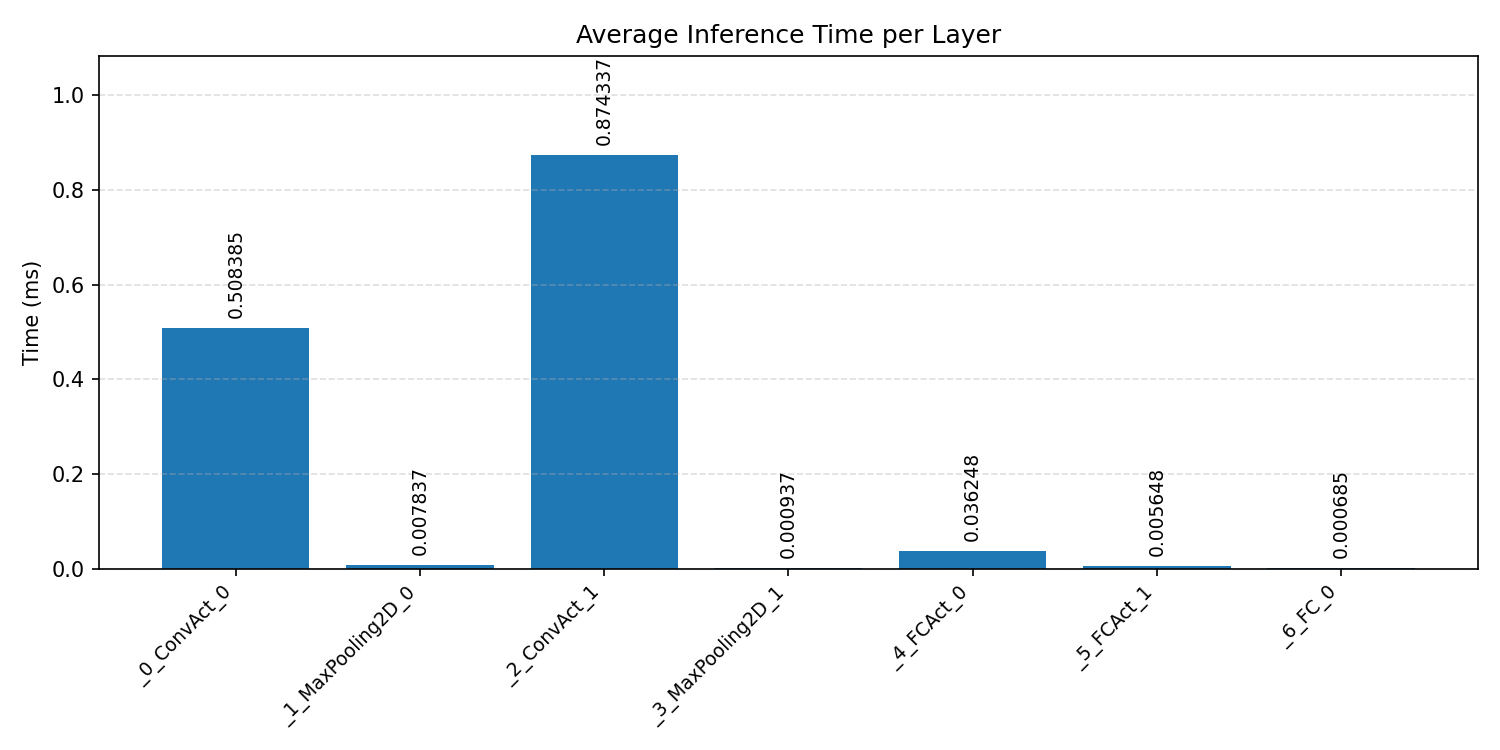
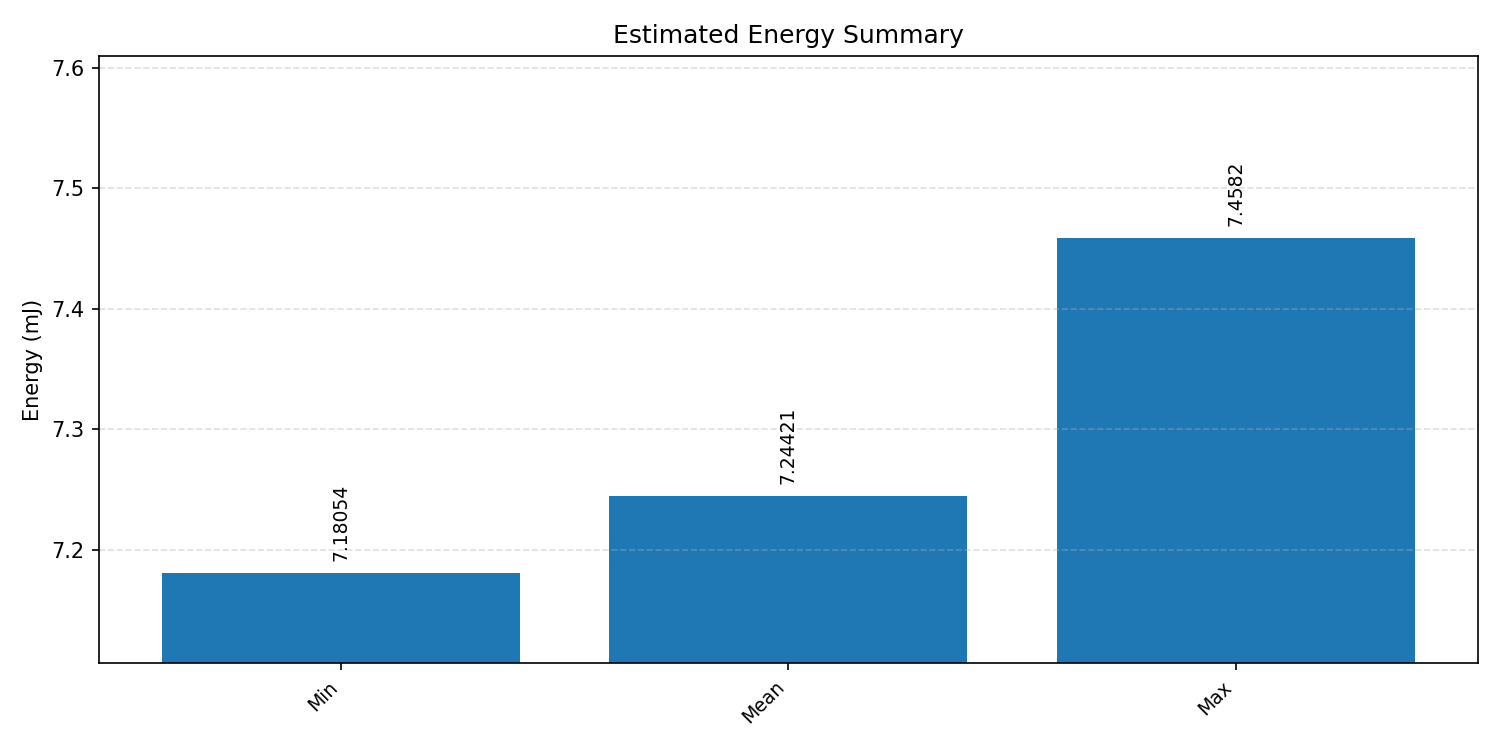
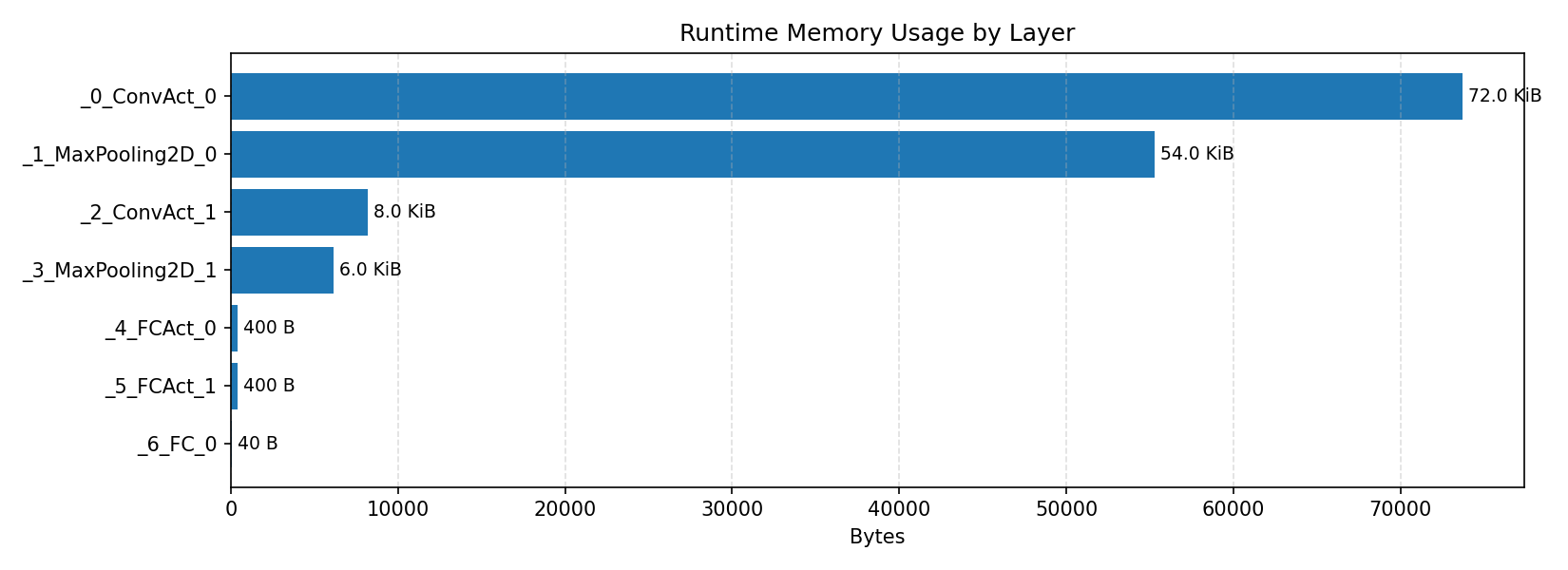
#3.1.2 (FP32) XNNPACK + CPP#
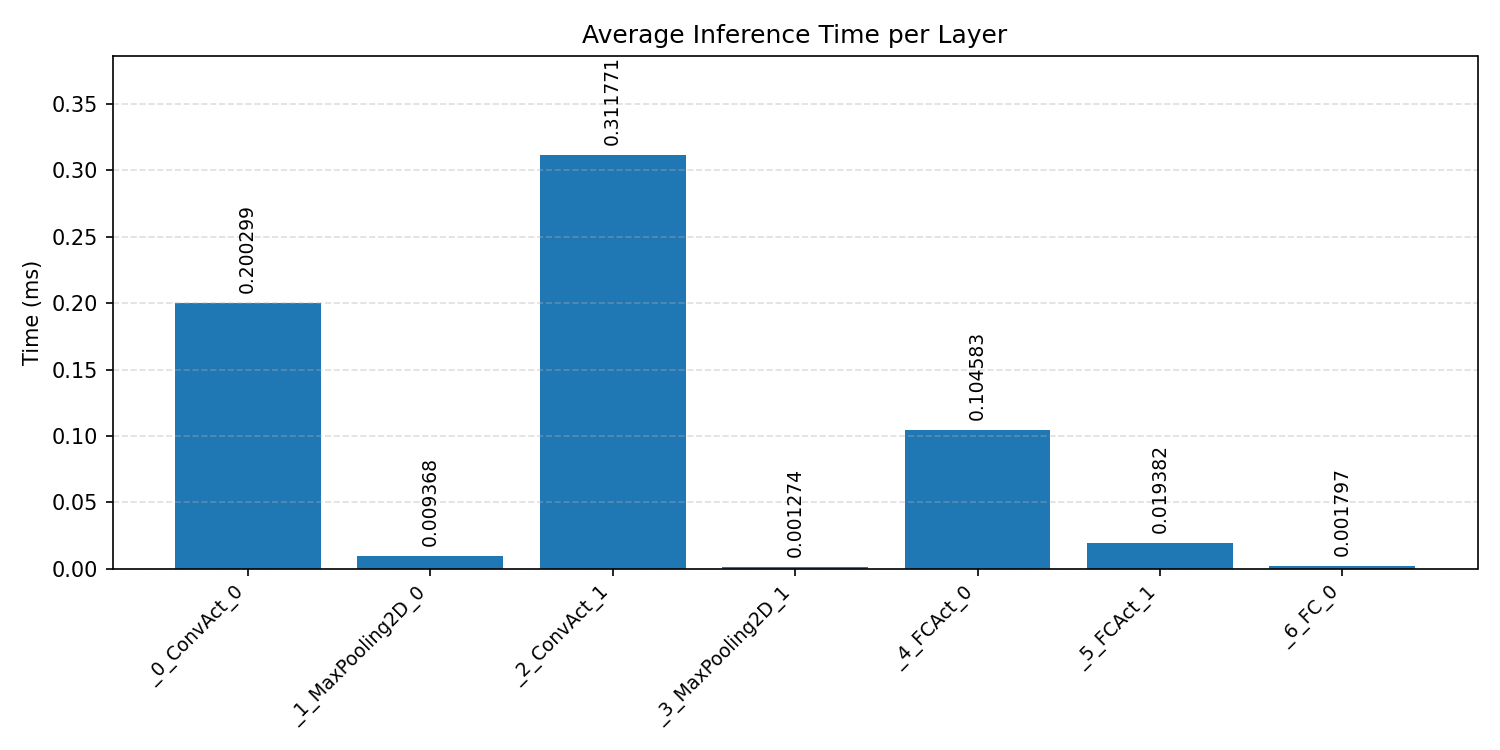
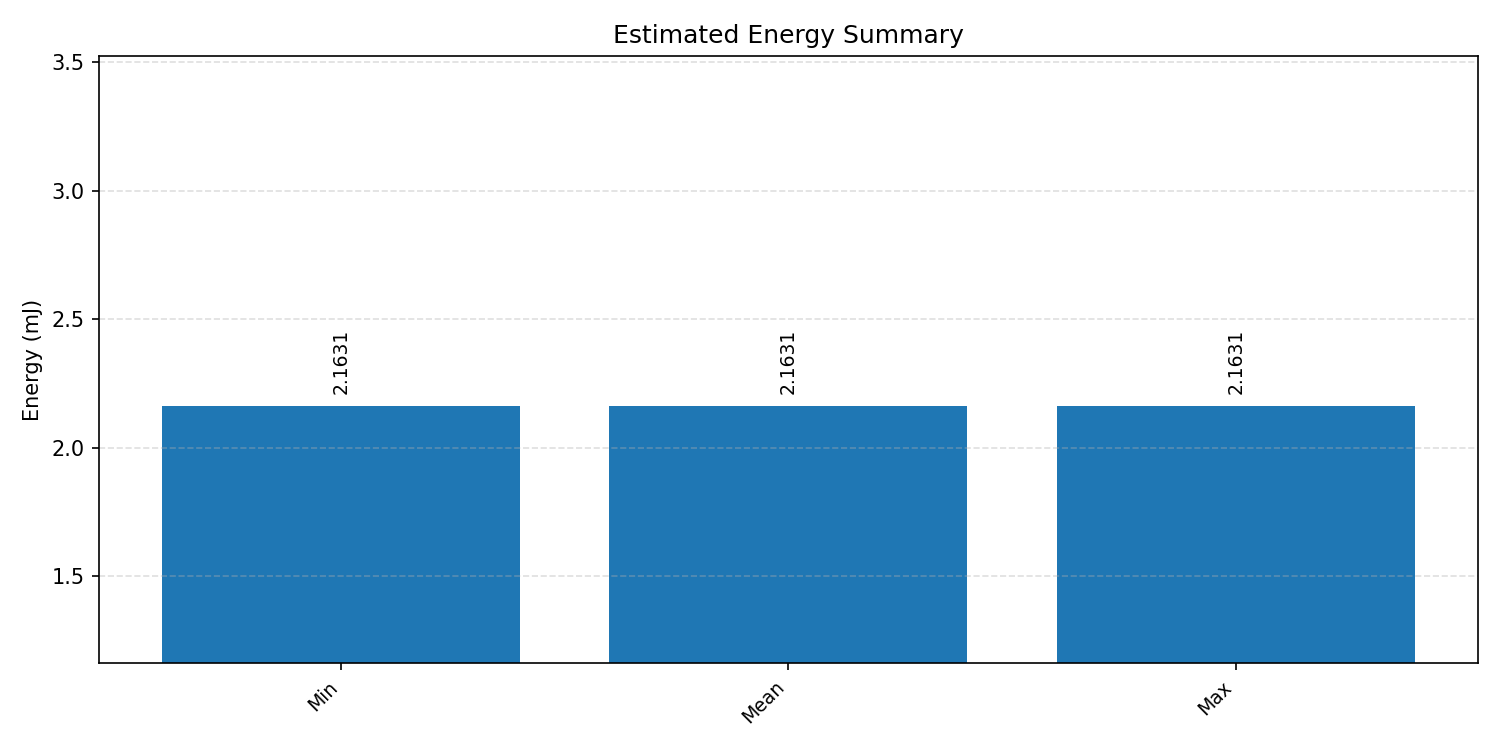
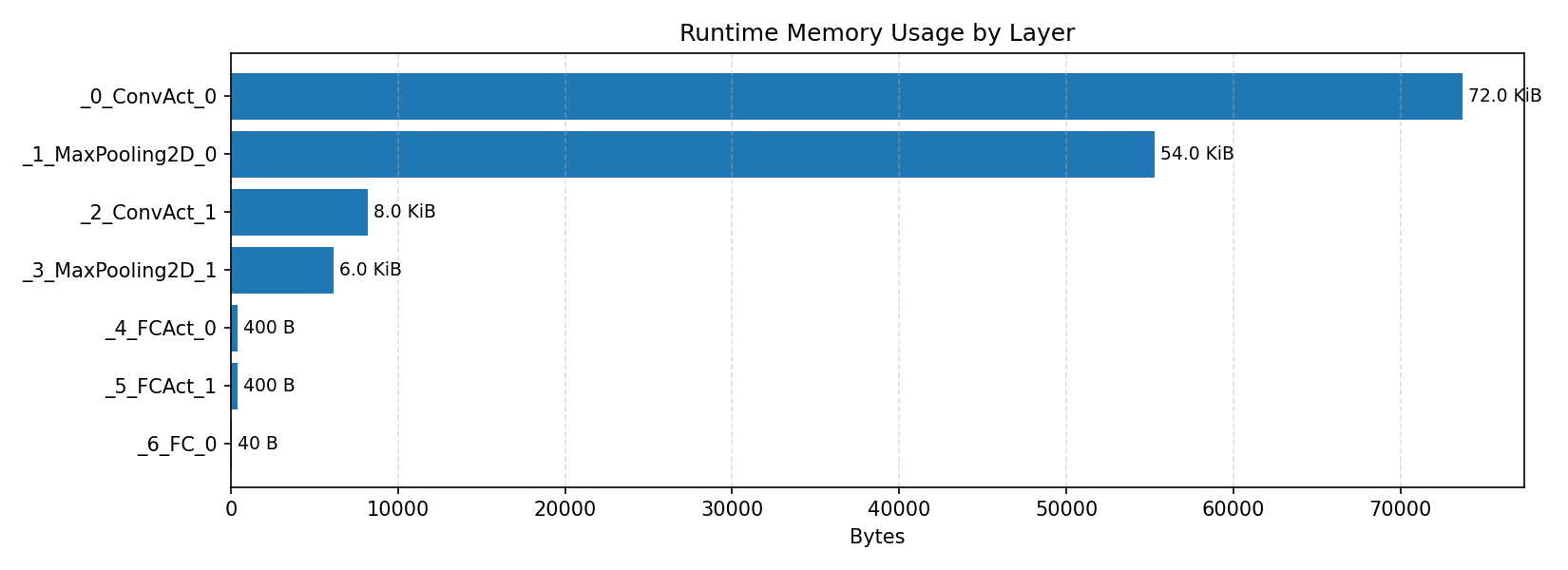
#3.1.3 (INT8) CPP#
#3.2 MobileNet V1 VWW#
Comparison Chart
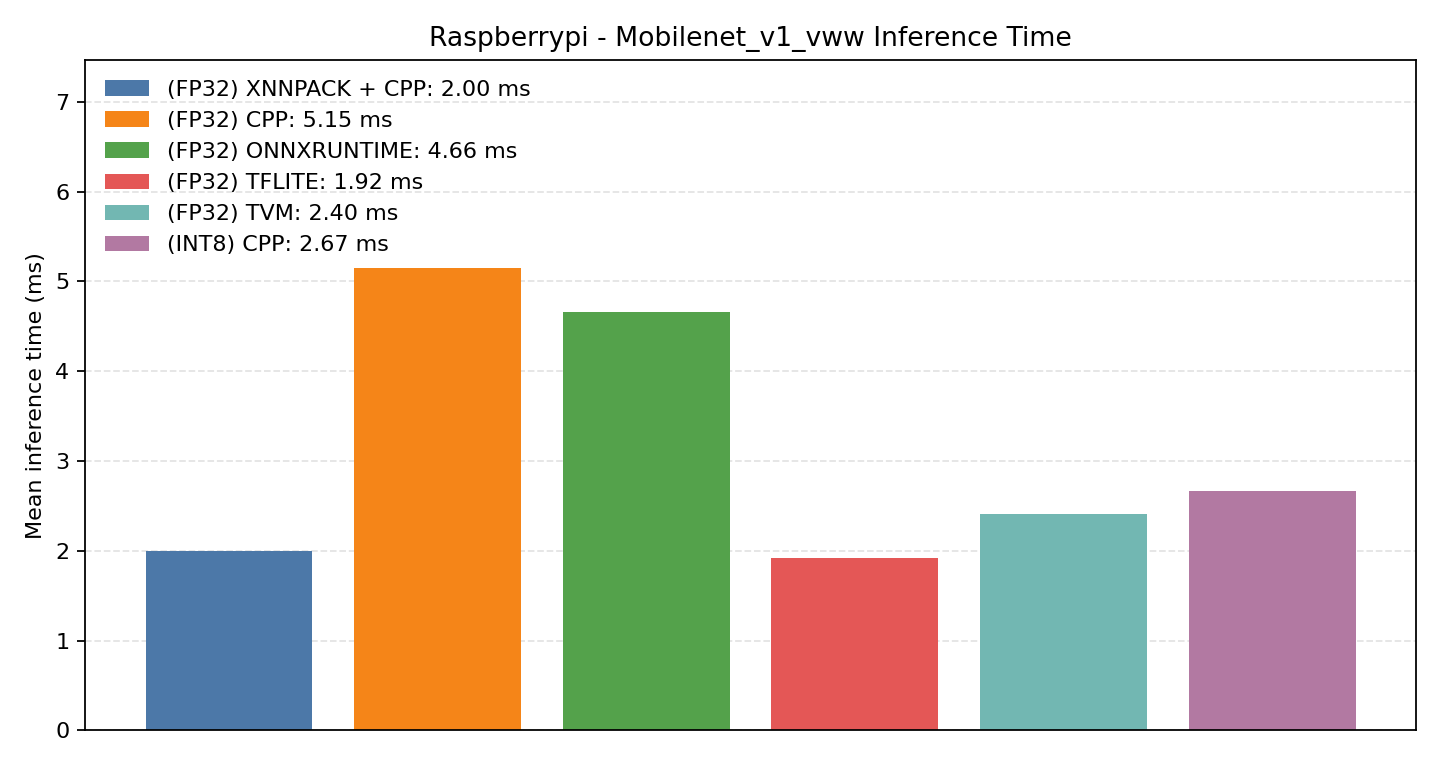
#3.2.1 (FP32) CPP#
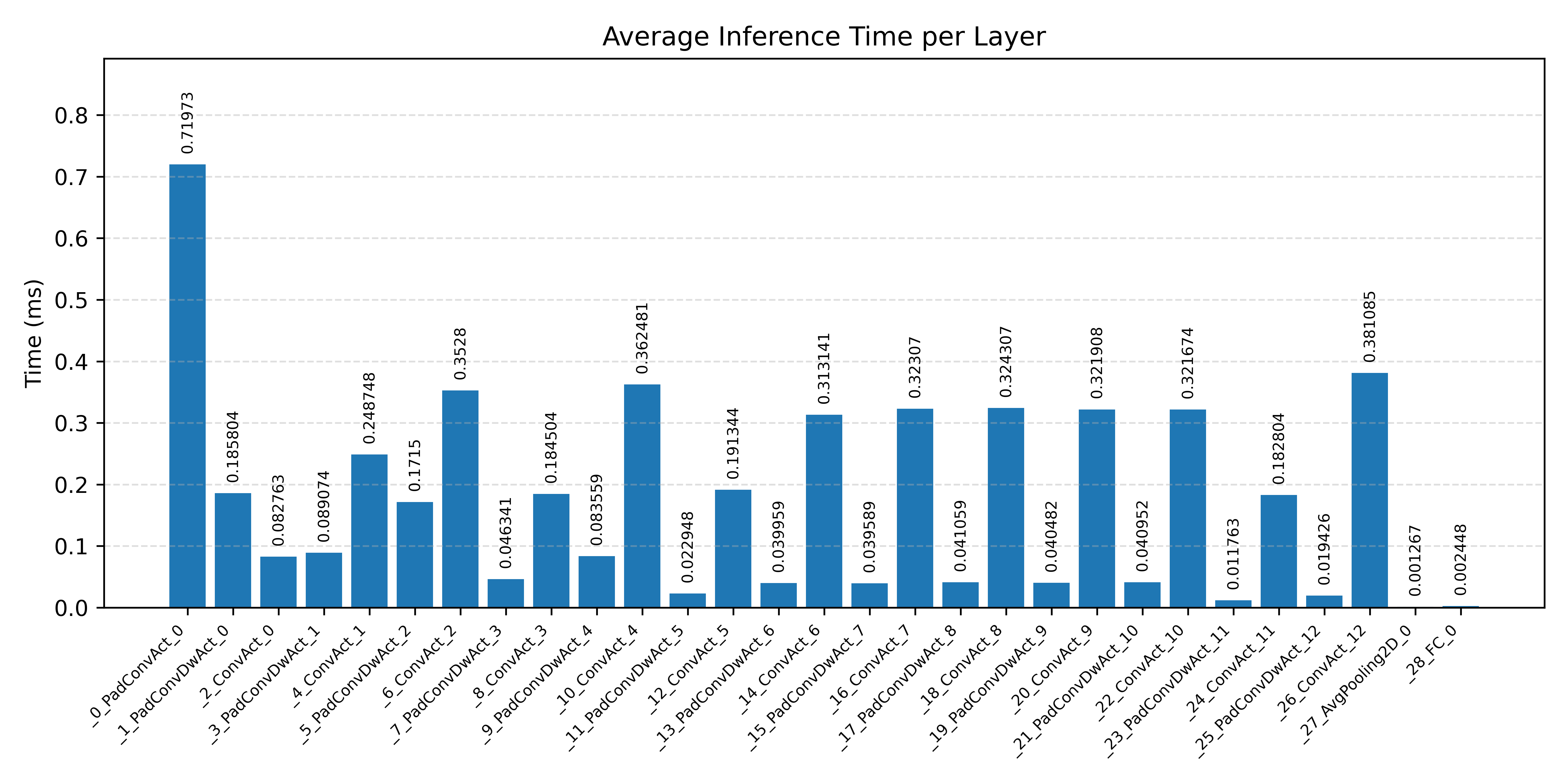
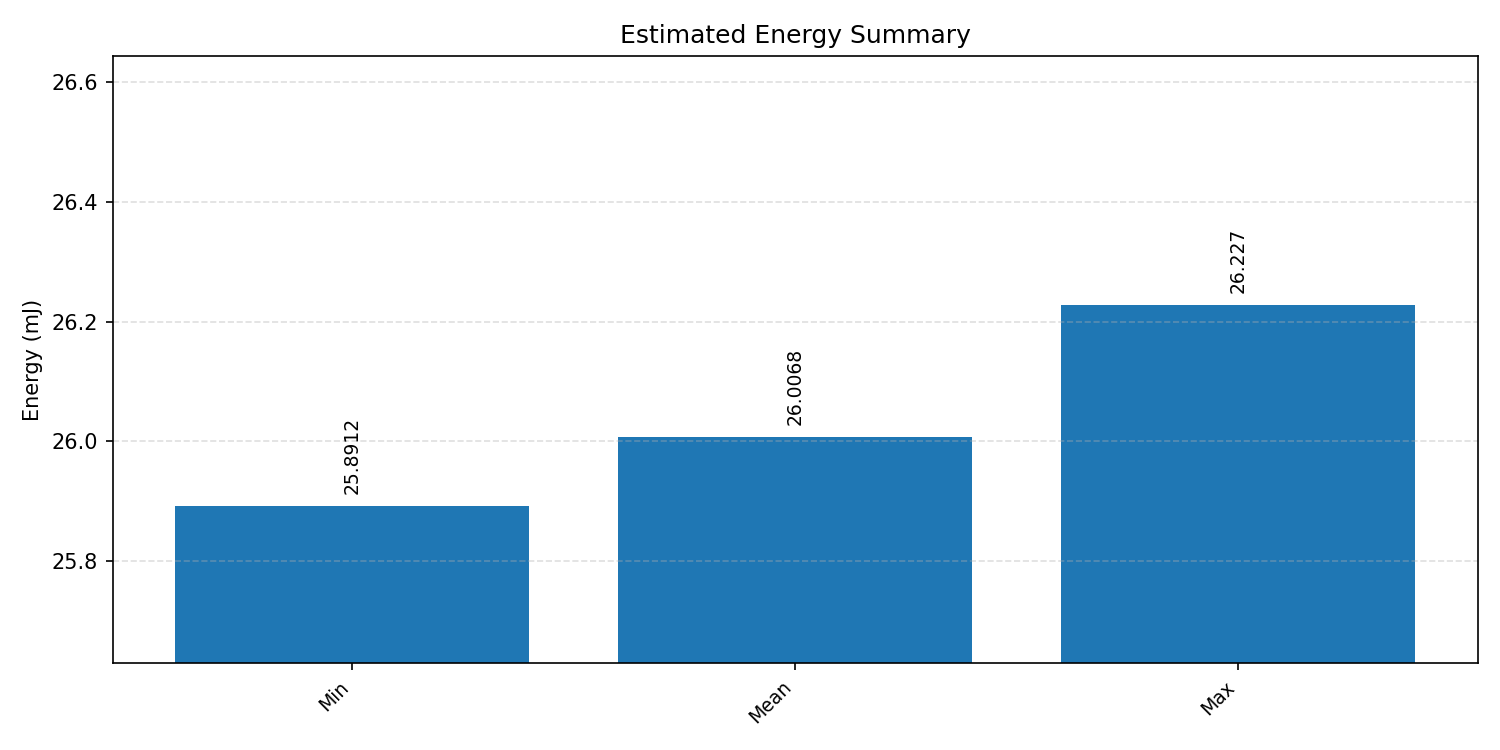
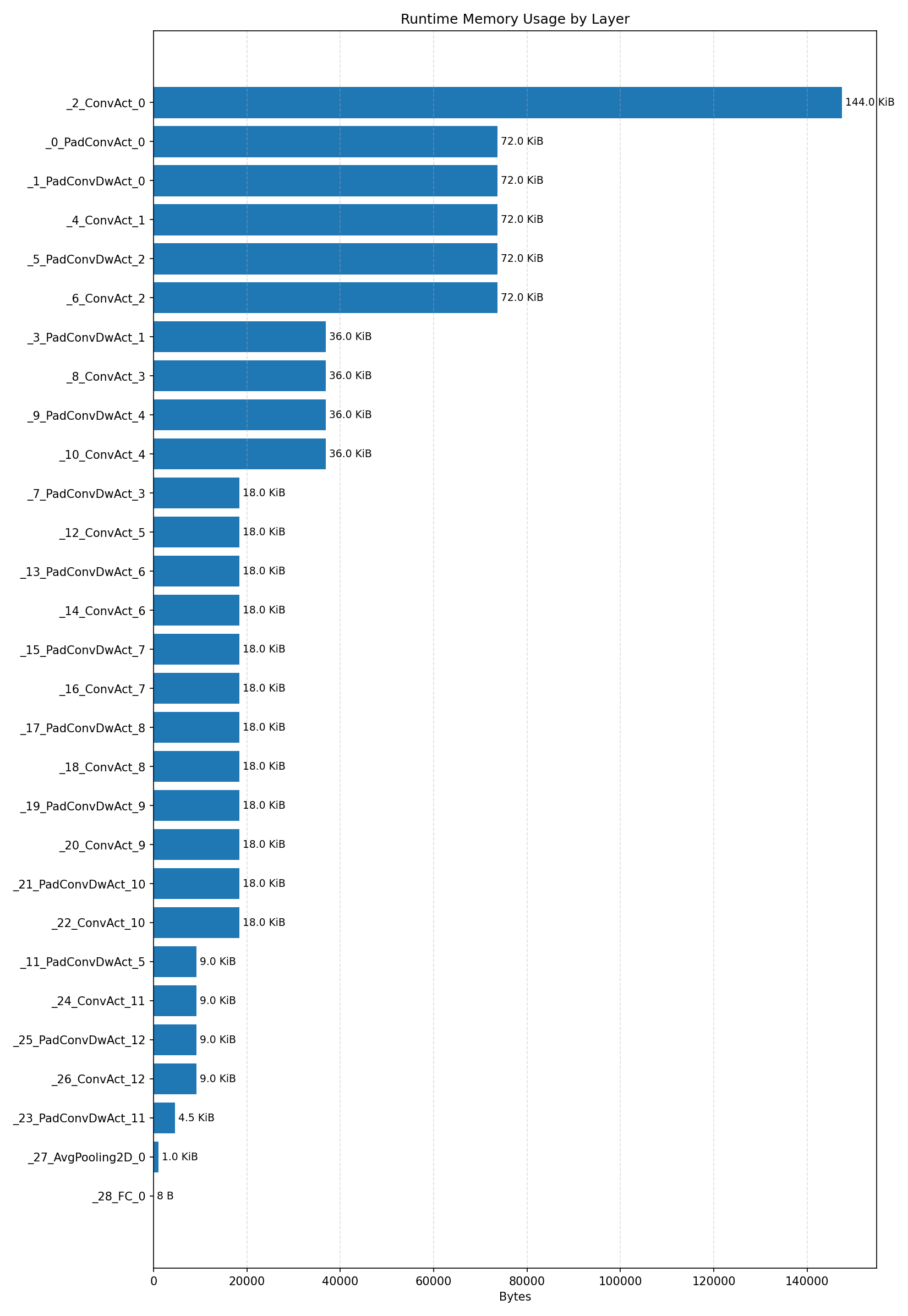
#3.2.2 (FP32) XNNPACK + CPP#
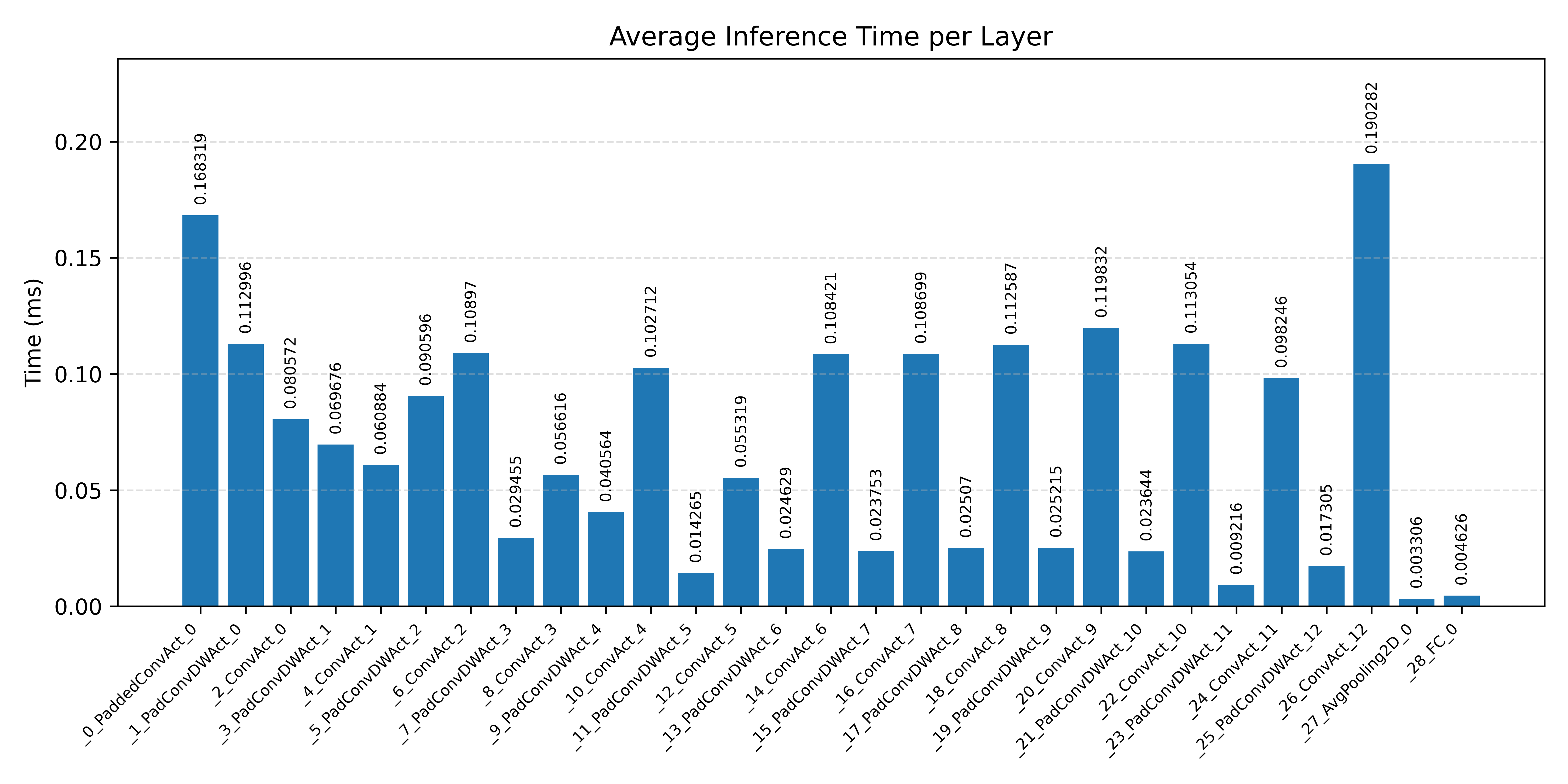
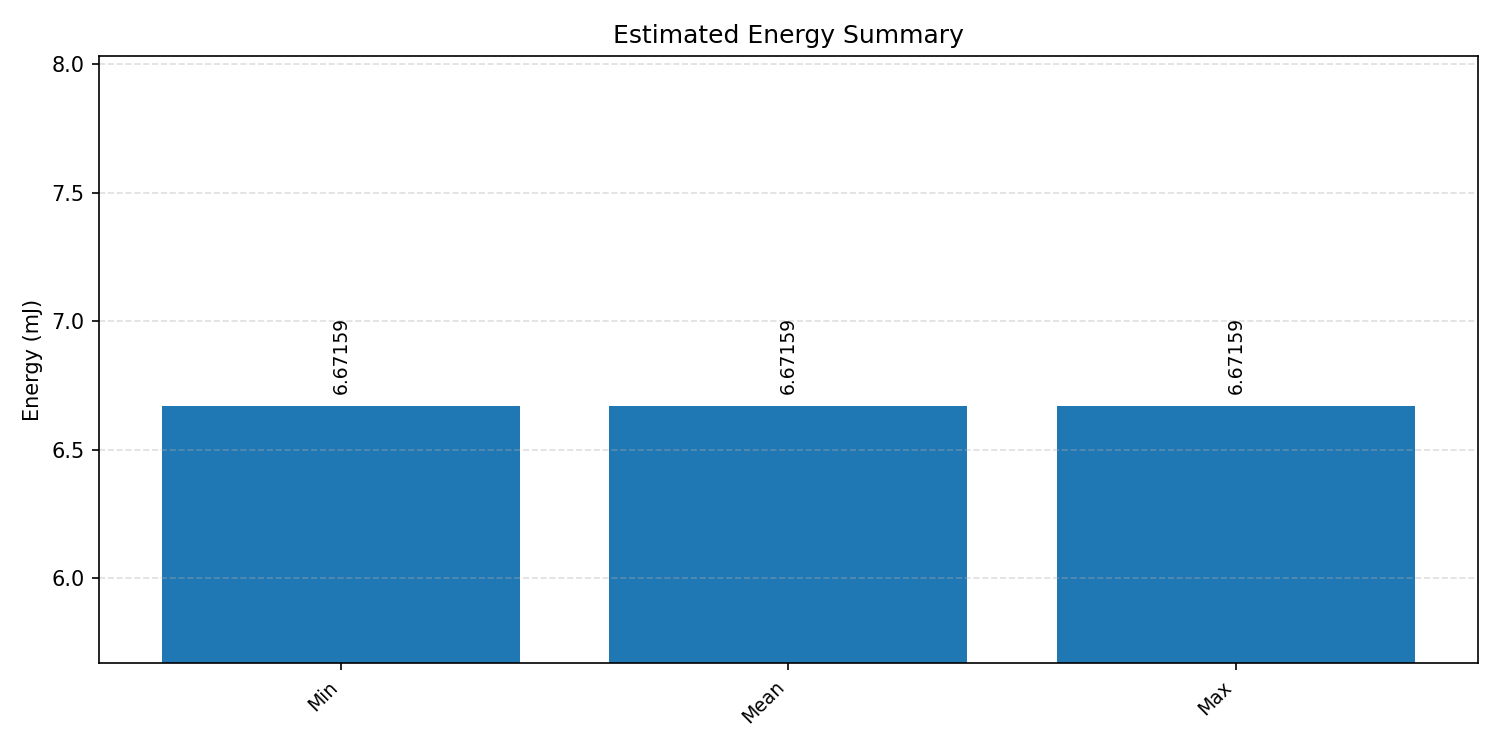
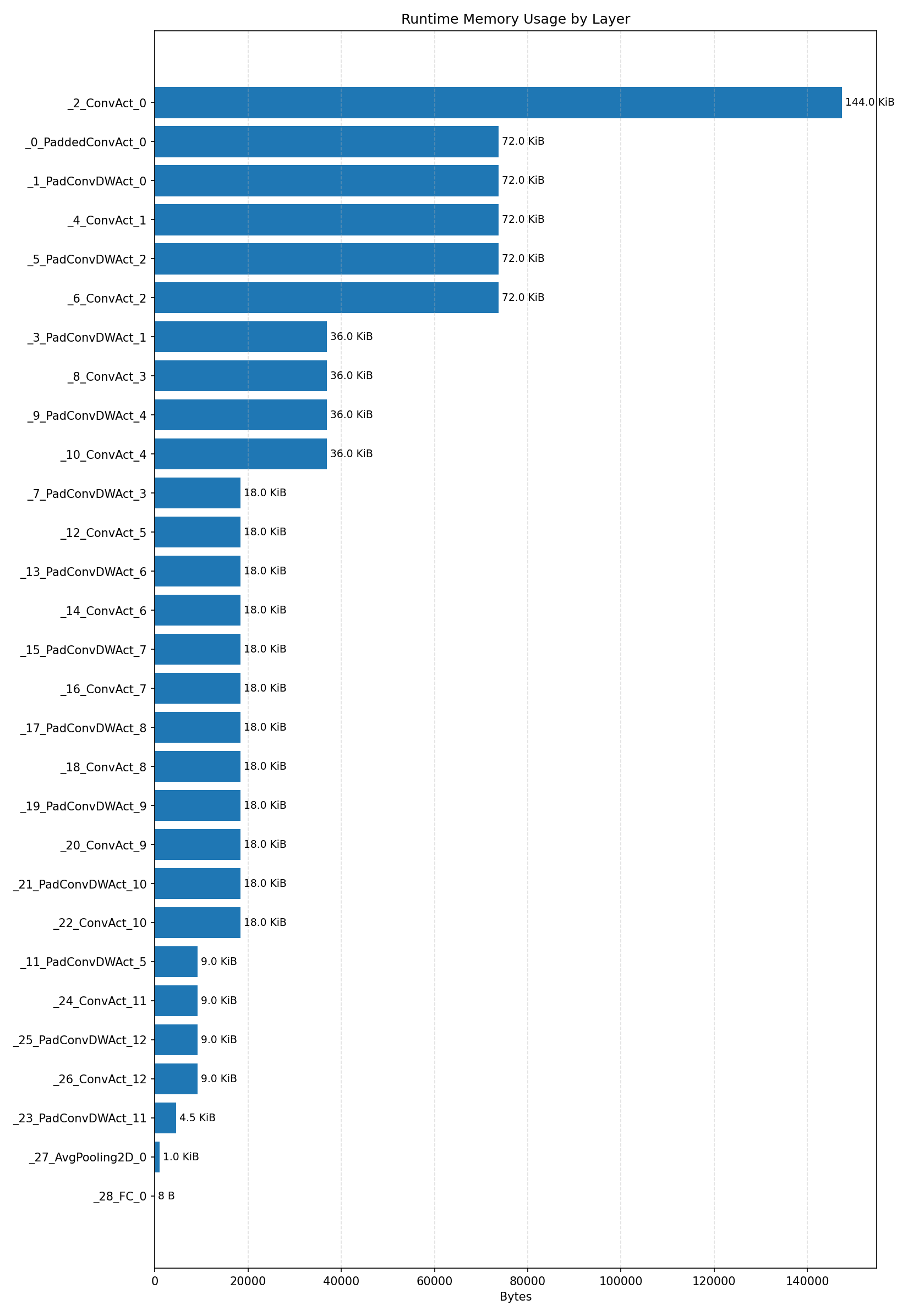
#3.2.3 (INT8) CPP#
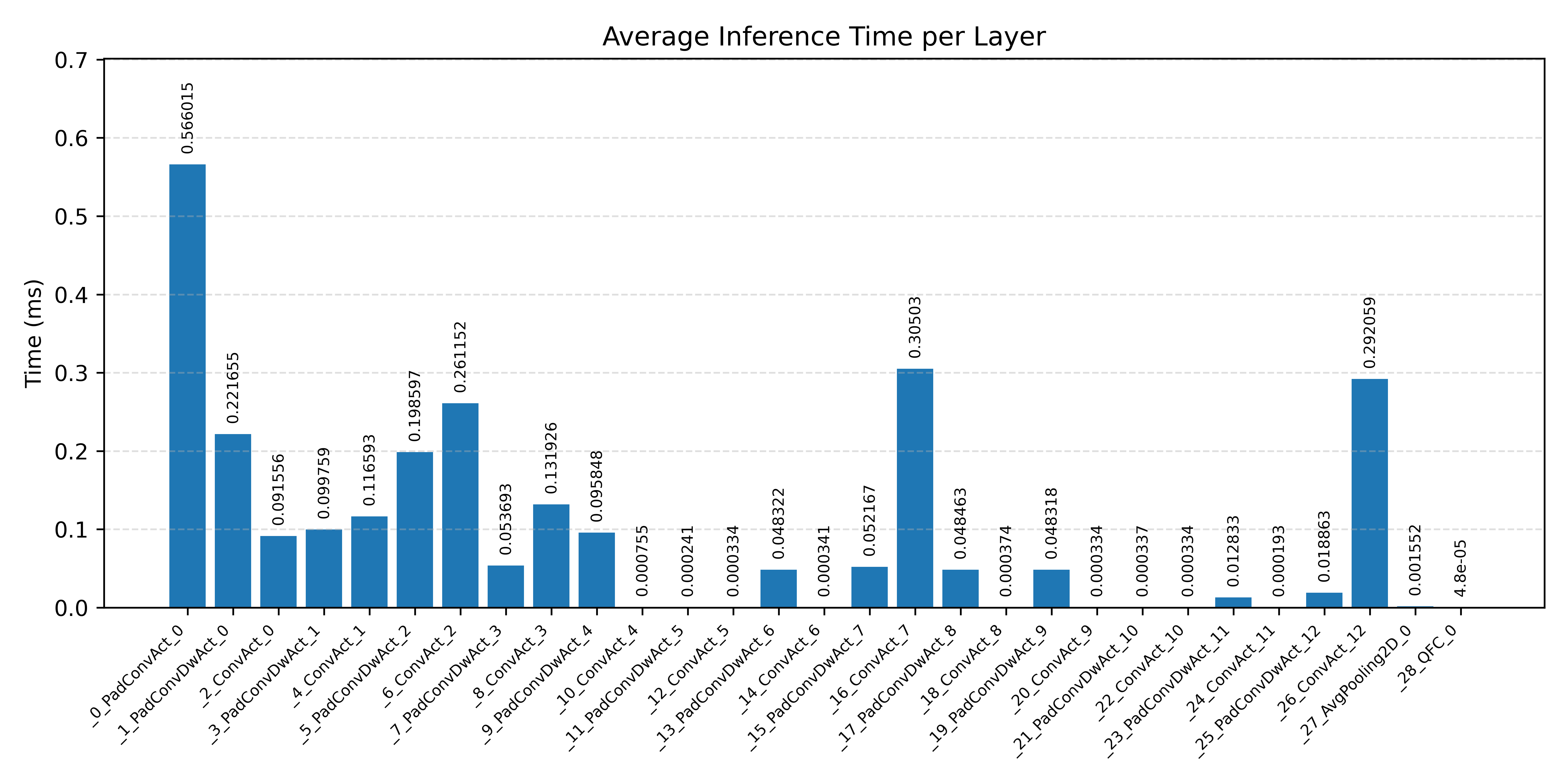
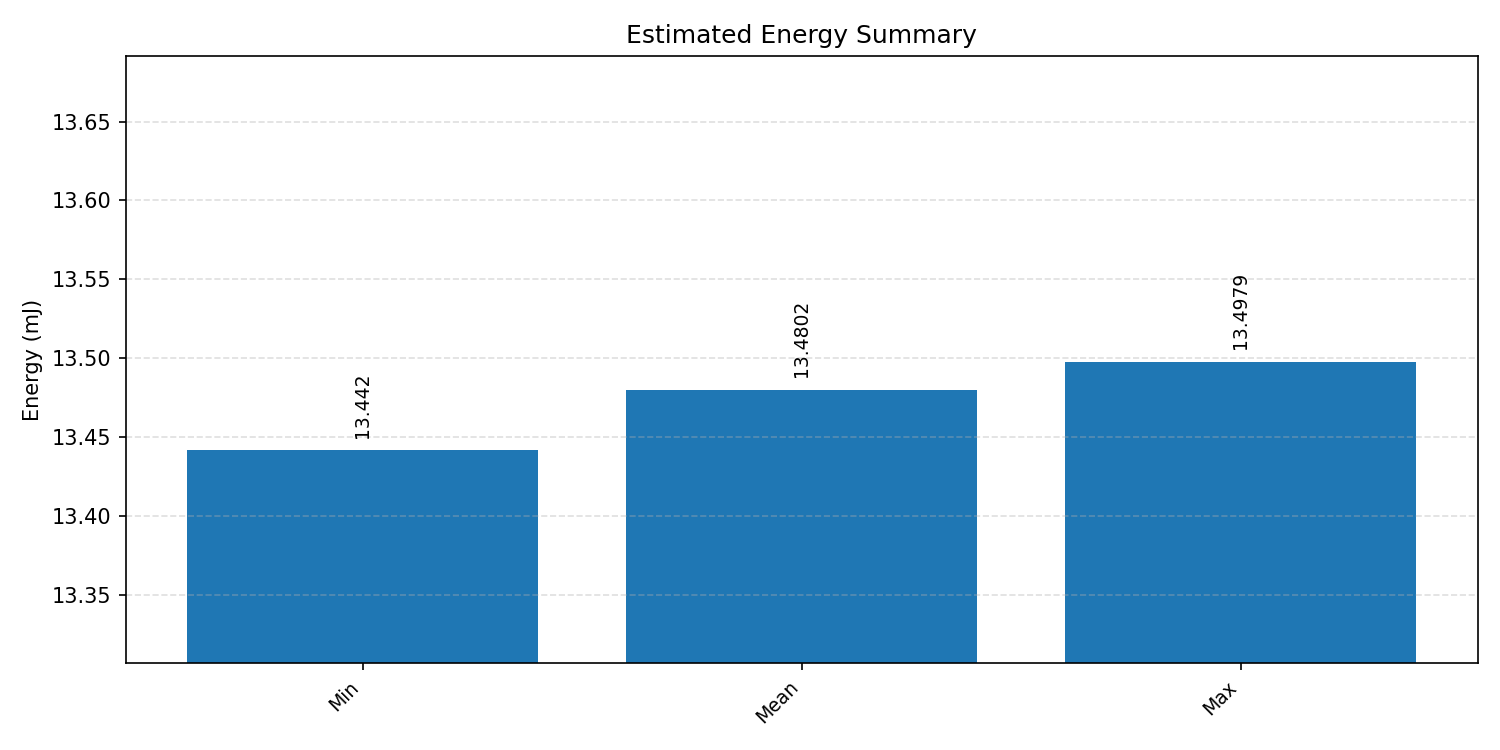
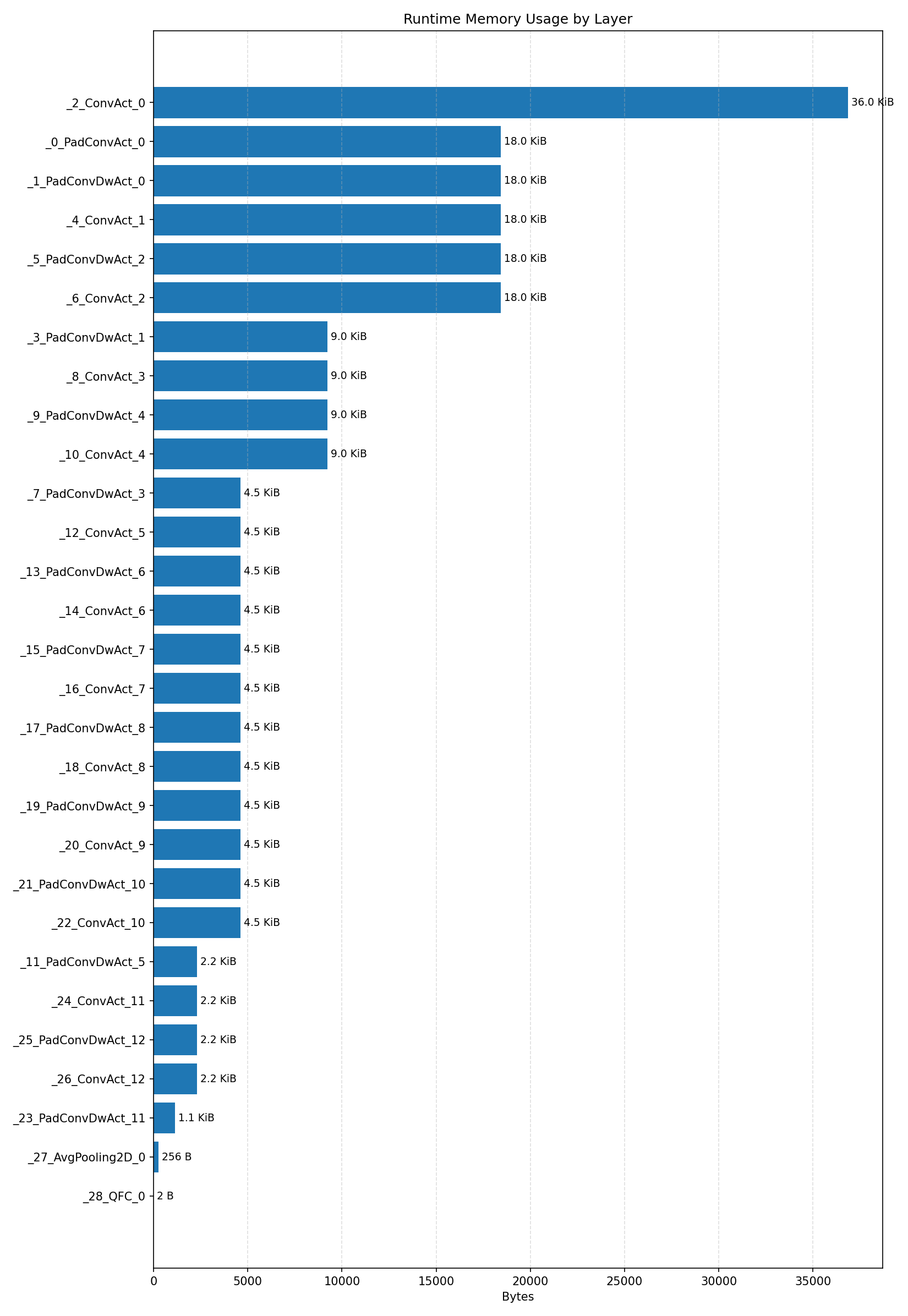
#3.3 ResNet8 CIFAR-10#
Comparison Chart
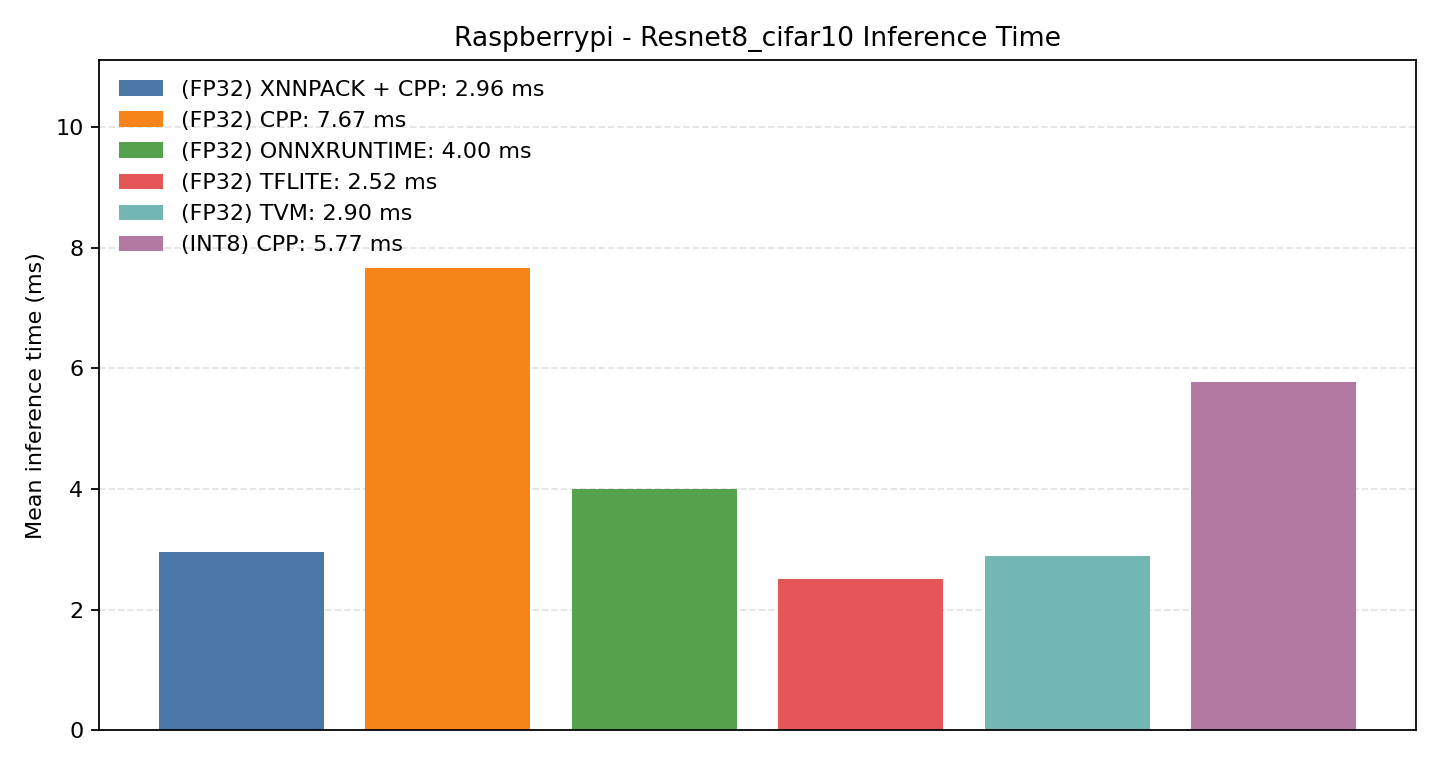
#3.3.1 (FP32) CPP#
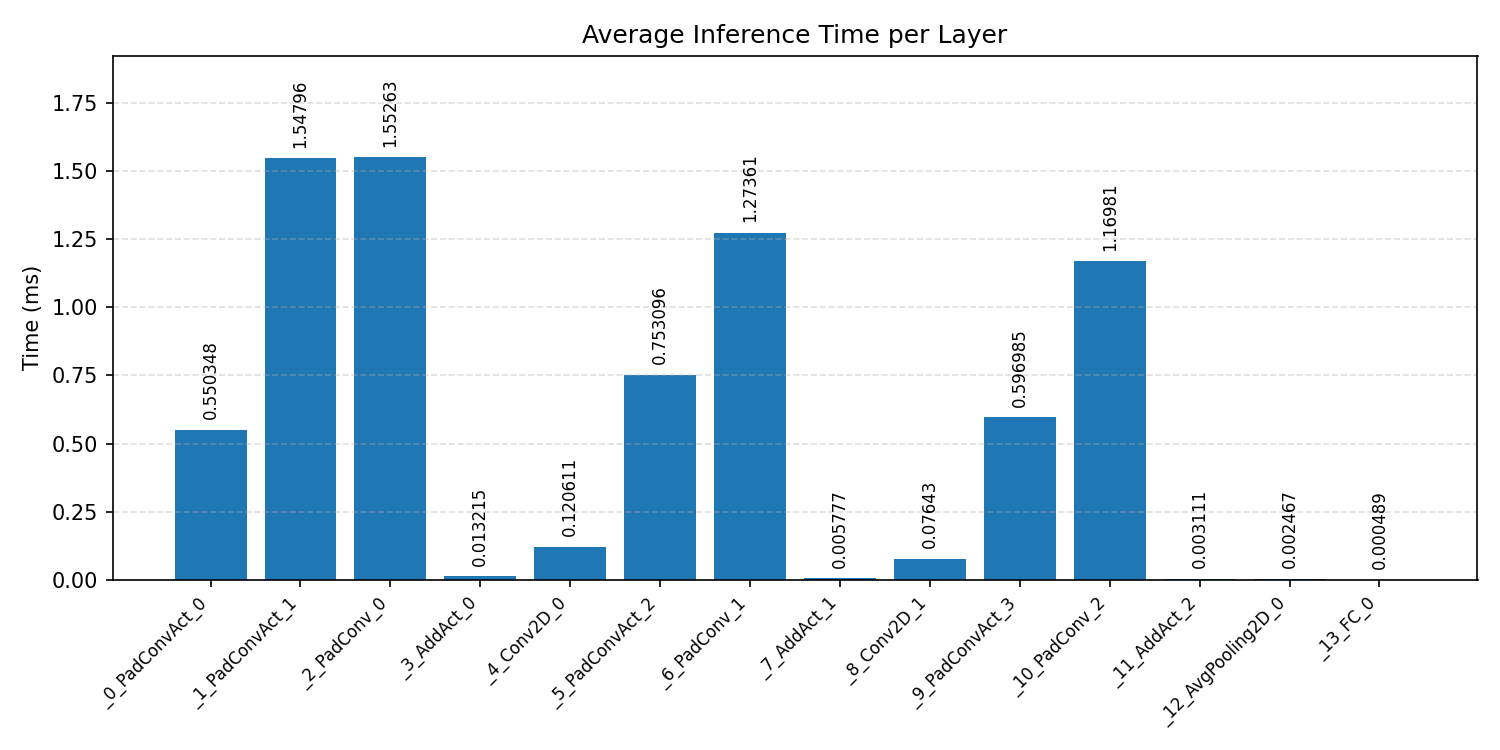
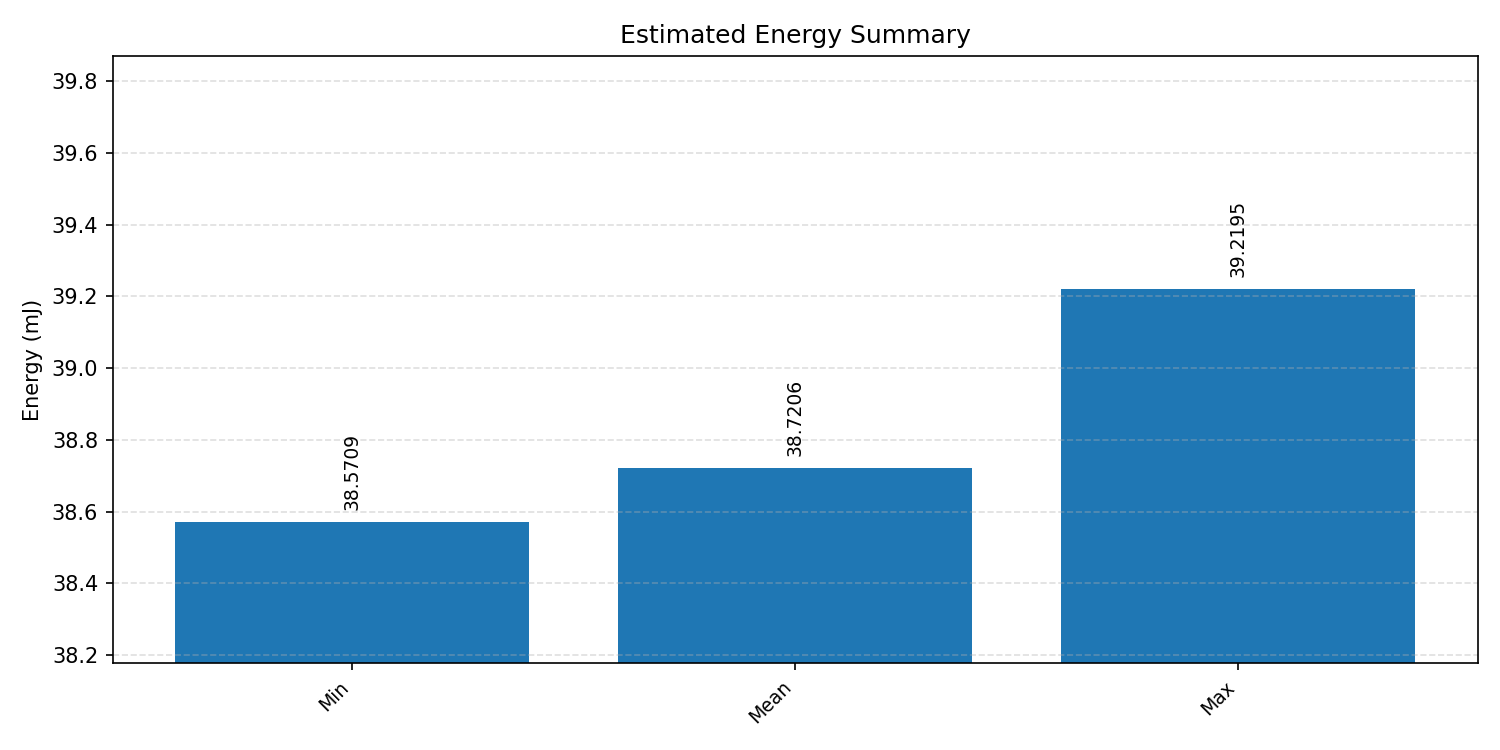
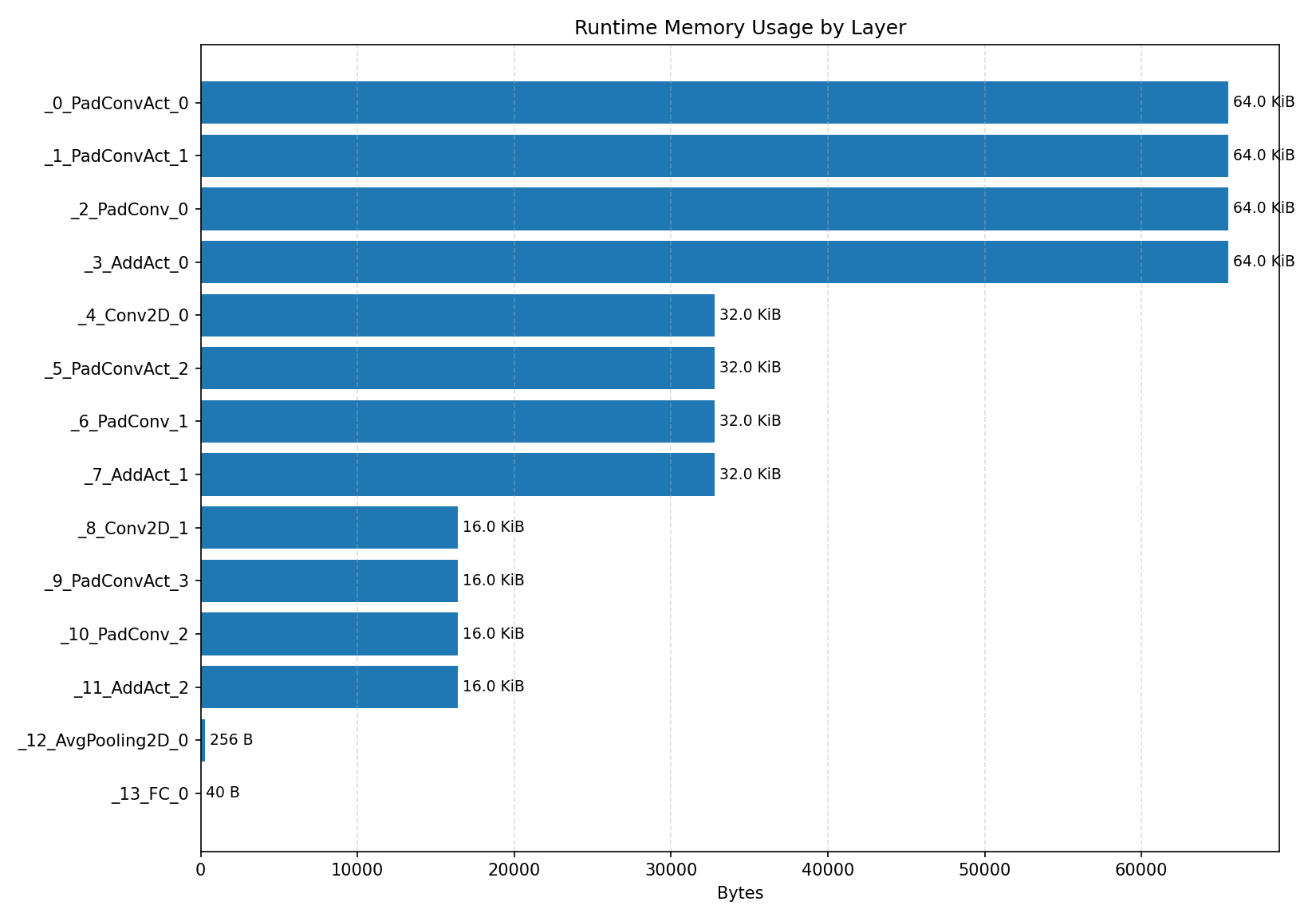
#3.3.2 (FP32) XNNPACK + CPP#
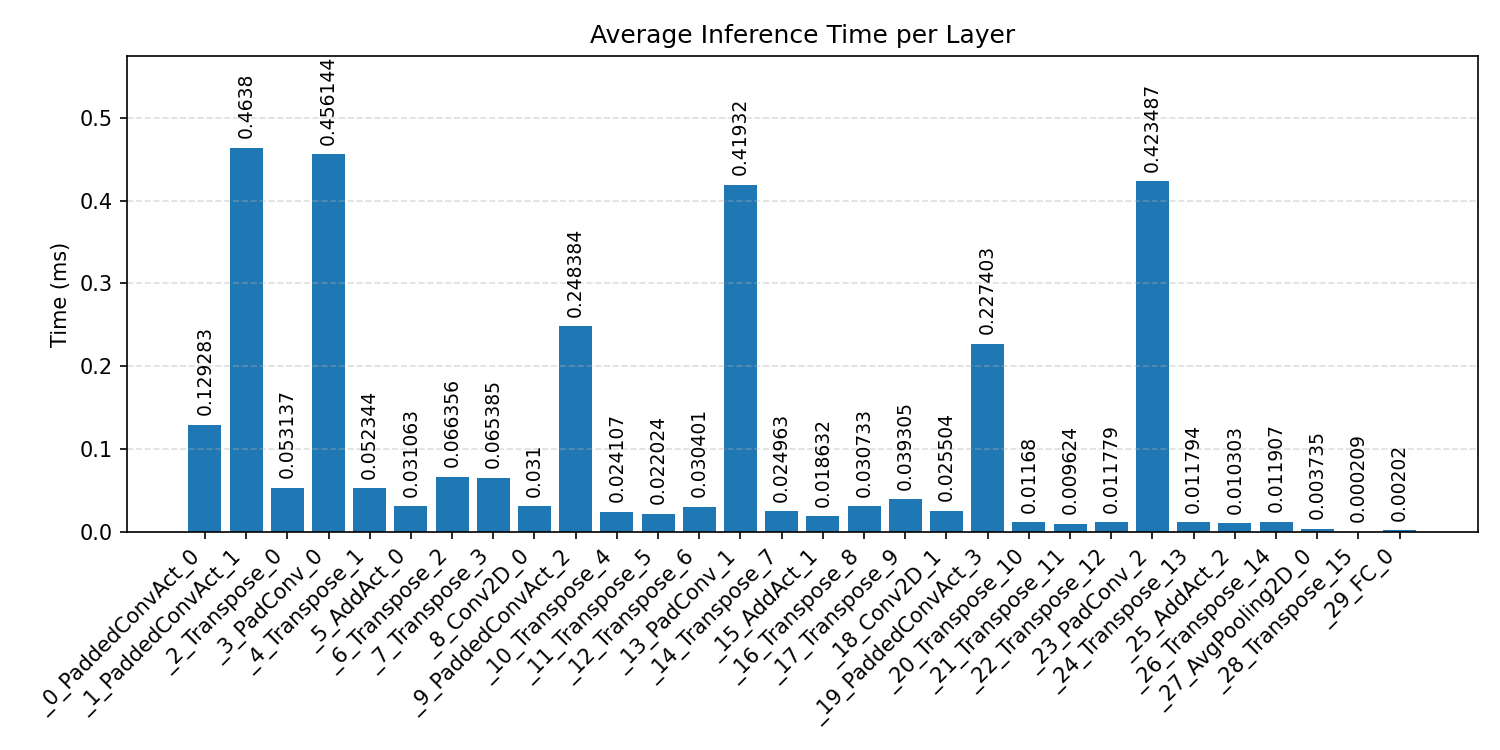
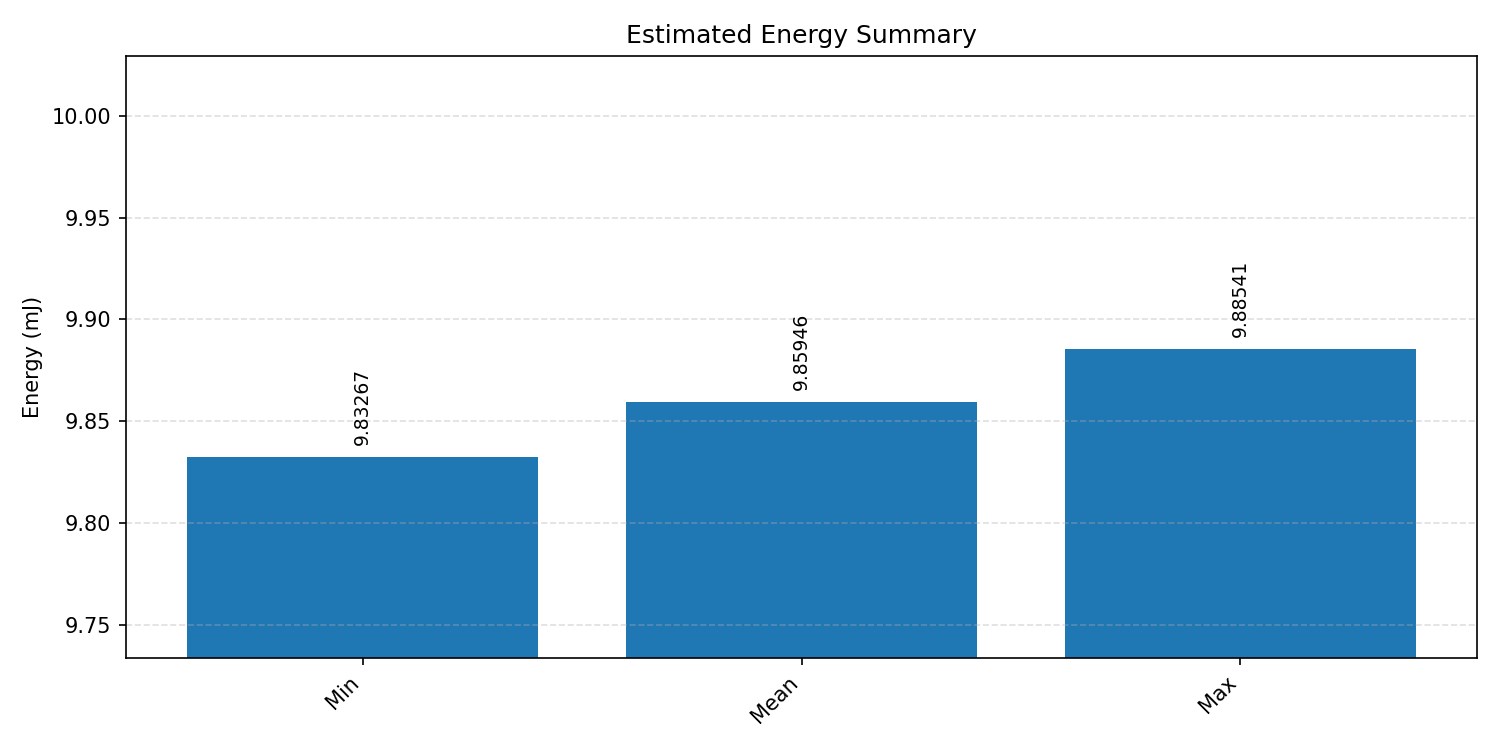
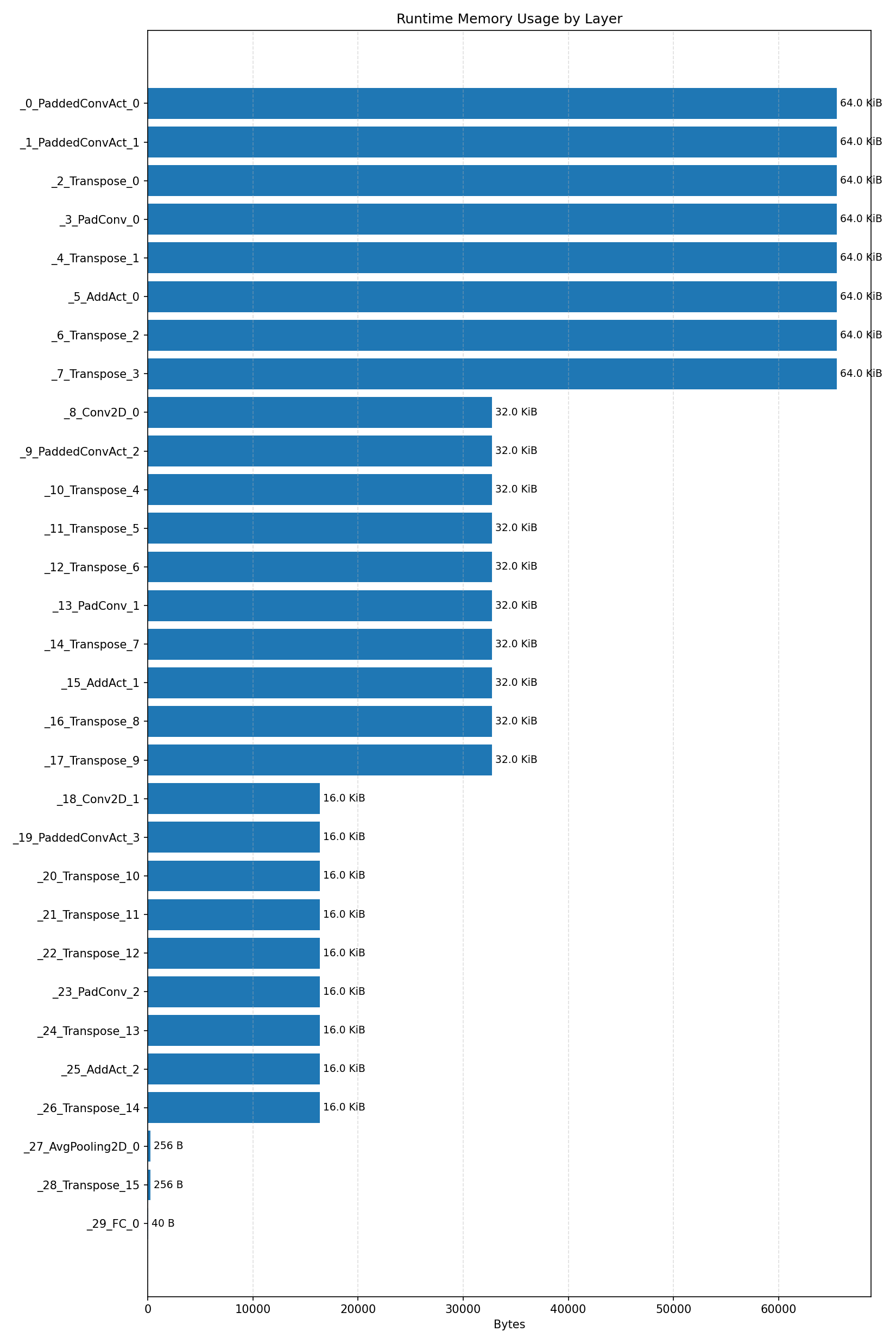
#3.3.3 (INT8) CPP#
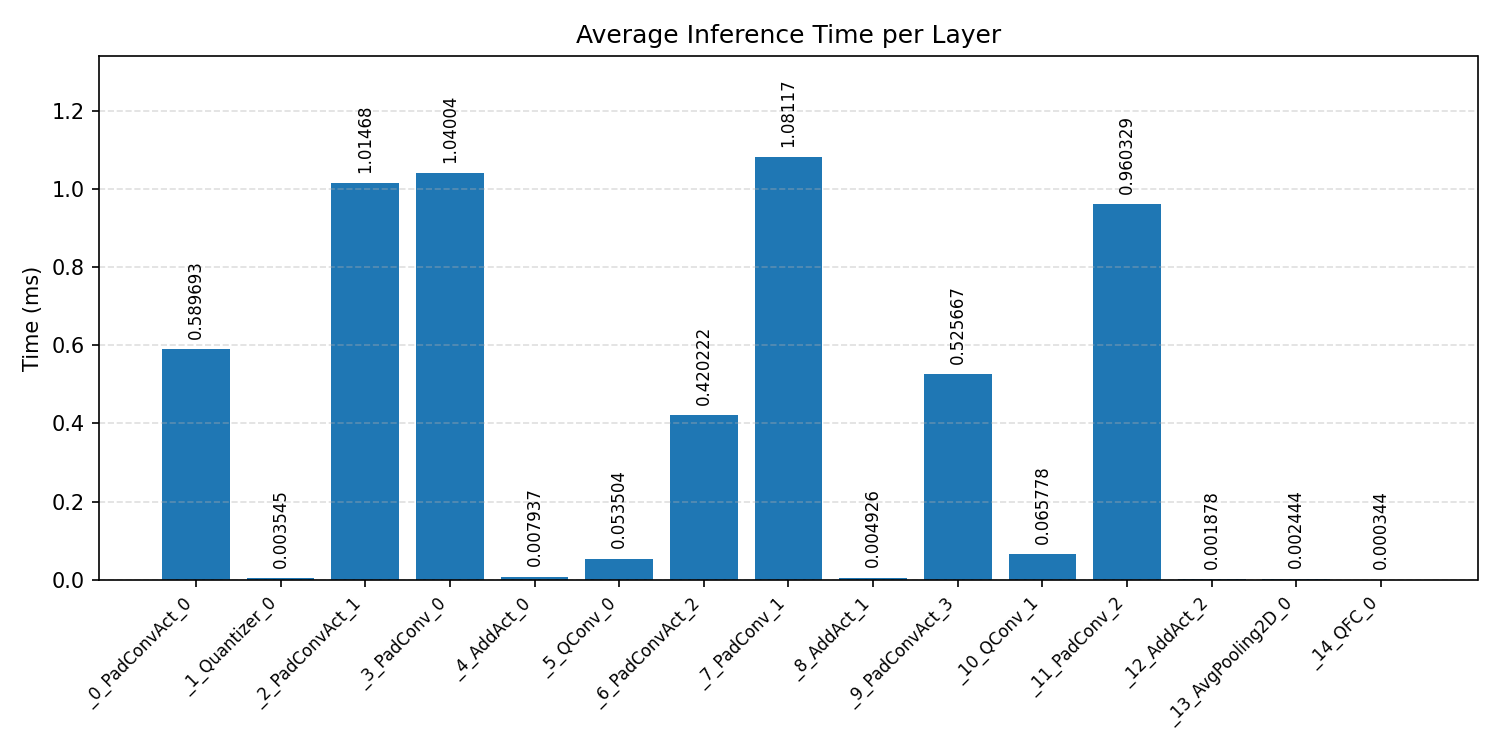
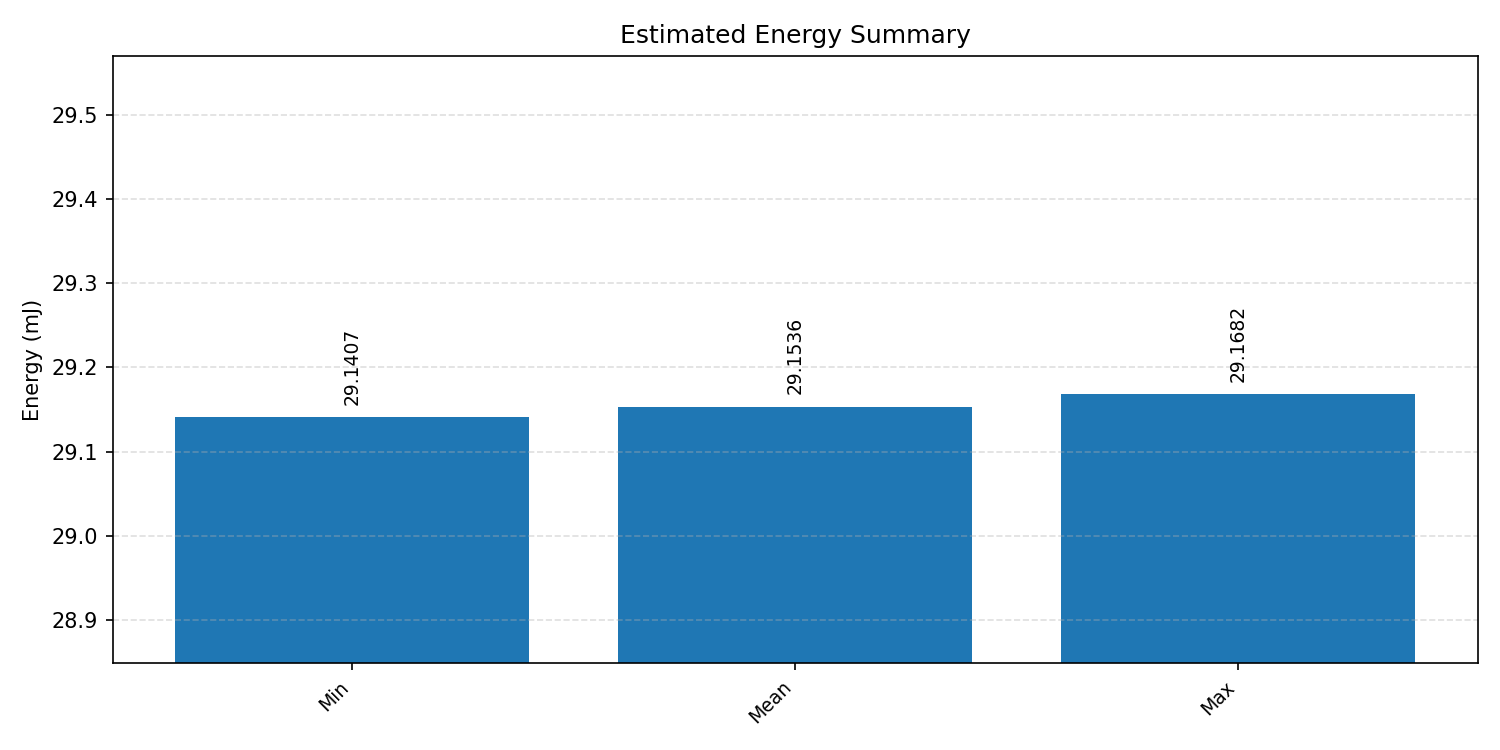
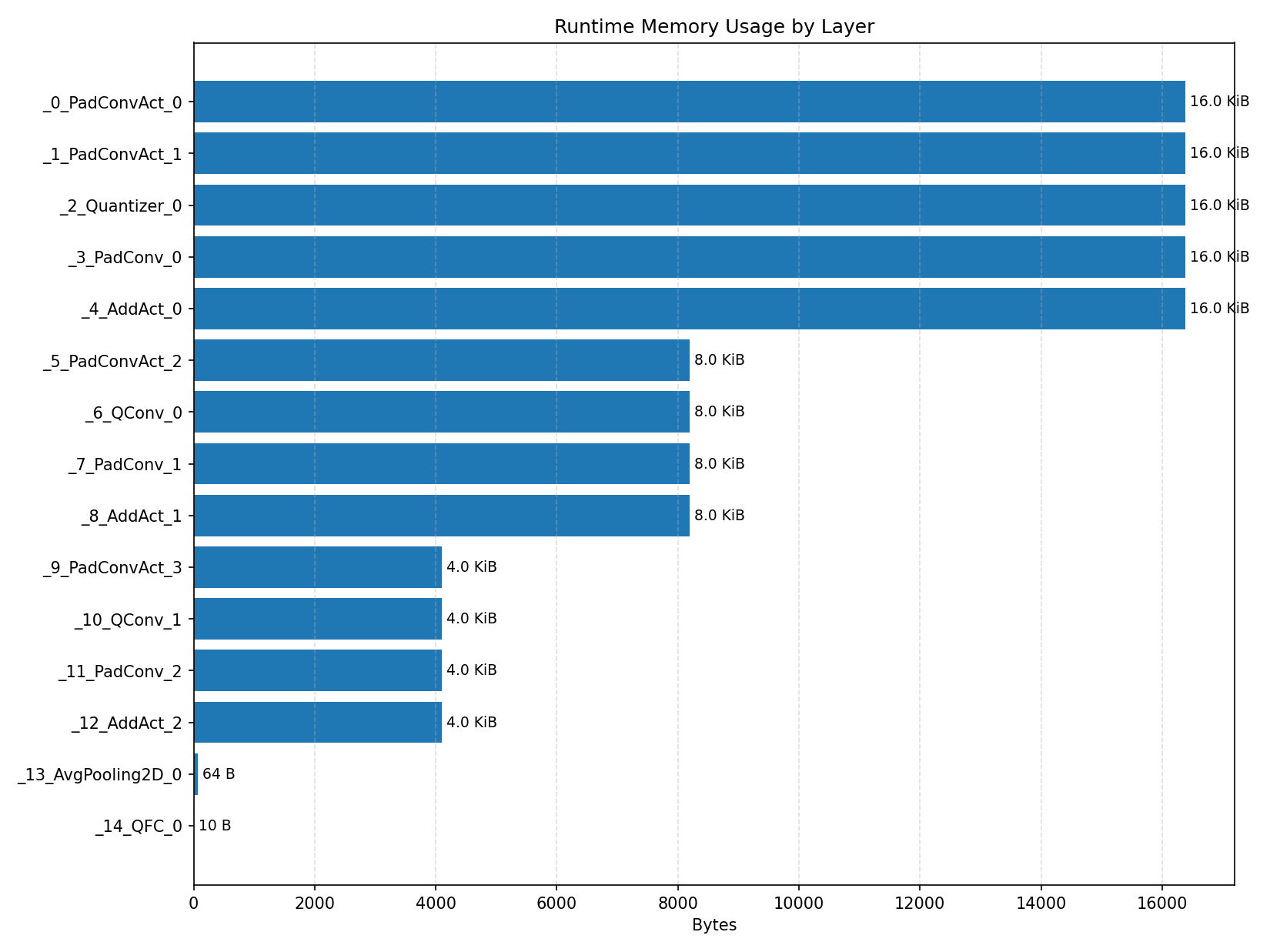
#3.4 DS-CNN#
Comparison Chart
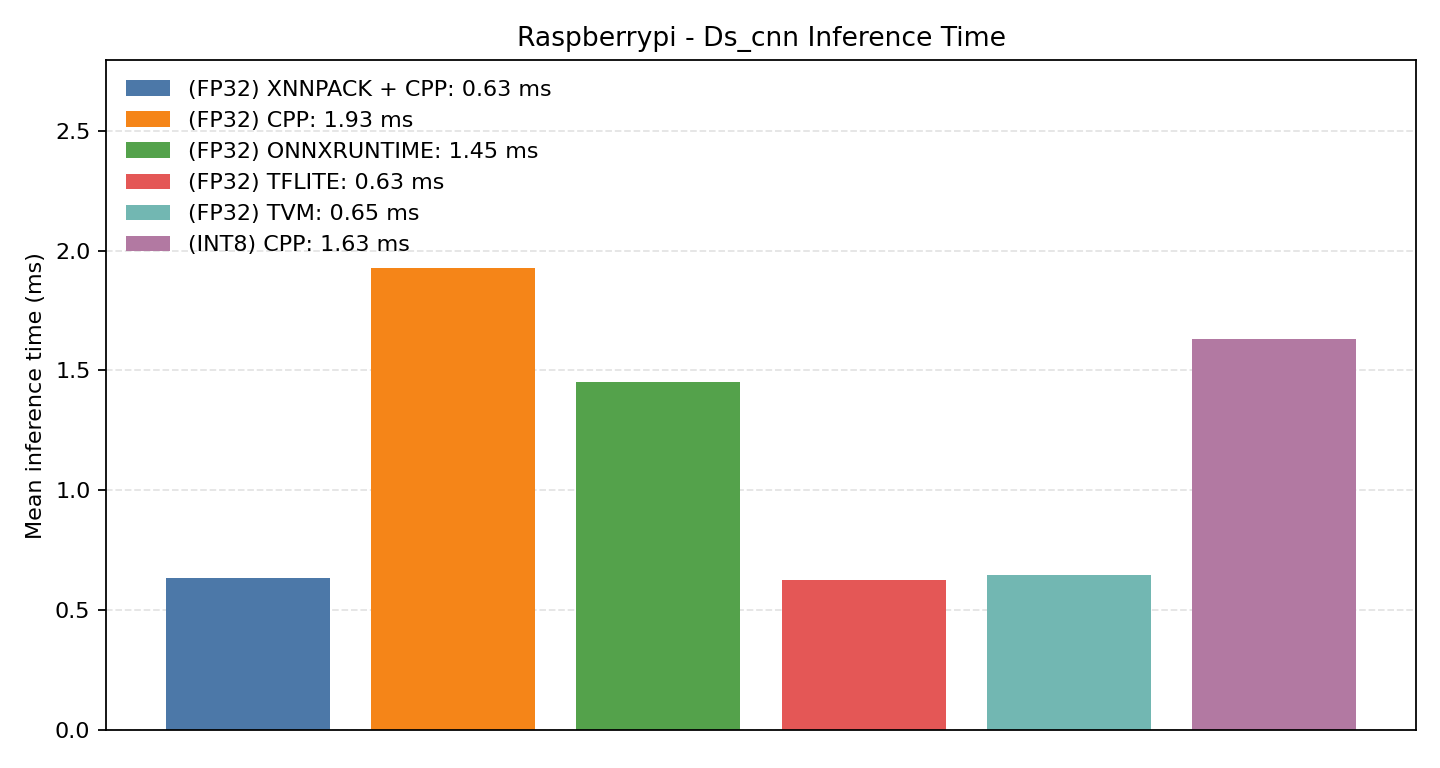
#3.4.1 (FP32) CPP#
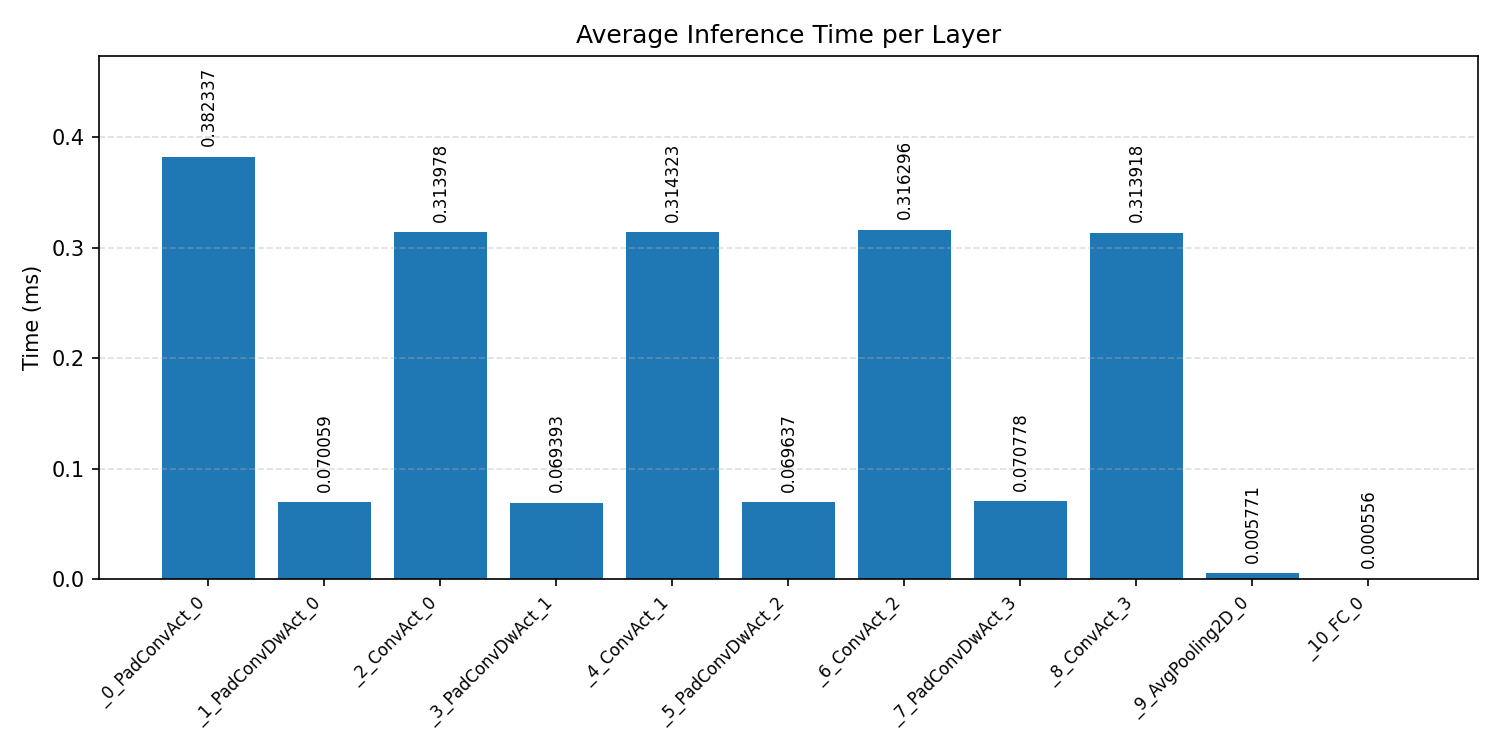
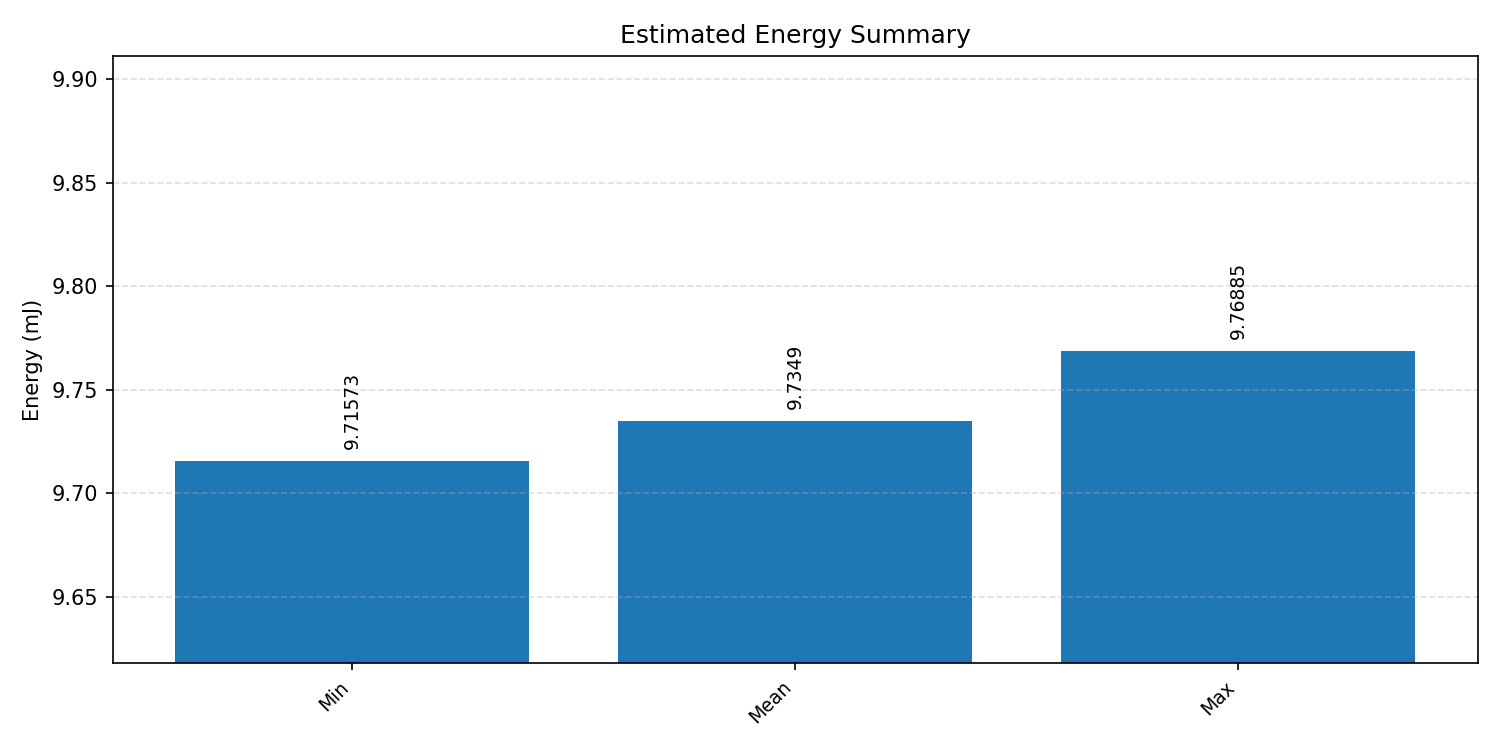
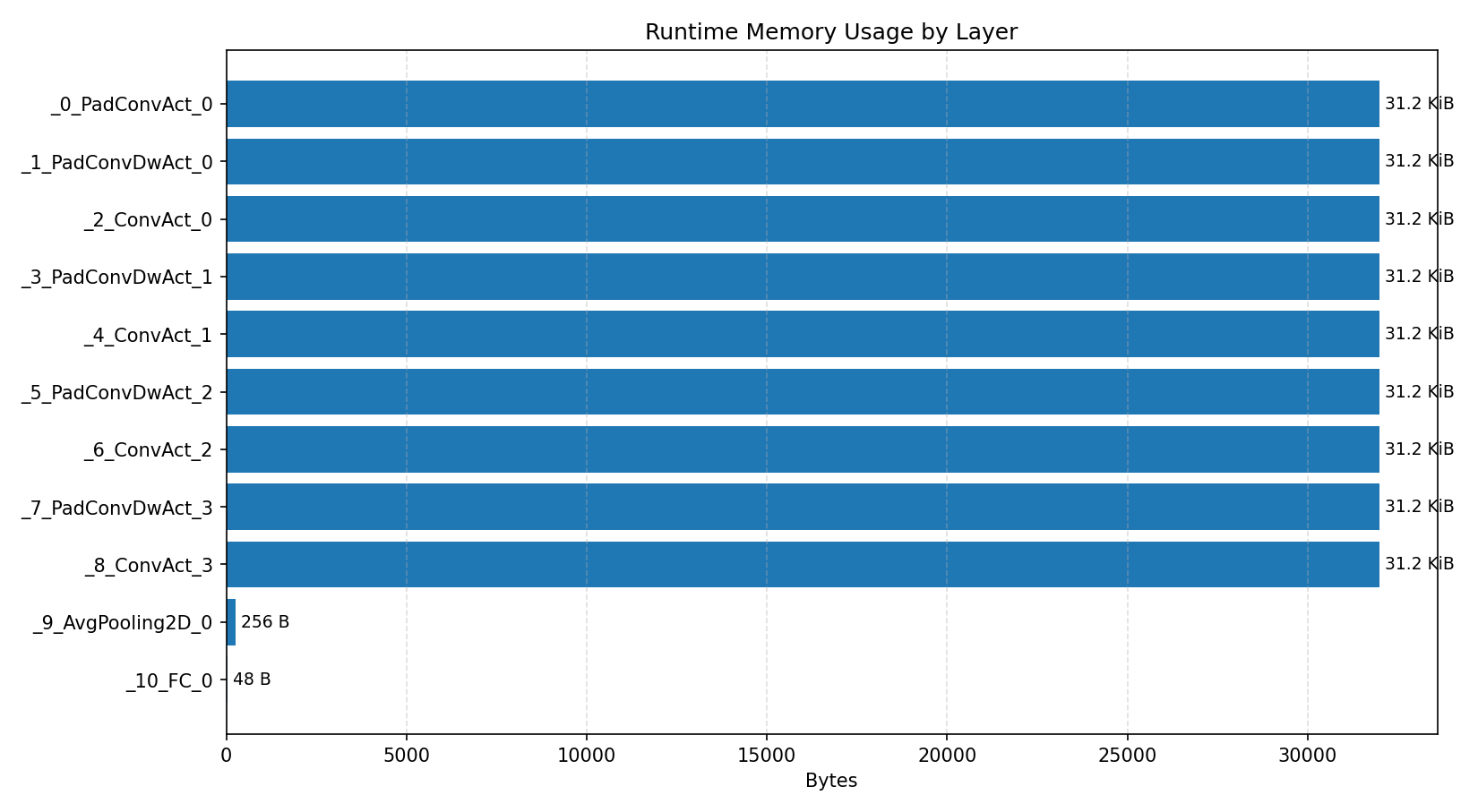
#3.4.2 (FP32) XNNPACK + CPP#
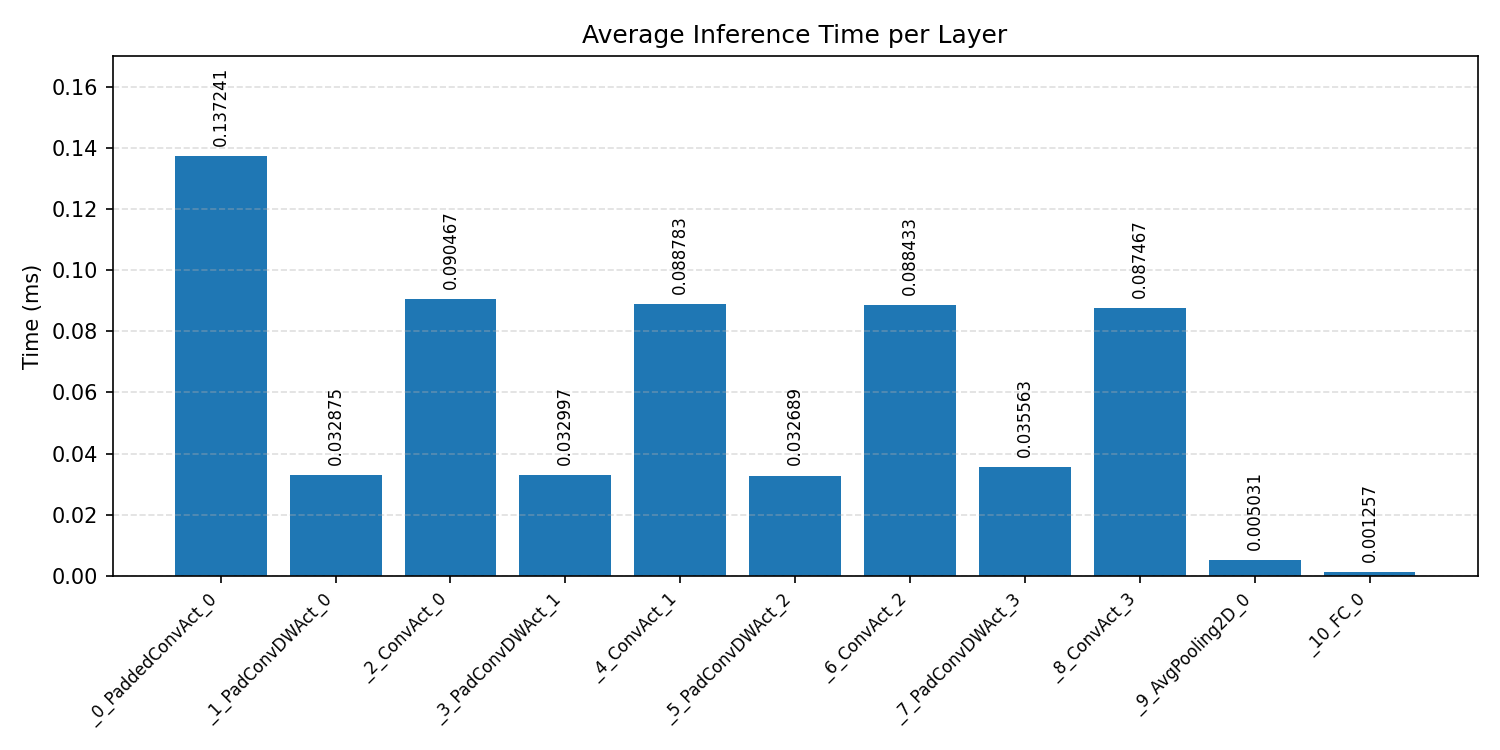
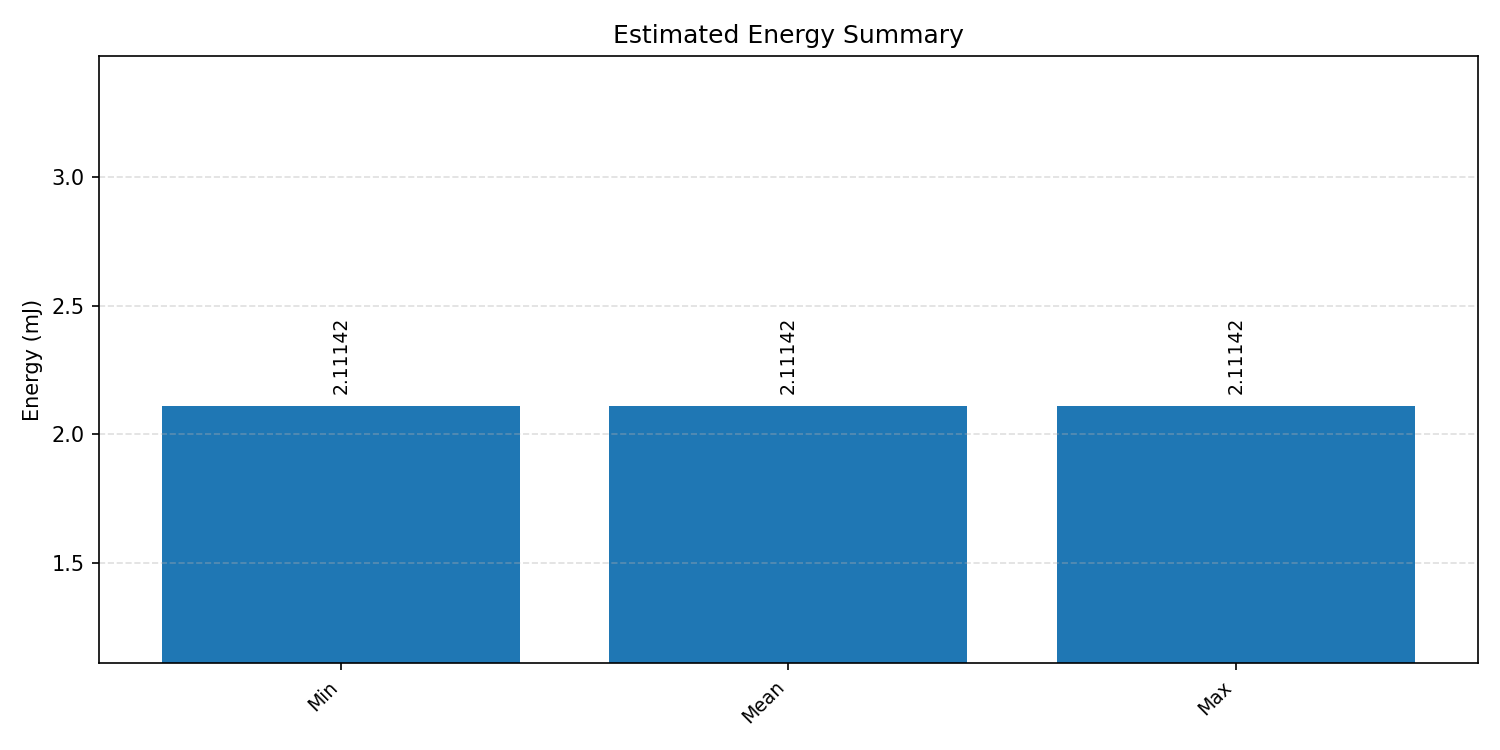
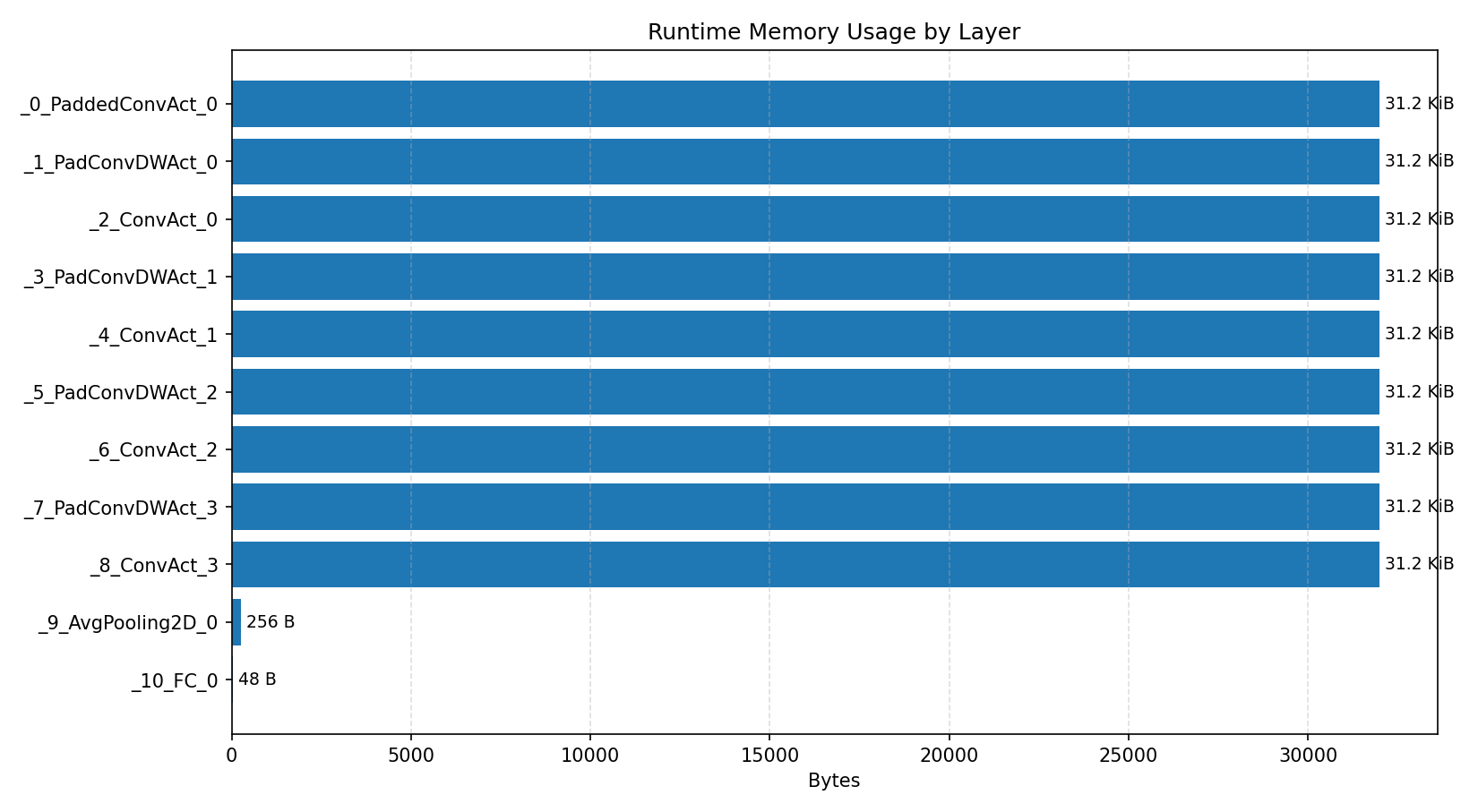
#3.4.3 (INT8) CPP#
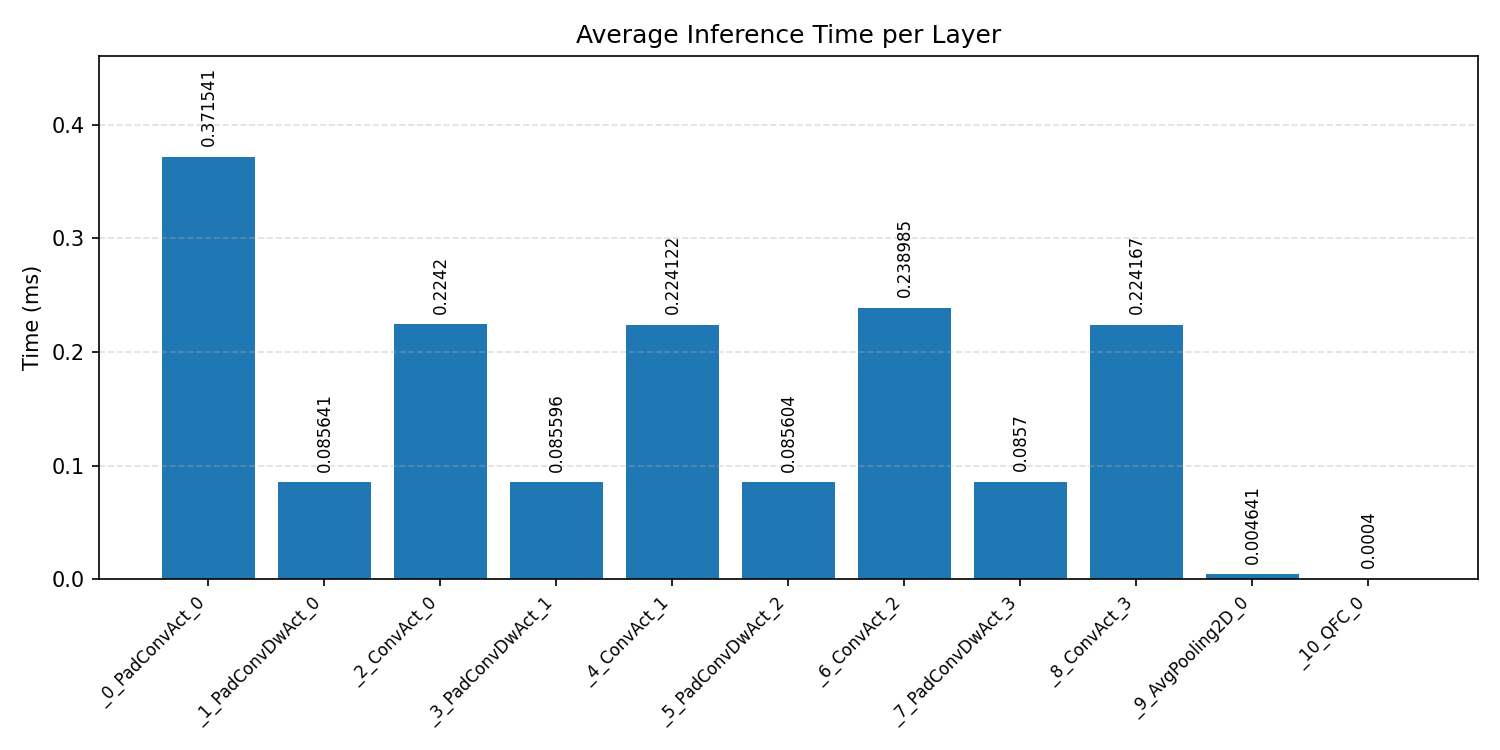
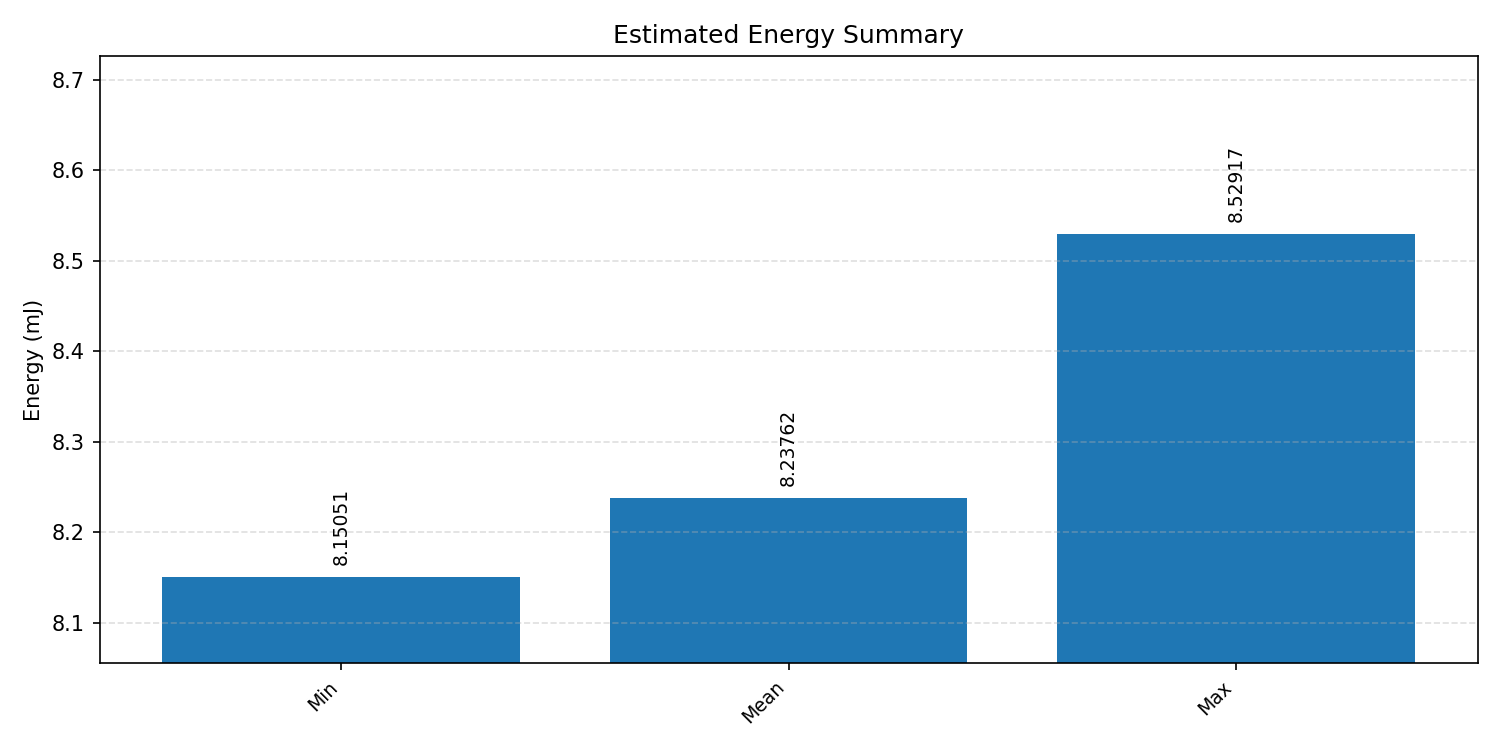
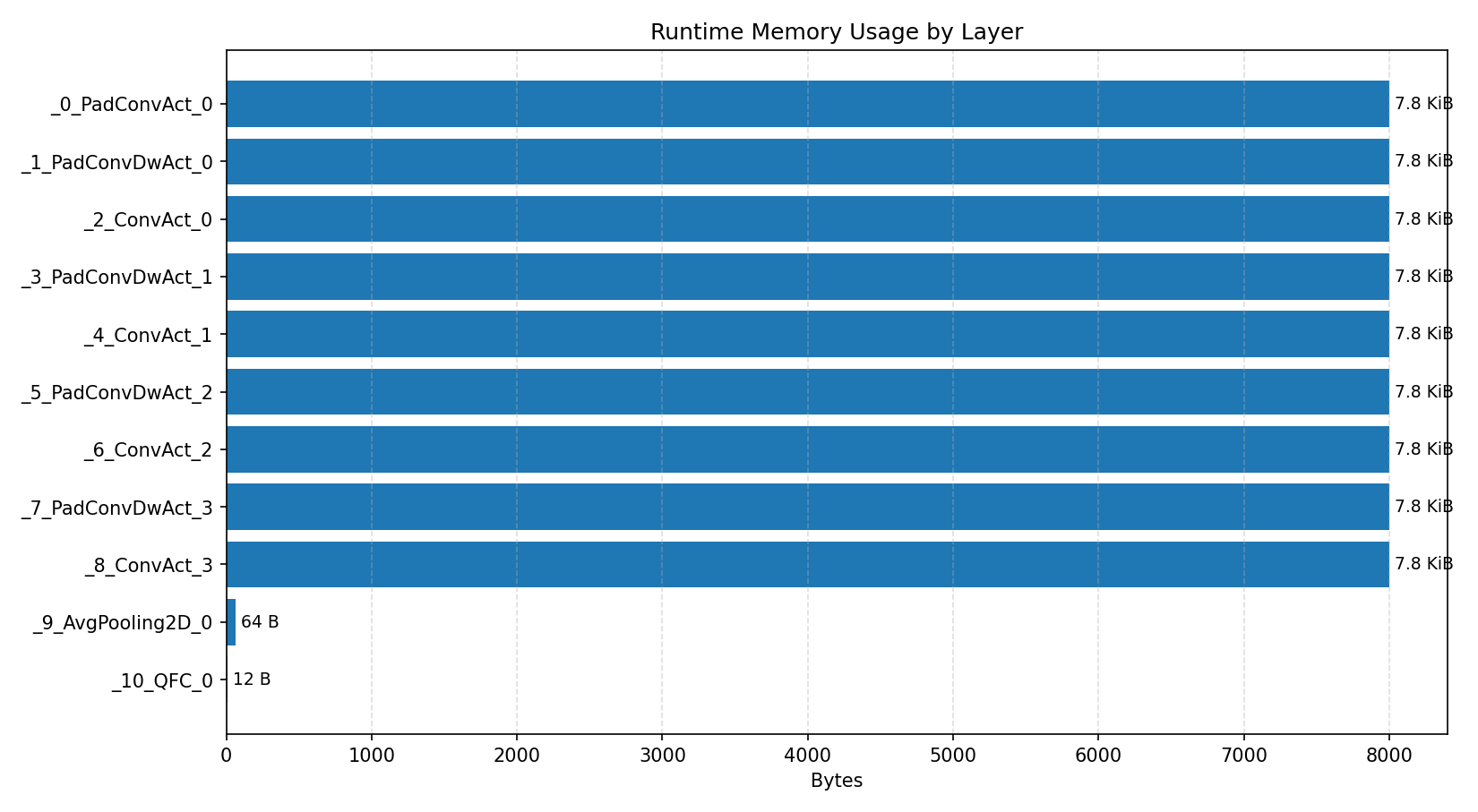
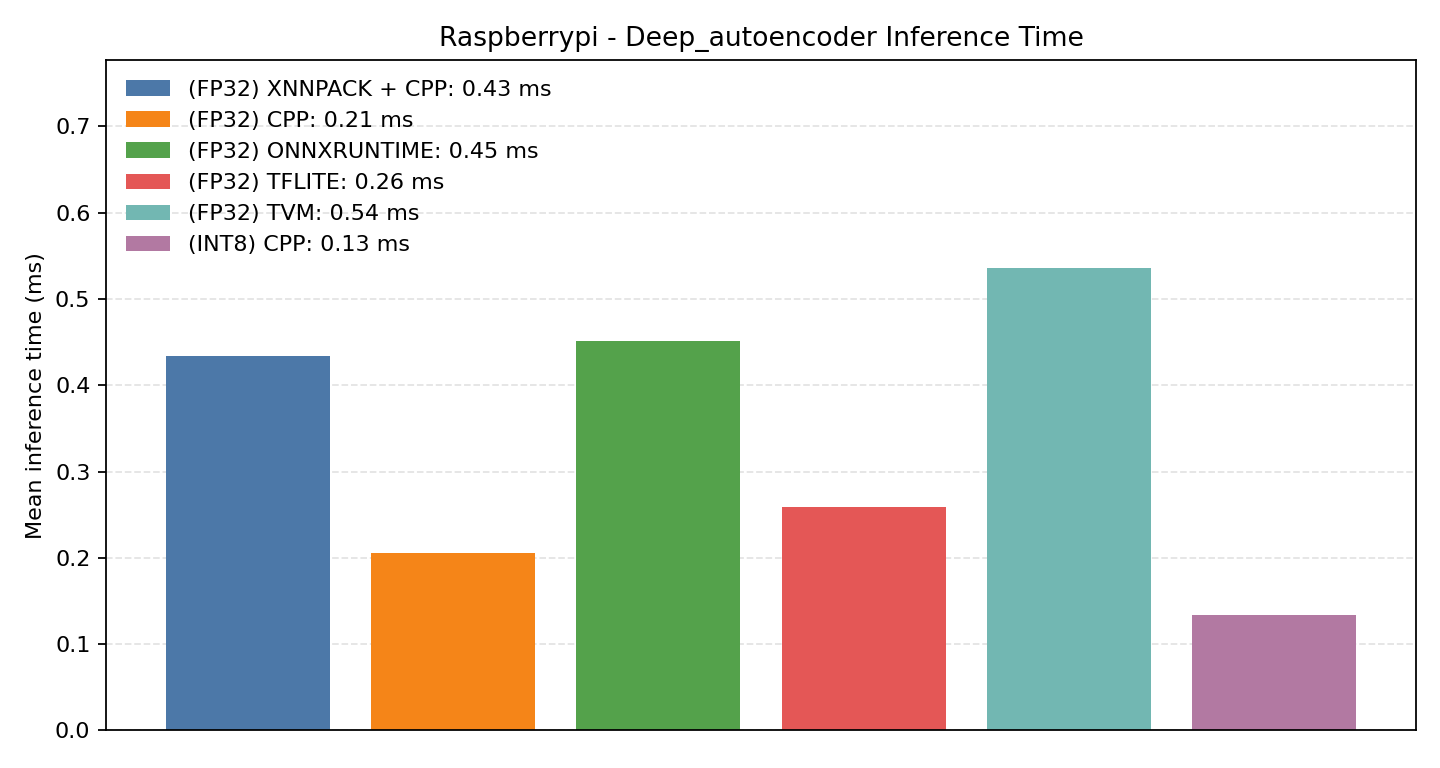
#3.5 Deep autoencoder#
Comparison Chart
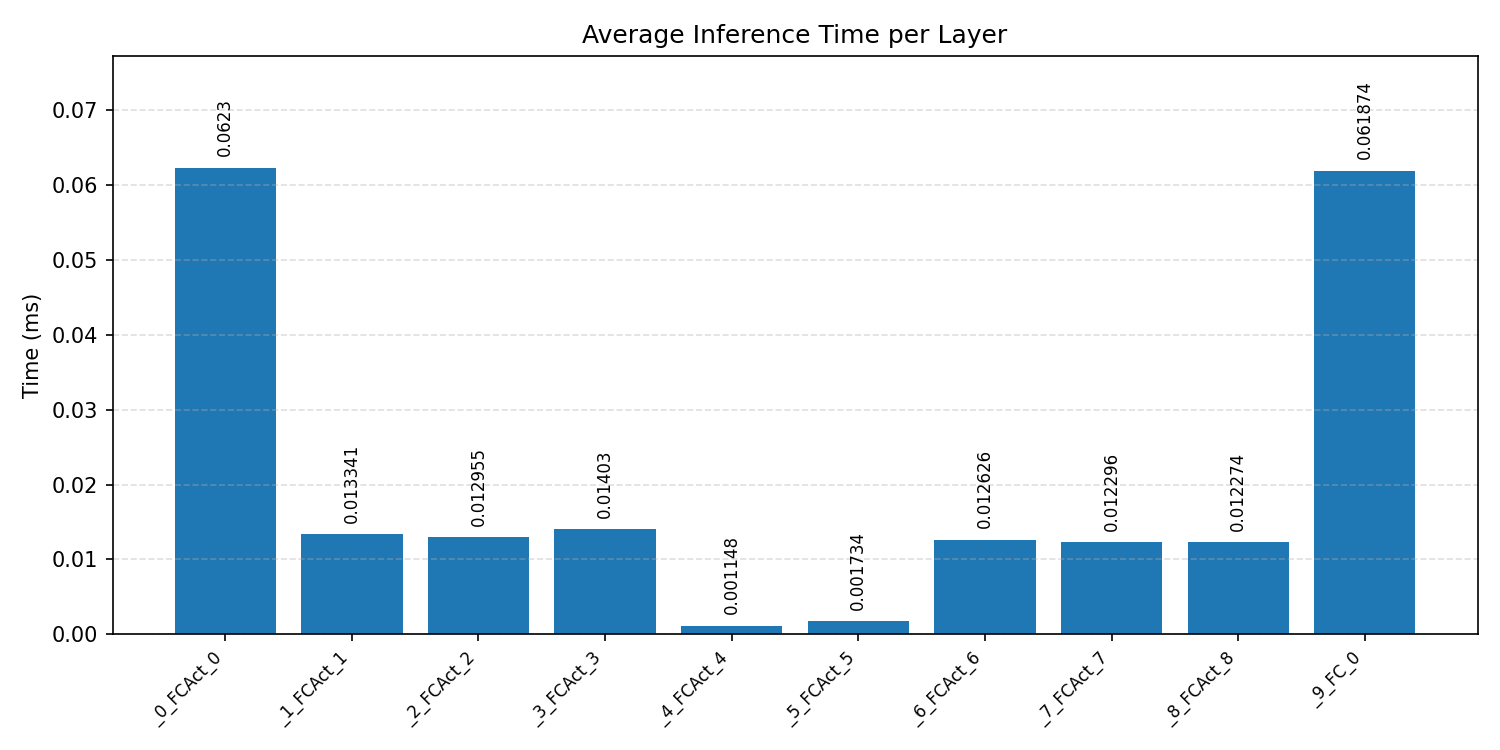
#3.5.1 (FP32) CPP#
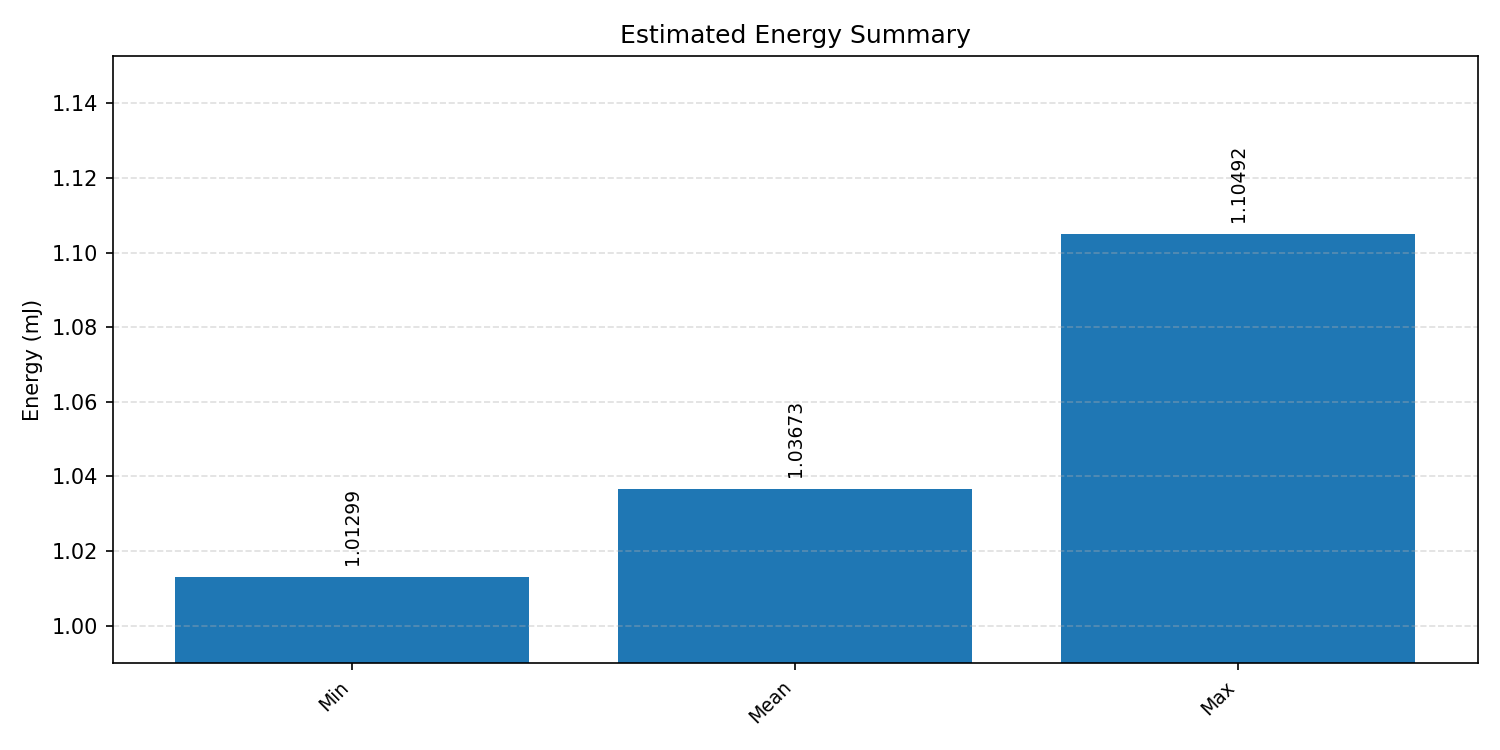
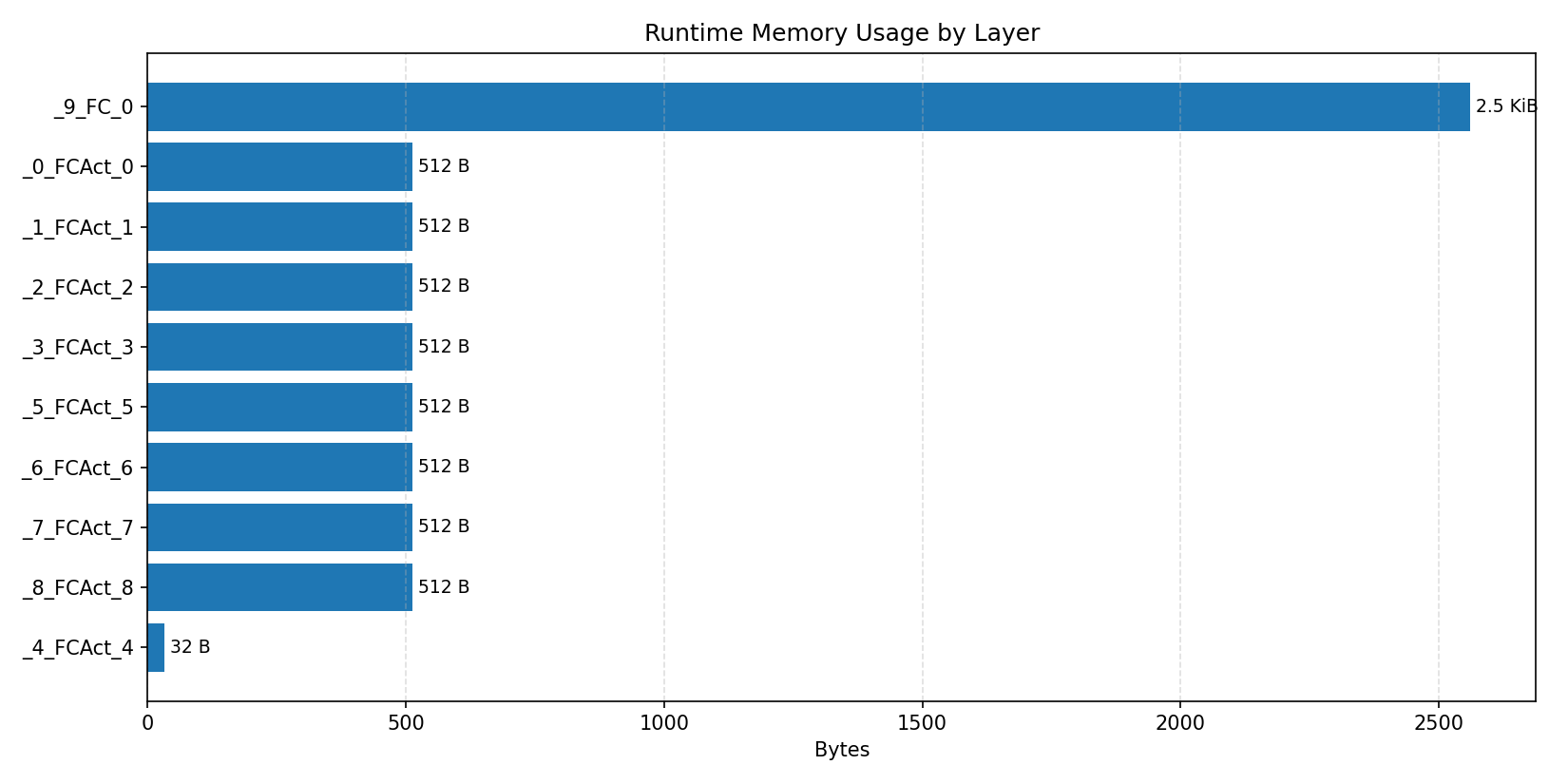
#3.5.2 (FP32) XNNPACK + CPP#
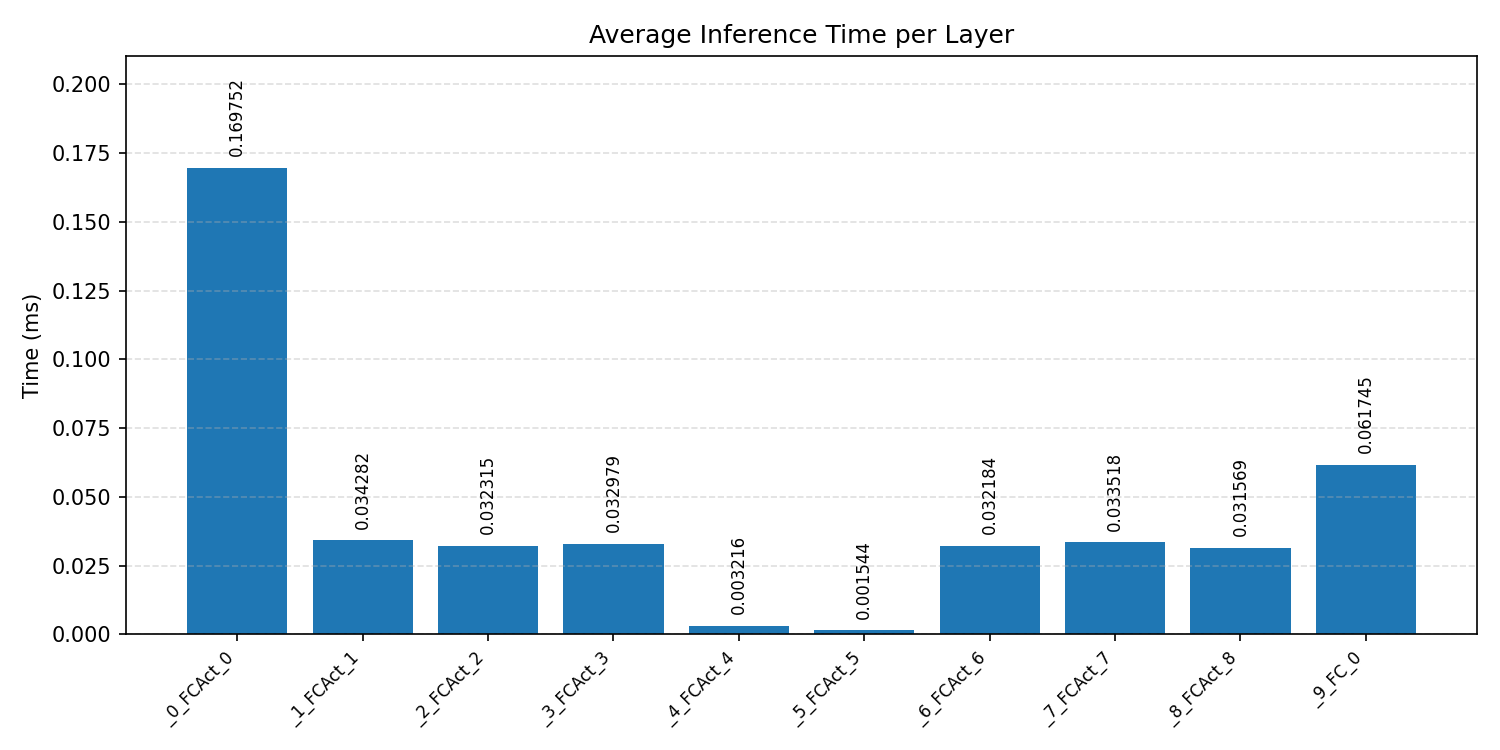
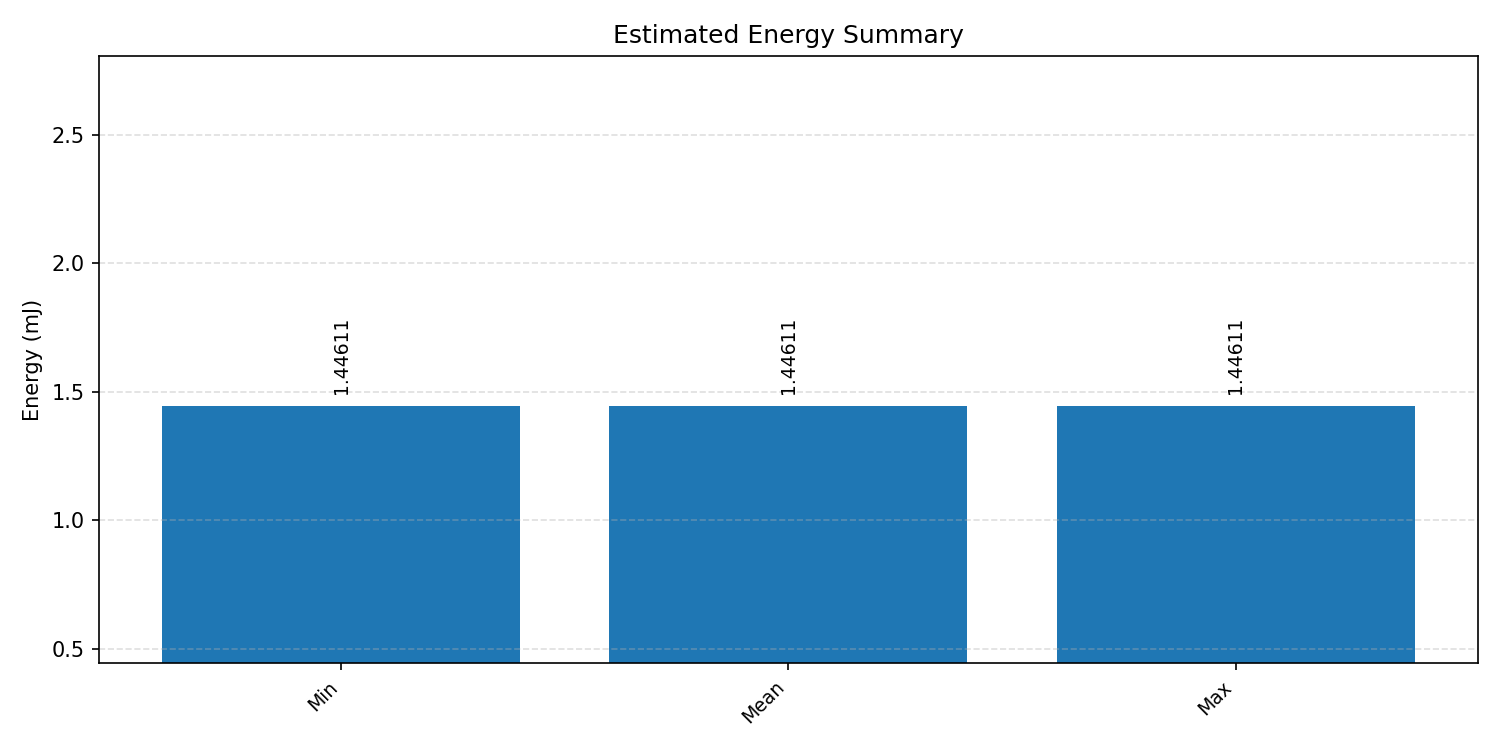
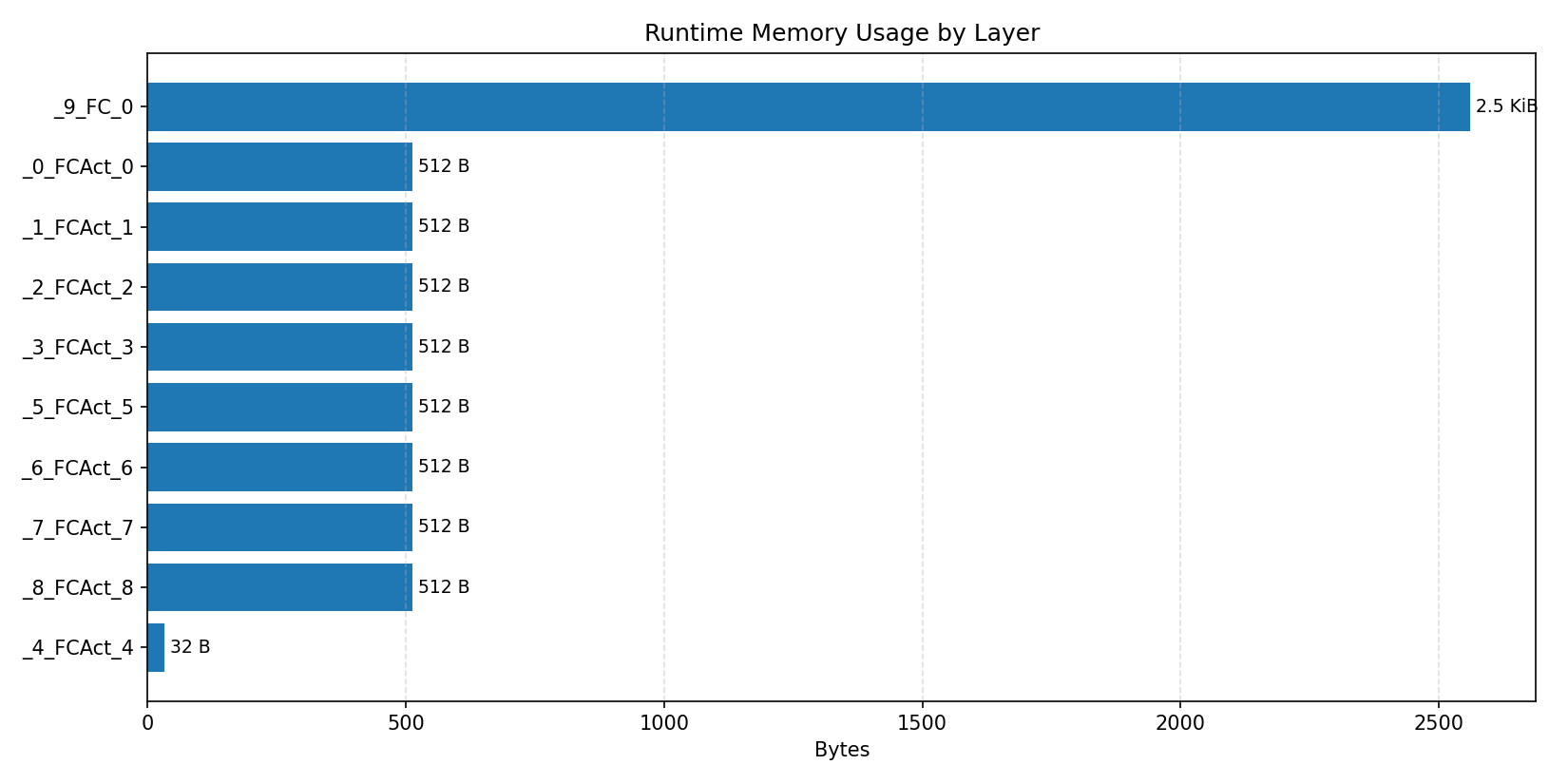
#3.5.3 (INT8) CPP#
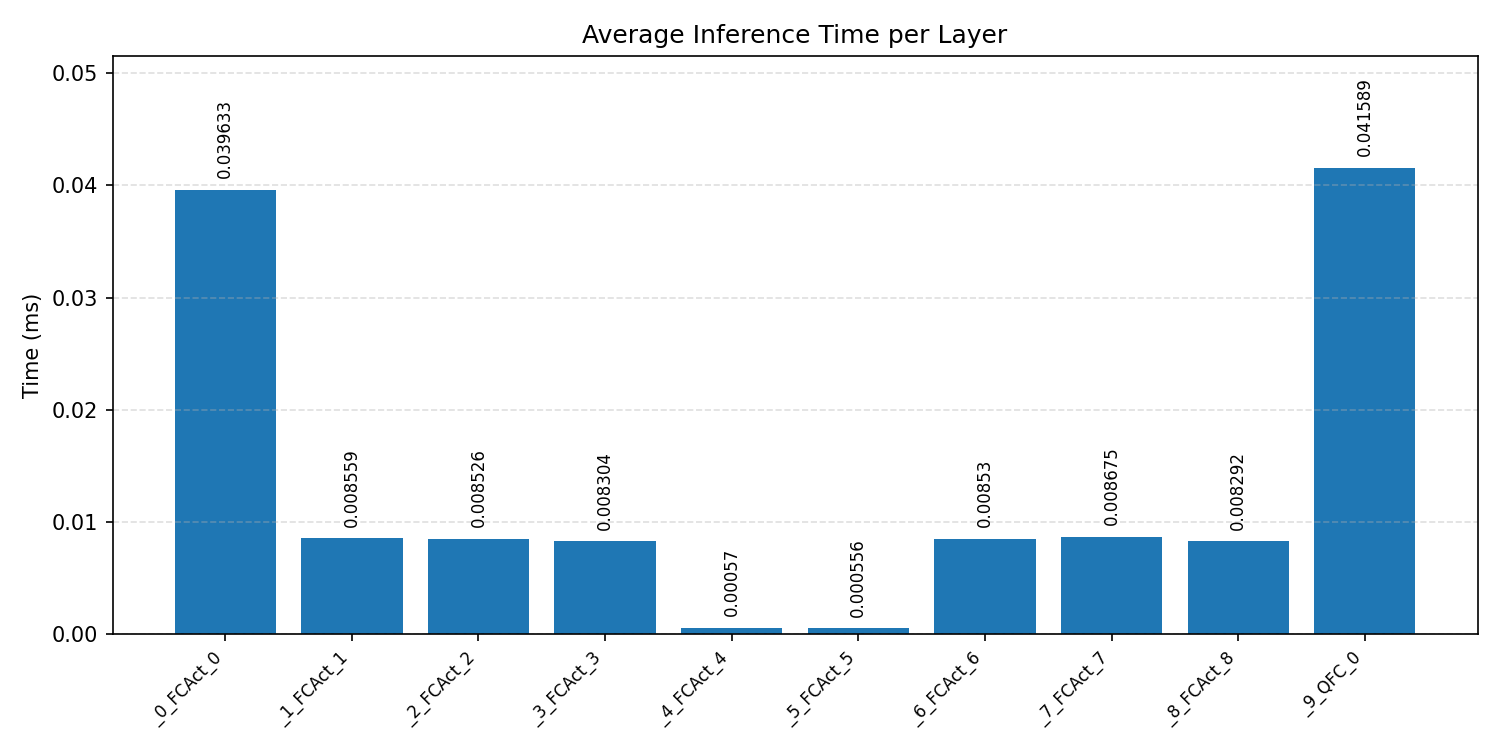
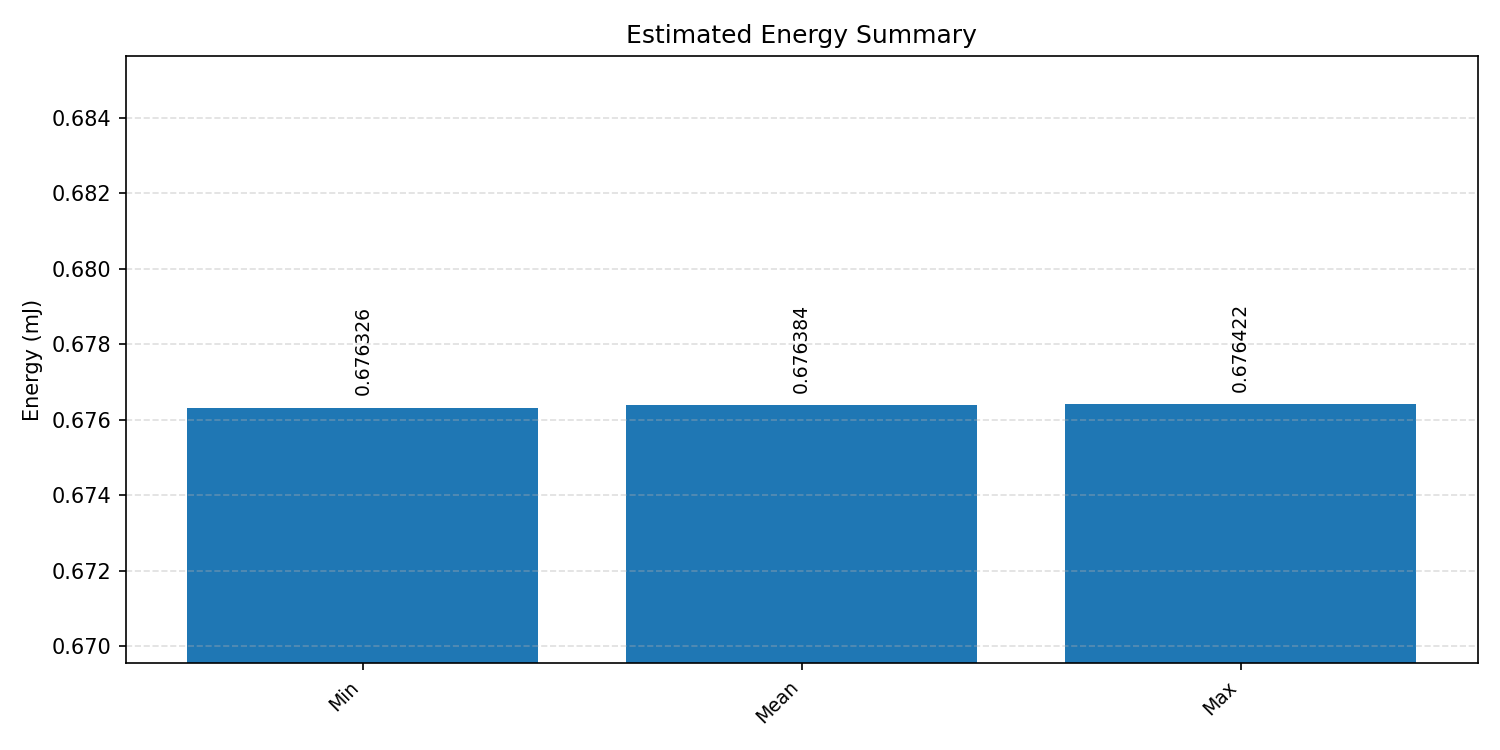
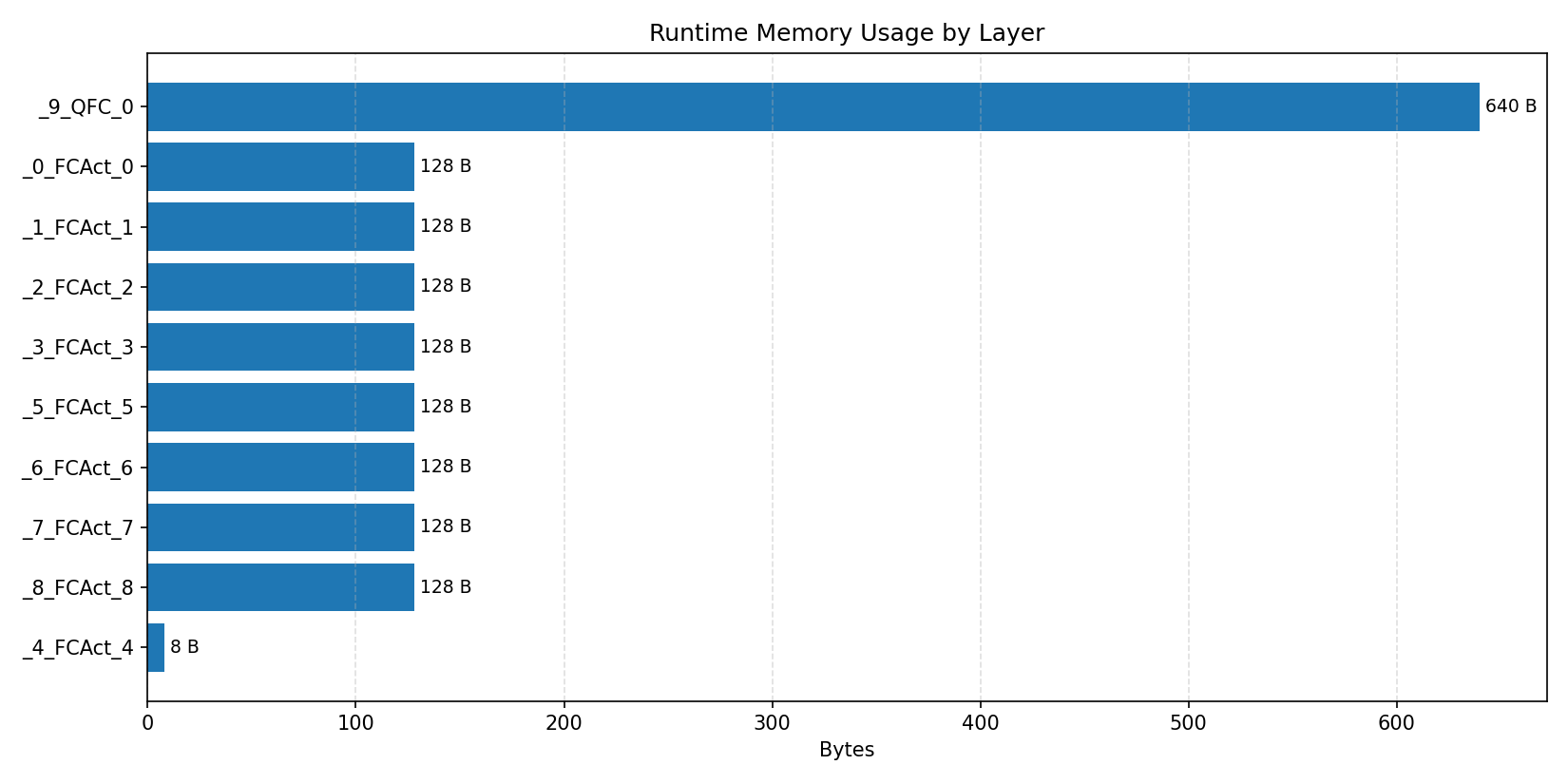
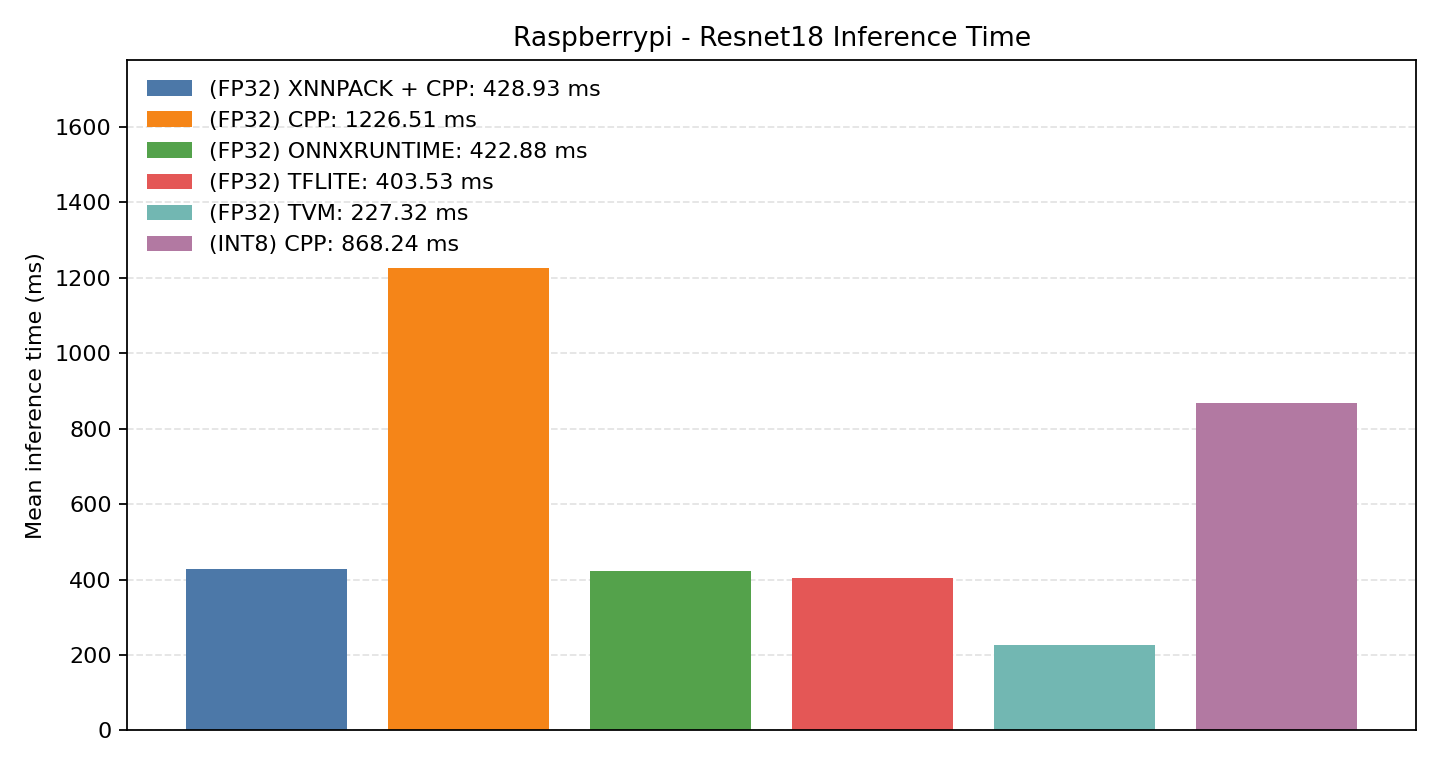
#3.6 ResNet18#
Comparison Chart
#3.6.1 (FP32) CPP#
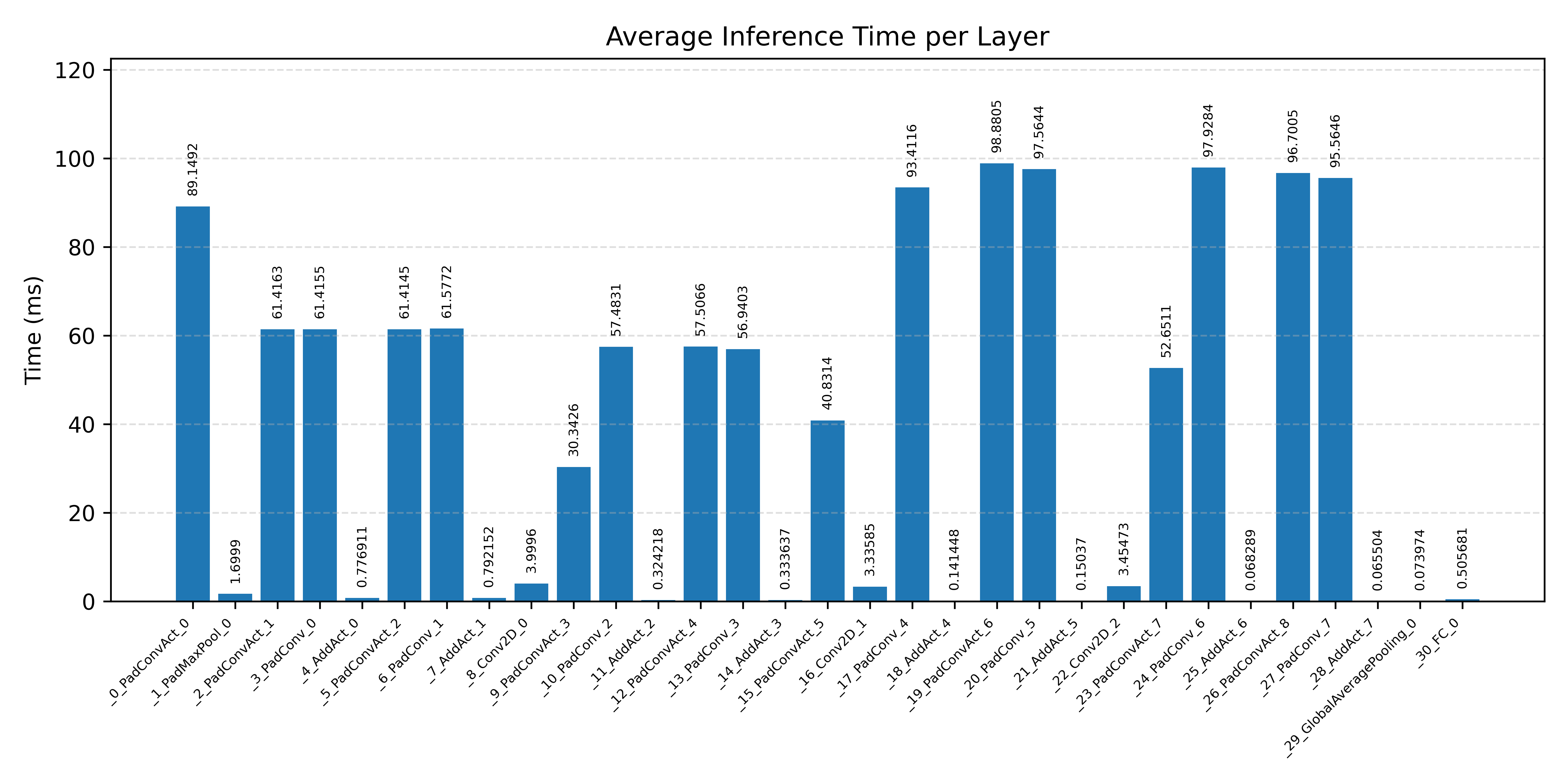
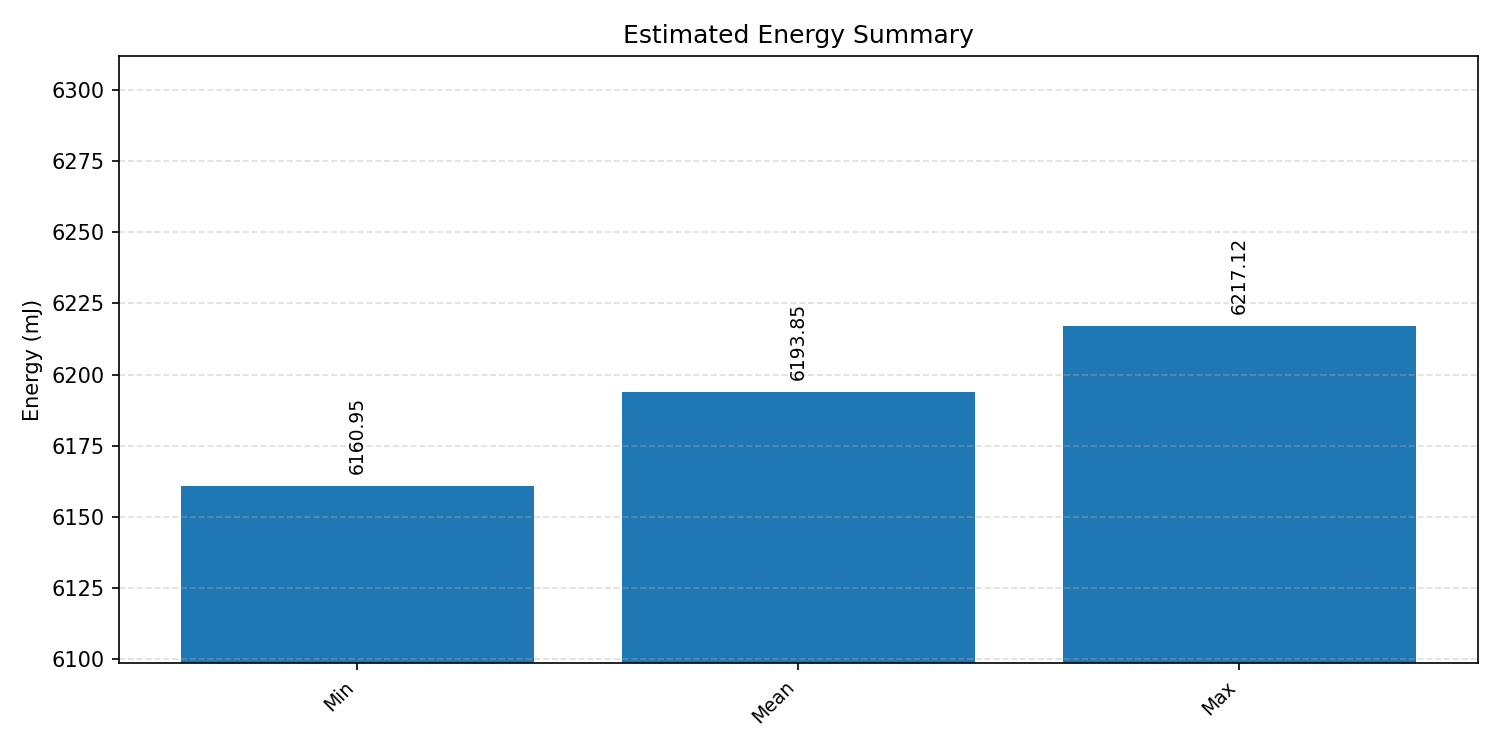
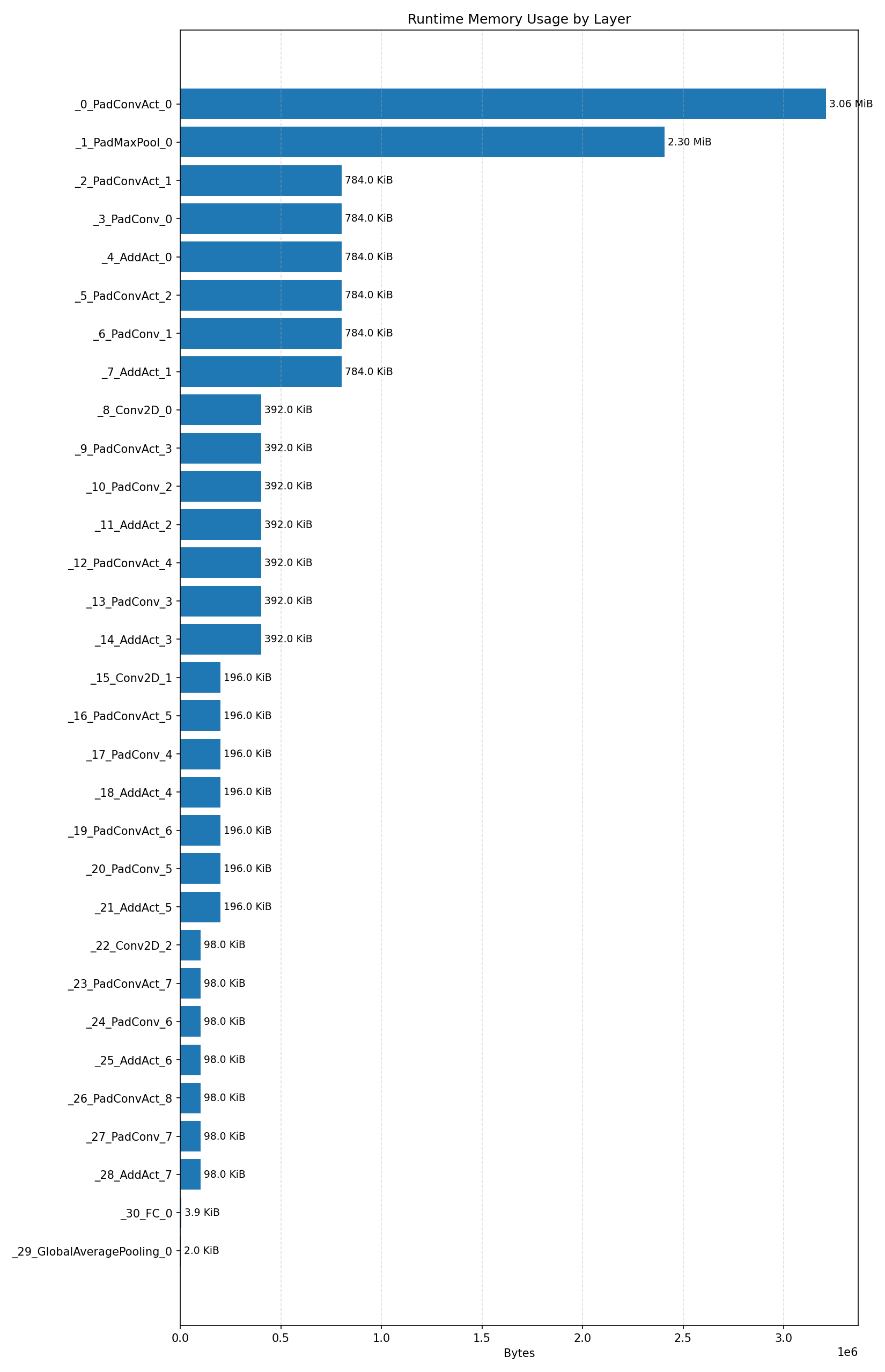
#3.6.2 (FP32) XNNPACK + CPP#
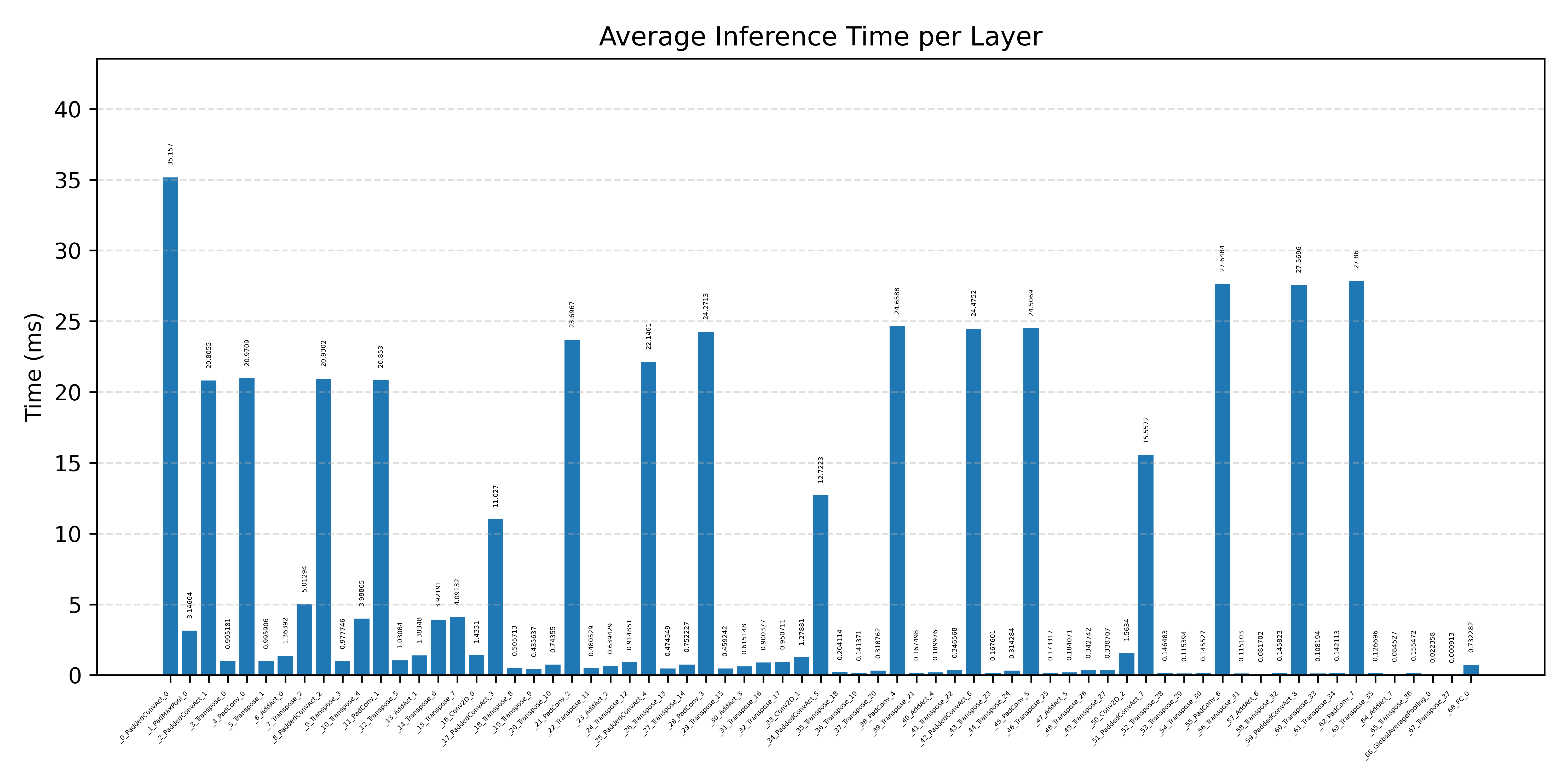
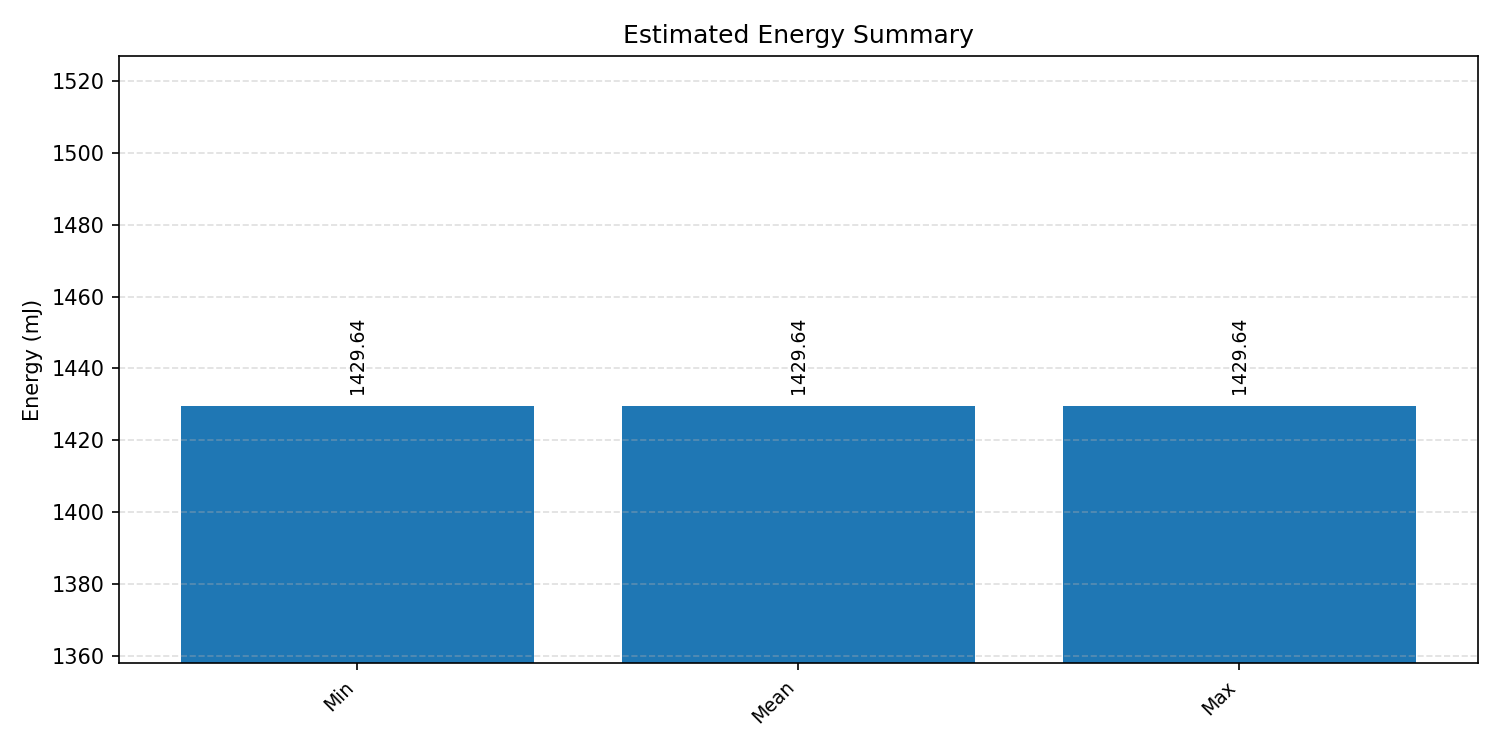
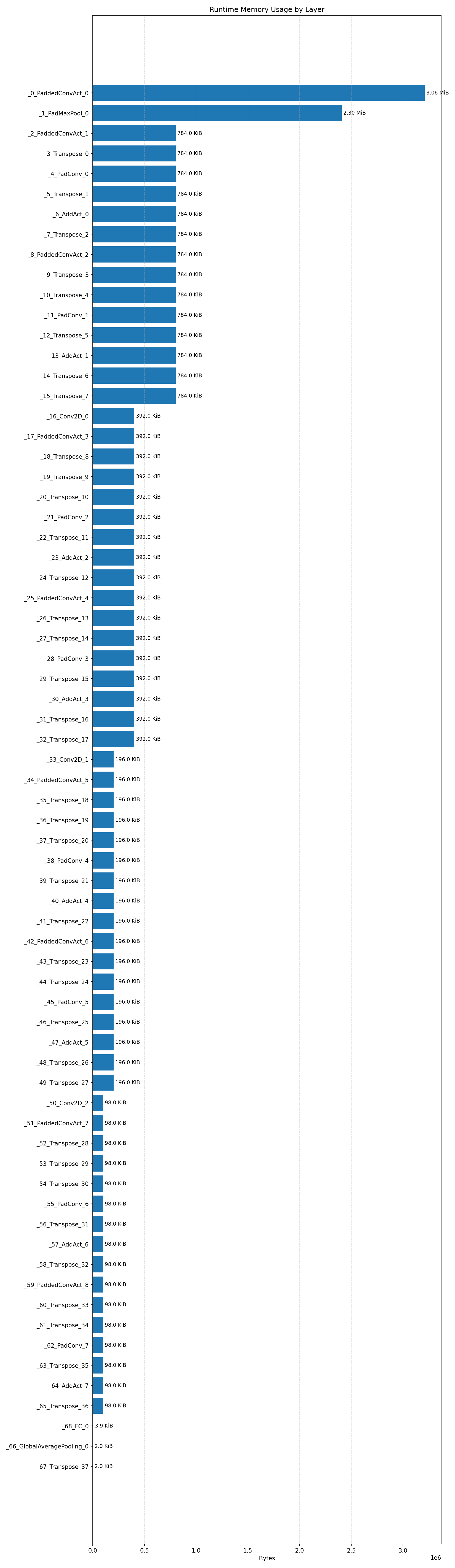
#3.6.3 (INT8) CPP#
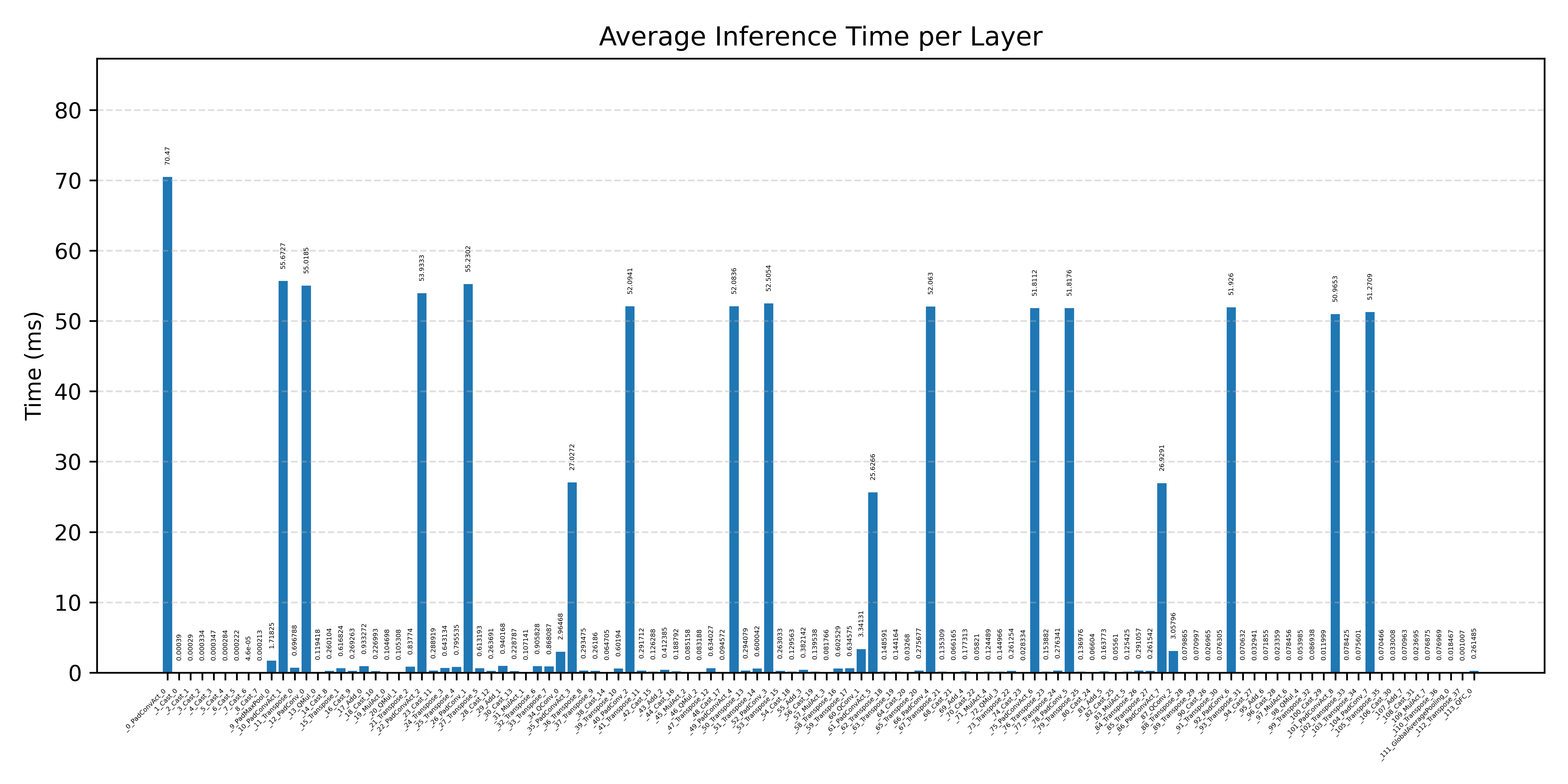
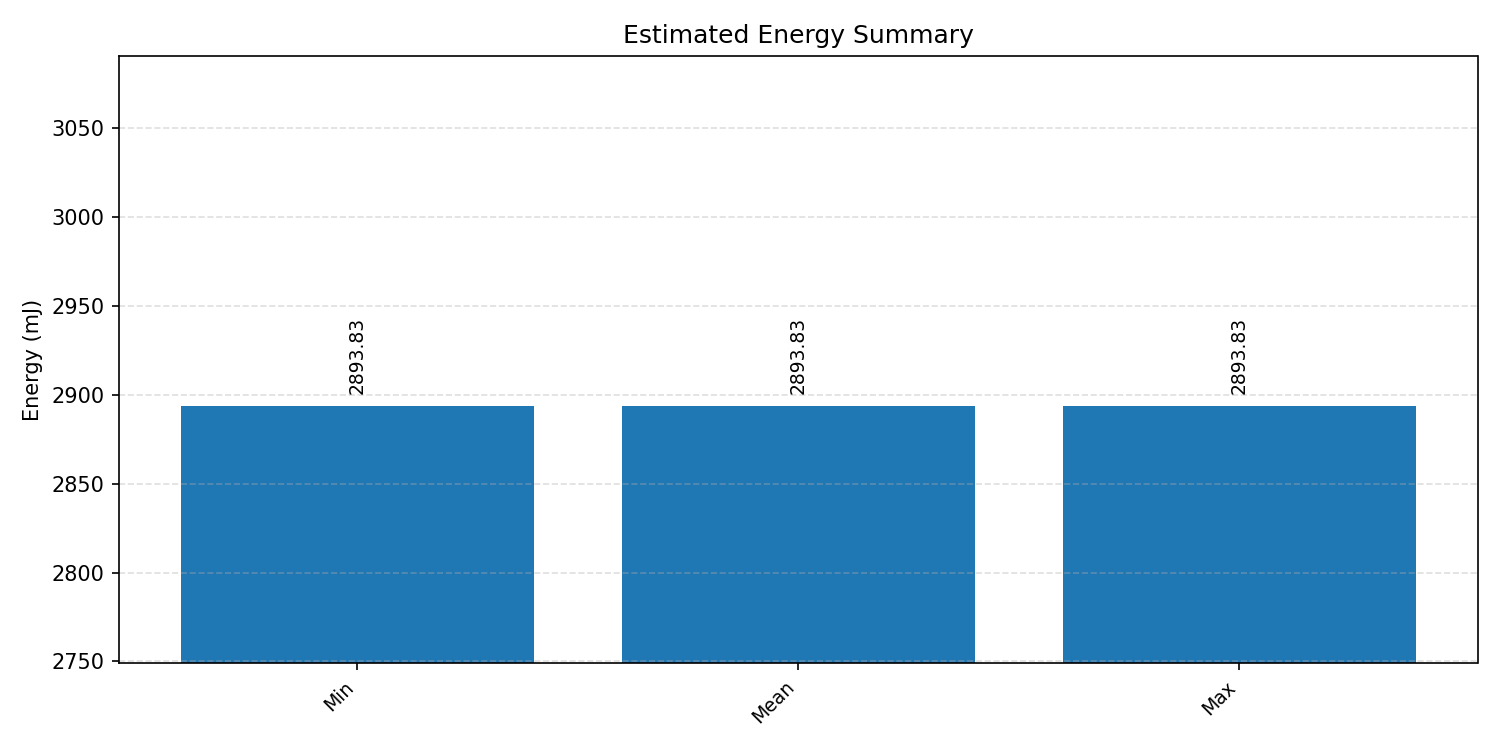

#3.7 ResNet50#
Comparison Chart
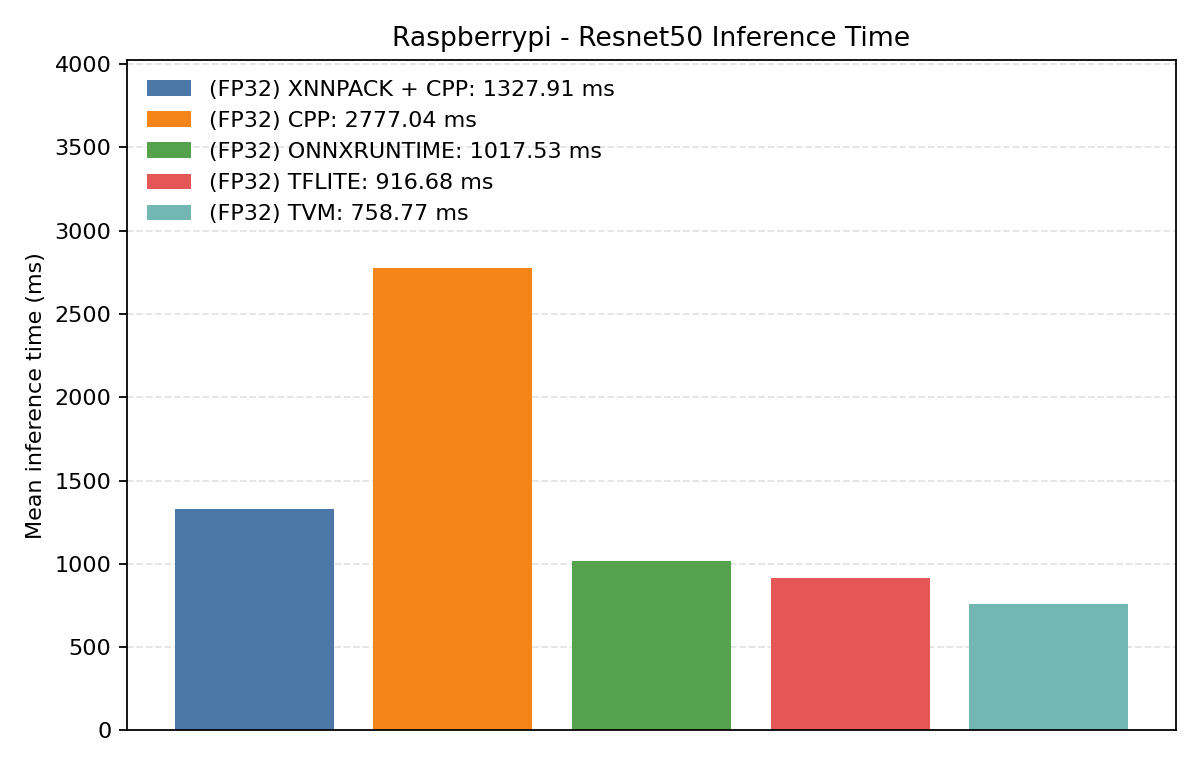
#3.7.1 (FP32) CPP#
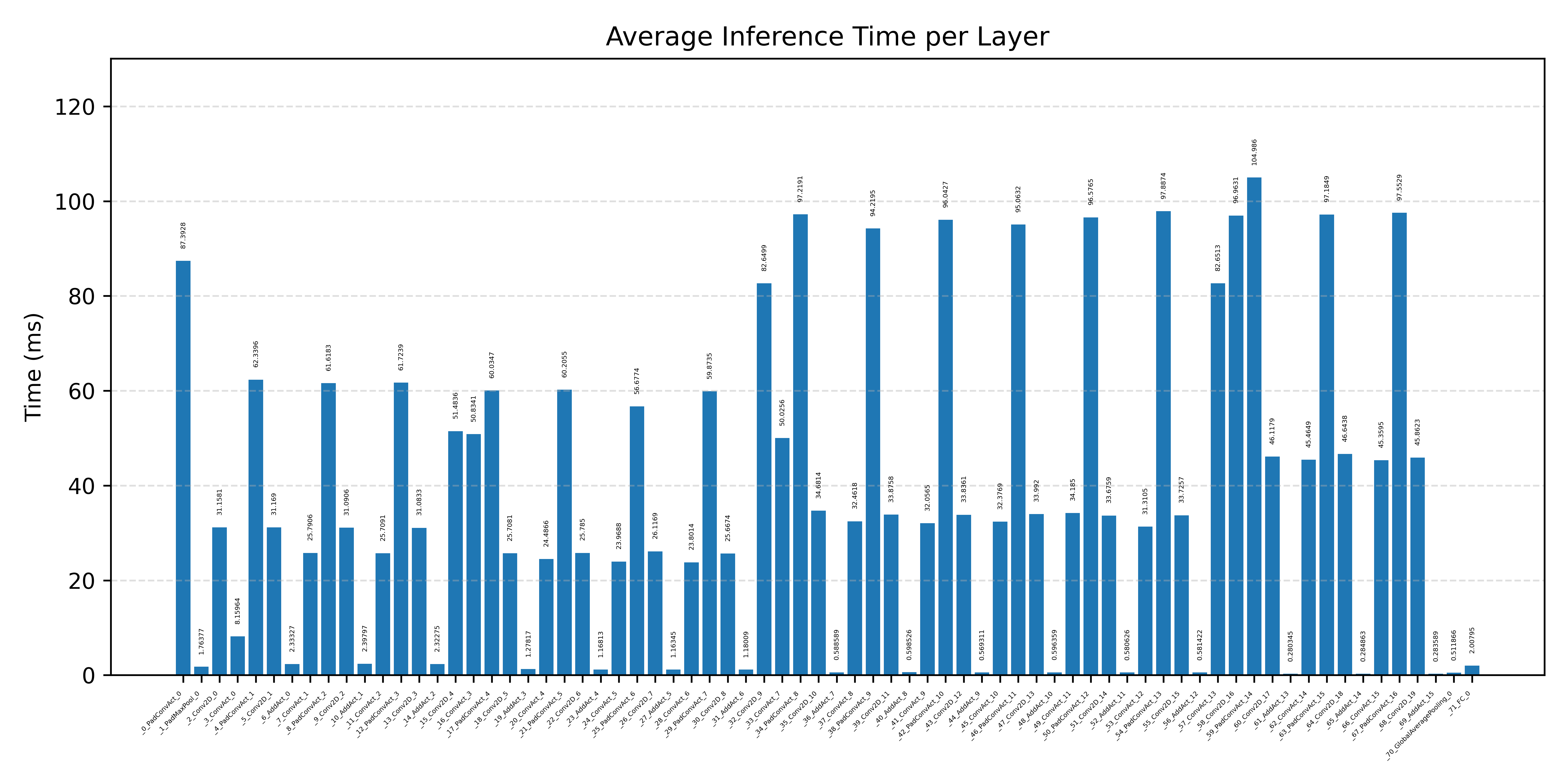
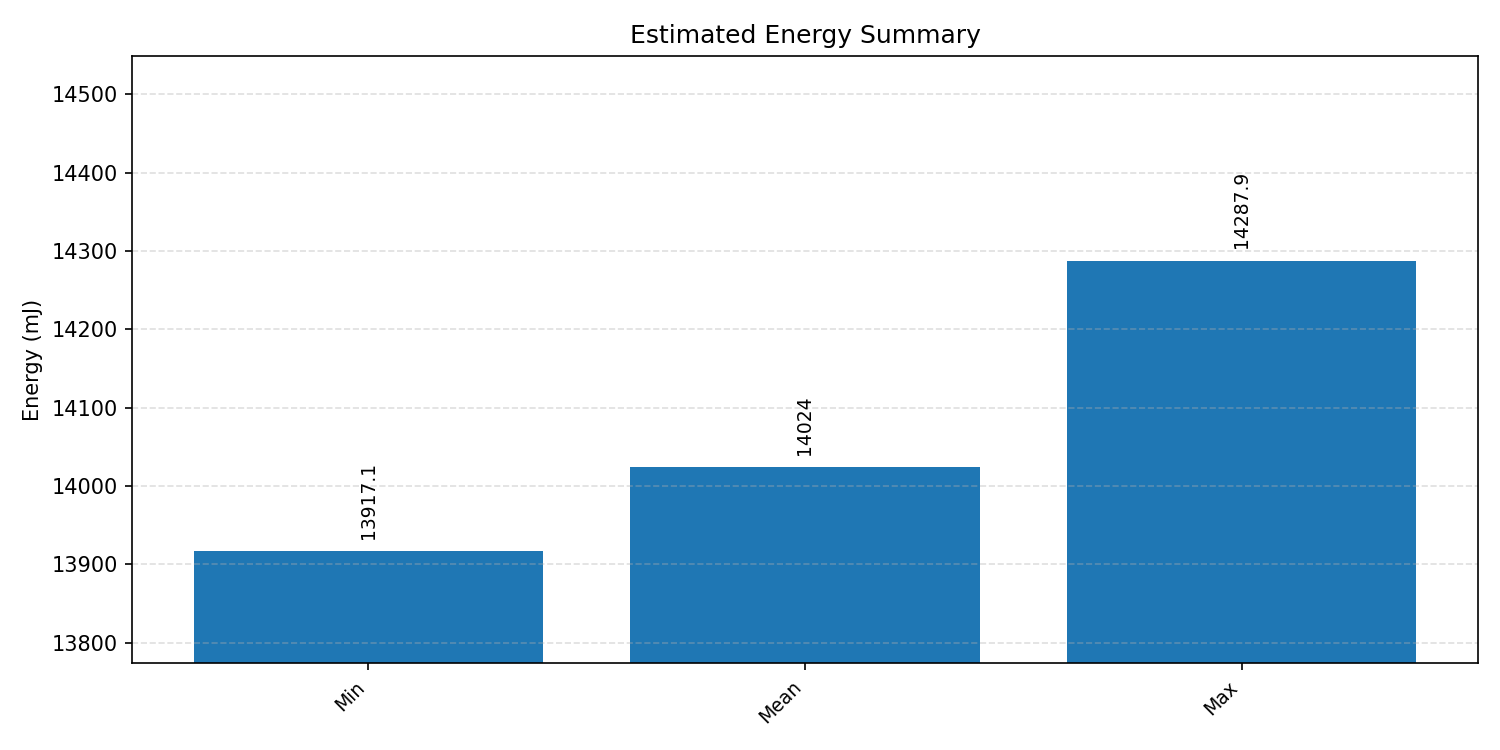
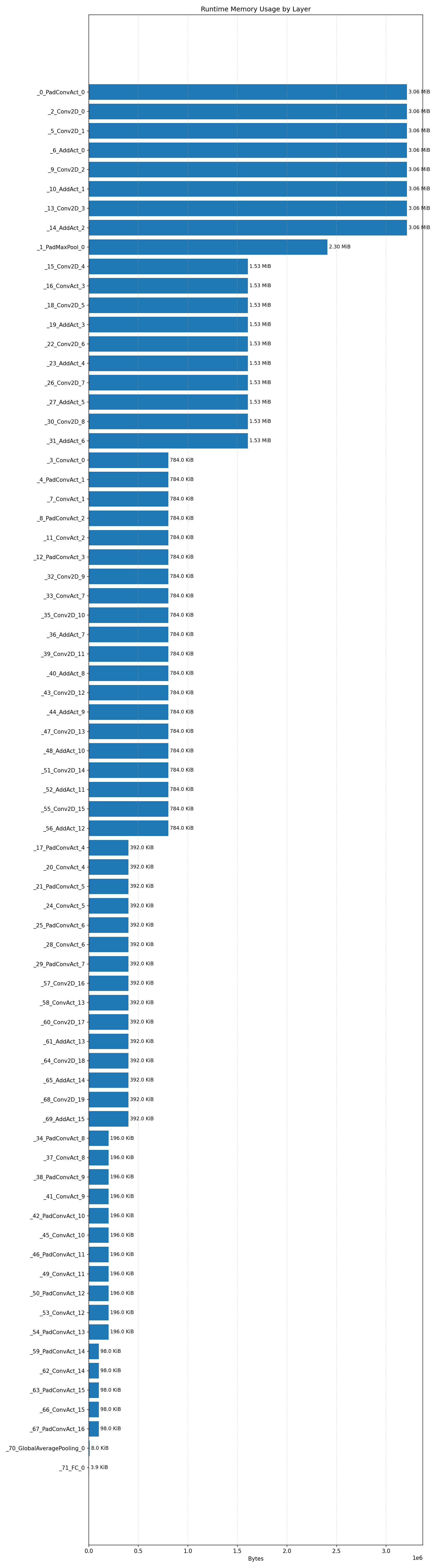
#3.7.2 (FP32) XNNPACK + CPP#
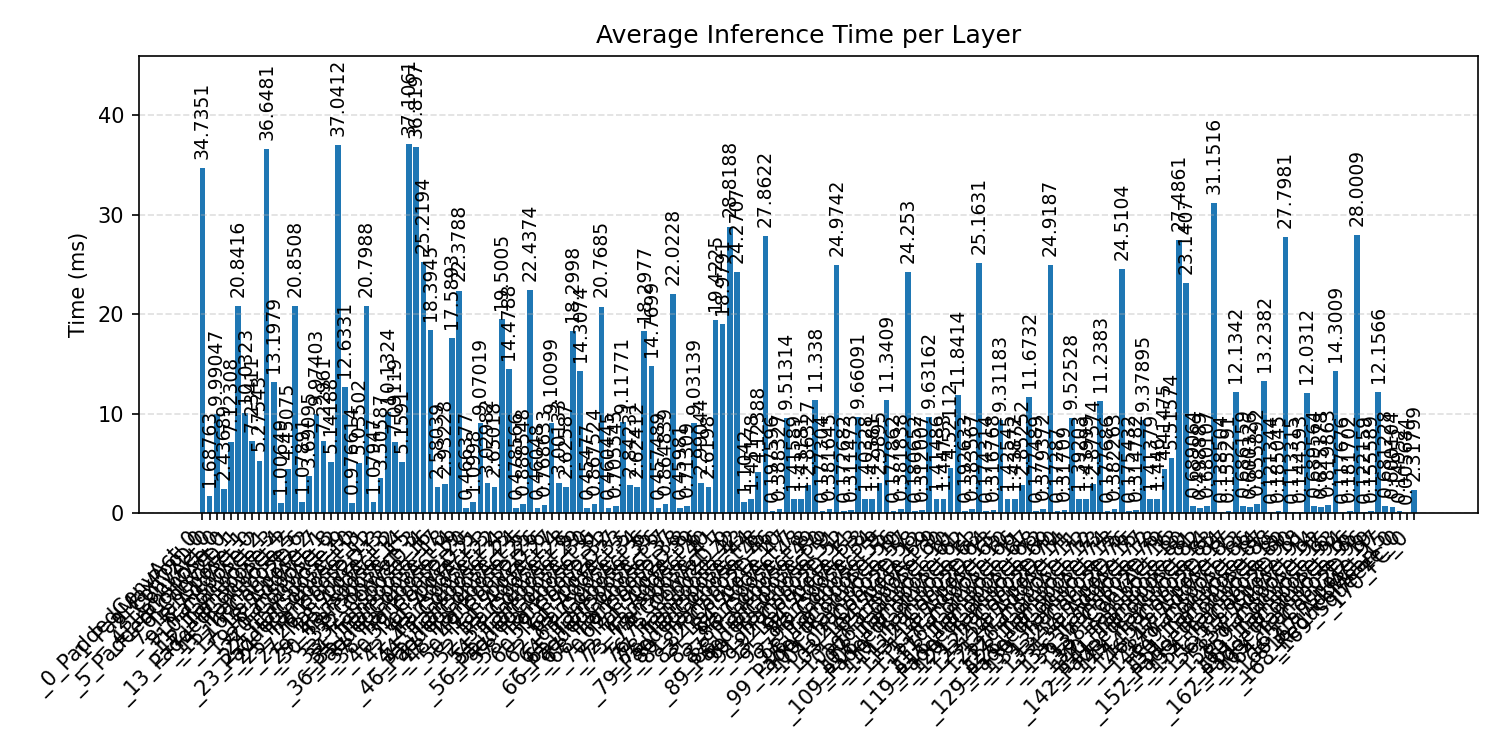
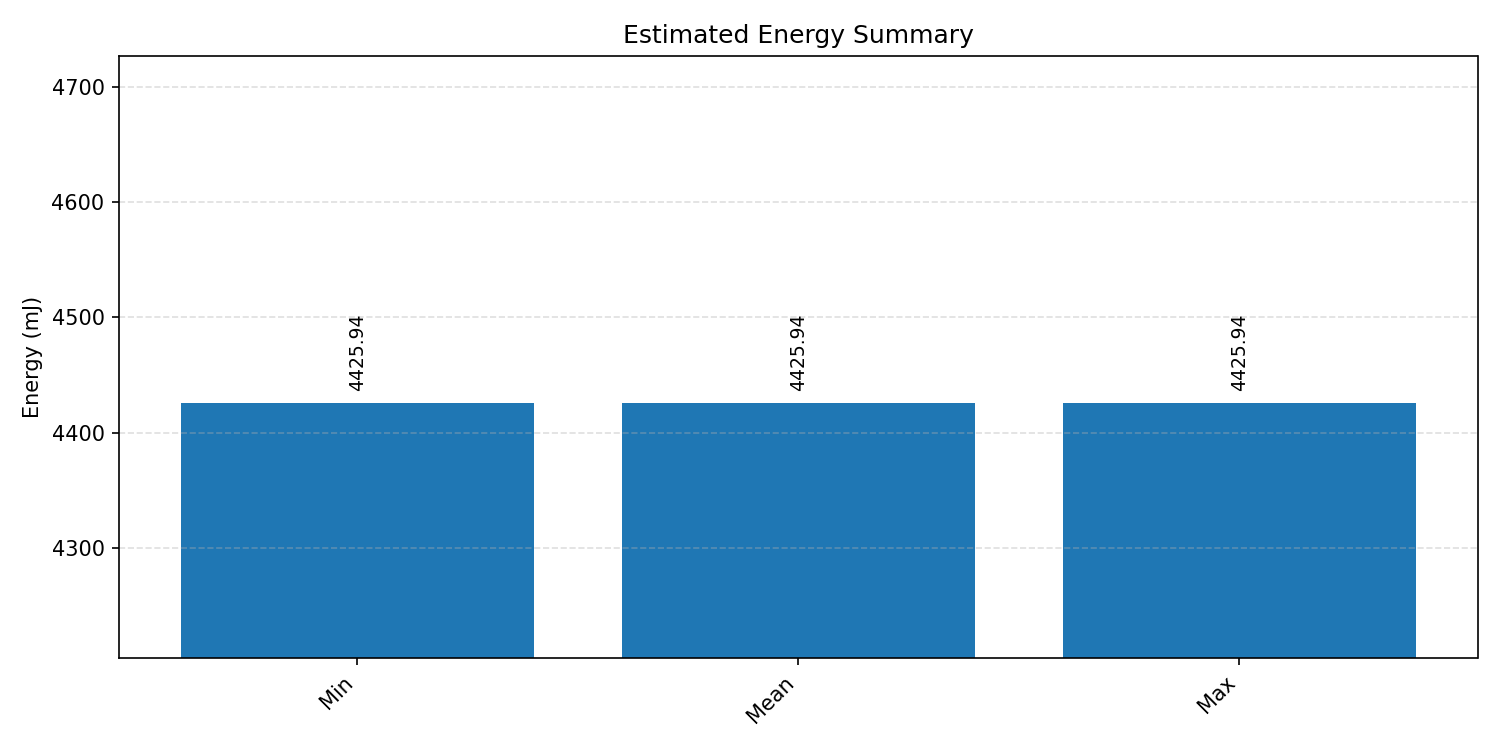

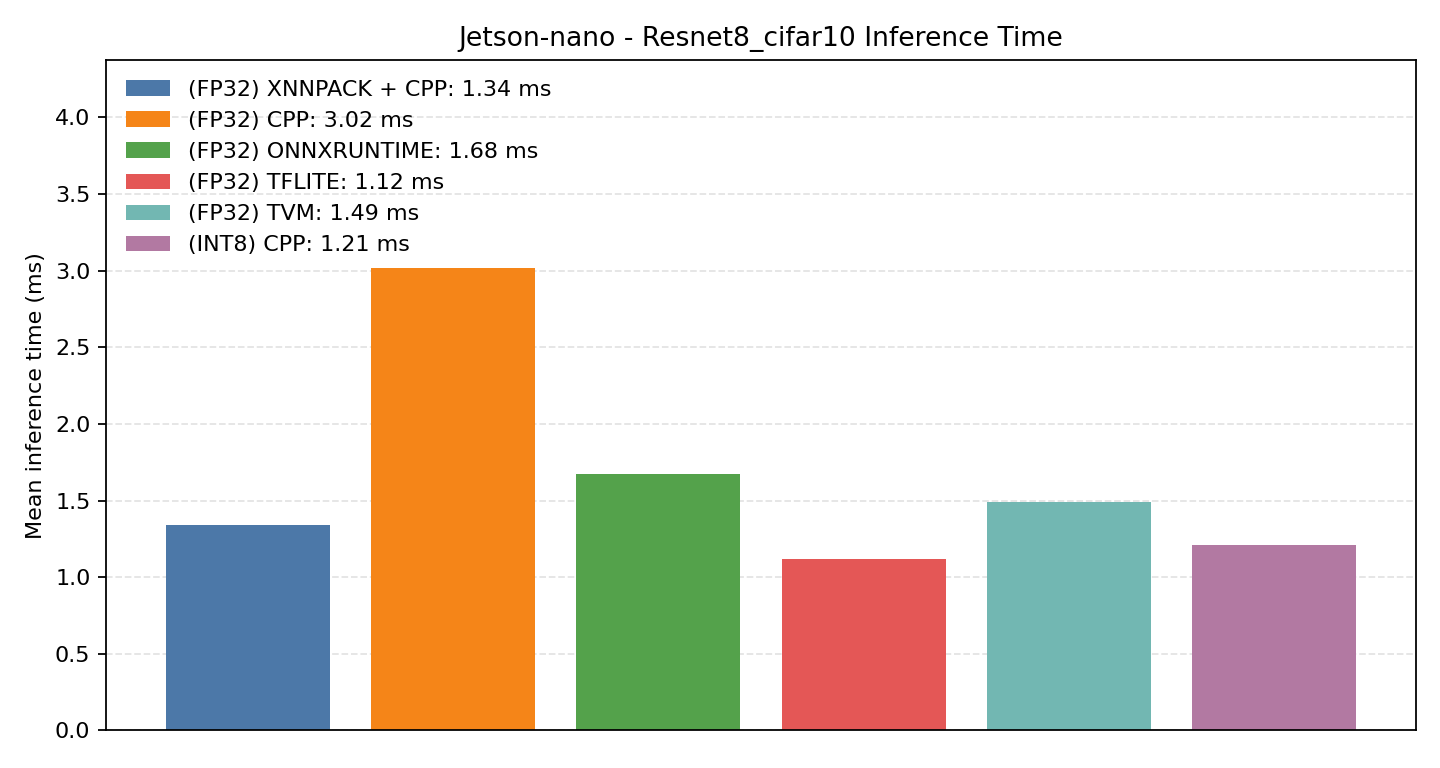
#4. Jetson NANO Embedded Benchmarks#
The Jetson Nano is a more constrained edge-Linux platform, making it a good reference for low-power embedded use cases. Each case starts with the compiled Comparison Chart when available, followed by the detailed per-export benchmark graphs.
#4.1 LeNet MNIST#
Comparison Chart
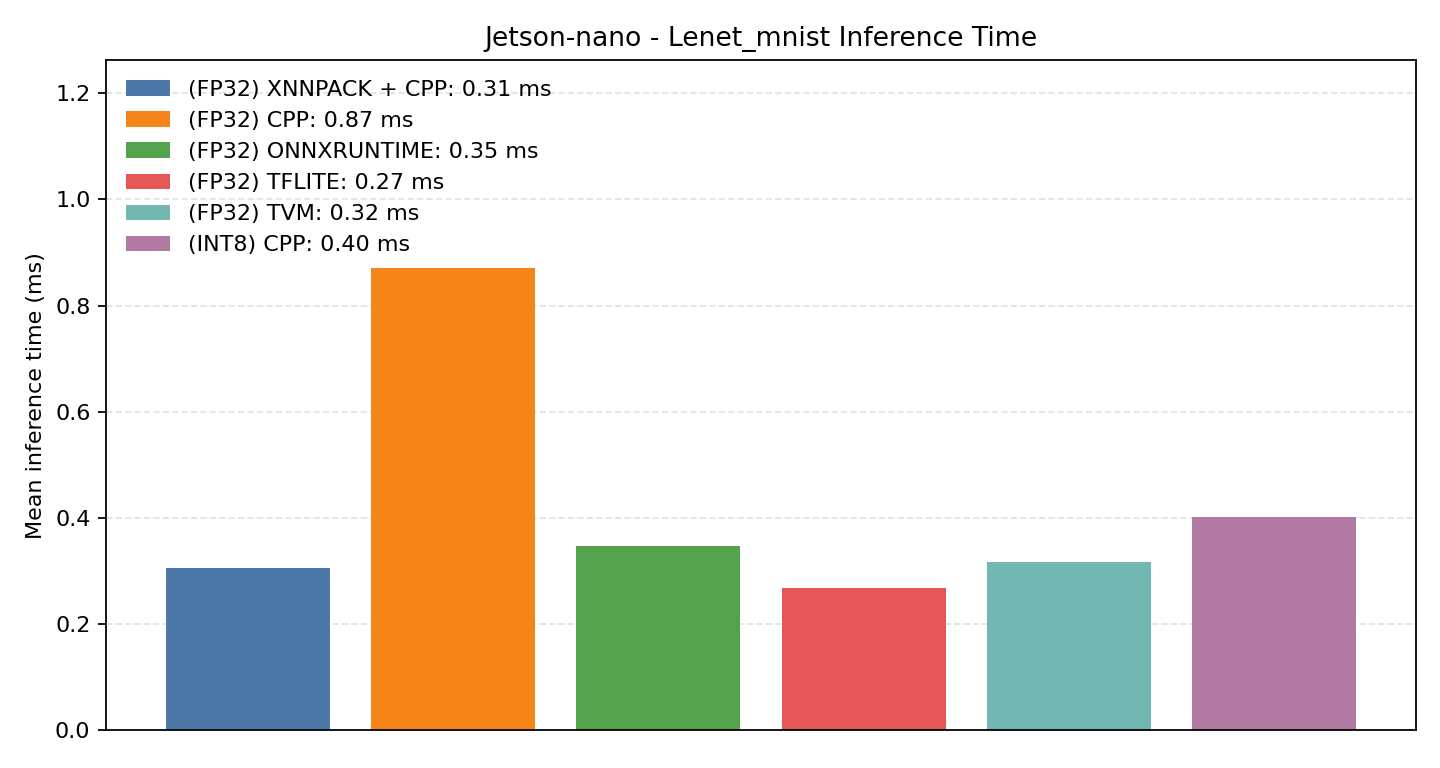
#4.1.1 (FP32) CPP#
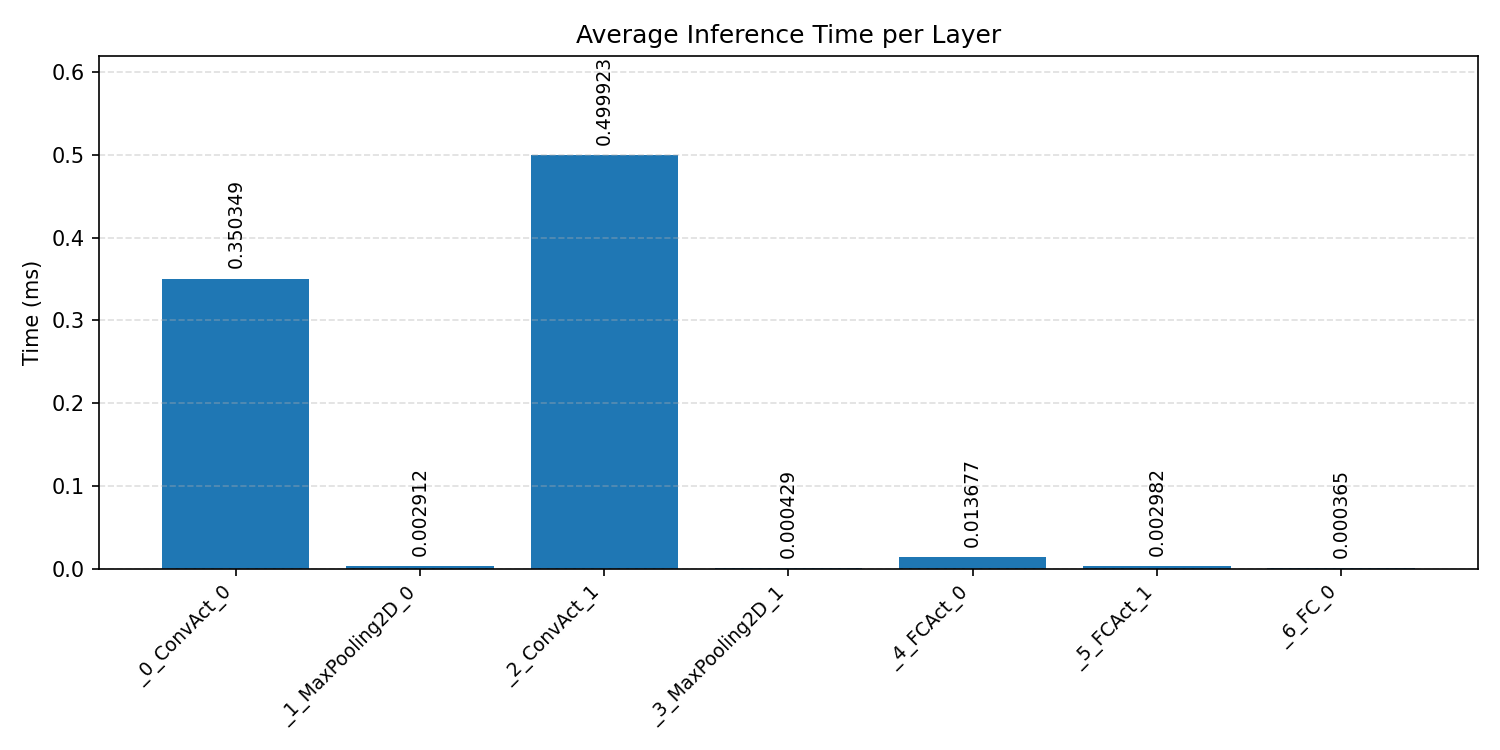
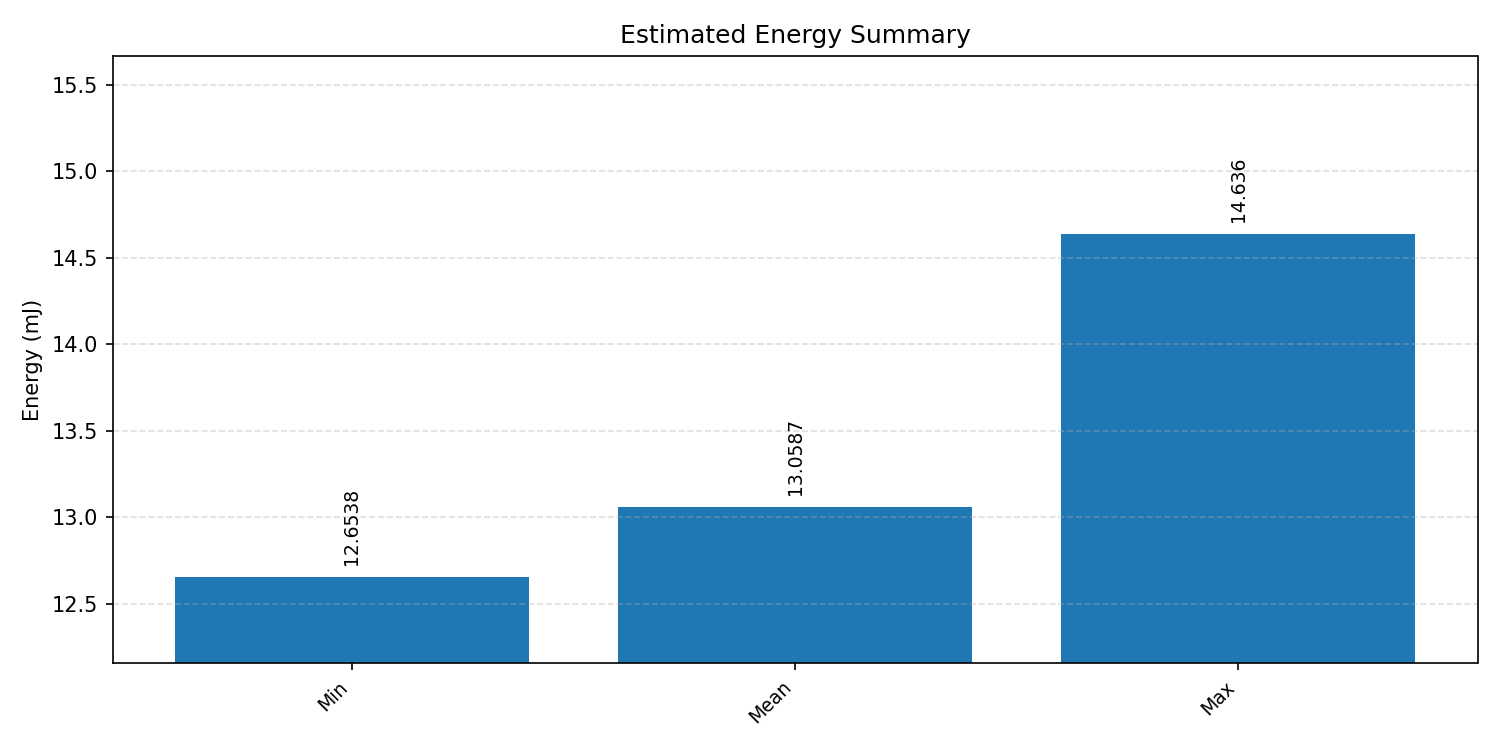
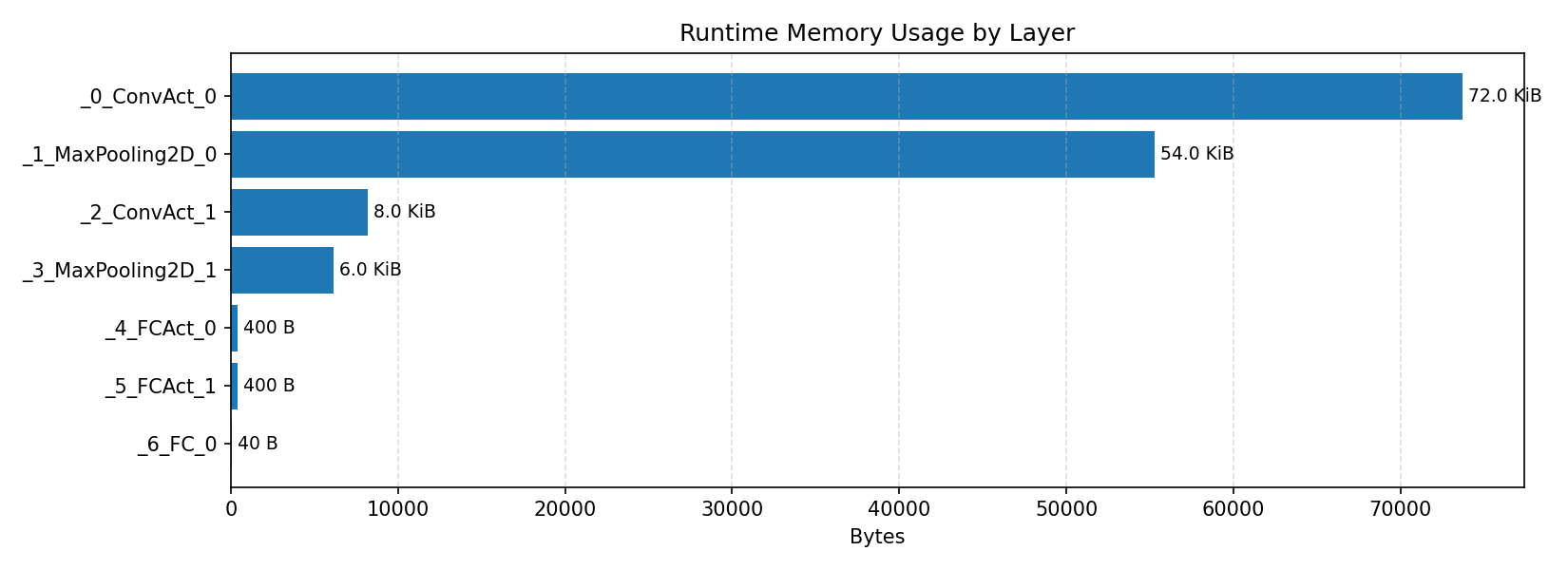
#4.1.2 (FP32) XNNPACK + CPP#
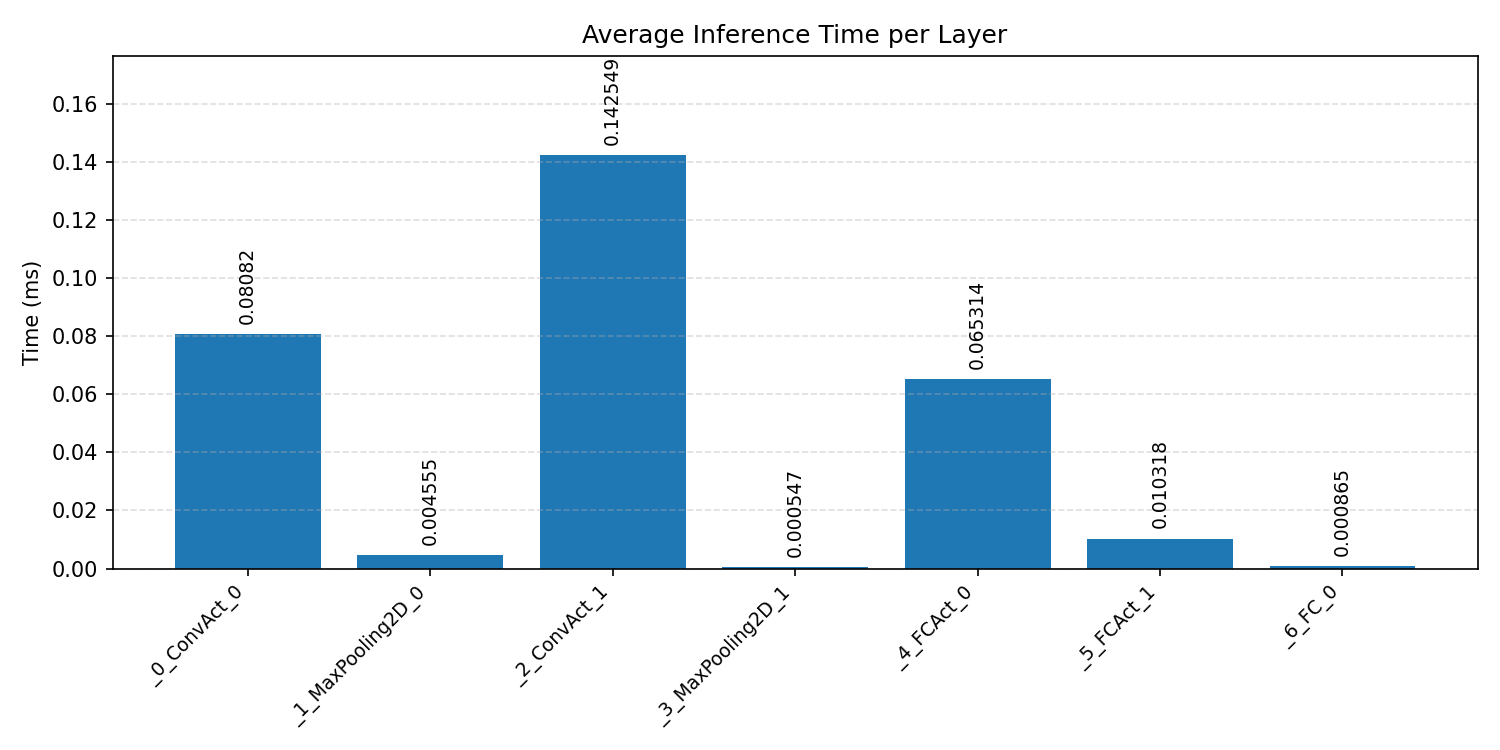
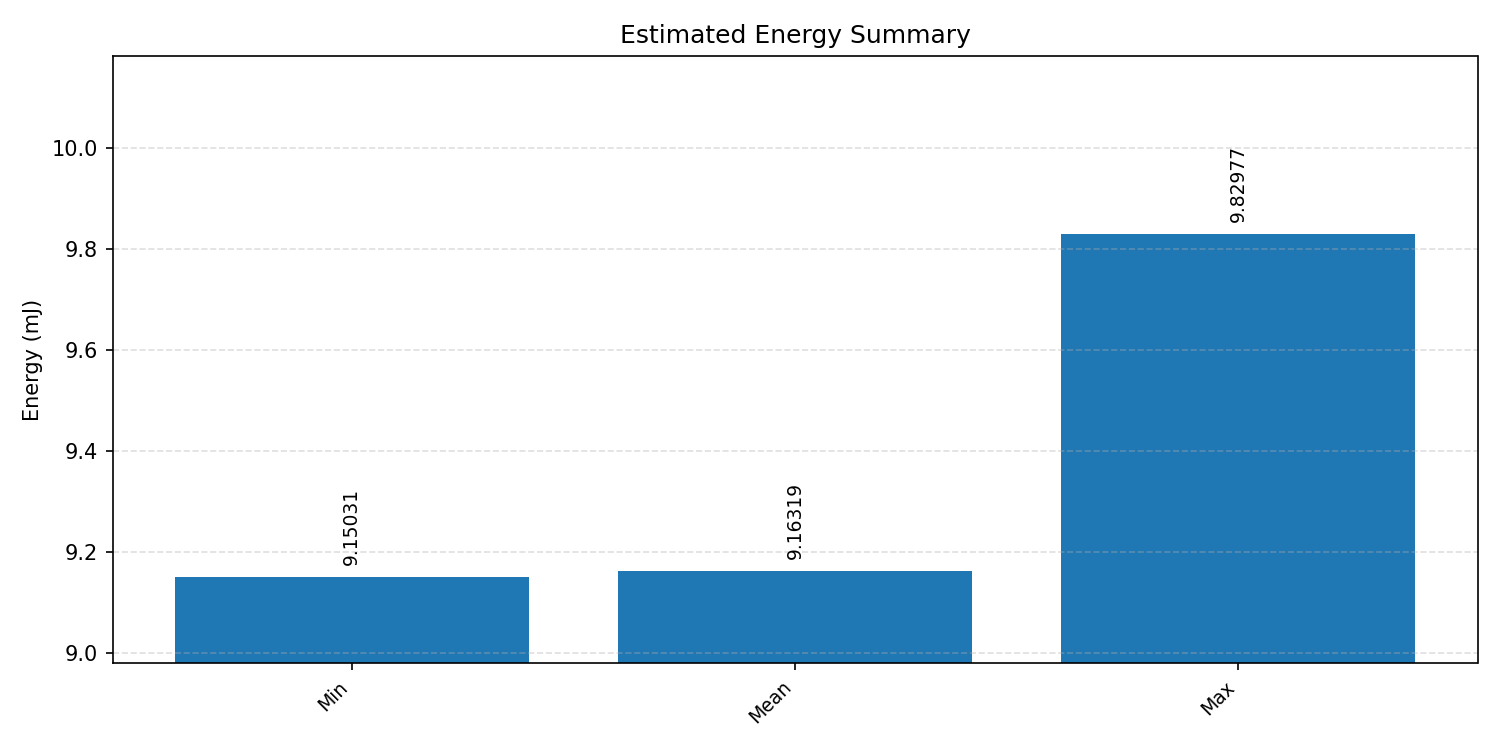
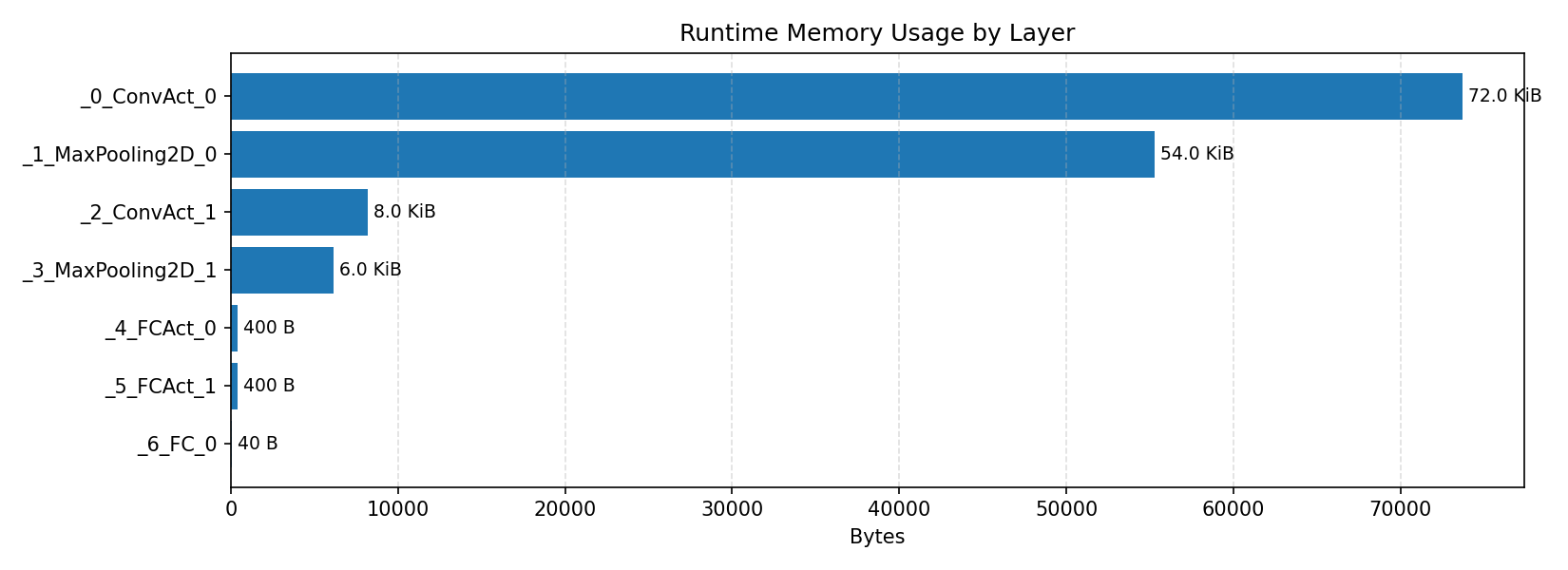
#4.1.3 (INT8) CPP#
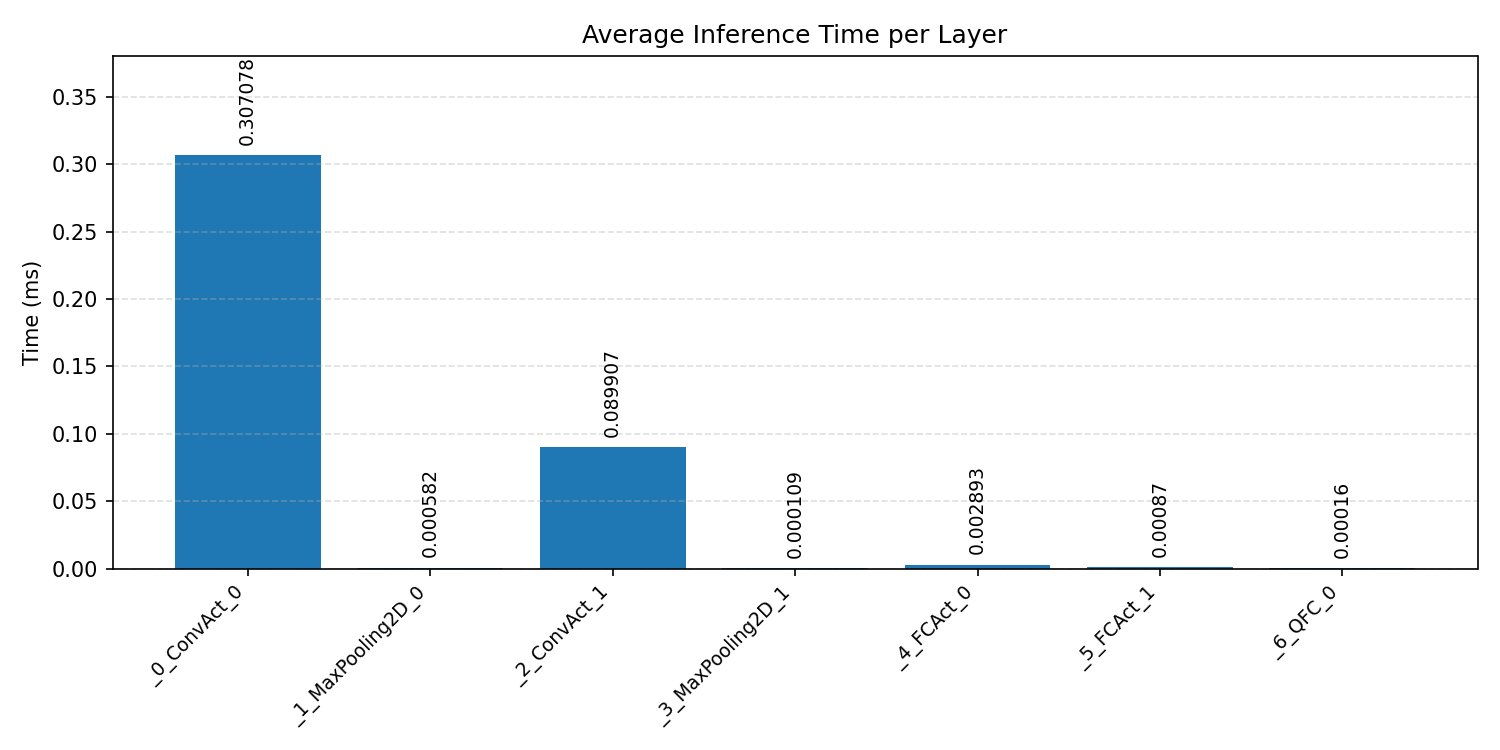
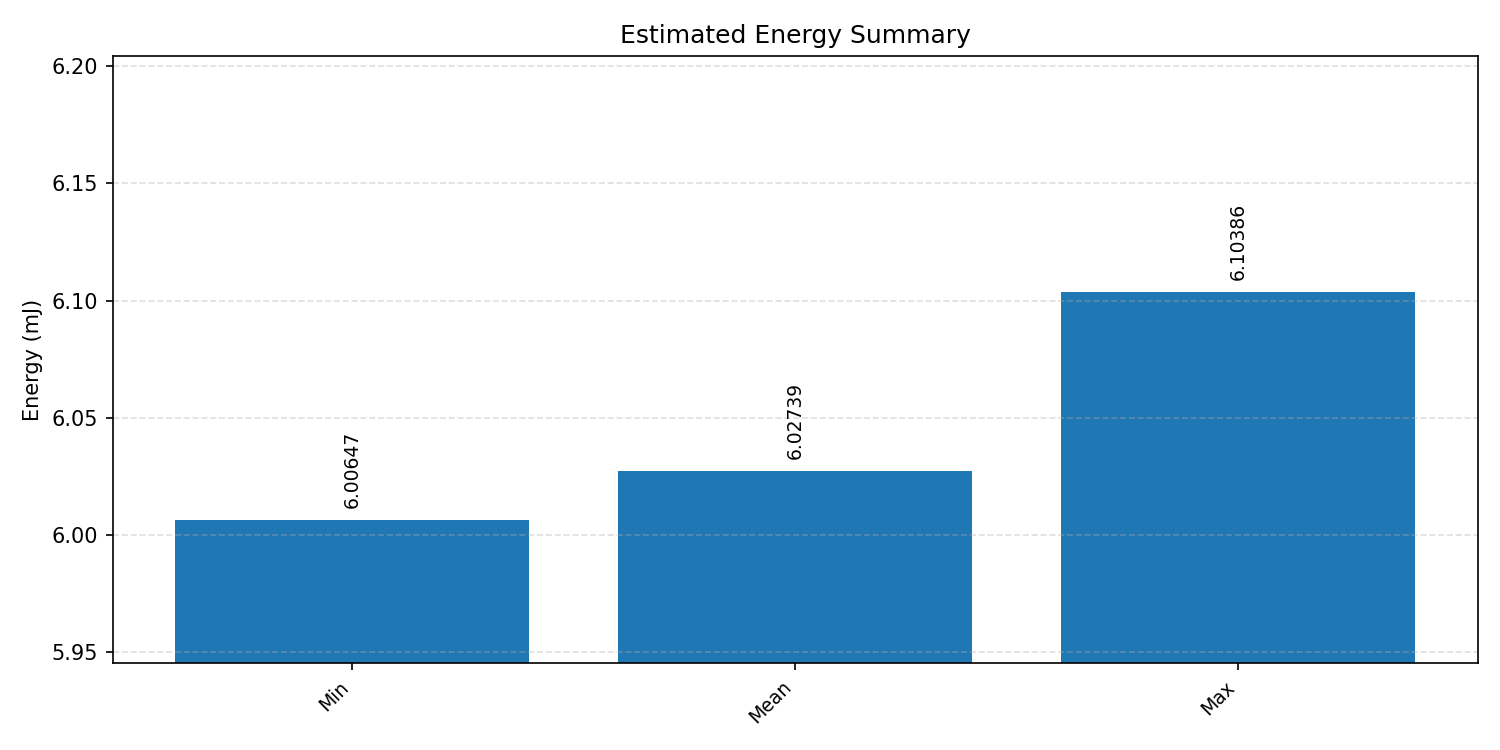
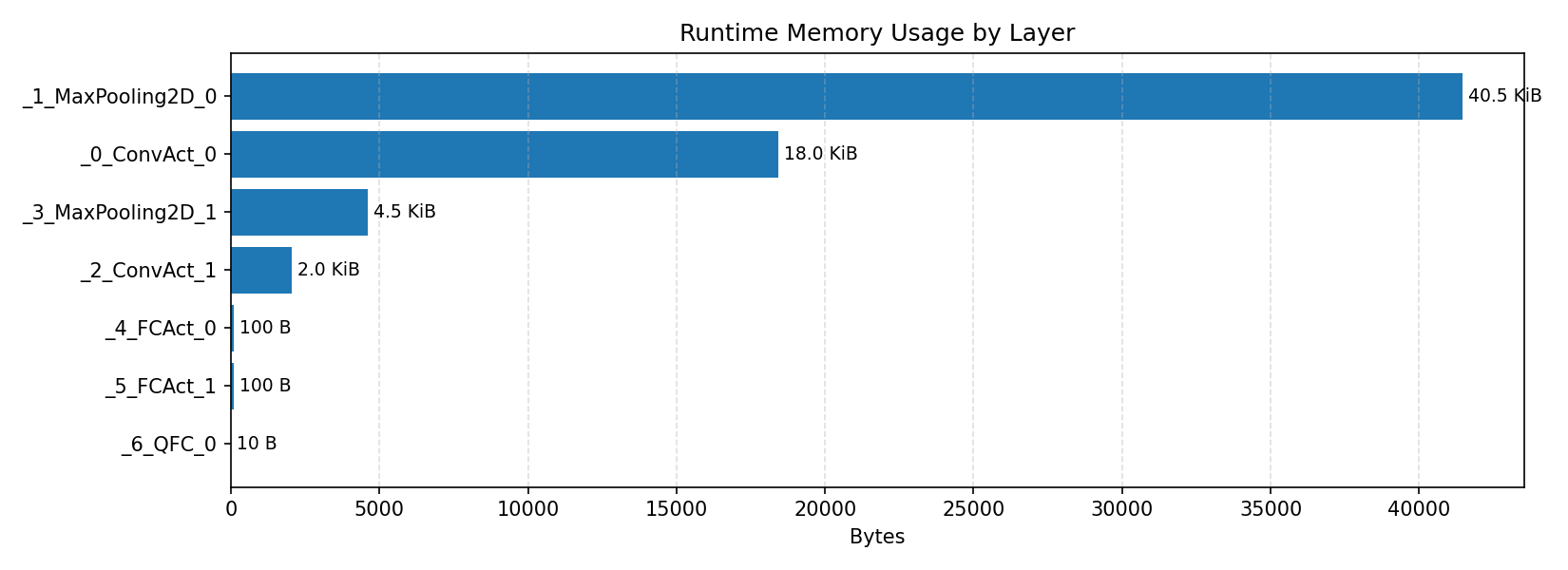
#4.2 MobileNet V1 VWW#
Comparison Chart
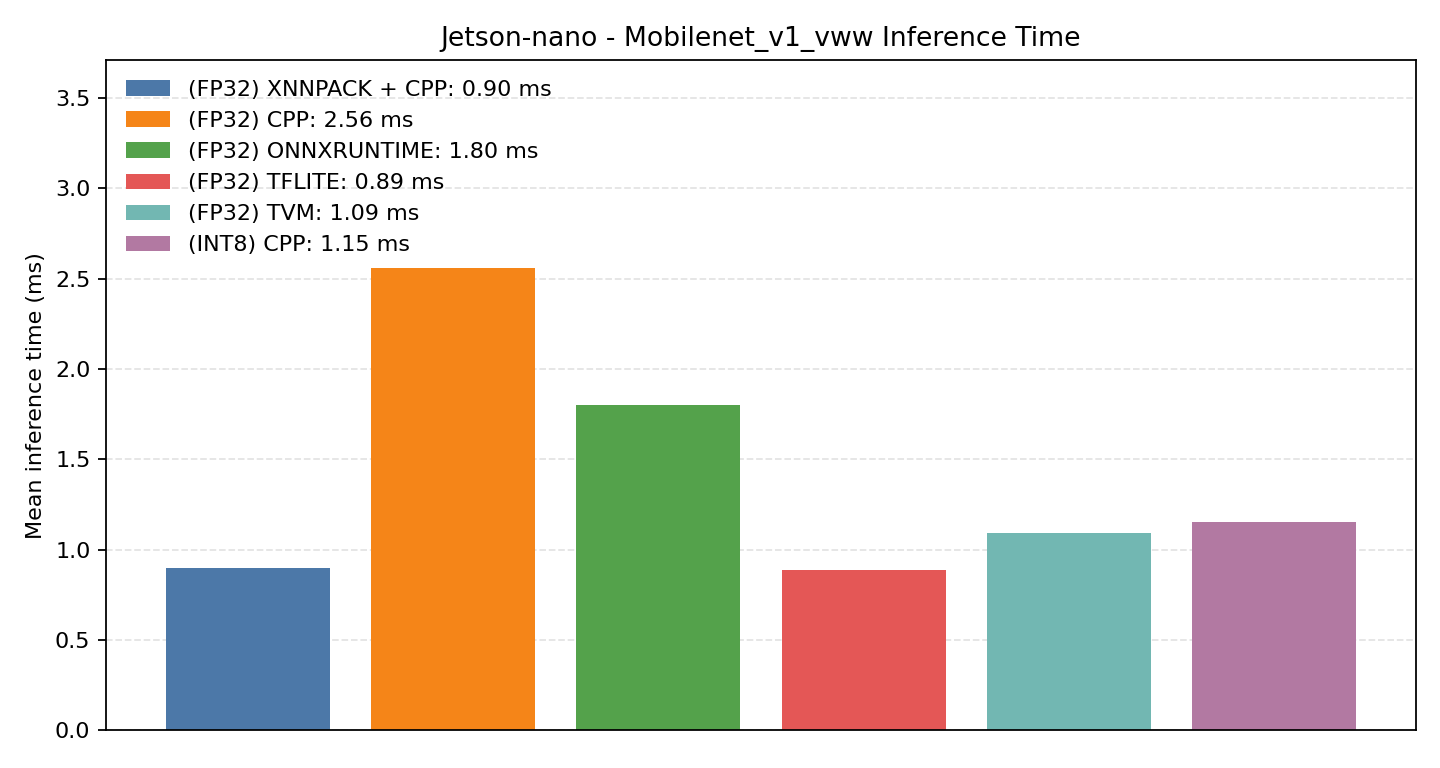
#4.2.1 (FP32) CPP#
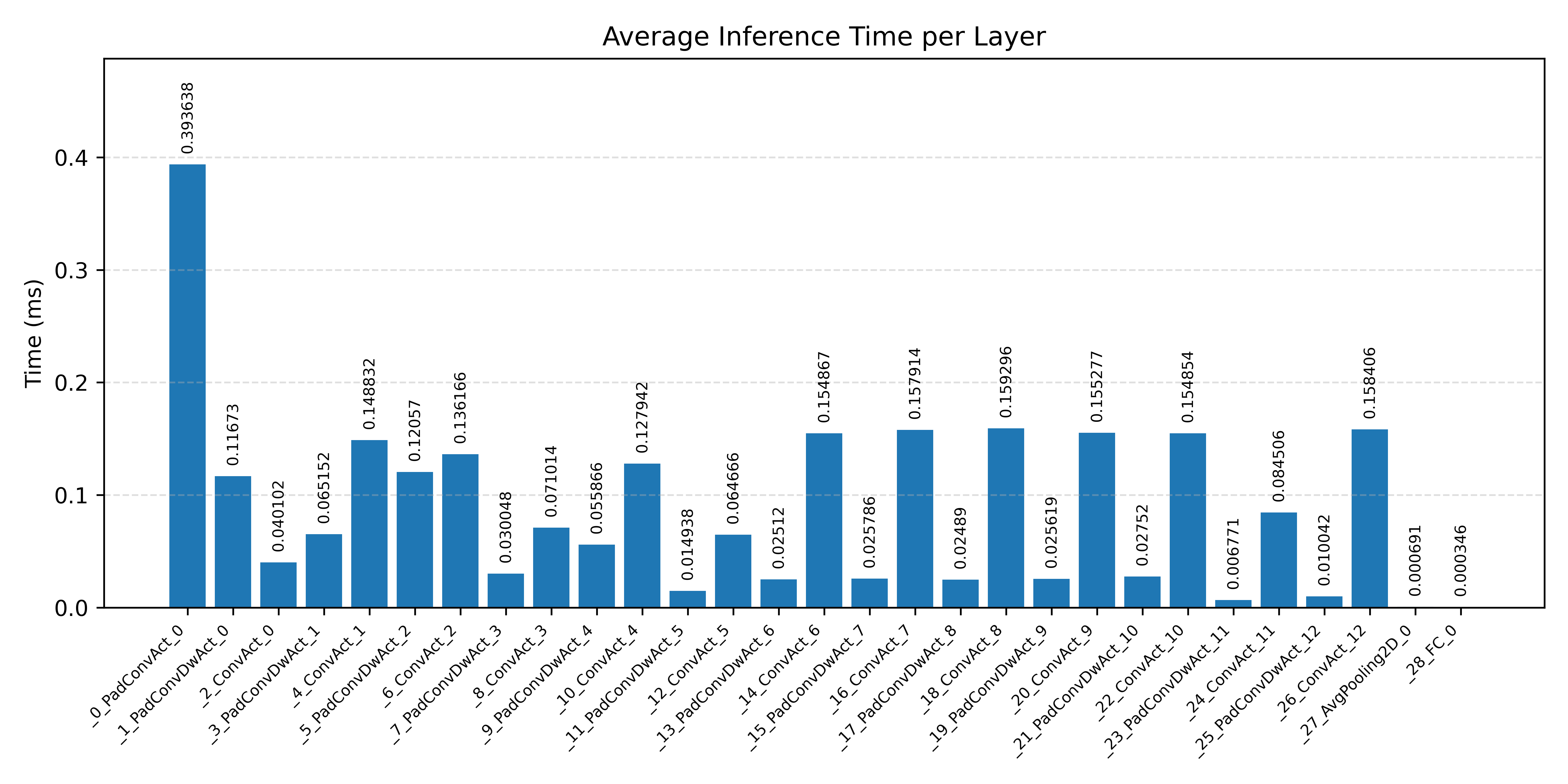
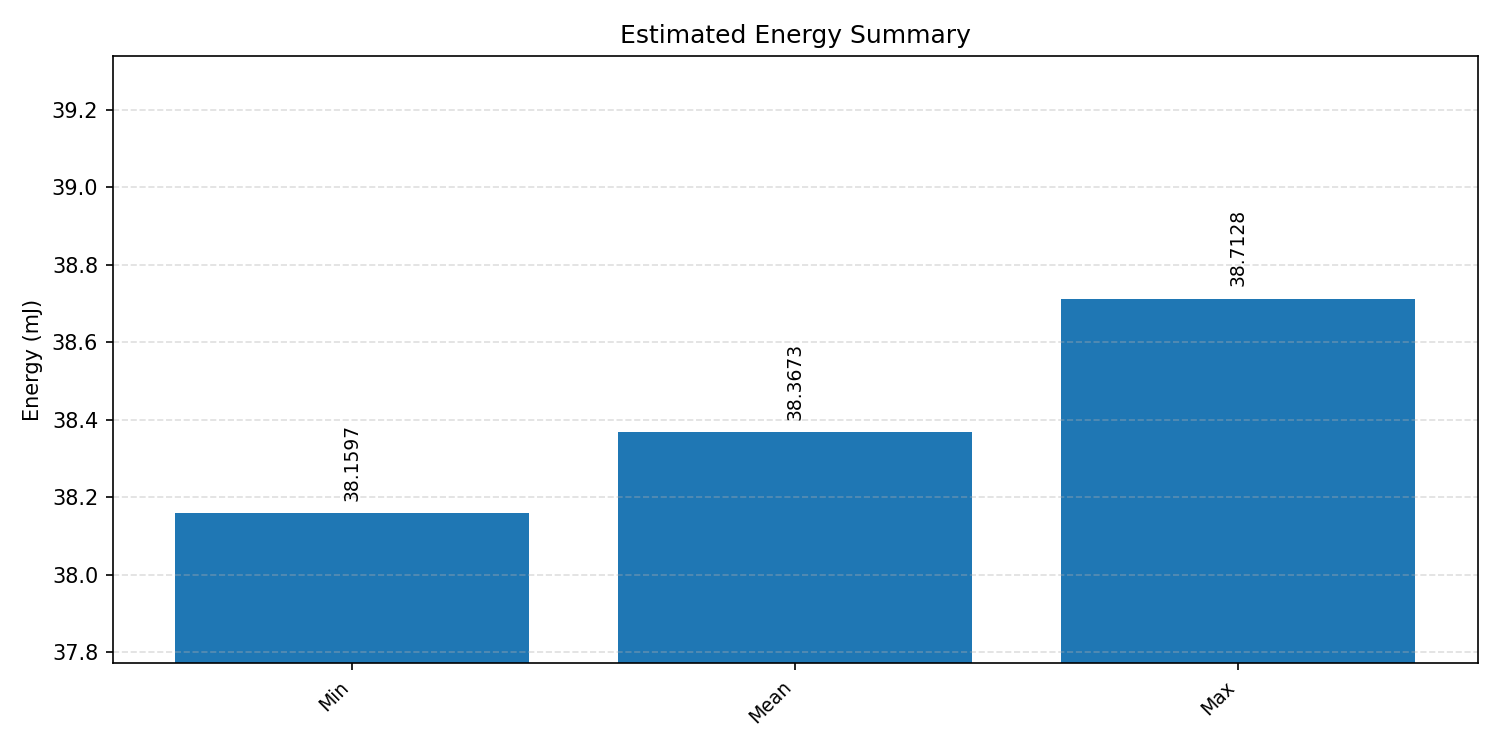
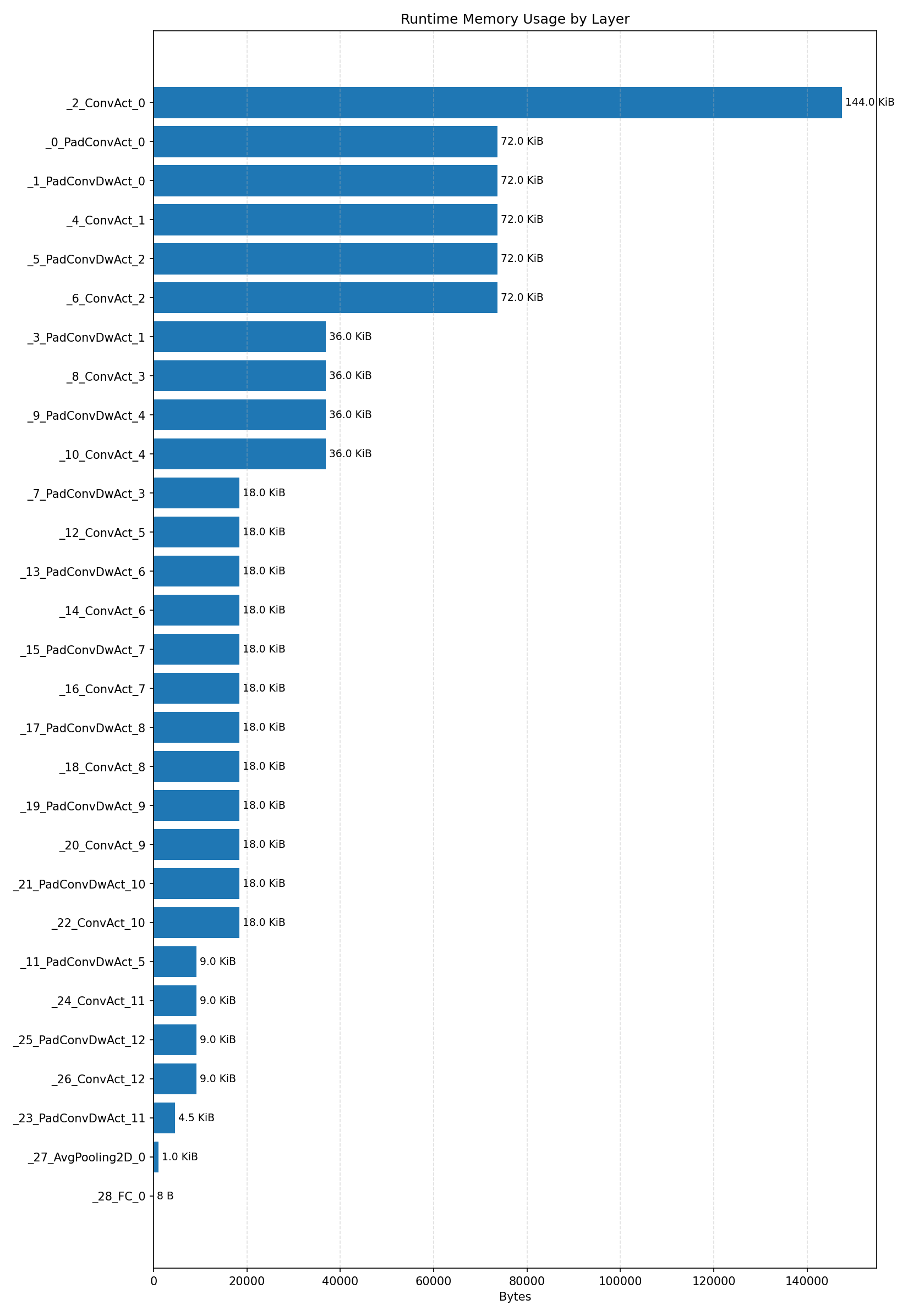
#4.2.2 (FP32) XNNPACK + CPP#
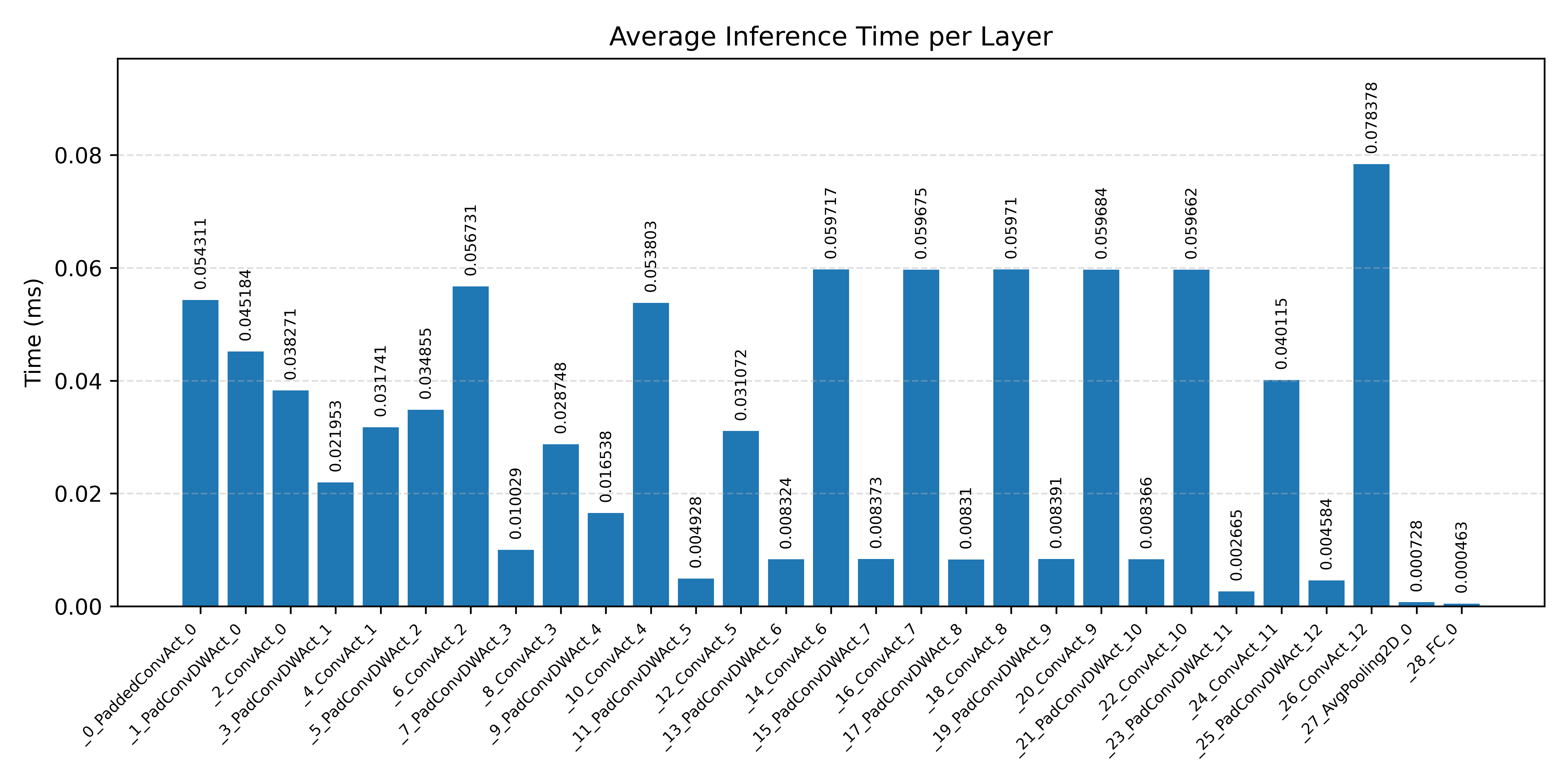
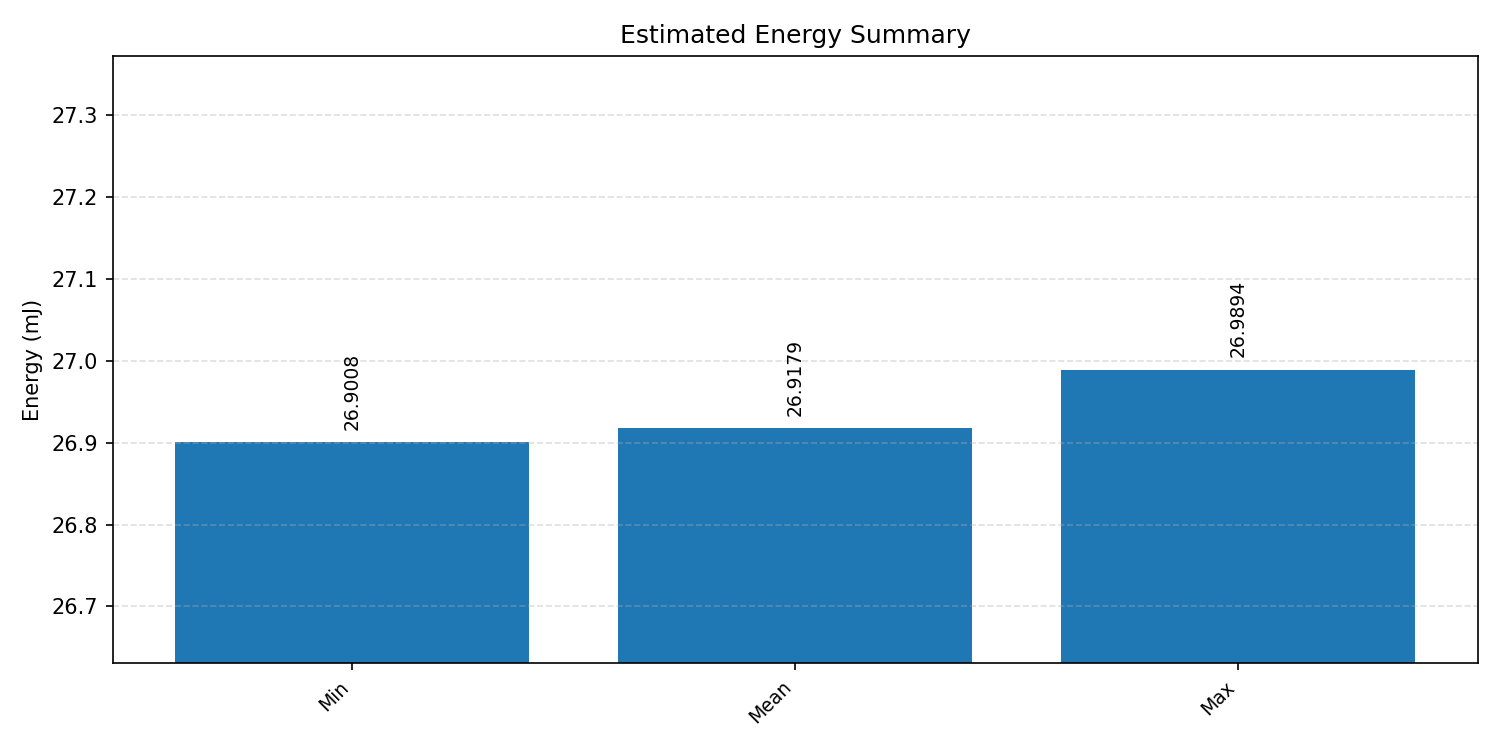
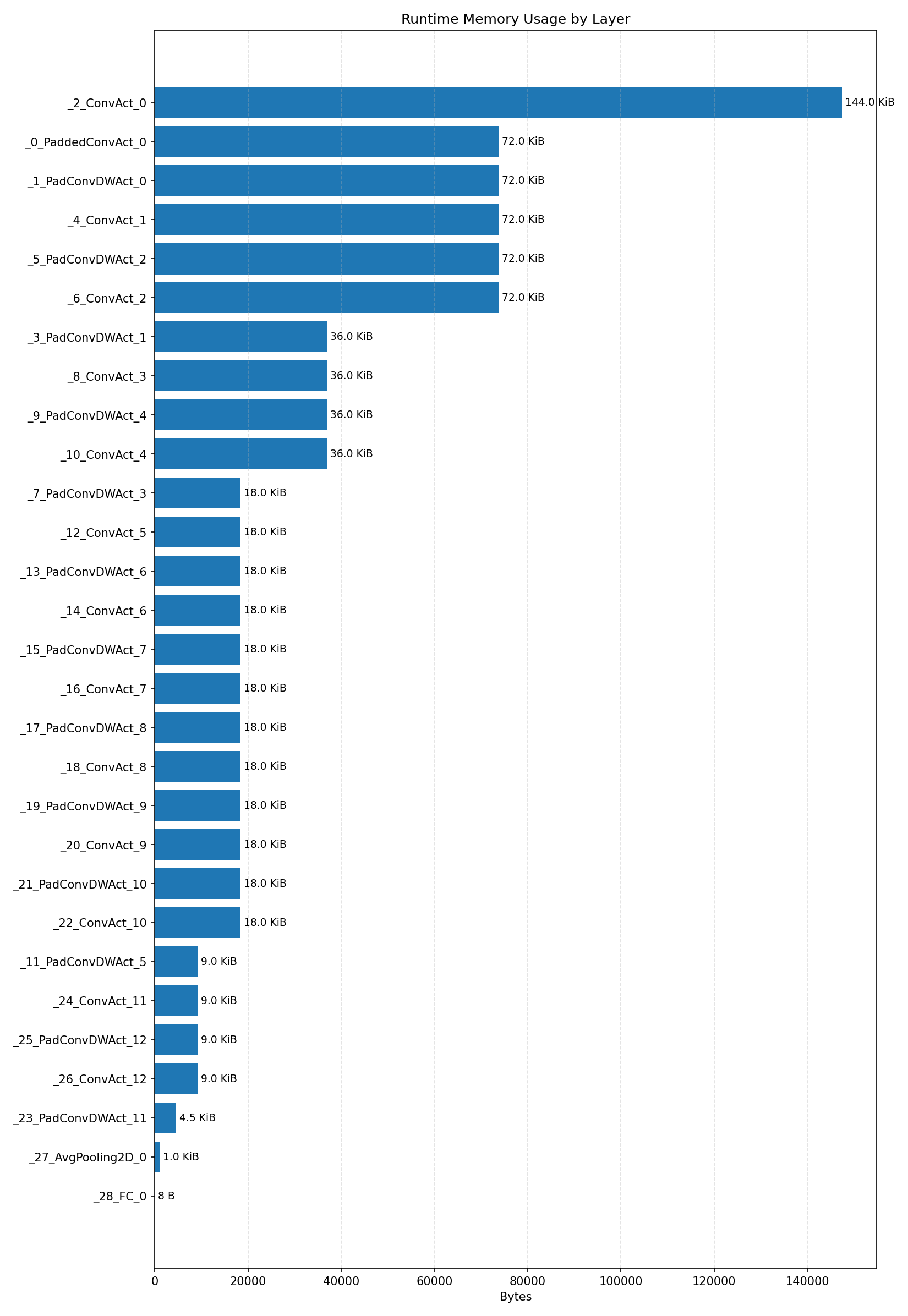
#4.2.3 (INT8) CPP#
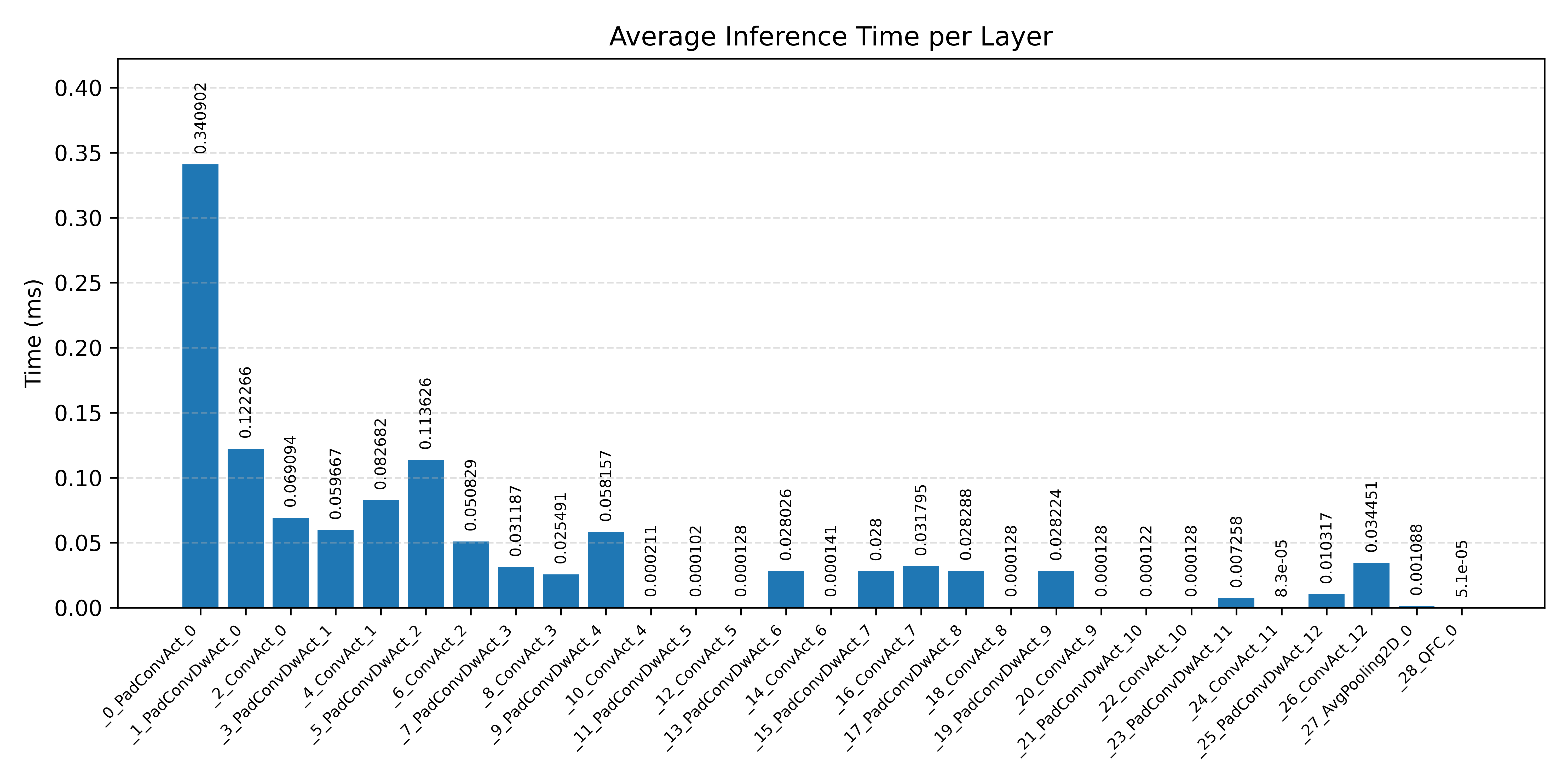
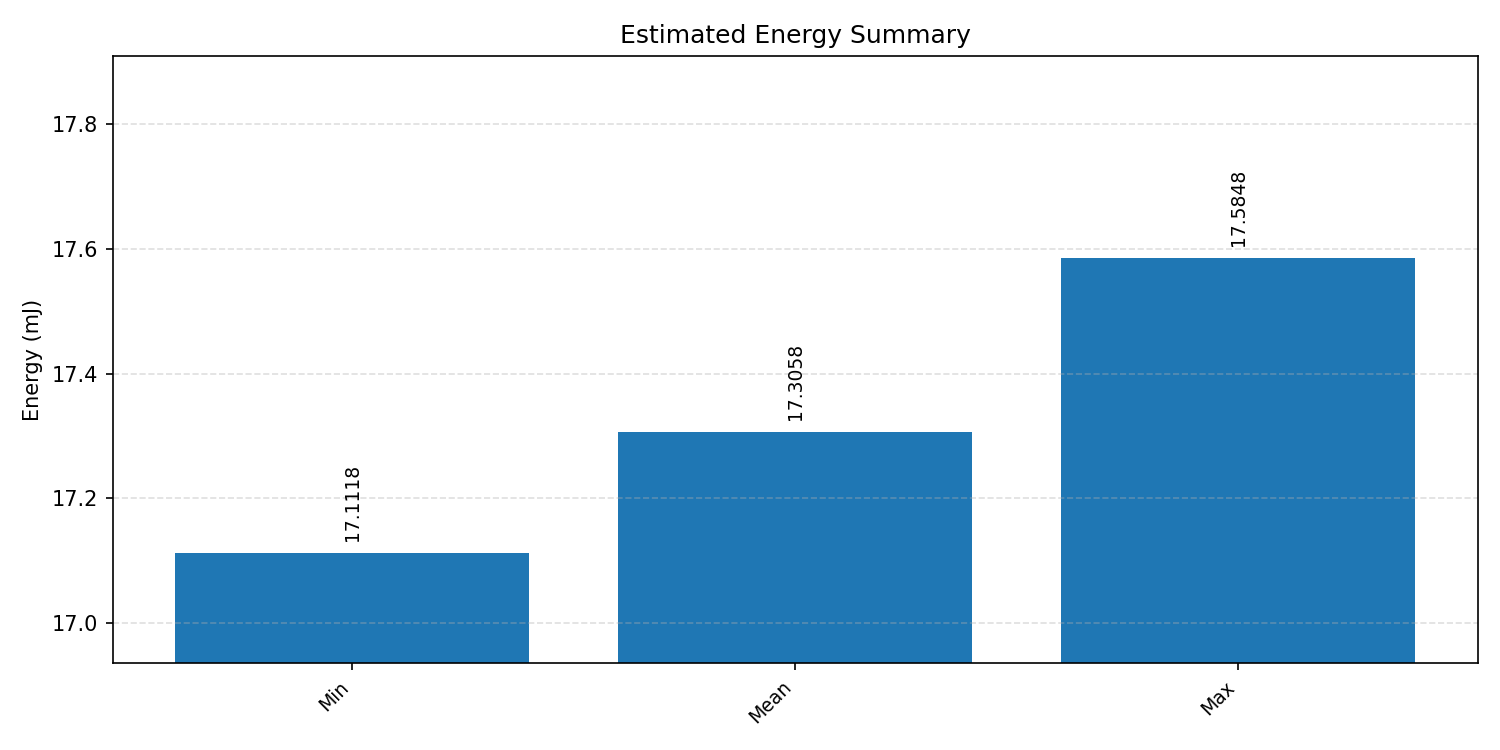
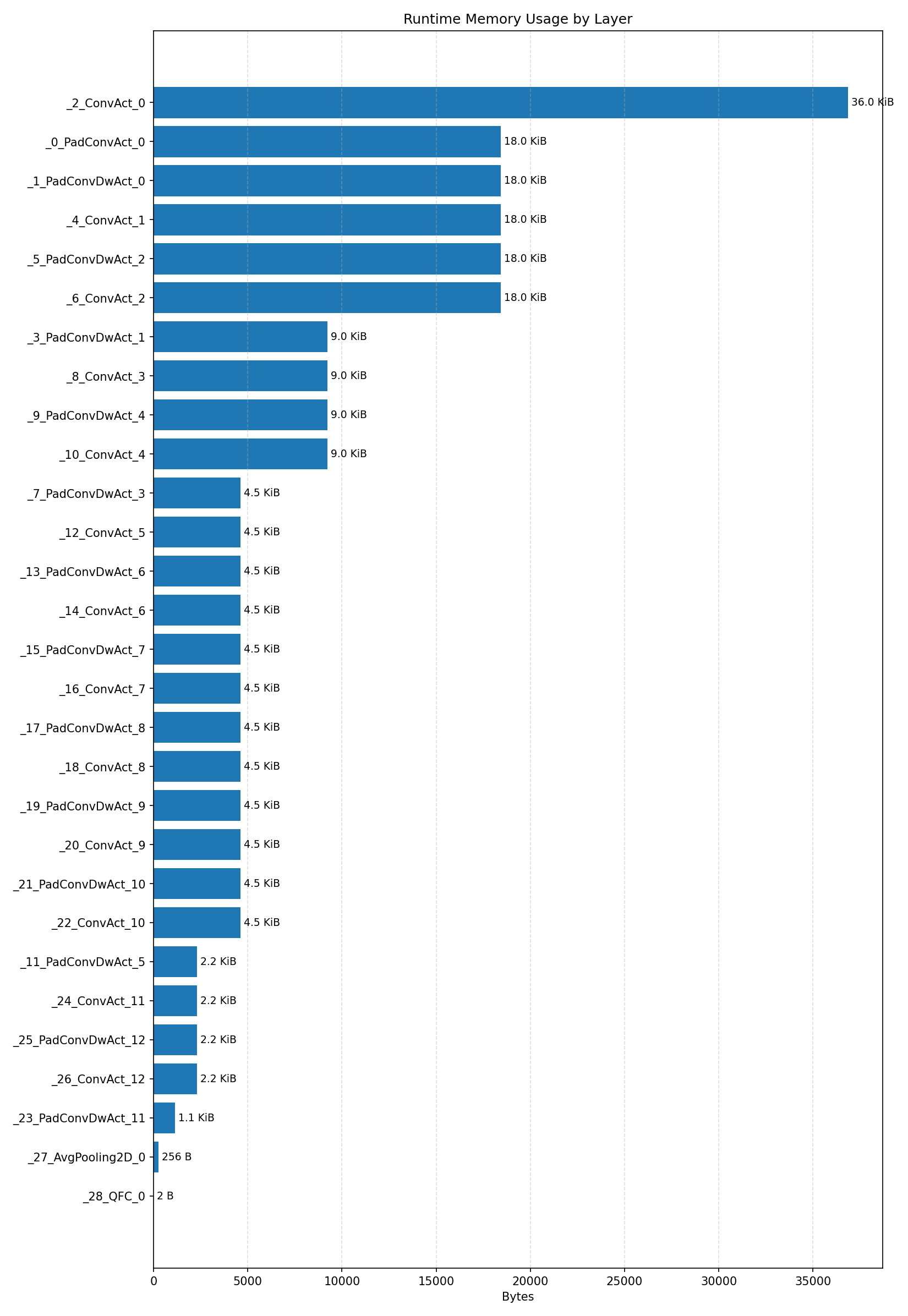
#4.3 ResNet8 CIFAR-10#
Comparison Chart
#4.3.1 (FP32) CPP#
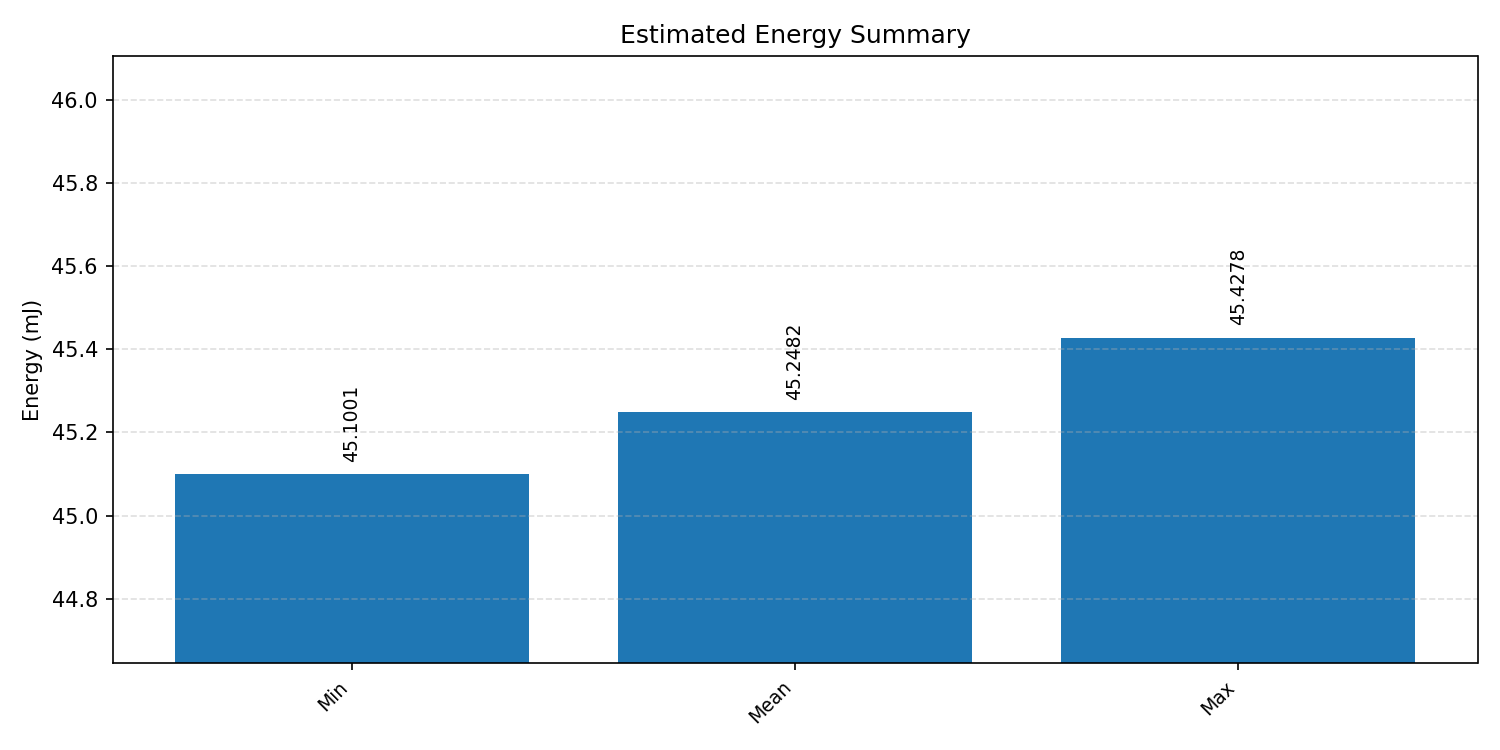
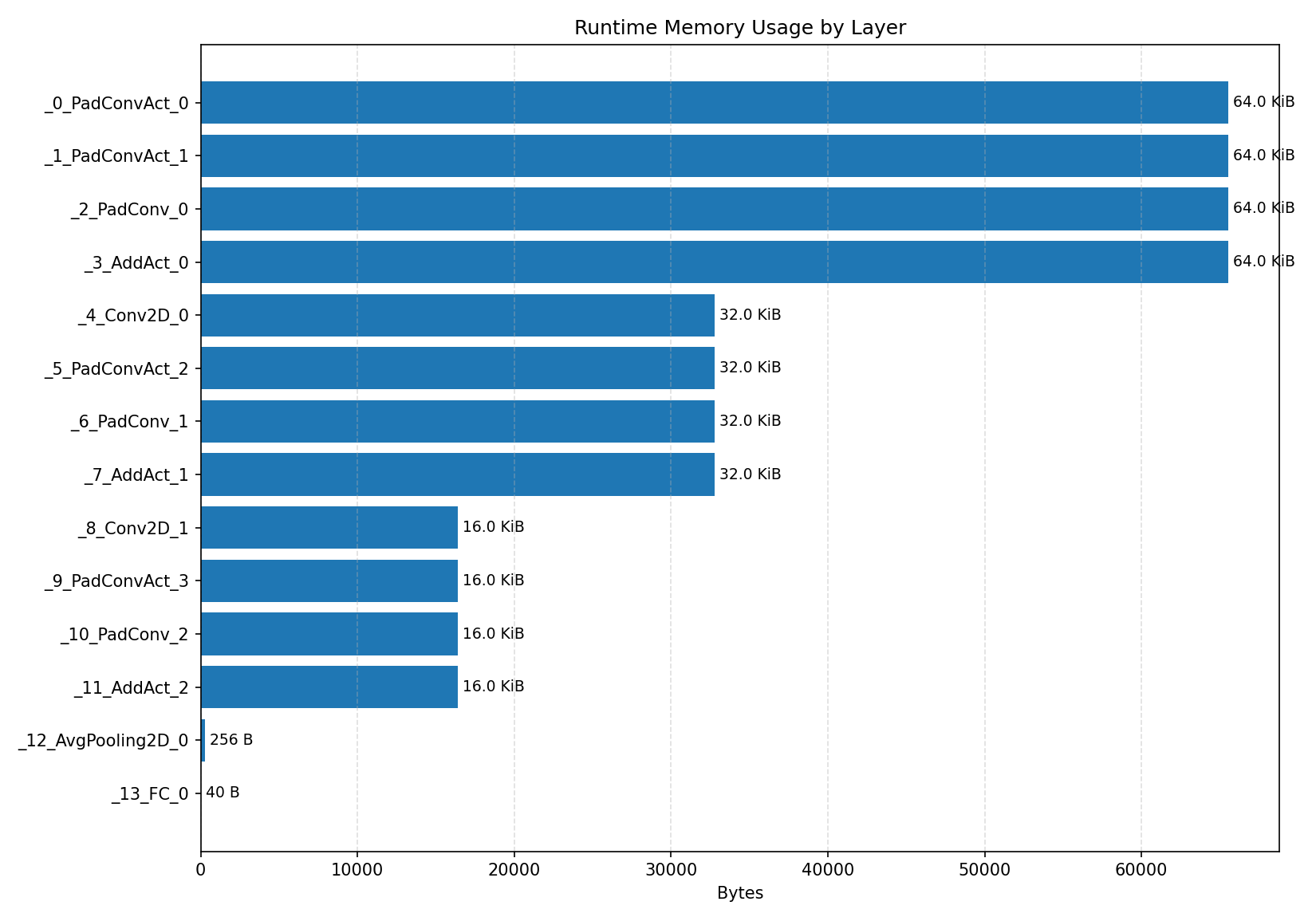
#4.3.2 (FP32) XNNPACK + CPP#
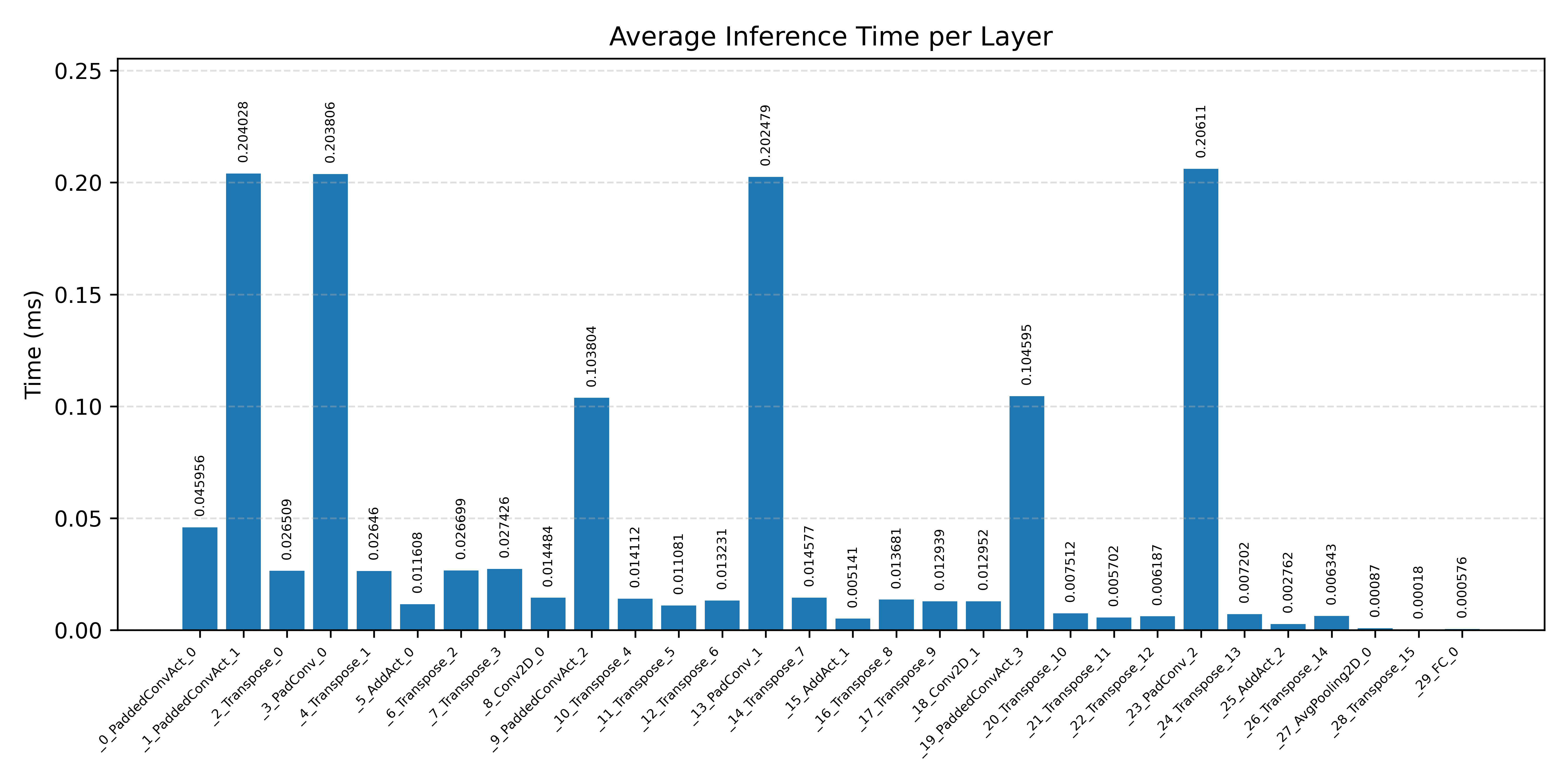
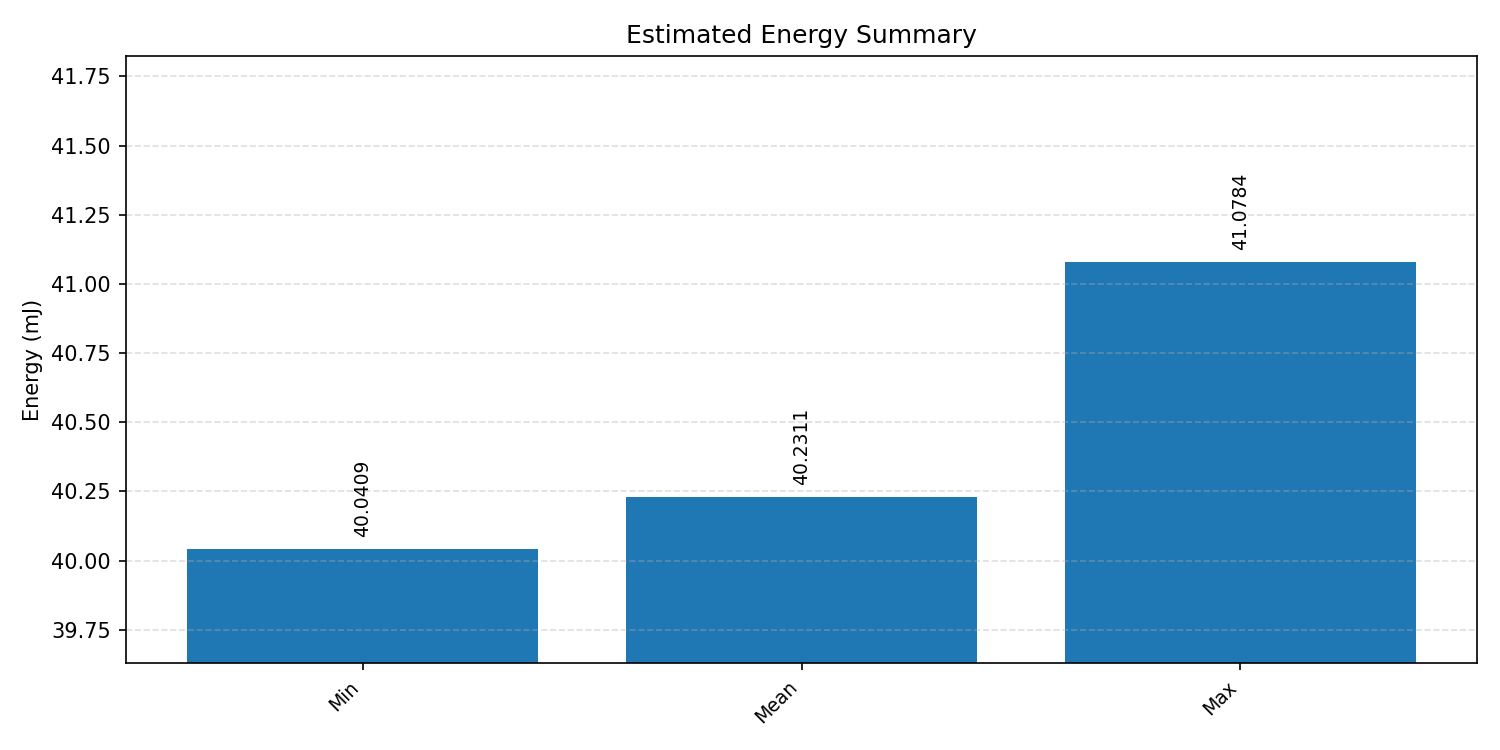
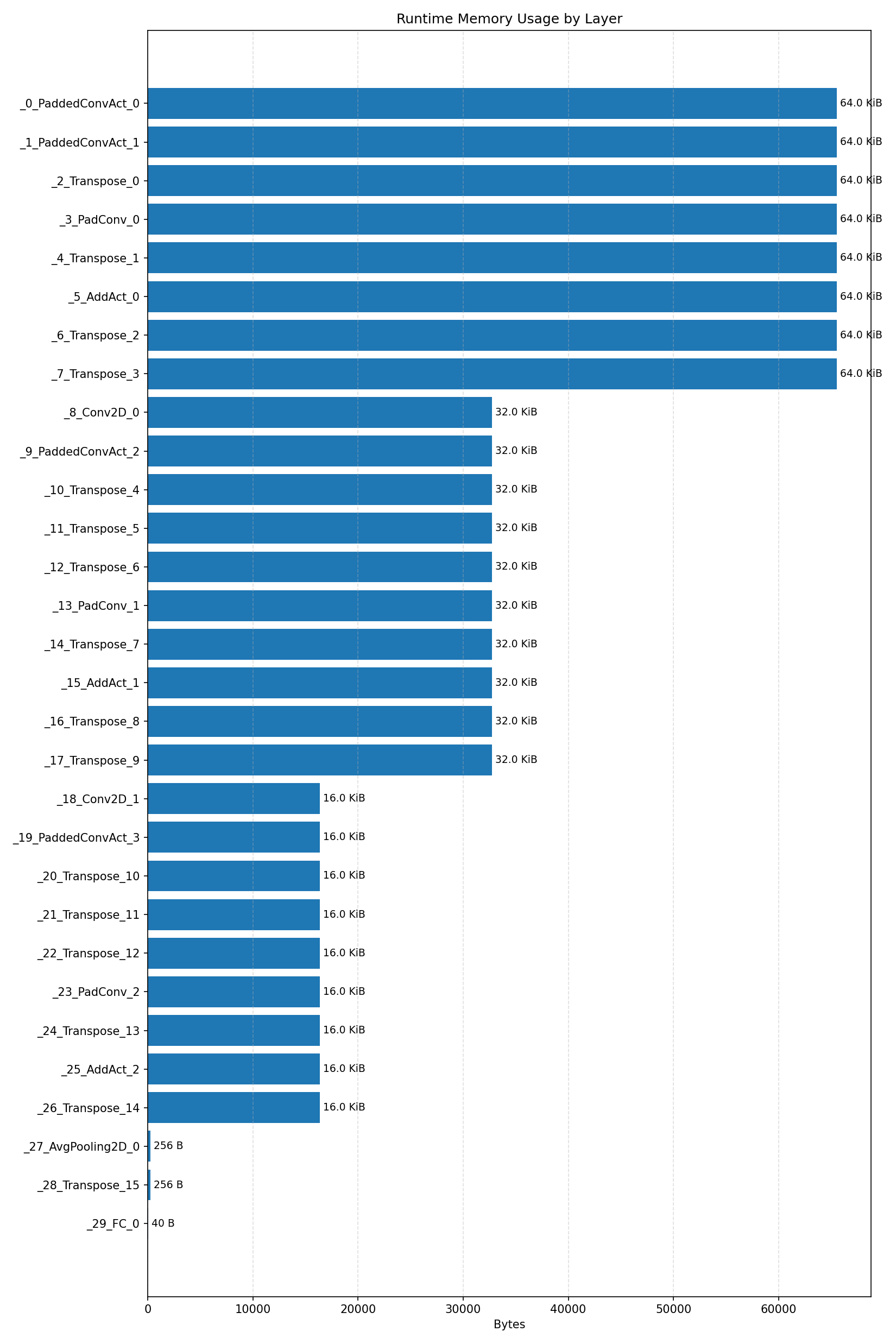
#4.3.3 (INT8) CPP#
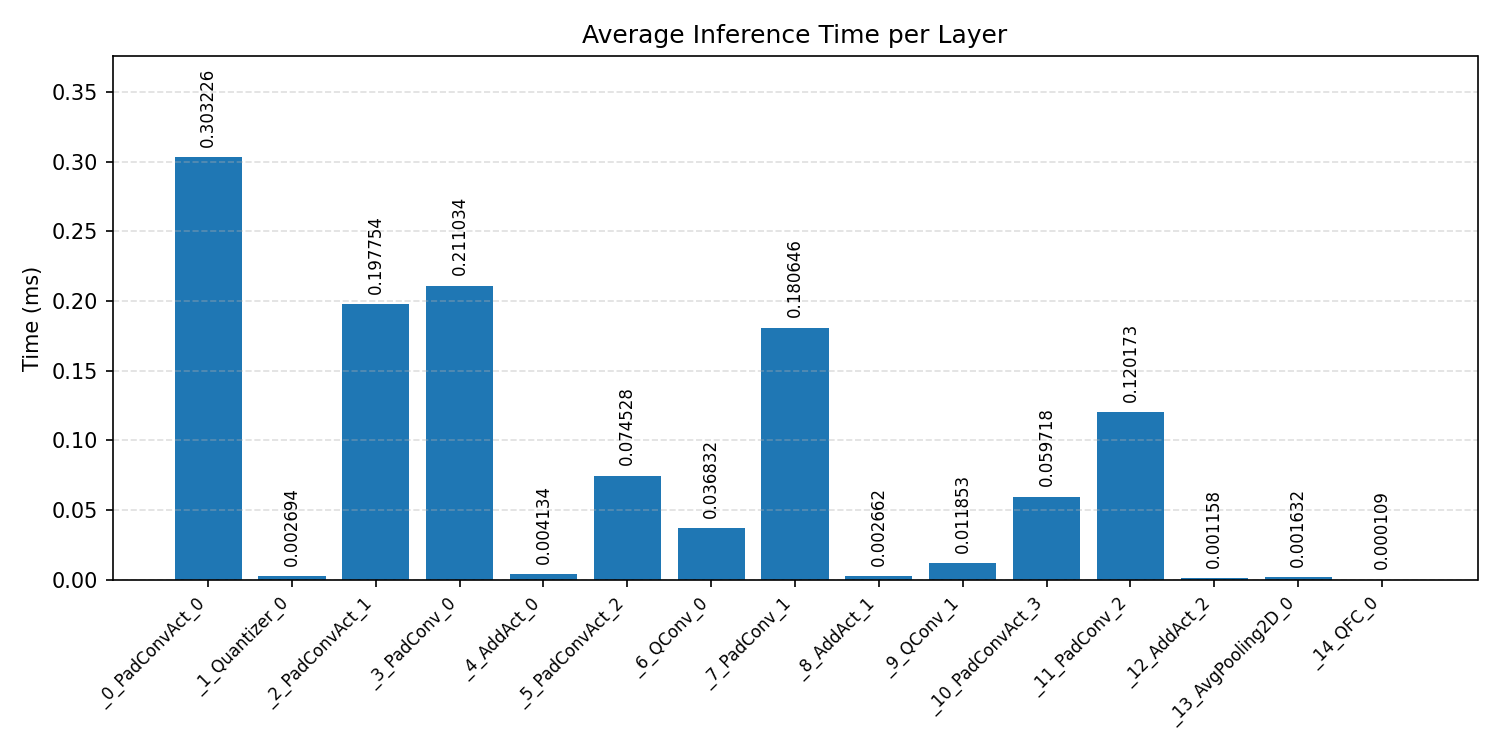
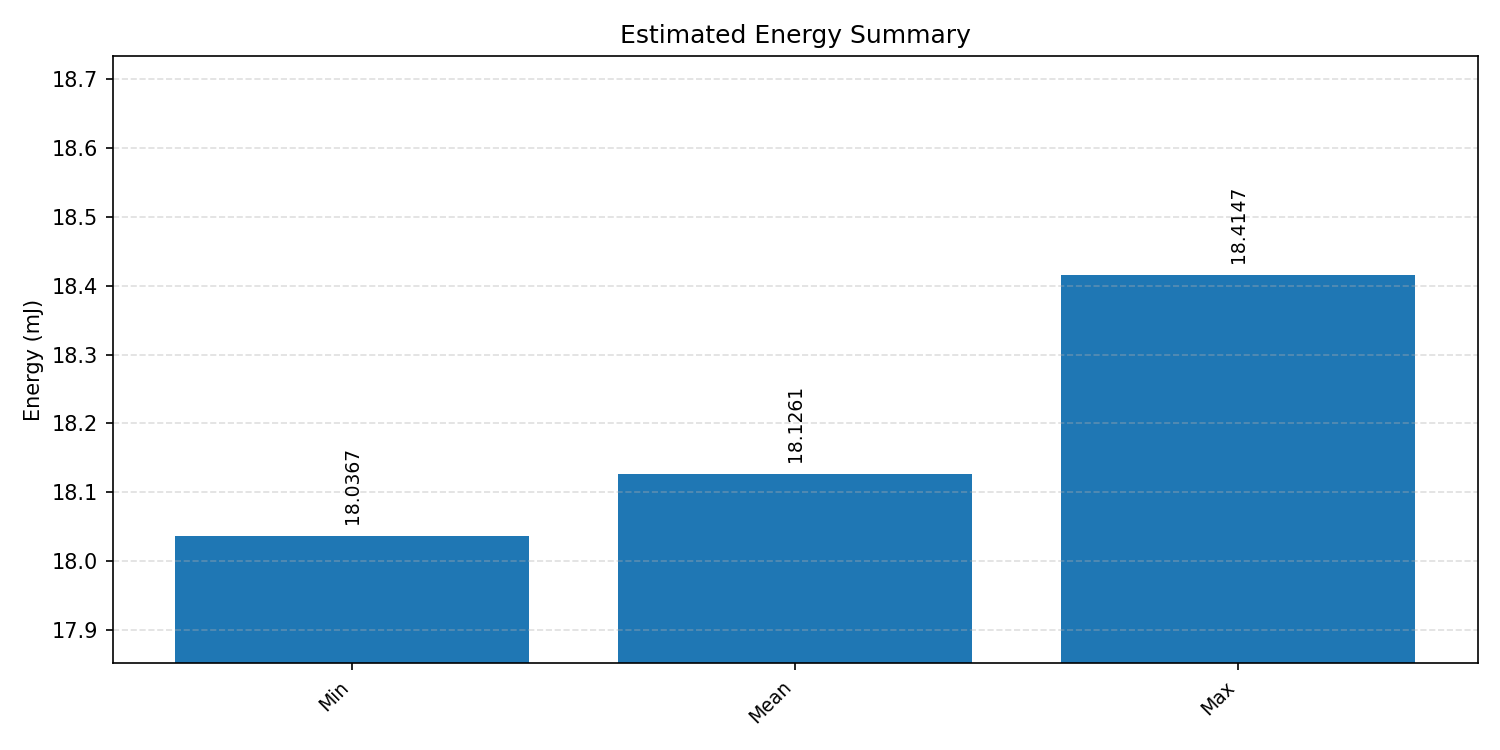
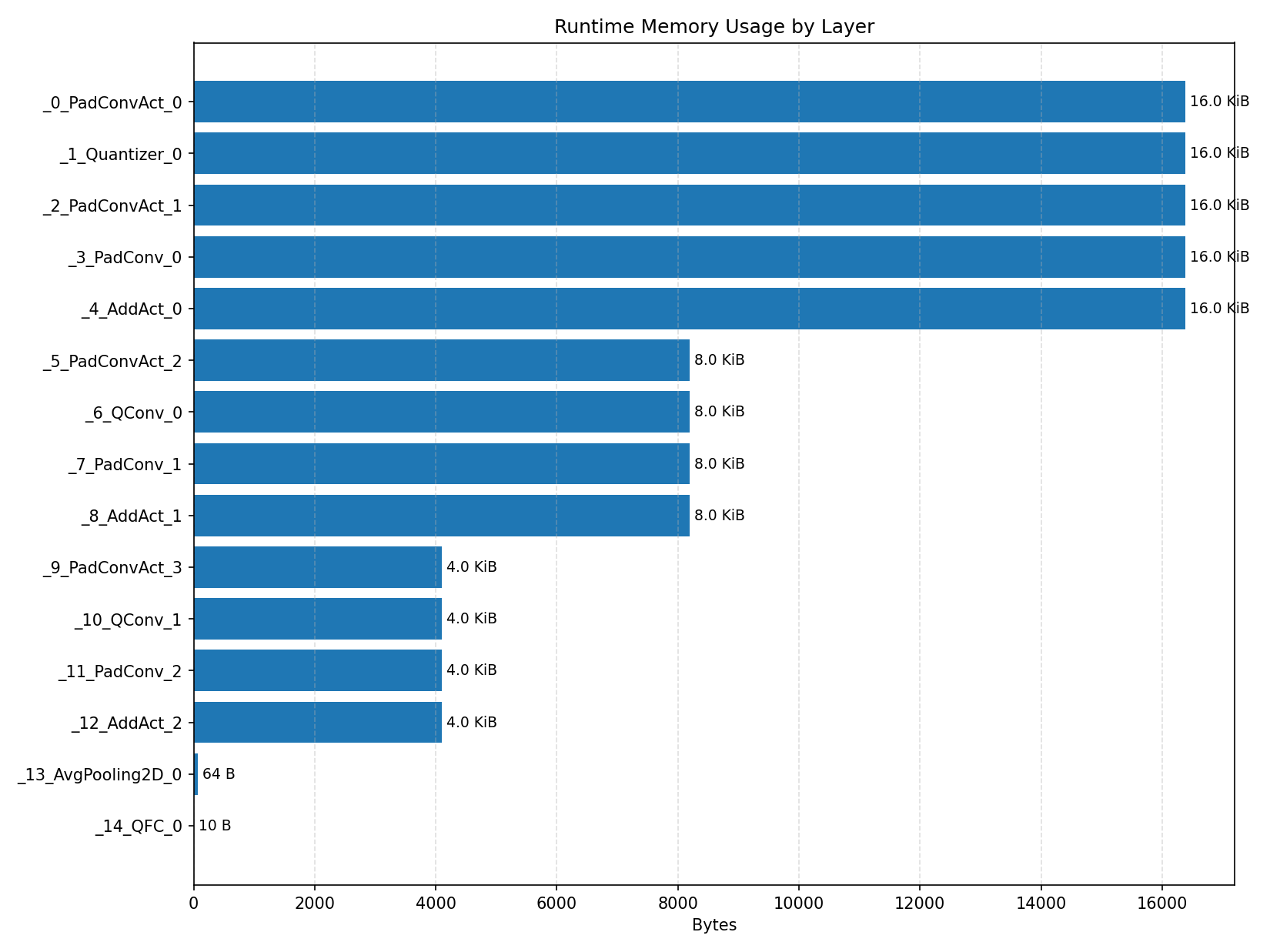
#4.4 DS-CNN#
Comparison Chart
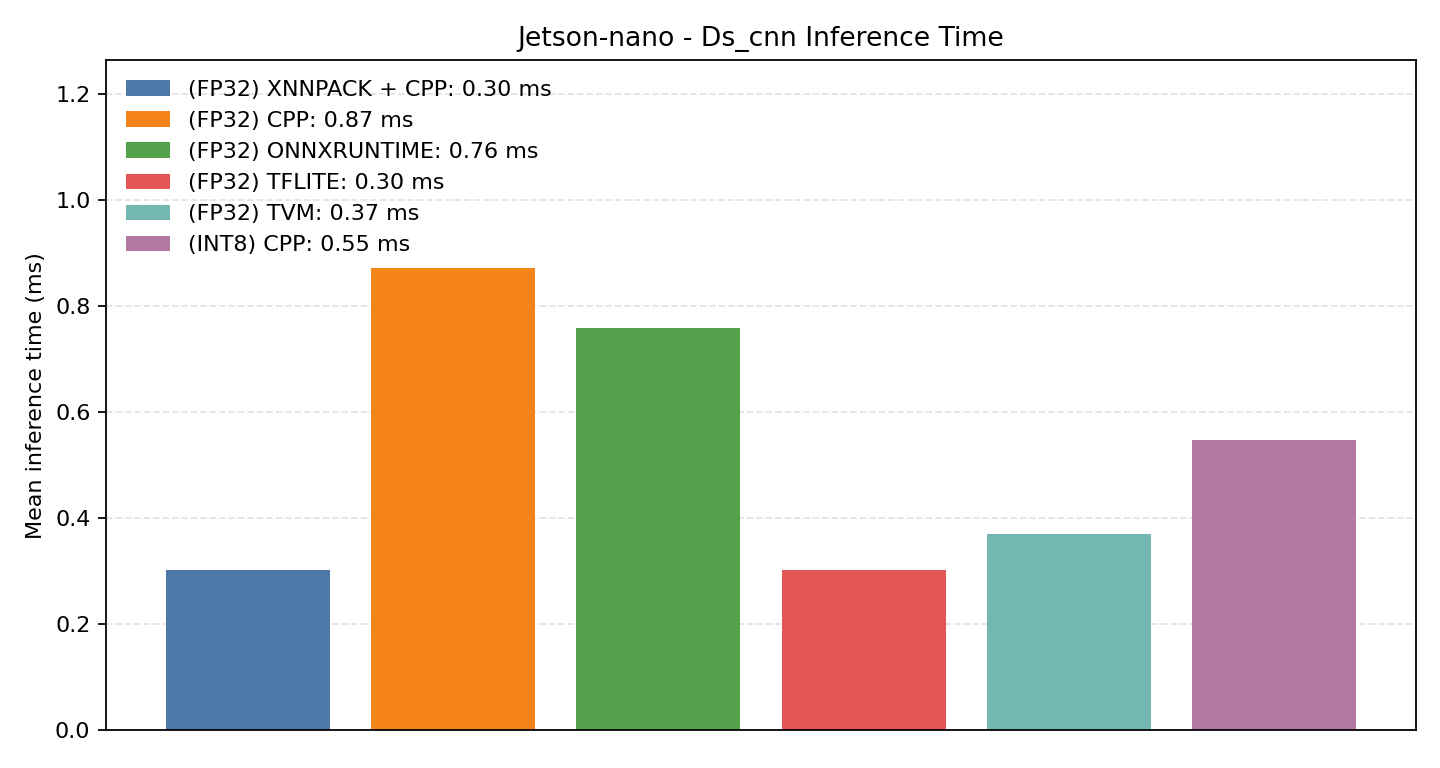
#4.4.1 (FP32) CPP#
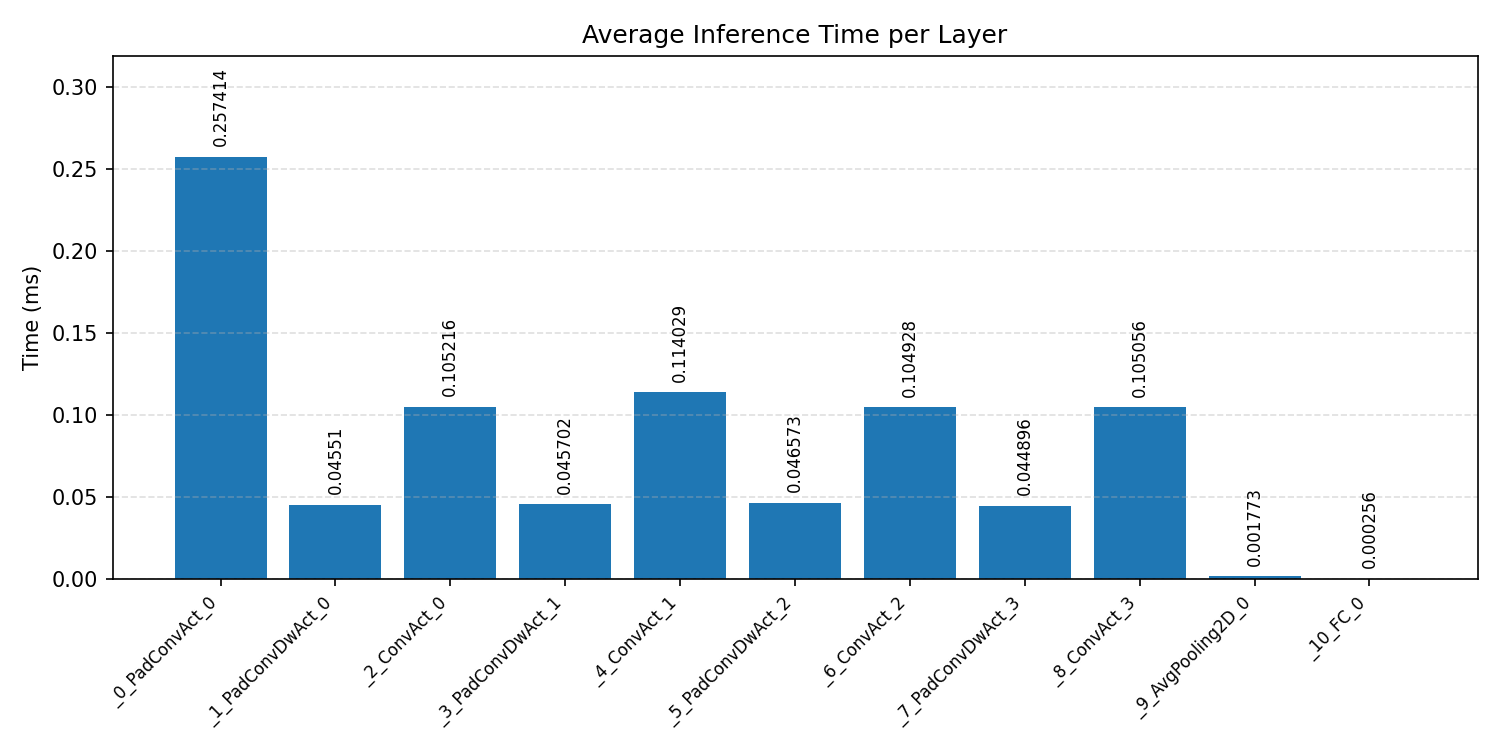
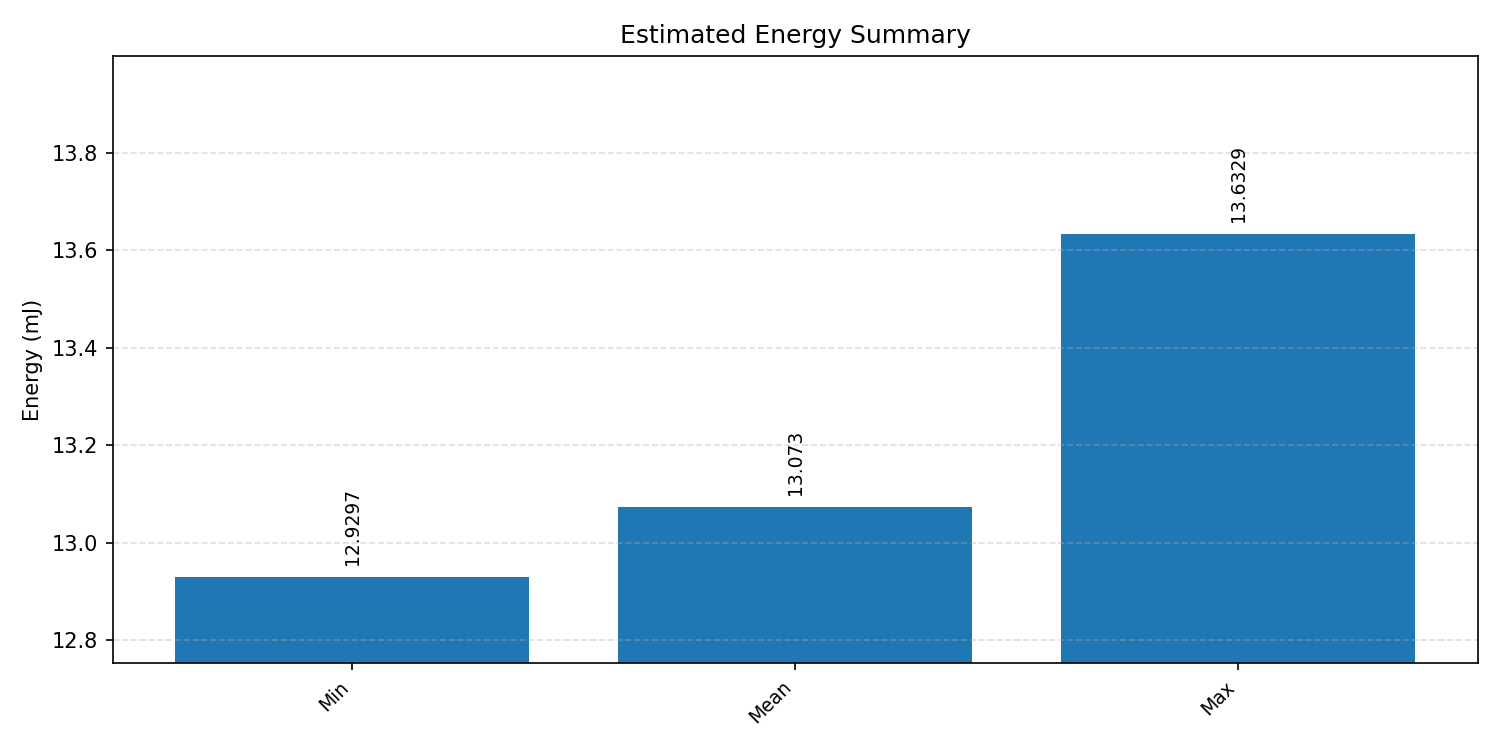
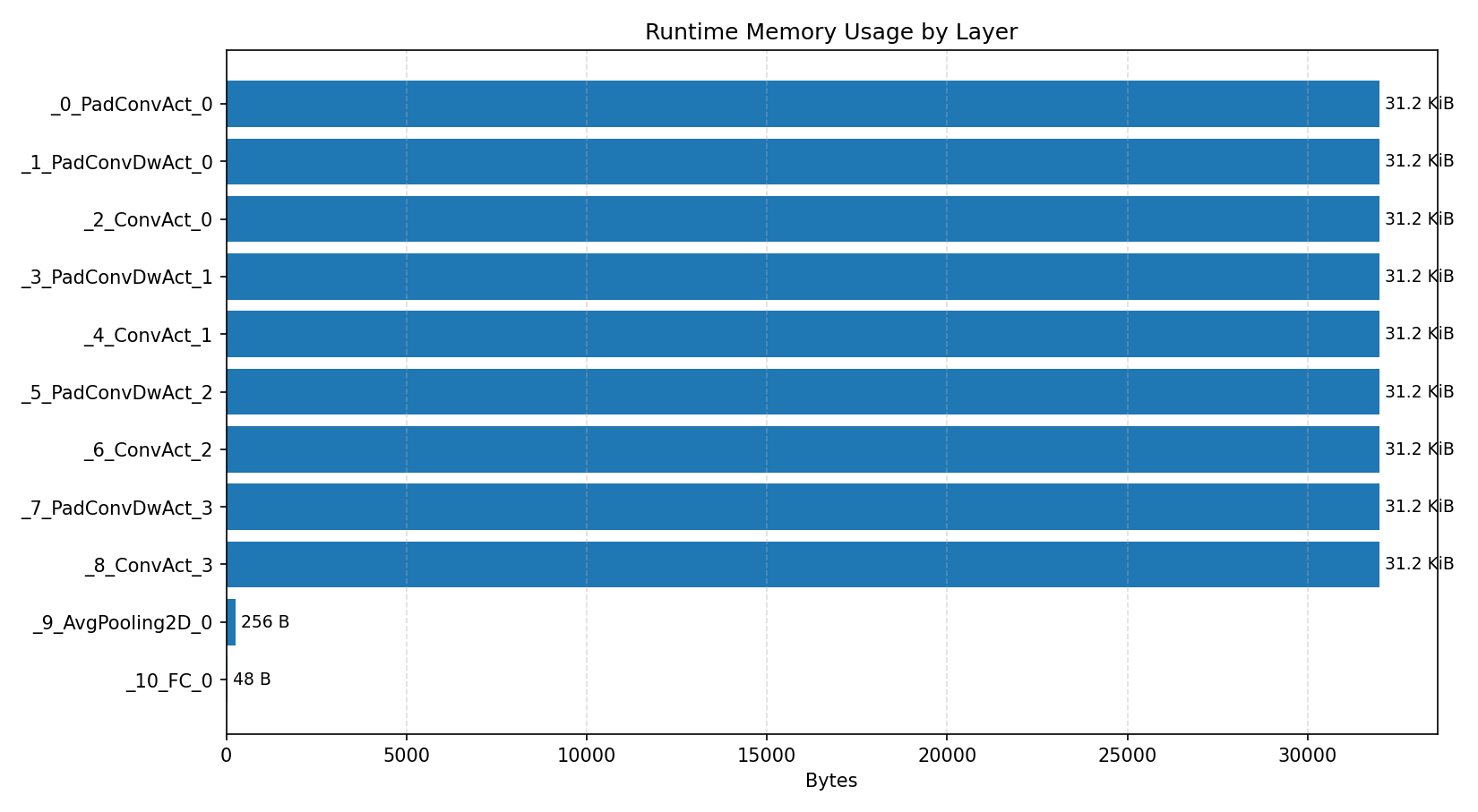
#4.4.2 (FP32) XNNPACK + CPP#
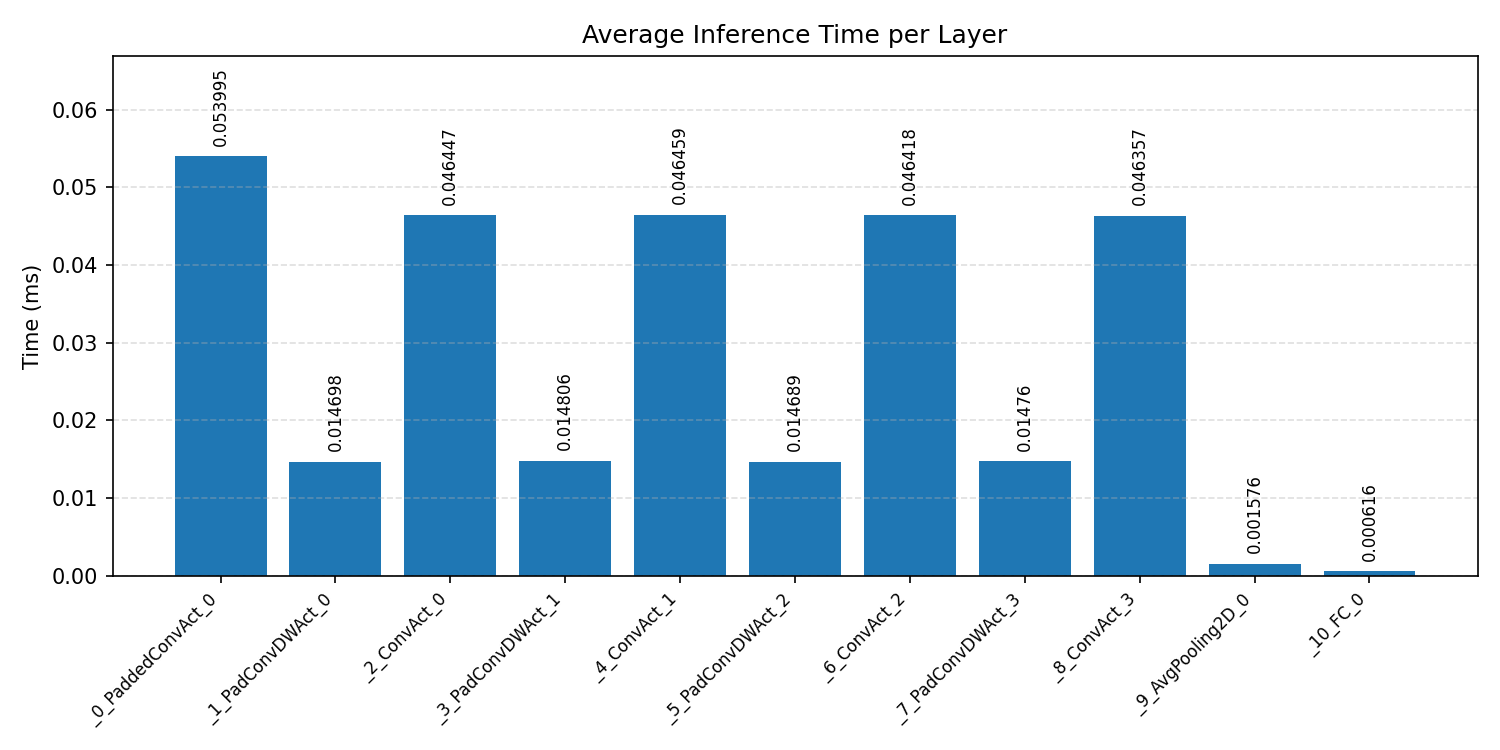
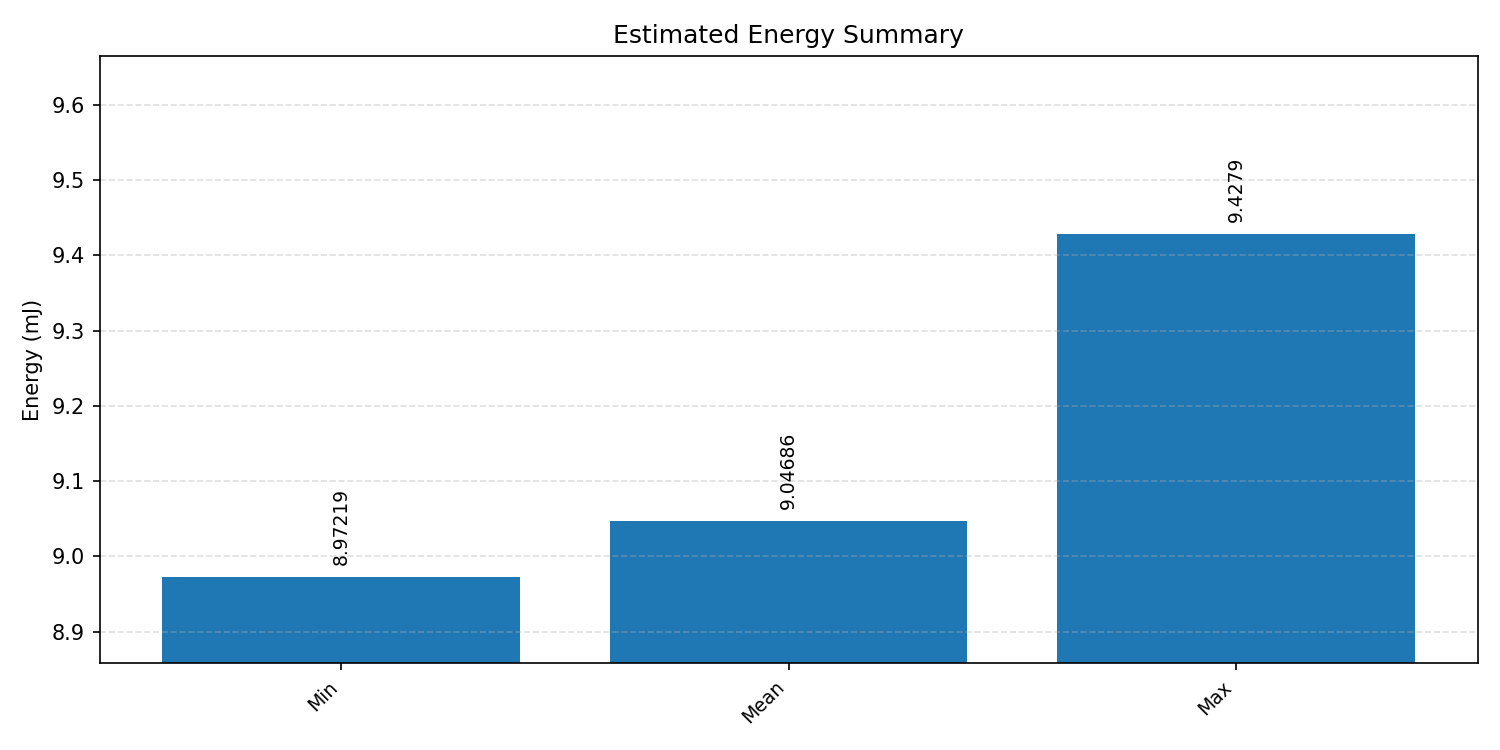
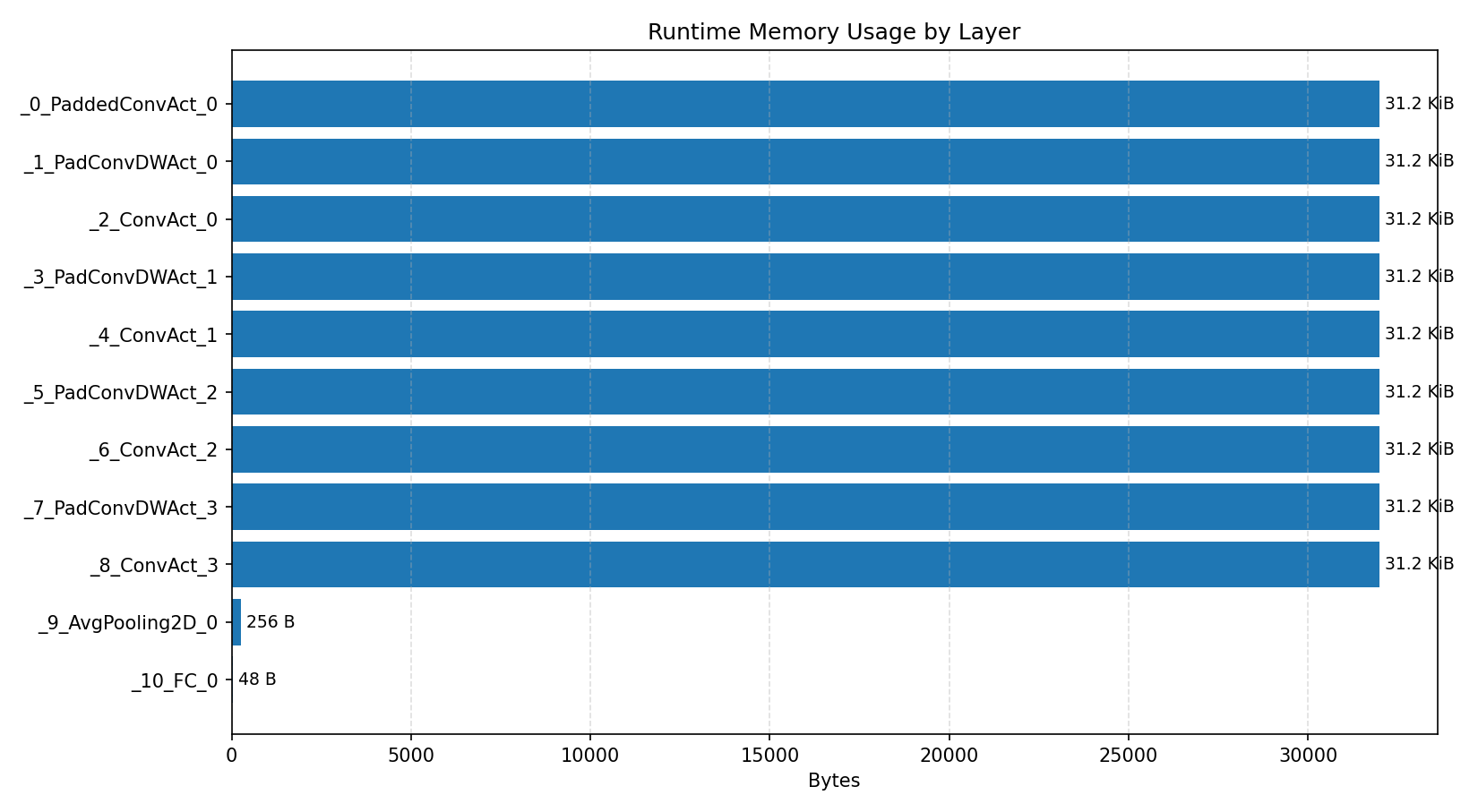
#4.4.3 (INT8) CPP#
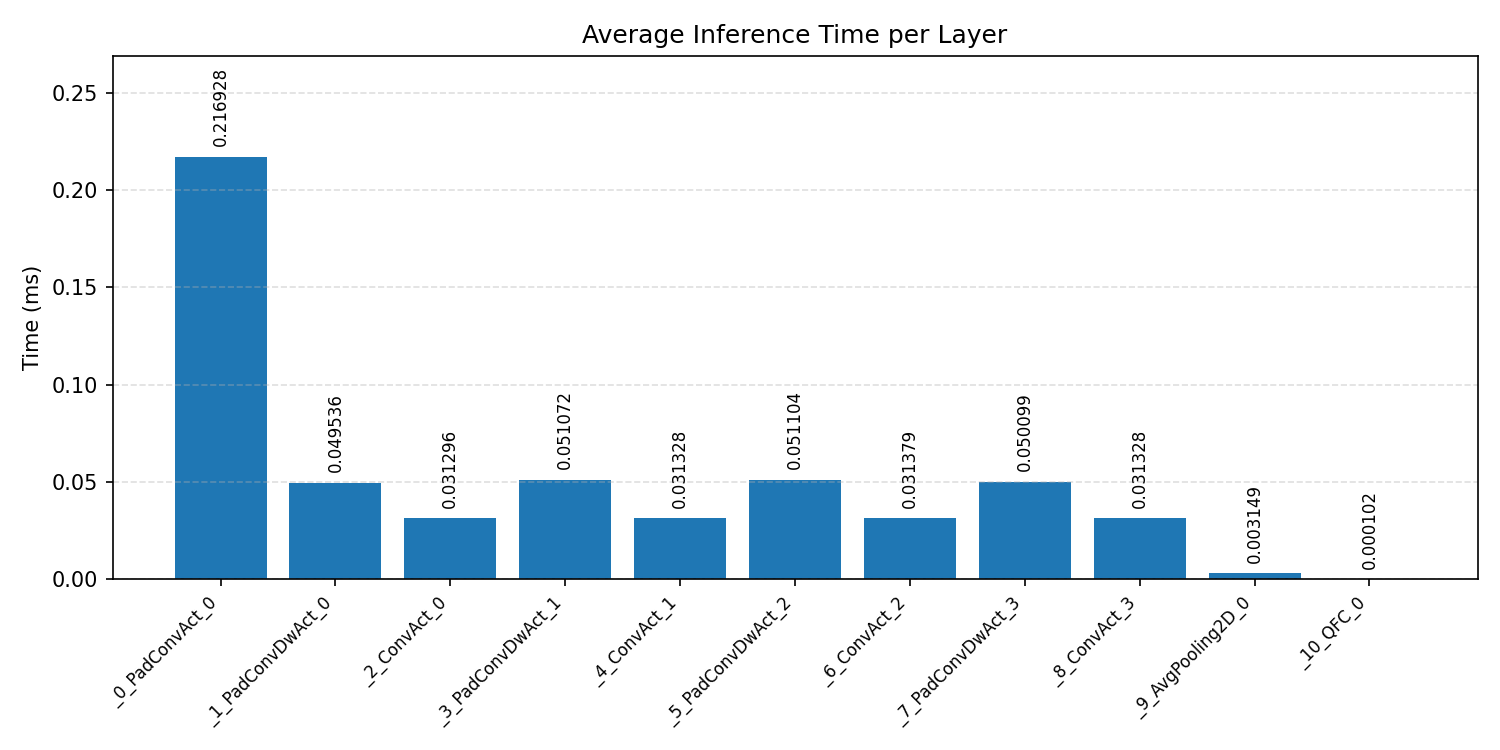
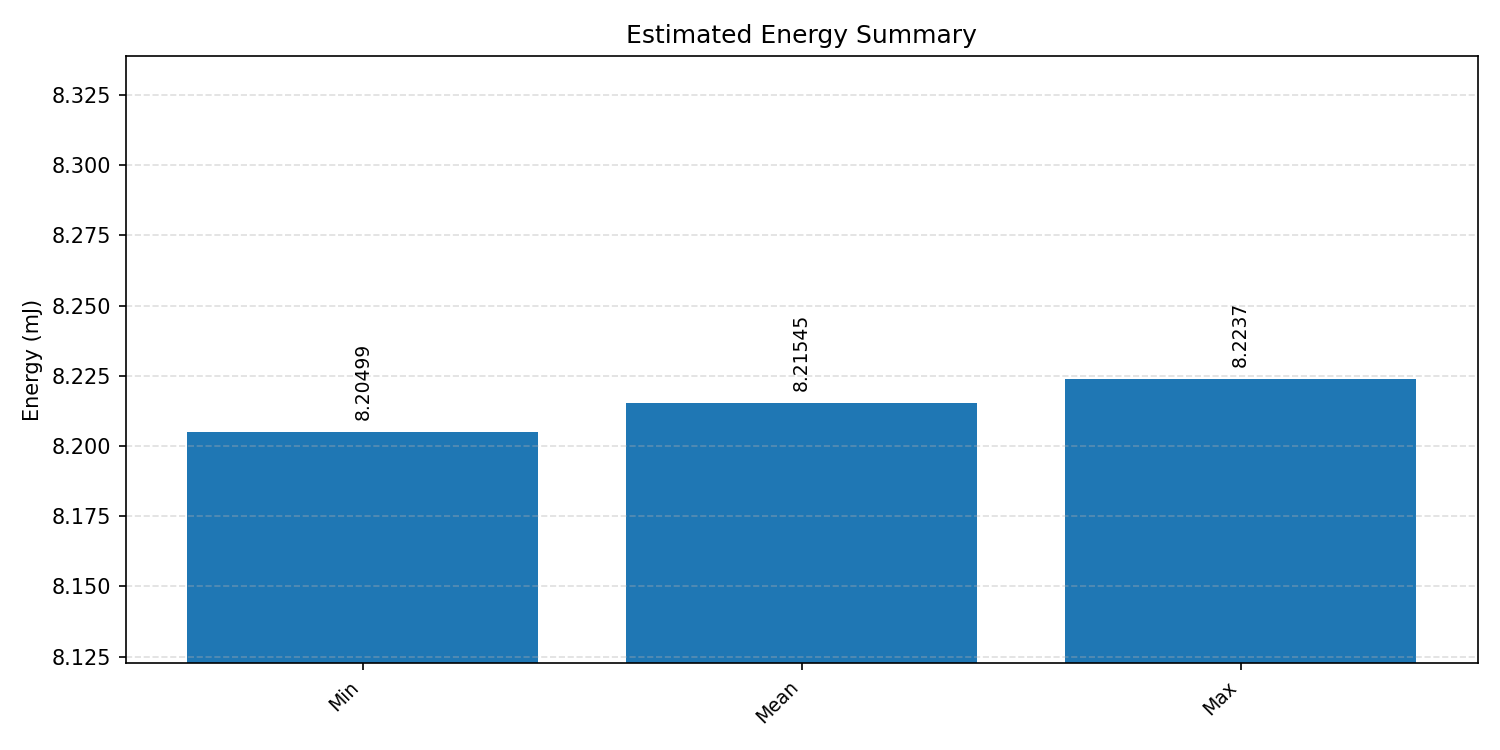
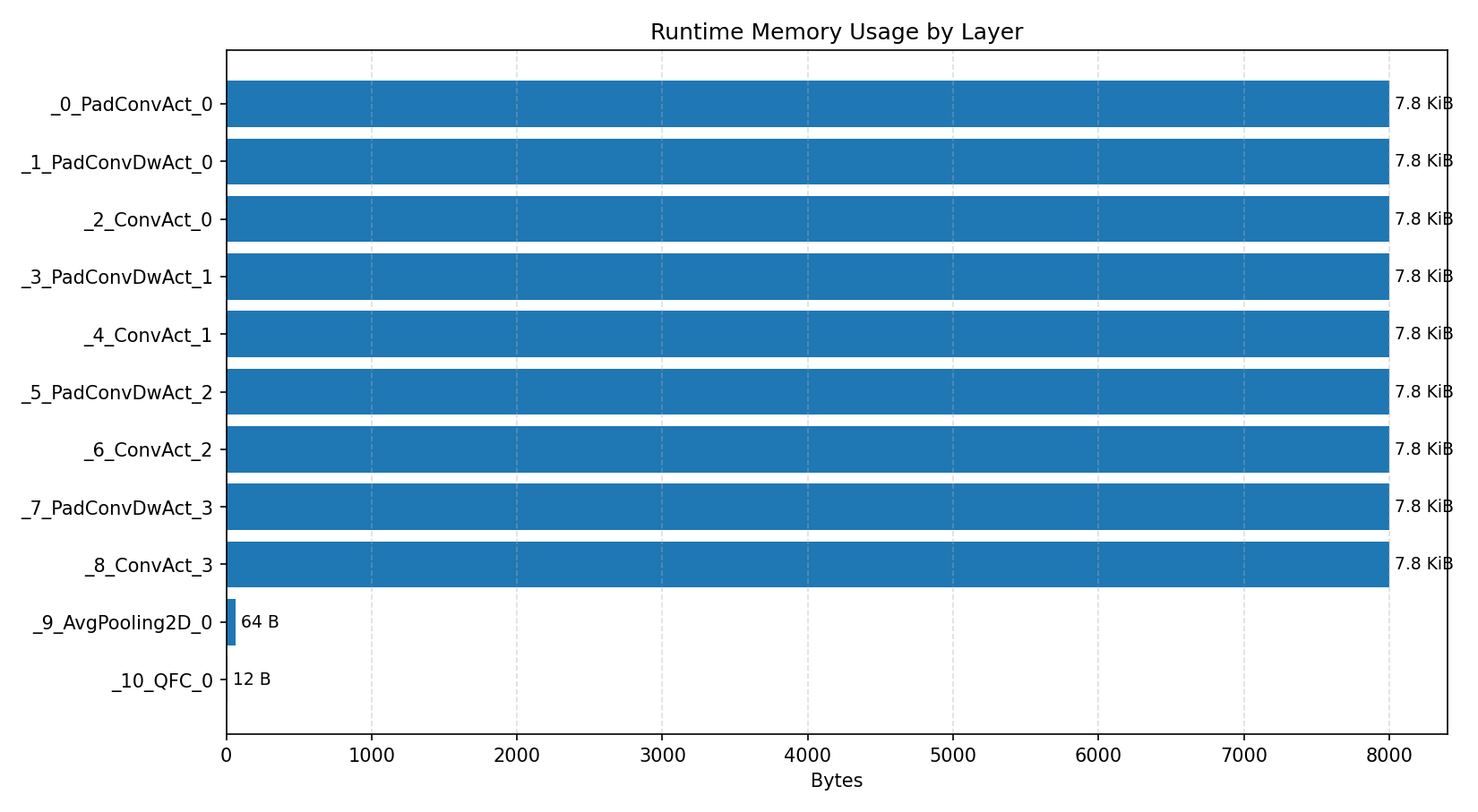
#4.5 Deep autoencoder#
Comparison Chart
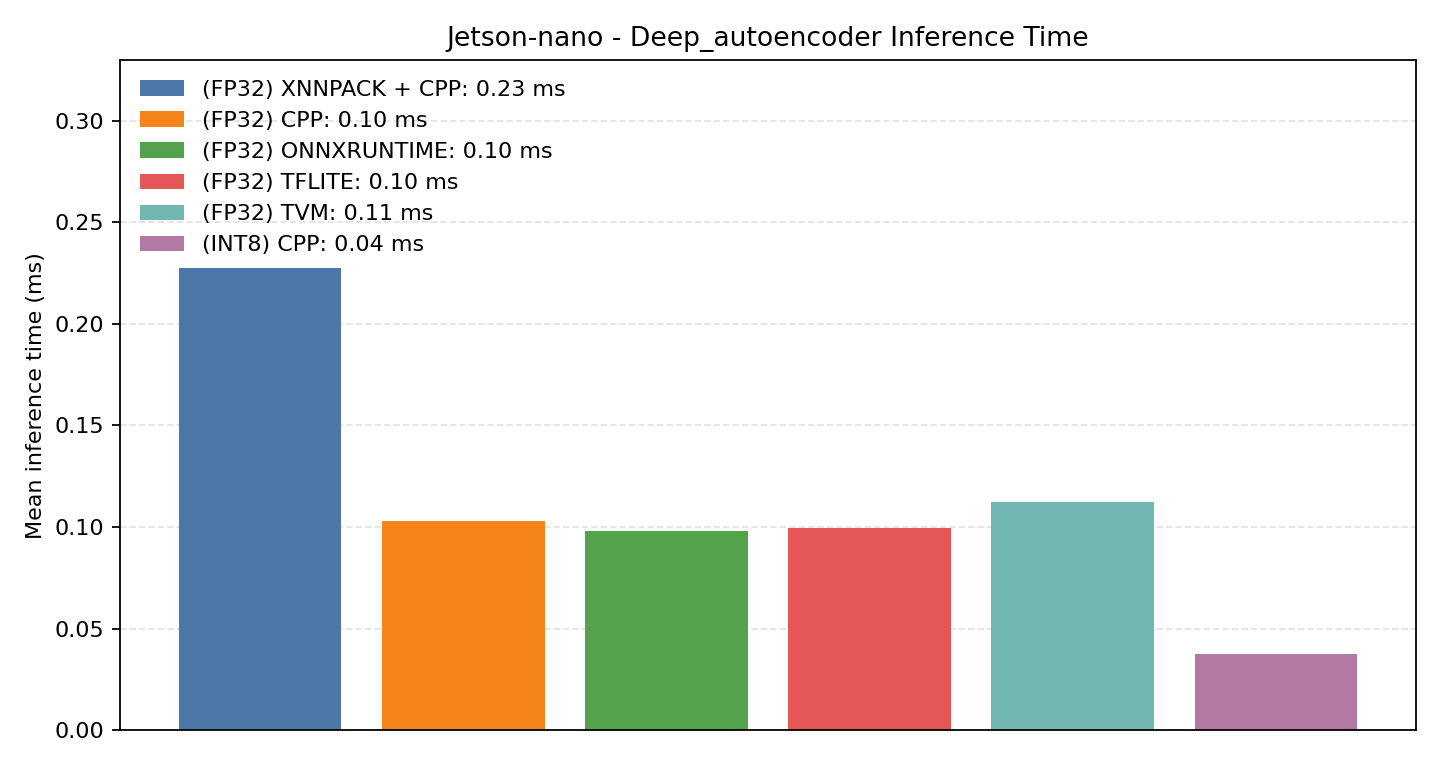
#4.5.1 (FP32) CPP#
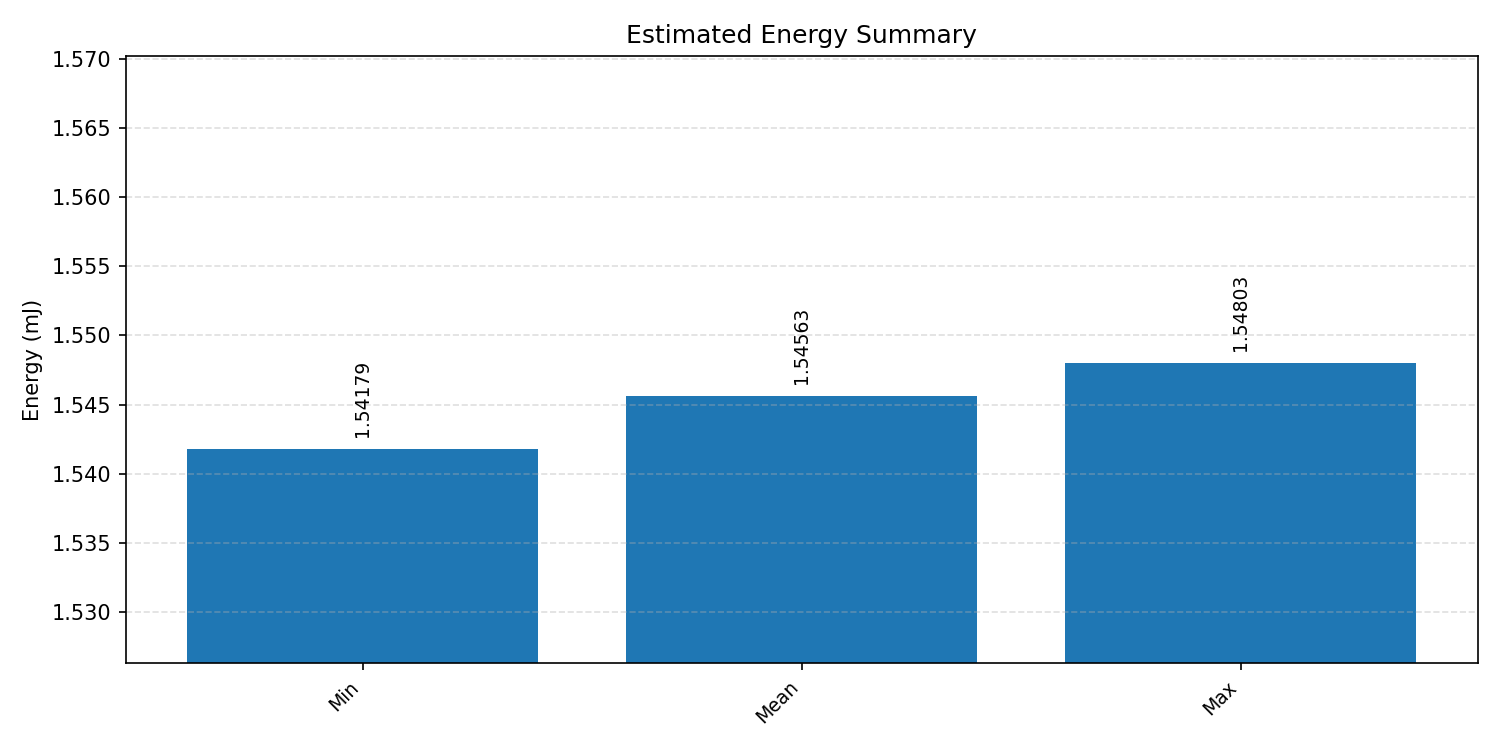
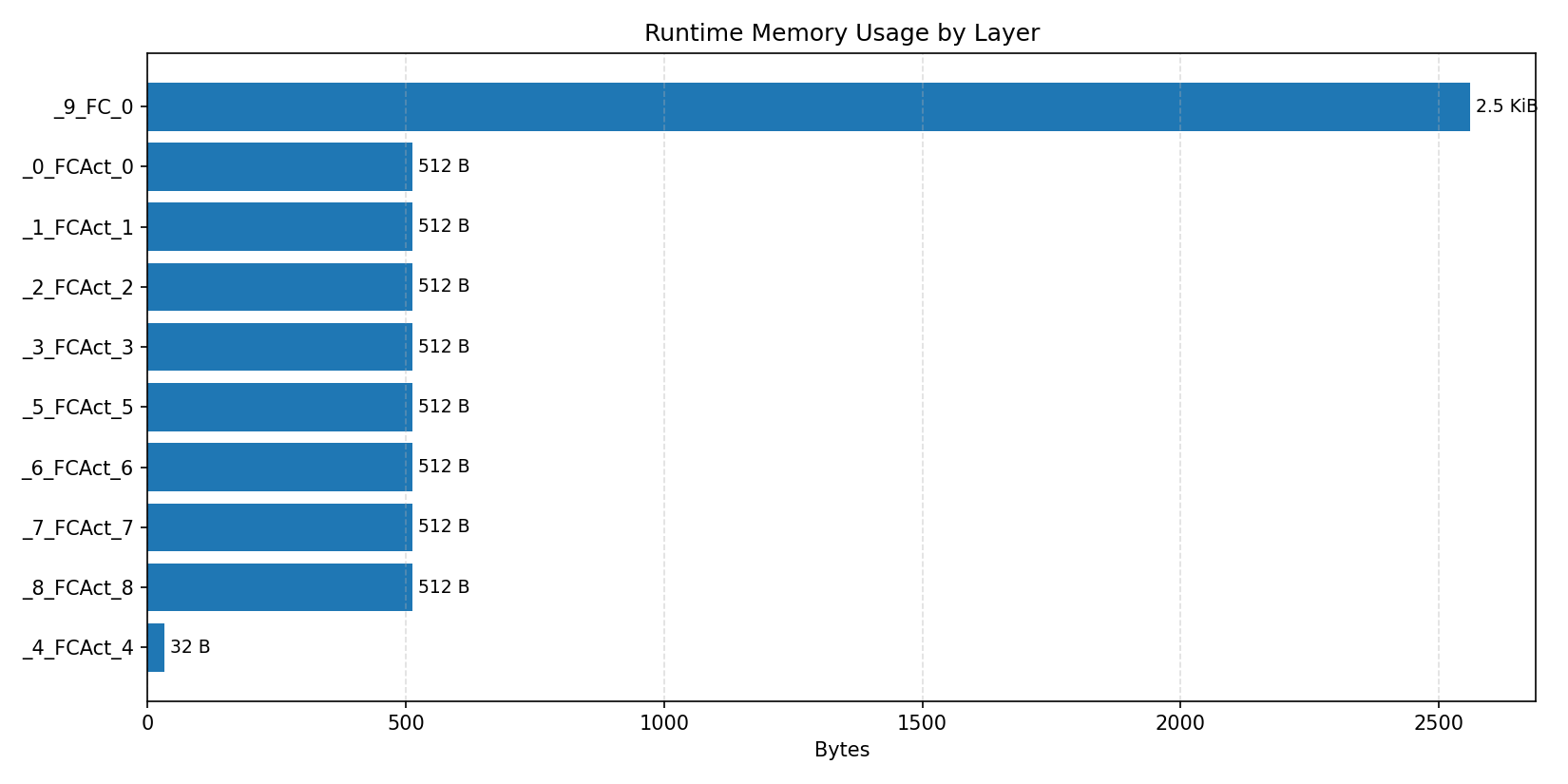
#4.5.2 (FP32) XNNPACK + CPP#
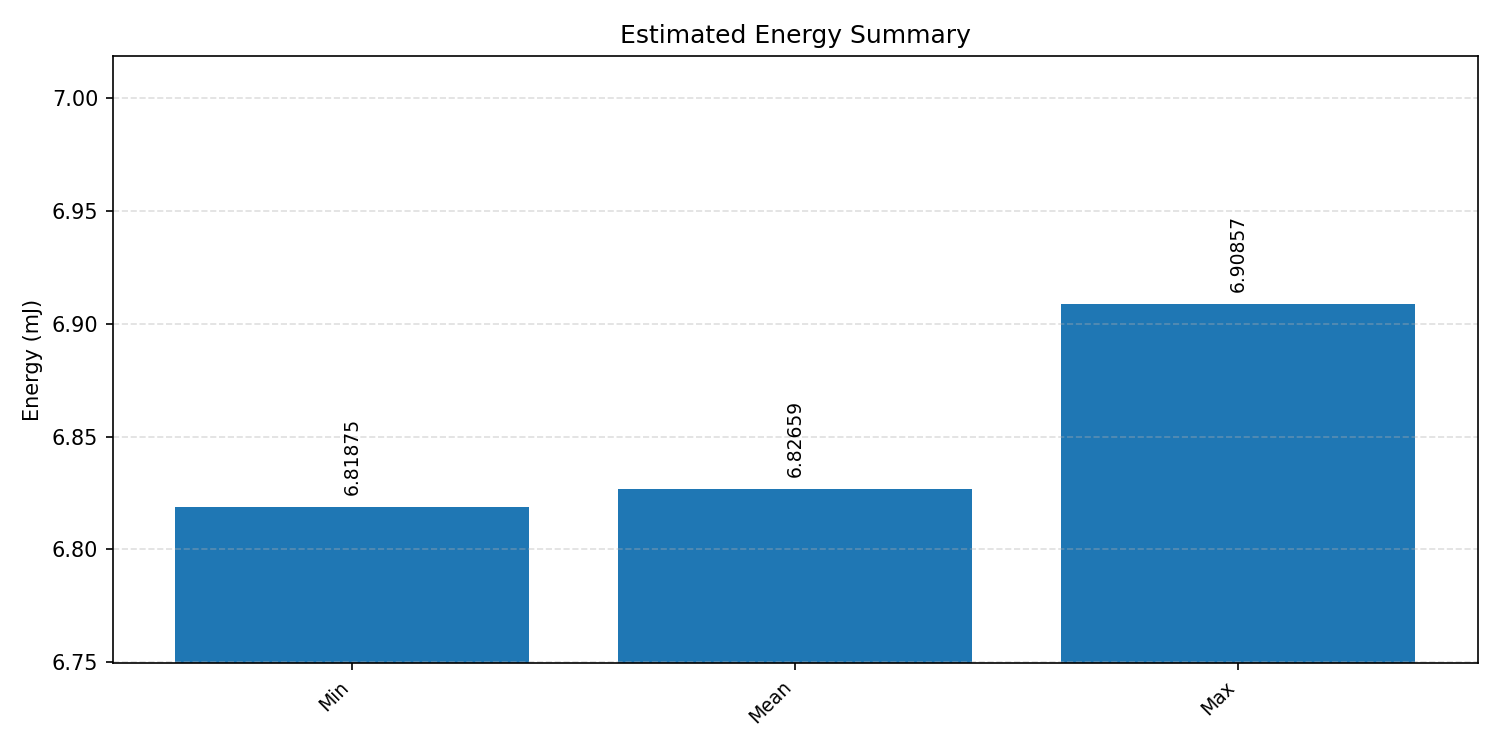
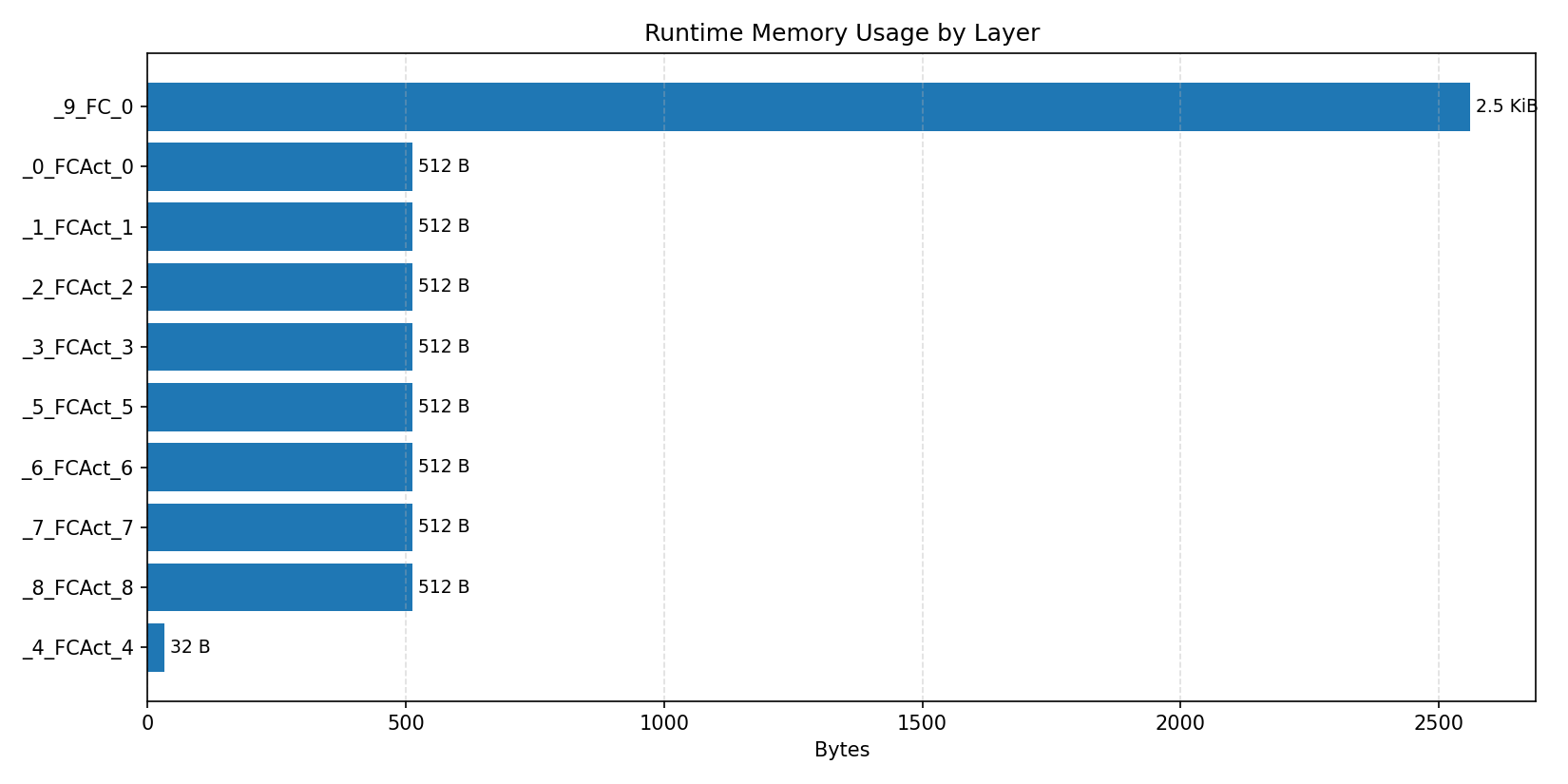
#4.5.3 (INT8) CPP#
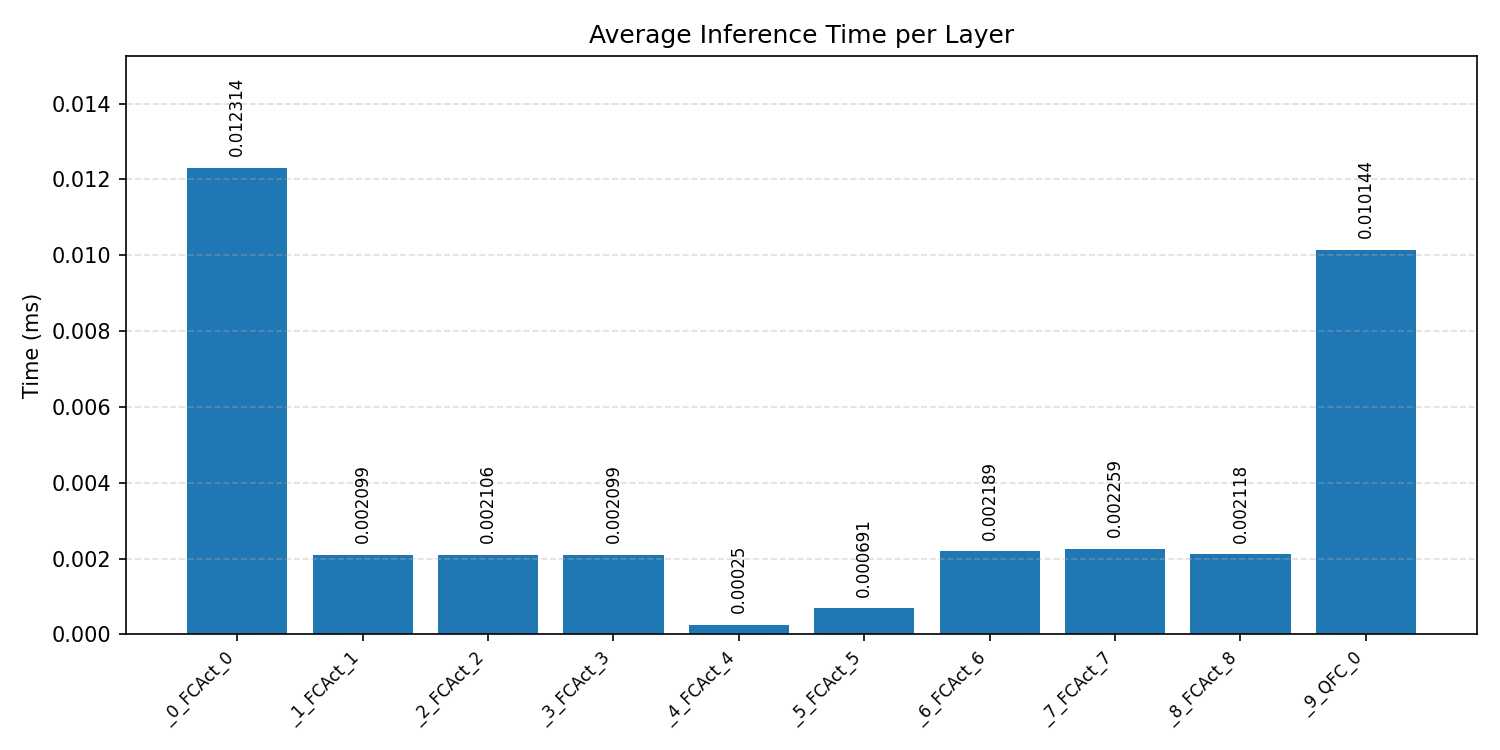
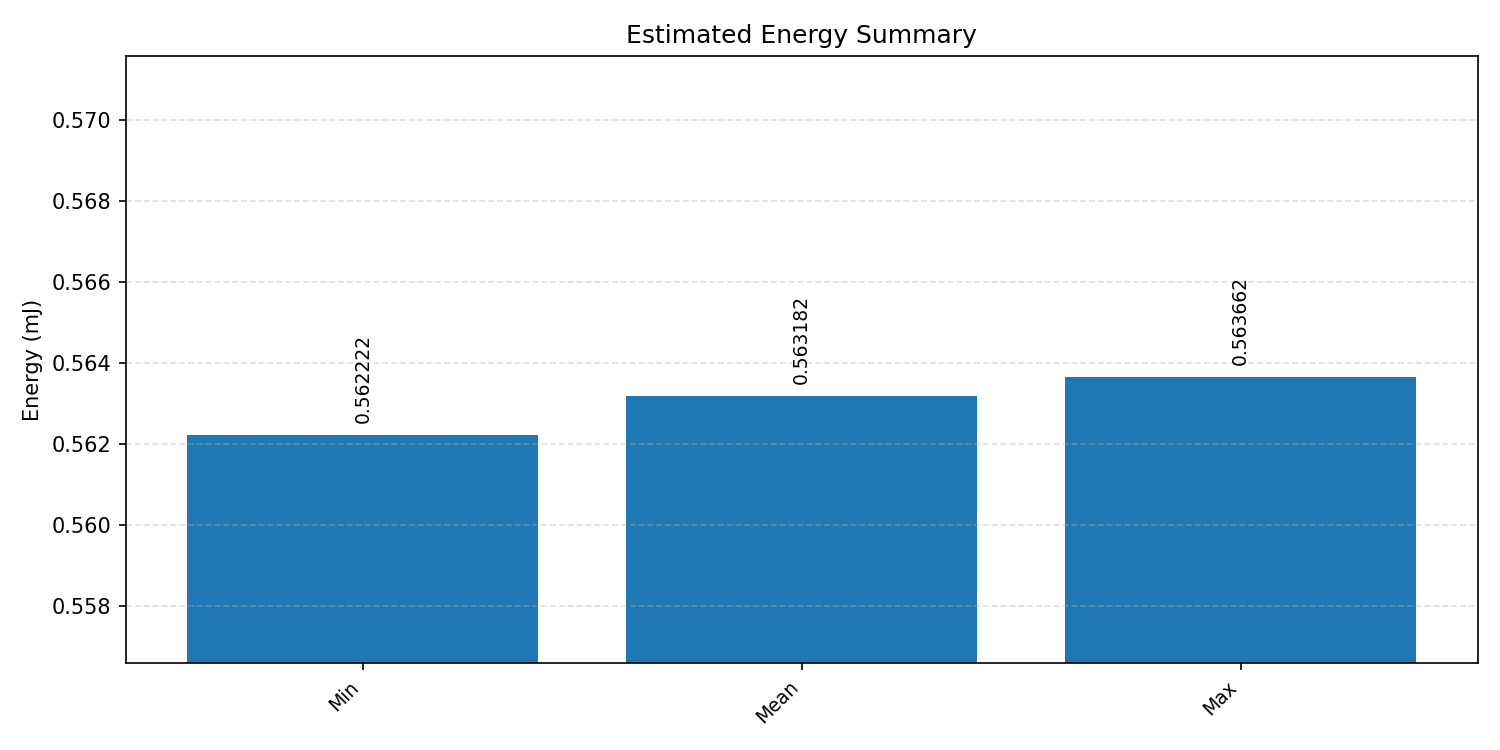
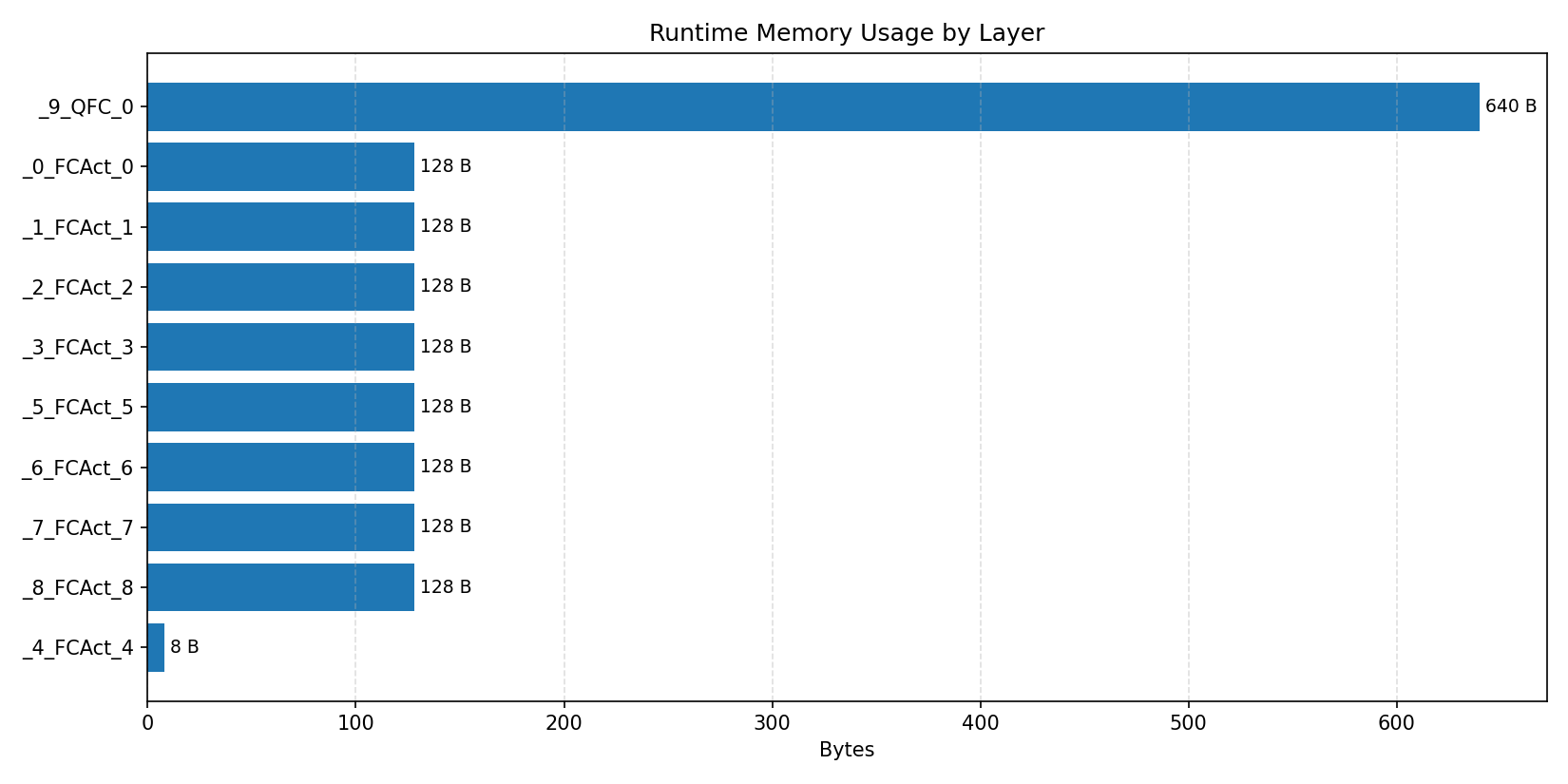
#4.6 ResNet18#
ResNet18 is a larger residual network used here to compare runtime strategies on edge-Linux targets.
Comparison Chart
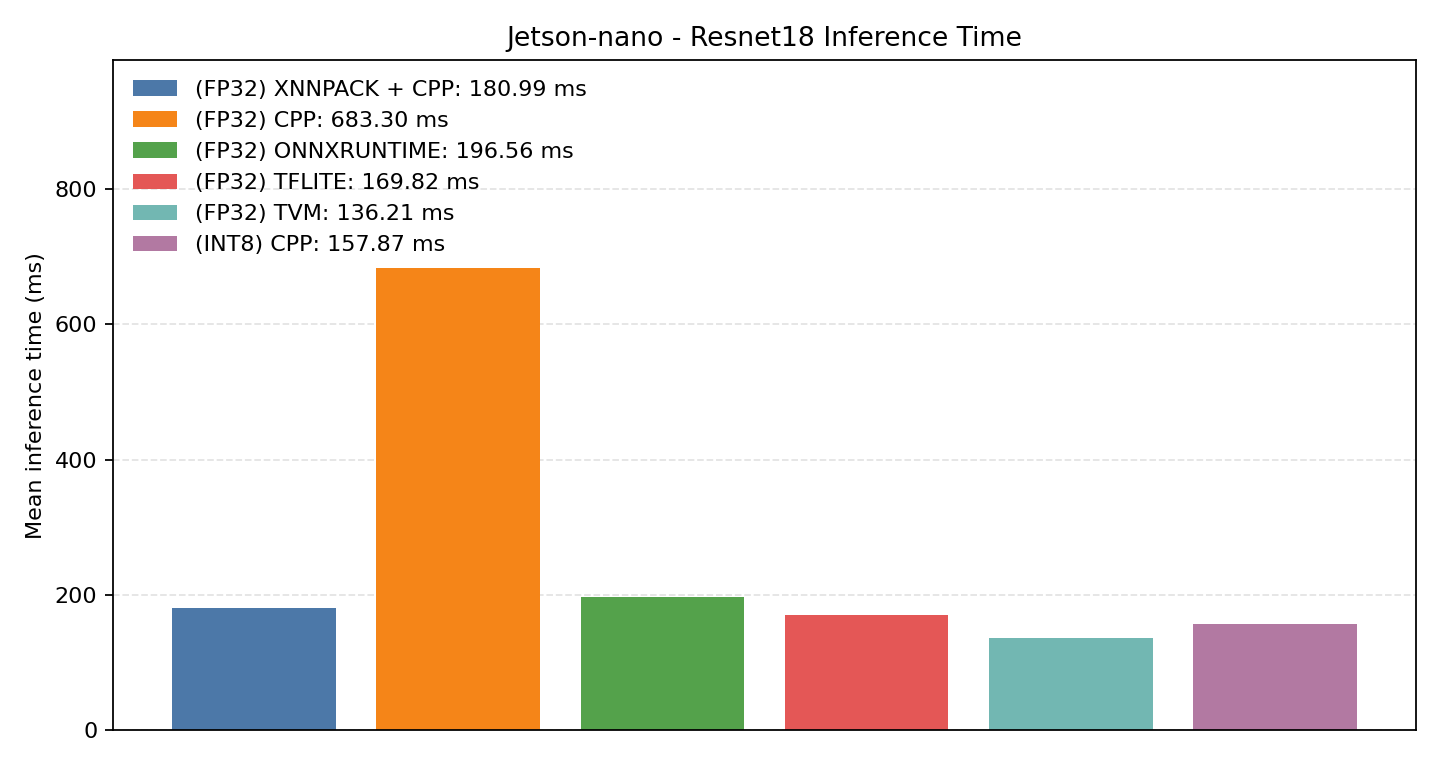
#4.6.1 (FP32) CPP#
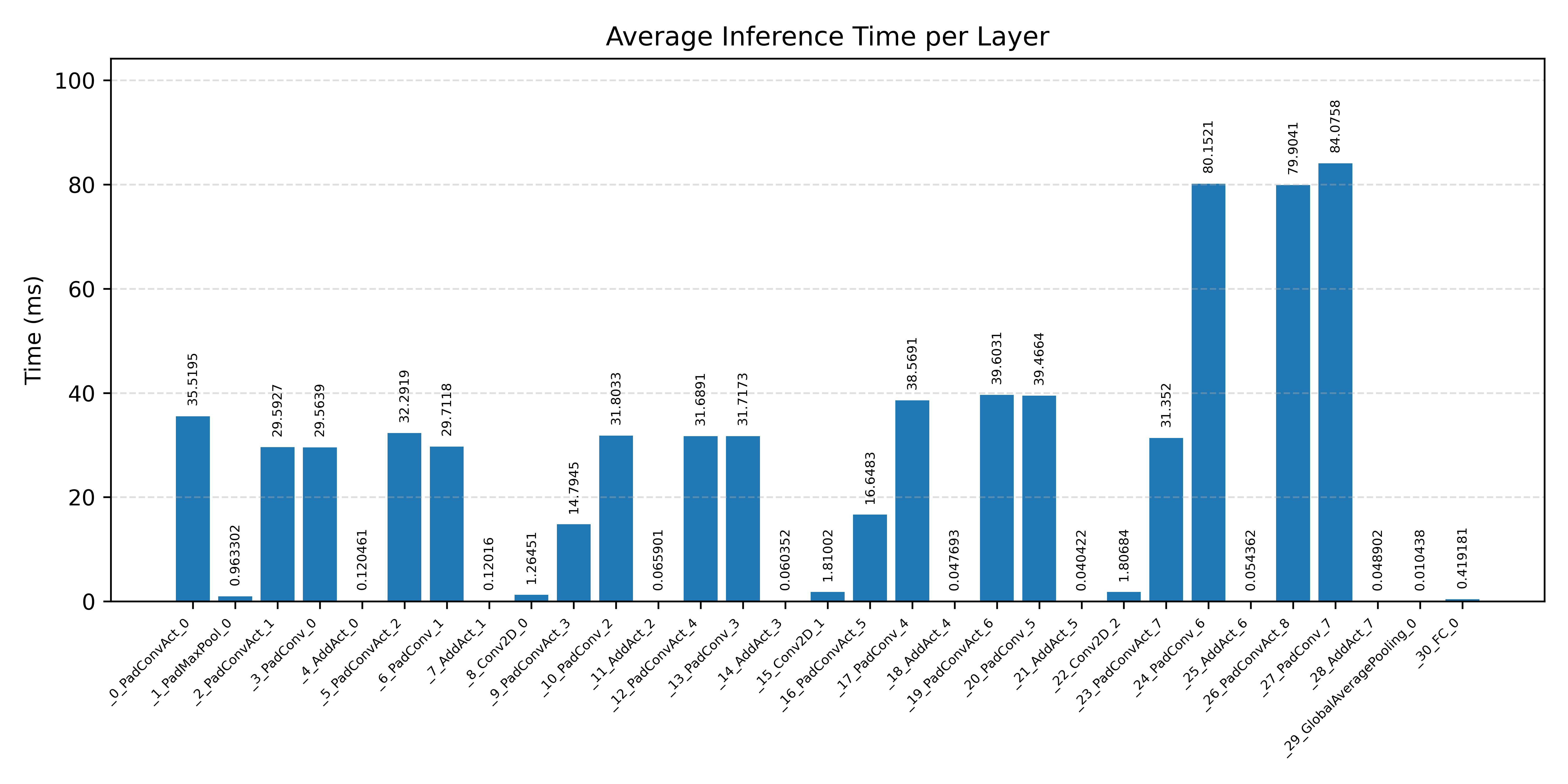
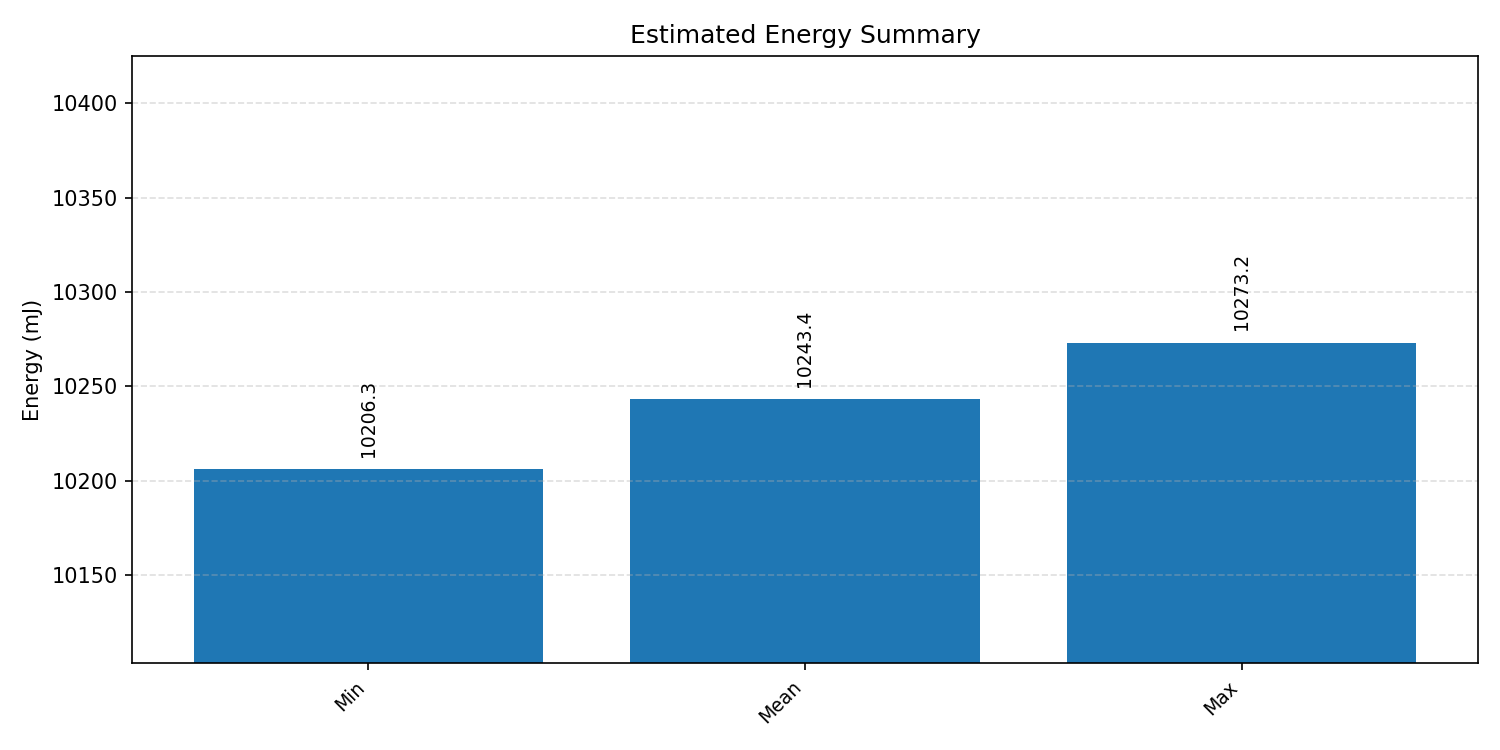
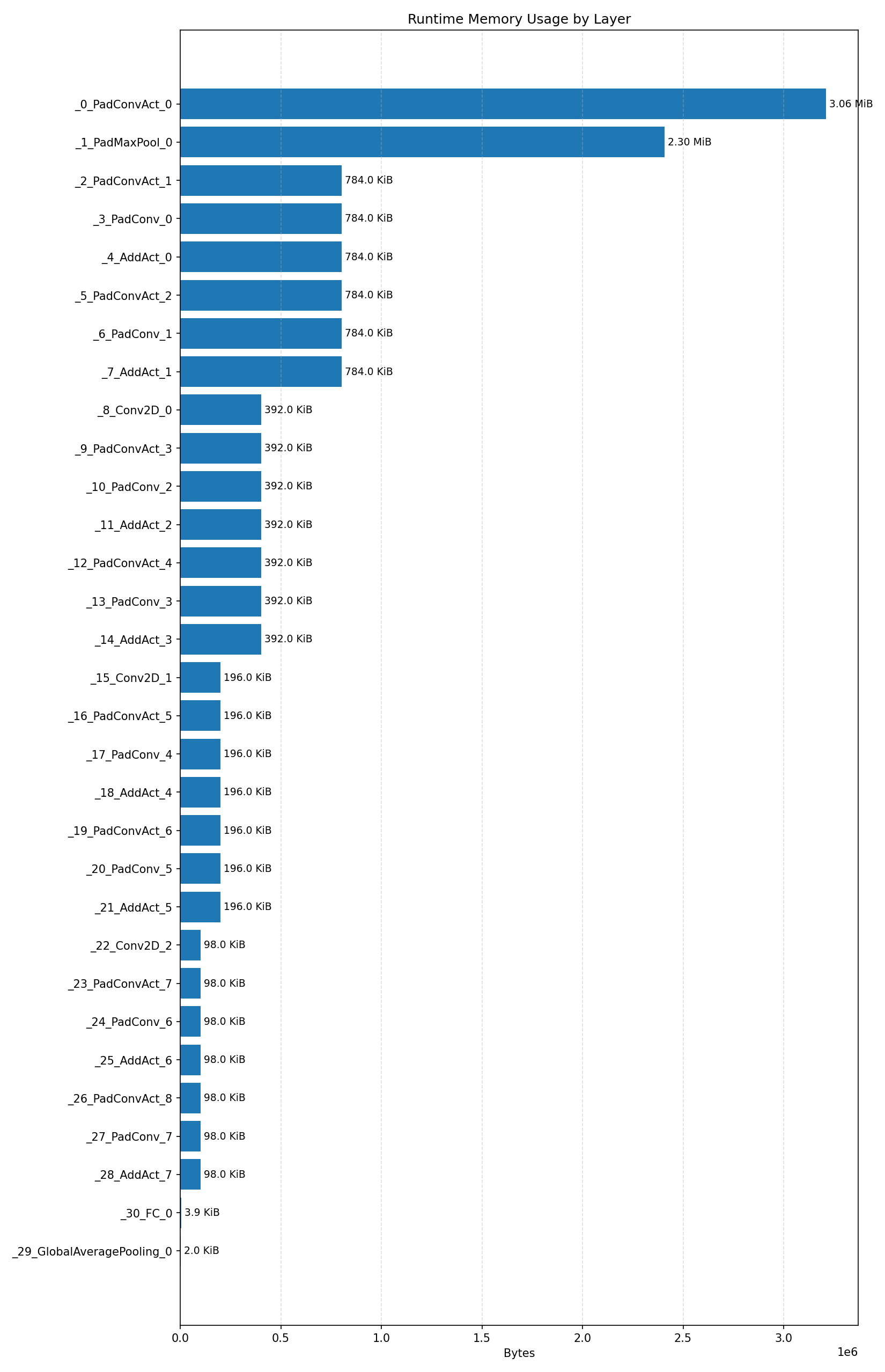
#4.6.2 (FP32) XNNPACK + CPP#
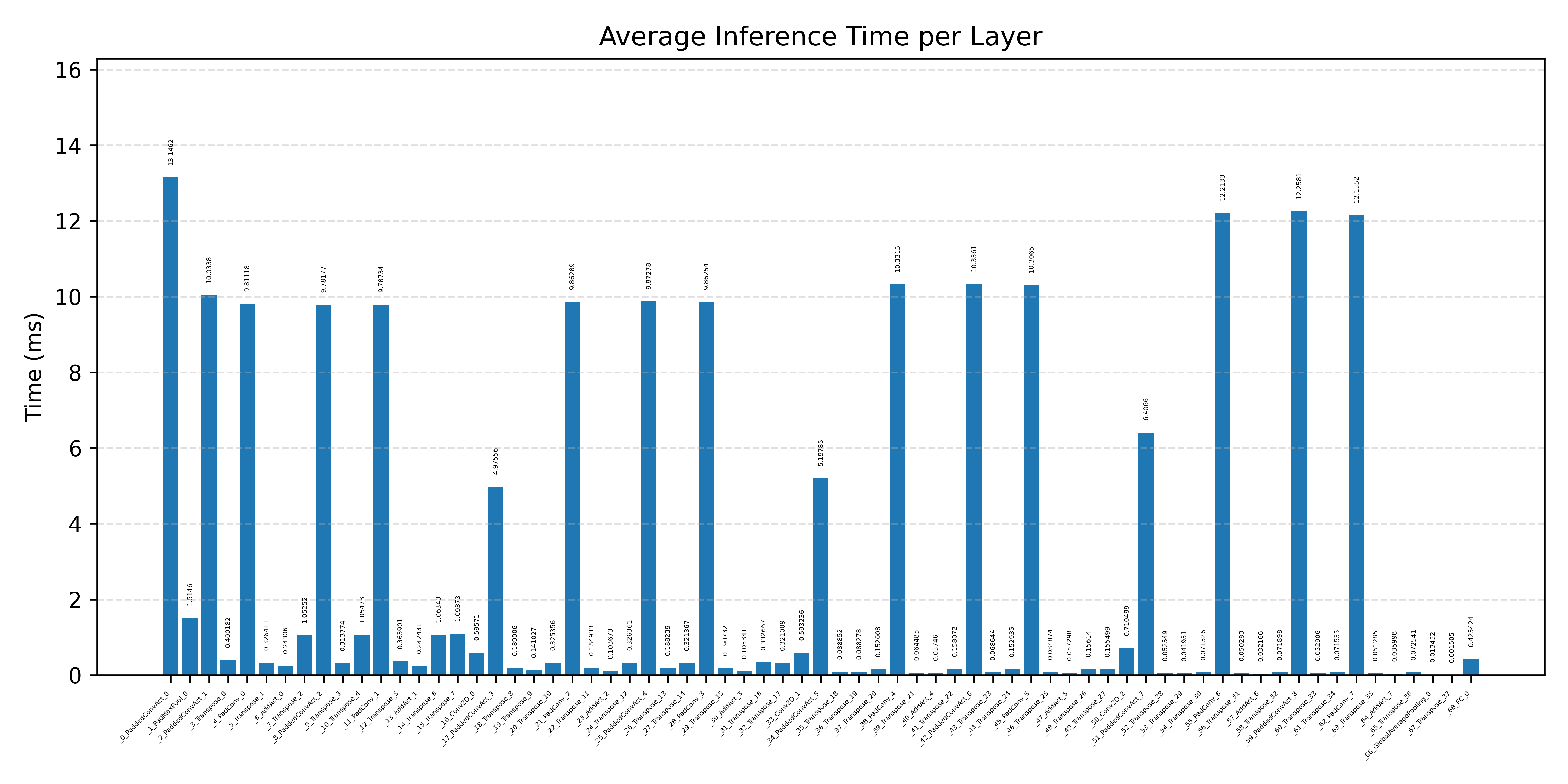
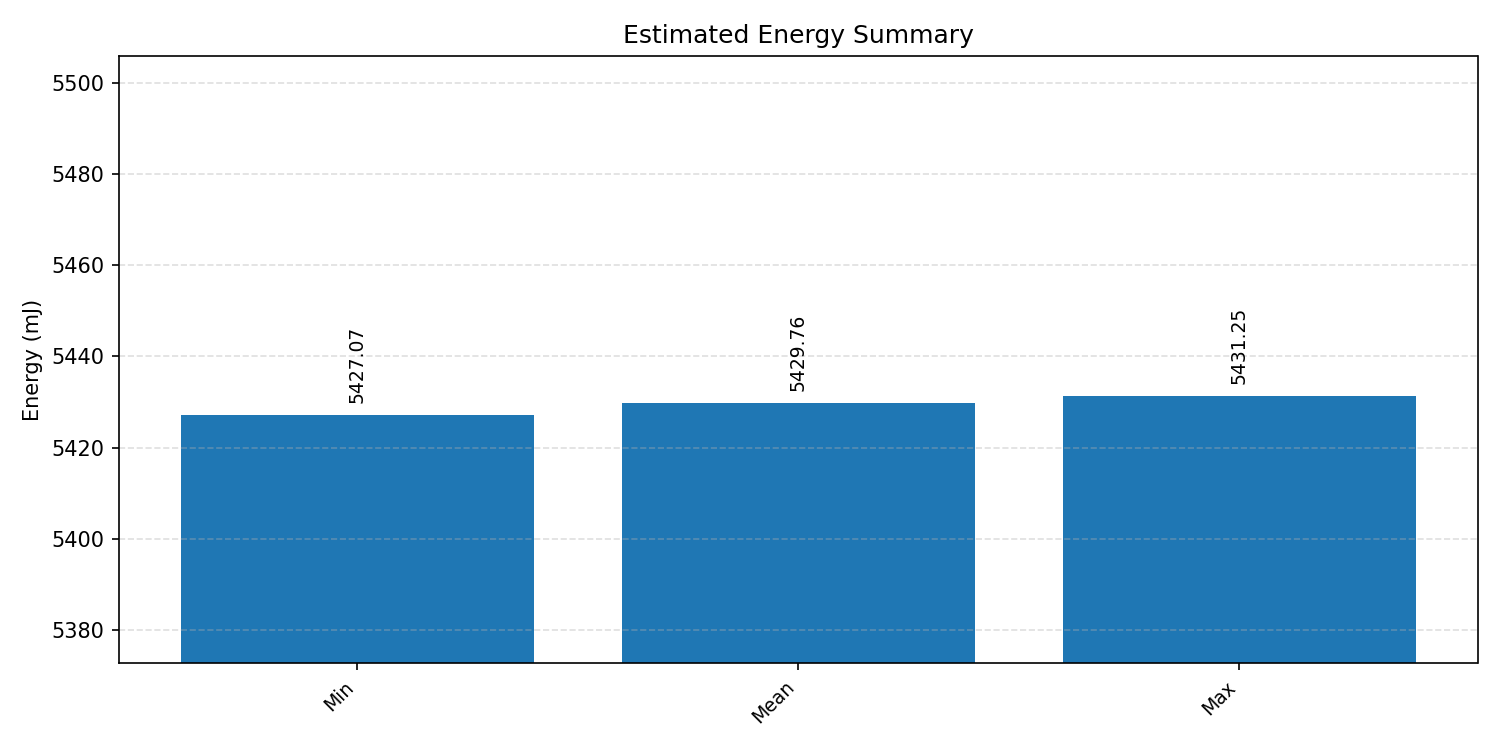
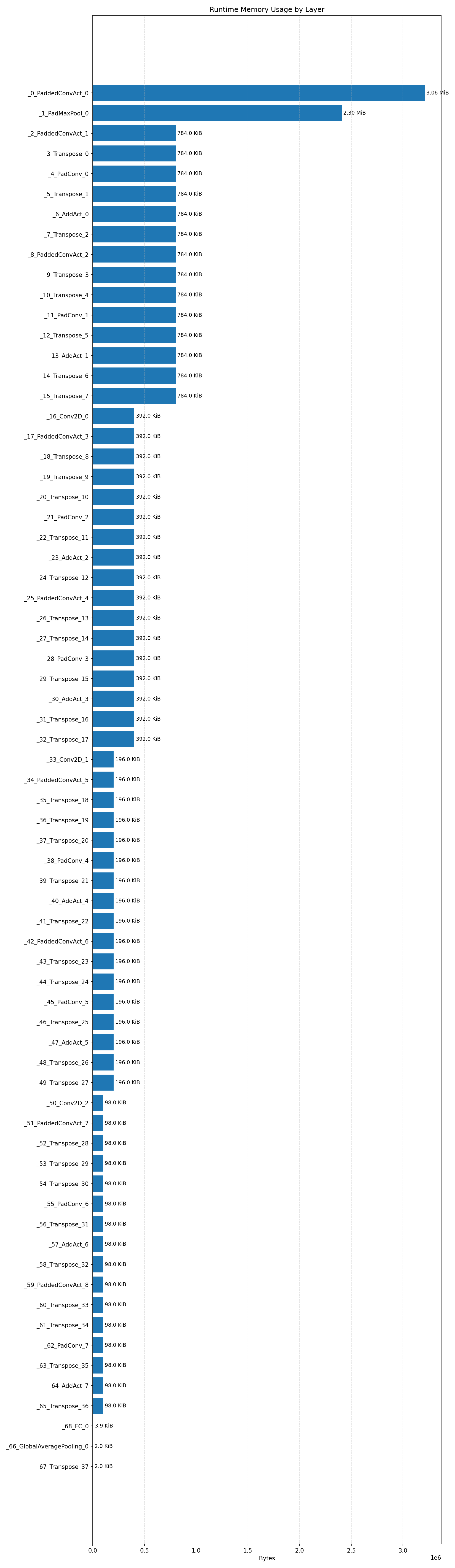
#4.6.3 (INT8) CPP#
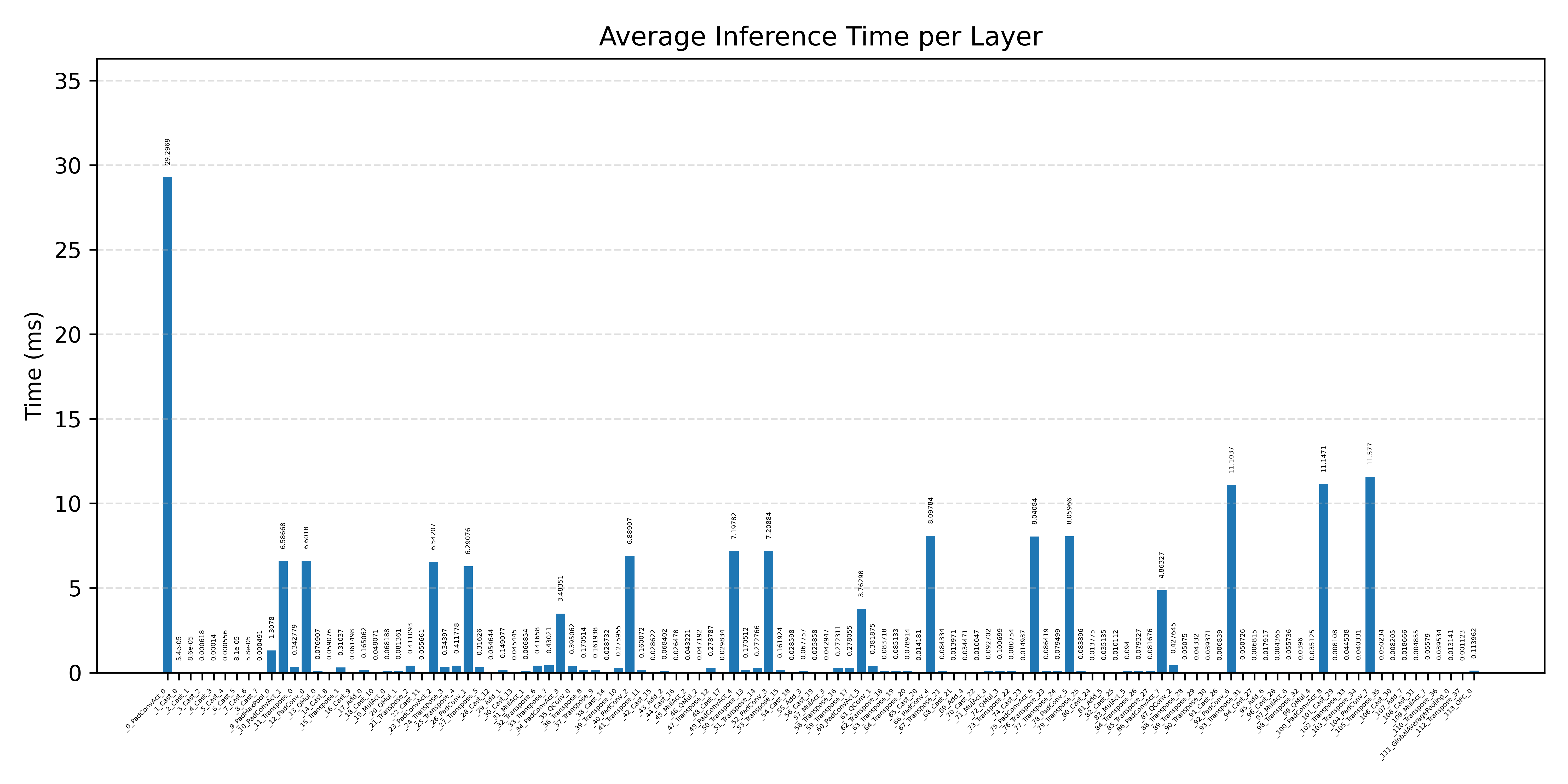
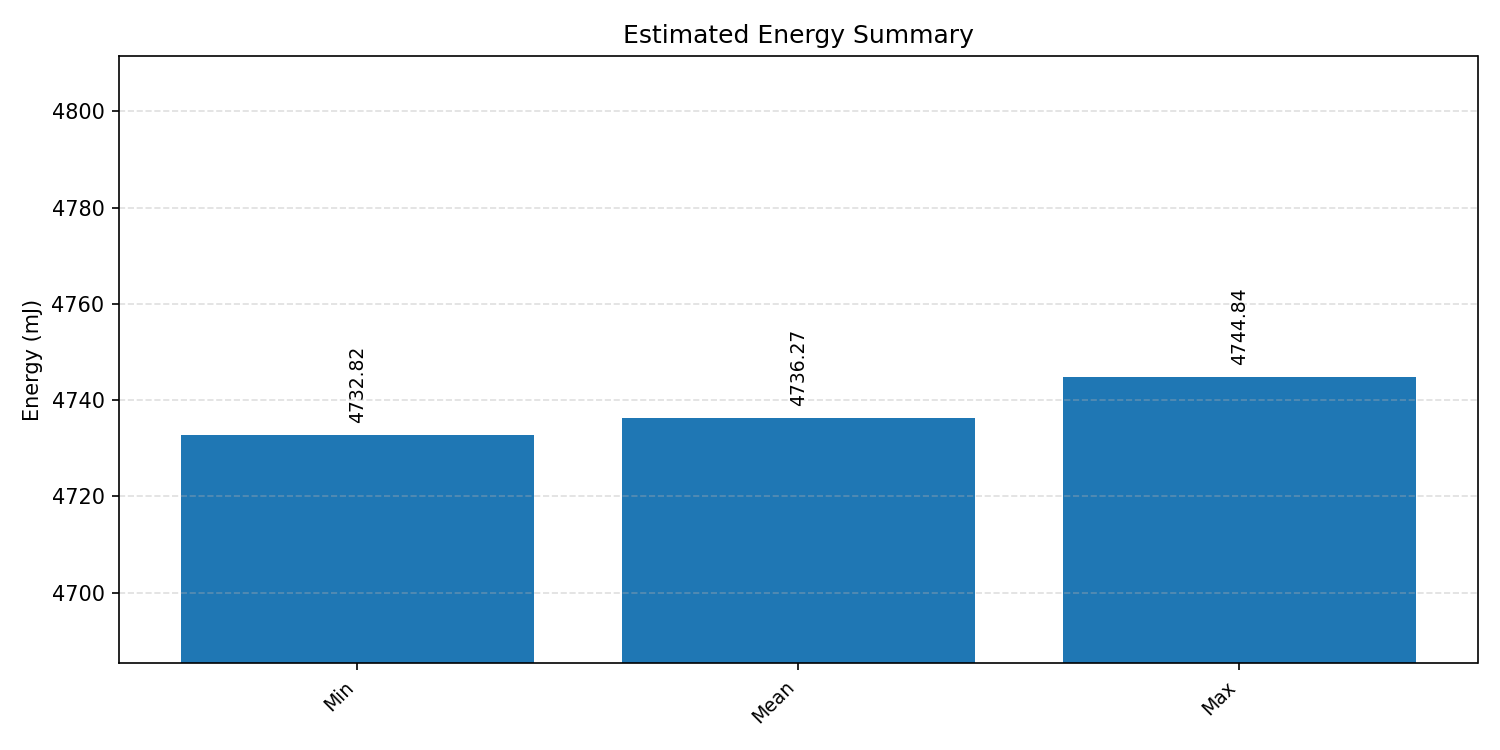

#4.7 ResNet50#
ResNet50 increases model depth and compute load, making backend selection effects easier to inspect.
Comparison Chart
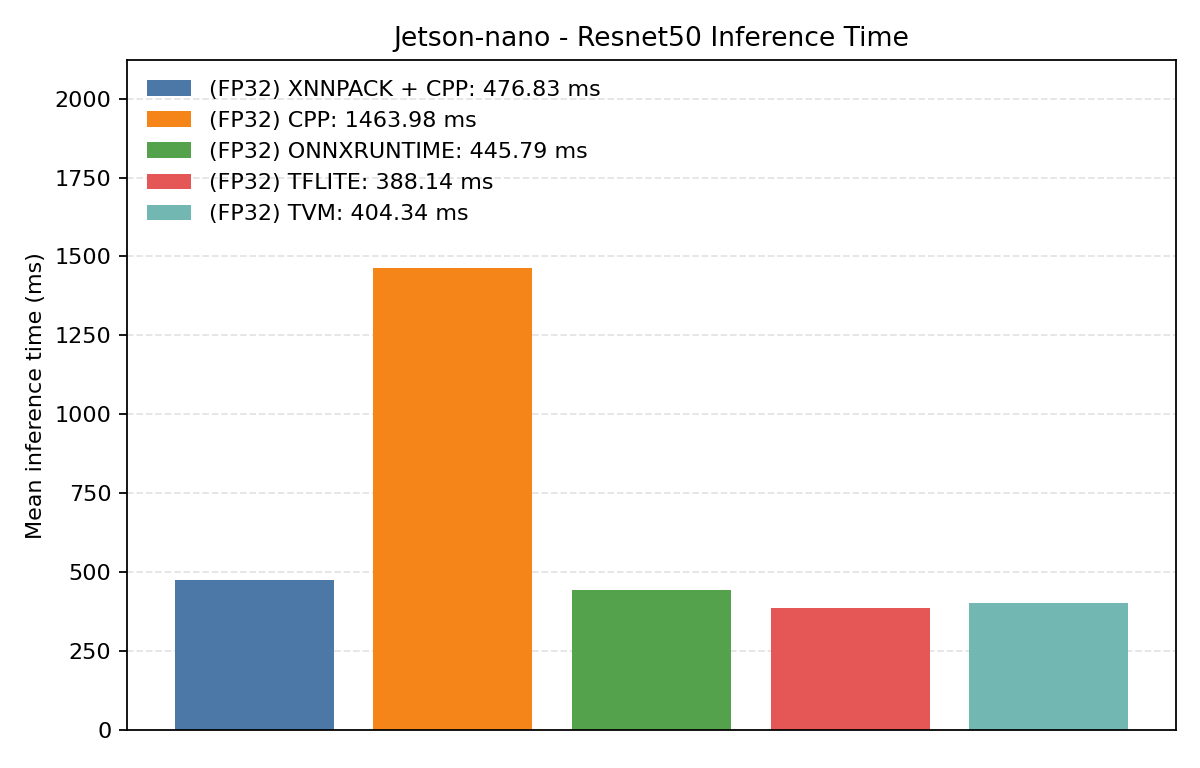
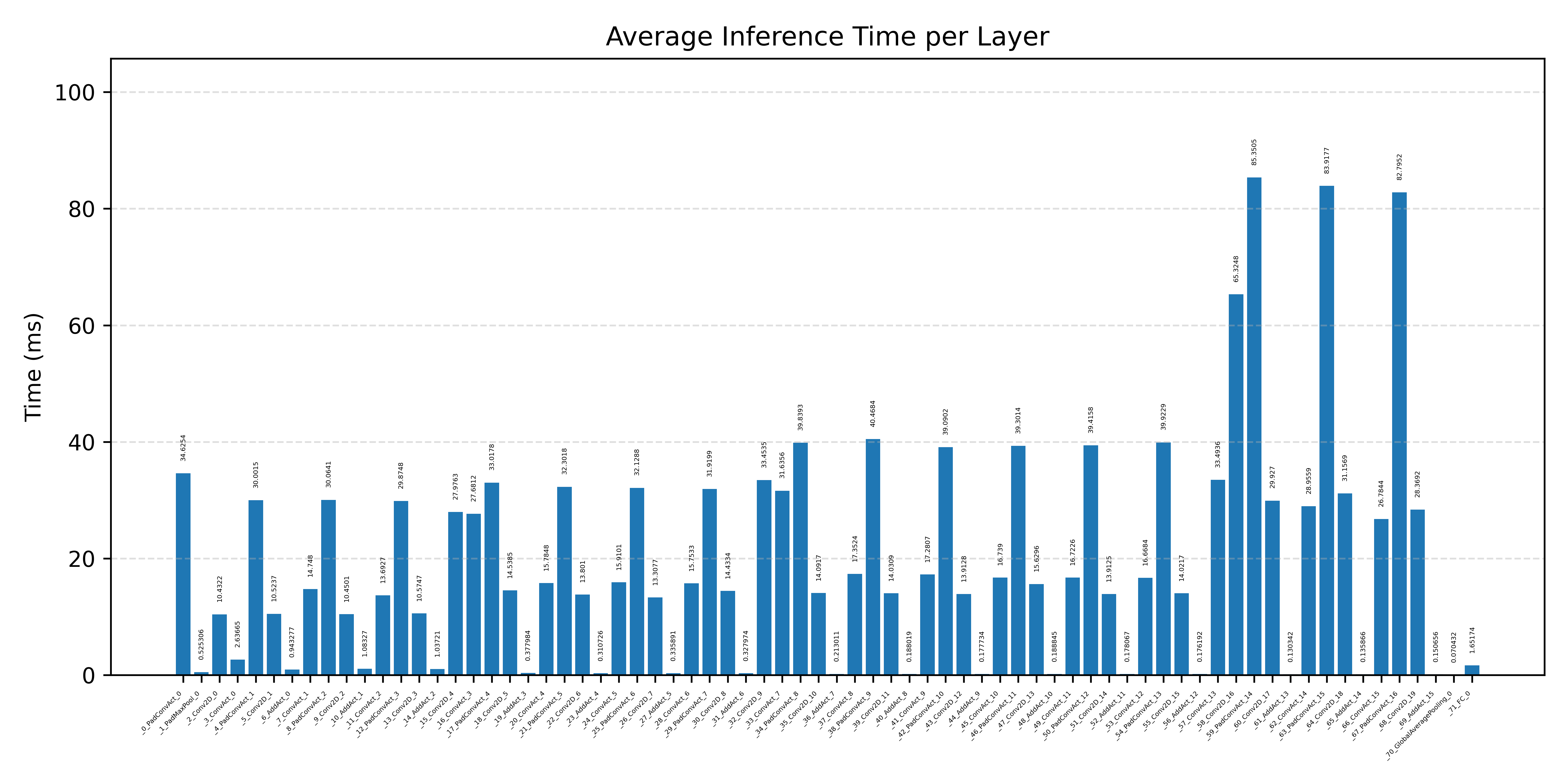
#4.7.1 (FP32) CPP#
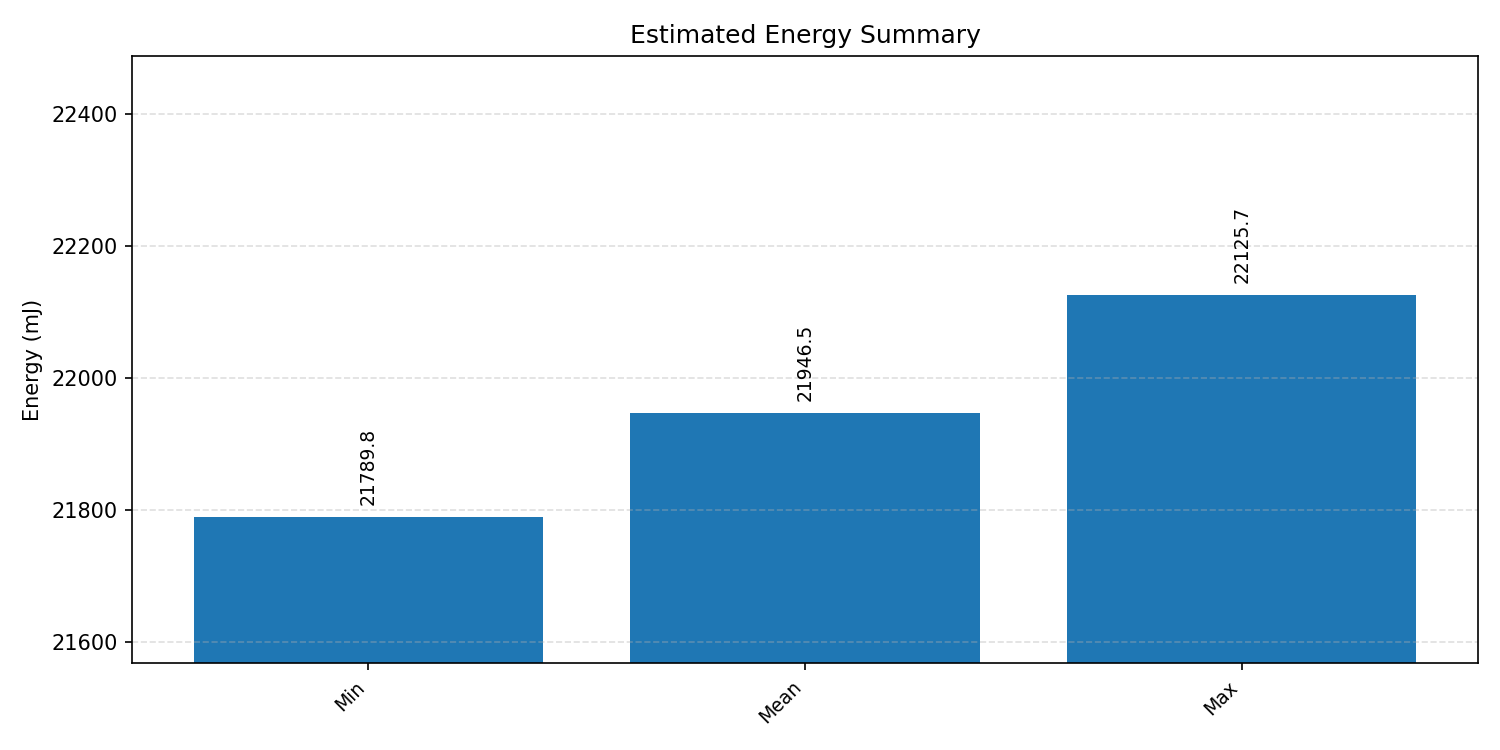
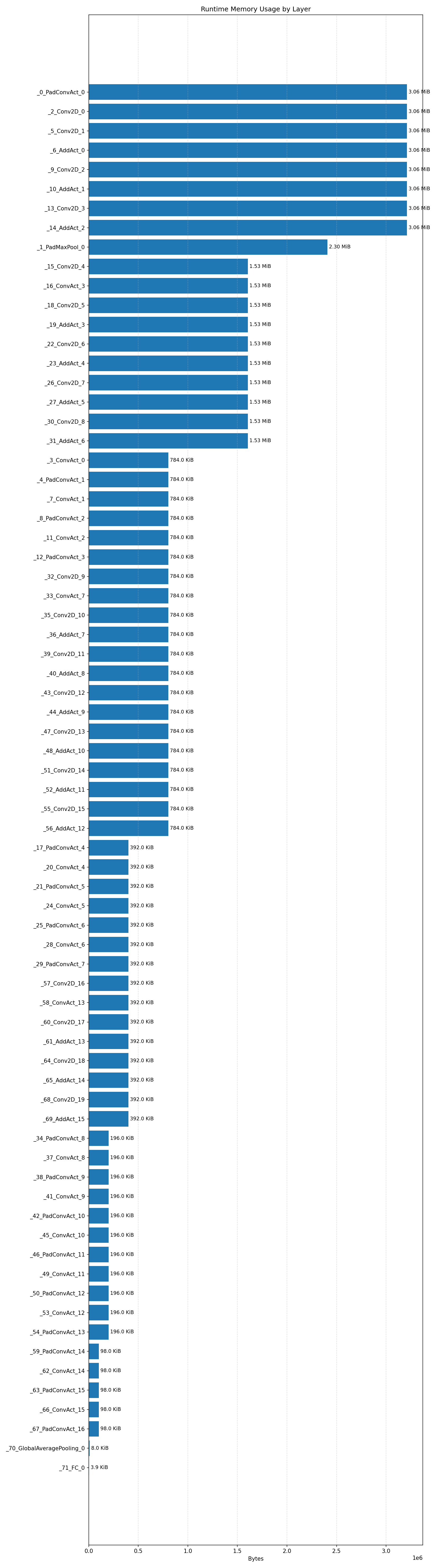
#4.7.2 (FP32) XNNPACK + CPP#