
Aidge quantization API#
Post-Training Quantization (PTQ)#
High-level methods#
- aidge_quantization.check_architecture(network: aidge_core.aidge_core.GraphView) bool#
Determine whether an input GraphView can be quantized or not.
- Parameters:
network (
aidge_core.GraphView) – The GraphView to be checked.- Returns:
True if the GraphView can be quantized, else False.
- Return type:
bool
- aidge_quantization.quantizability_report(graphView: aidge_core.aidge_core.GraphView) None#
Print a full quantizability report indicating which operator is supported, which will stay in Float precision and which is not supported by the PTQ.
- Parameters:
graph_view (
aidge_core.GraphView) – The GraphView to be check.
- aidge_quantization.auto_assign_node_precision(graphview: aidge_core.aidge_core.GraphView, act_precision: aidge_core.aidge_core.dtype, weight_precision: aidge_core.aidge_core.dtype, bias_precision: aidge_core.aidge_core.dtype) None#
Automatically assigns precision attributes to all nodes in a computation graph.
This function traverses every node in the given graph and tags it with precision-related attributes used for quantization (e.g., INT8, FLOAT32, etc.). It distinguishes between activation, weight, and bias precisions, and automatically sets the correct precision depending on the node type (affine, merging, or producer).
Nodes that already have a “quantization.ptq.precision” attribute are skipped.
“Producer” nodes (e.g., graph inputs) are not modified.
For affine nodes, parent nodes corresponding to weights and biases are also tagged with their respective precisions.
Each node receives both “quantization.ptq.precision” and, when applicable, “quantization.ptq.accumulationprecision” attributes.
- Parameters:
graphview (
aidge_core.GraphView) – Shared pointer to the computation graph to annotate.act_precision (
aidge_core.DataType) – Data type representing the precision of activations (e.g., INT8, FLOAT32).weight_precision (
aidge_core.DataType) – Data type representing the precision of weights.bias_precision (
aidge_core.DataType) – Data type representing the precision of biases and accumulation.
- Returns:
None
- Note:
This function only assigns metadata tags — it does not perform actual quantization or data casting. It must be called before invoking the main quantization pipeline, unless you manually tag every node with the required precision attributes.
- aidge_quantization.quantize_network(network: aidge_core.aidge_core.GraphView, calibration_set: collections.abc.Sequence[aidge_core.aidge_core.Tensor], clipping_mode: aidge_quantization.aidge_quantization_cuda.Clipping = <Clipping.MAX: 1>, rescale_inputs: bool = False, equalize: bool = True, channel_wise: bool = False, no_quant: bool = False, optimize_signs: bool = False, single_shift: bool = False, fold_graph: bool = True, fake_quantize: bool = False, dequantize: bool = False, verbose: bool = False) None#
Main quantization routine. Performs every step of the quantization pipeline.
- Parameters:
network (
aidge_core.GraphView) – The GraphView to be quantized.calibration_set (list of
aidge_core.Tensor) – The input dataset used for the activations calibration.clipping_mode (
aidge_quantization.Clipping) – Type of the clipping optimization. Can be either ‘MAX’, ‘MSE’, ‘AA’ or ‘KL’.no_quant (bool) – Whether to apply the rounding operations or not.
optimize_signs (bool) – Whether to take account of the IO signs of the operators or not.
single_shift (bool) – Whether to convert the scaling factors into bit-shifts. If true the approximations are compensated using the previous nodes parameters.
fold_graph (bool) – Whether to fold the parameter quantizers after the quantization or not.
fake_quantize (bool) – Whether to keep float representation for quantized data type.
dequantize (bool) – Whether to dequantize the outputs of the network or not.
verbose (bool) – Whether to print extra information about the quantization process or not.
aidge_quantization.quantize_network performs the following operations in order:
ranges=aidge_quantization.compute_rangesaidge_quantization.adjust_ranges(ranges)(
ifdequantize)aidge_quantization.perform_dequantization(
ifsingle_shift)aidge_quantization.insert_compensation_nodes(
ifsingle_shift)aidge_quantization.perform_single_shift_approximation(
ifnotfake_quantize)aidge_quantization.cast_quantized_network(
iffold_graph)aidge_quantization.fold_producer_quantizers
Low-level methods#
- aidge_quantization.prepare_network(network: aidge_core.aidge_core.GraphView) None#
Prepare a network for the PTQ, by applying multiple recipes on it.
- Parameters:
network (
aidge_core.GraphView) – The GraphView to be quantized.
- aidge_quantization.insert_scaling_nodes(network: aidge_core.aidge_core.GraphView, channel_wise: bool = False) None#
Insert a scaling node after each affine node of the GraphView. Also insert a scaling node in every purely residual branches.
- Parameters:
network (
aidge_core.GraphView) – The GraphView containing the affine nodes.channel_wise (bool) – Whether to use channel wise scalings or not.
- aidge_quantization.cross_layer_equalization(network: aidge_core.aidge_core.GraphView, target_delta: SupportsFloat | SupportsIndex = 0.01) None#
Equalize the ranges of the nodes parameters by proceeding iteratively. Can only be applied to single branch networks (otherwise does not edit the graphView).
- Parameters:
network (
aidge_core.GraphView) – The GraphView to process.target_delta (float) – the stopping criterion (typical value : 0.01)
- aidge_quantization.normalize_parameters(network: aidge_core.aidge_core.GraphView, channel_wise: bool) None#
Normalize the parameters of each parametrized node, so that they fit in the [-1:1] range.
- Parameters:
network (
aidge_core.GraphView) – The GraphView containing the parametrized nodes.channel_wise (bool) – Whether to do channel wise normalization or not.
- aidge_quantization.compute_ranges(network: aidge_core.aidge_core.GraphView, calibration_set: collections.abc.Sequence[aidge_core.aidge_core.Tensor], scaling_nodes_only: bool) dict[aidge_core.aidge_core.Node, float]#
Compute the activation ranges of every affine node, given an input dataset.
- Parameters:
network (
aidge_core.GraphView) – The GraphView containing the affine nodes, on which the inferences are performed.calibration_set (list of
aidge_core.Tensor) – The input dataset, consisting of a vector of input samples.scaling_nodes_only (bool) – Whether to restrain the retrieval of the ranges to scaling nodes only or not
- Returns:
A map associating each considered node to it’s corresponding output range.
- Return type:
dict
- aidge_quantization.adjust_ranges(clipping_mode: aidge_quantization.aidge_quantization_cuda.Clipping, value_ranges: collections.abc.Mapping[aidge_core.aidge_core.Node, SupportsFloat | SupportsIndex], network: aidge_core.aidge_core.GraphView, calibration_set: collections.abc.Sequence[aidge_core.aidge_core.Tensor], verbose: bool = False) dict[aidge_core.aidge_core.Node, float]#
Return a corrected map of the provided activation ranges. To do so compute the optimal clipping values for every node and multiply the input ranges by those values. The method used to compute the clippings can be either ‘MSE’, ‘AA’, ‘KL’ or ‘MAX’.
- Parameters:
clipping_mode (enum) – The method used to compute the optimal clippings.
value_ranges (dict) – The map associating each affine node to its output range.
network (
aidge_core.GraphView) – The GraphView containing the considered nodes.calibration_set (list of
aidge_core.Tensor) – The input dataset, consisting of a list of input samples.verbose (bool) – Whether to print the clipping values or not.
- Returns:
The corrected map associating to each provided node its clipped range.
- Return type:
dict
- aidge_quantization.normalize_activations(network: aidge_core.aidge_core.GraphView, value_ranges: collections.abc.Mapping[aidge_core.aidge_core.Node, SupportsFloat | SupportsIndex]) None#
Normalize the activations of each affine node so that they fit in the [-1:1] range.
- Parameters:
network (
aidge_core.GraphView) – The GraphView containing the affine nodes.value_ranges (list of float.) – The node output value ranges computed over the calibration dataset.
- aidge_quantization.quantize_normalized_network(network: aidge_core.aidge_core.GraphView, no_quant: bool = False, optimize_signs: bool = False, verbose: bool = False) None#
Quantize an already normalized (in term of parameters and activations) network.
- Parameters:
network (
aidge_core.GraphView) – The GraphView to be quantized.no_quant (bool) – Whether to apply the rounding operations or not.
optimize_signs (bool) – Whether to take account of the IO signs of the operators or not.
verbose (bool) – Whether to print extra verbose or not.
- aidge_quantization.insert_compensation_nodes(graphview: aidge_core.aidge_core.GraphView) None#
Insert compensation nodes after single-shift quantization.
Add multiplicative “Mul” nodes before quantizers to correct scaling after PTQ. If no_quant=False, also quantize the compensation coefficients.
- Parameters:
graphview (aidge_core.GraphView) – Graphview containing the Quantizers to modify.
- aidge_quantization.perform_single_shift_approximation(graphview: aidge_core.aidge_core.GraphView) None#
Apply single-shift scaling factor approximation to quantizers.
Replace each quantizer’s scale with the nearest power-of-two and compensate this change on the parent affine node’s weights and bias.
- Parameters:
graphview (aidge_core.GraphView) – Graph to modify.
- Returns:
None
- aidge_quantization.cast_quantized_network(network: aidge_core.aidge_core.GraphView, single_shift: bool, dequantize: bool) None#
Take a quantized GraphView represented in floating precision and cast it to the tagged target precisions. If single-shift option is set to True, the scaling nodes contained in the activation quantizers are replaced with bit-shifts.
- Parameters:
network (
aidge_core.GraphView) – The GraphView to cast.single_shift (bool) – If set to True, replace the scaling-factors by bit-shifts.
- aidge_quantization.fold_producer_quantizers(graphview: aidge_core.aidge_core.GraphView) None#
Fold producer quantizers by marking their producers as constant.
Marks all producer quantizers and their internal producers as constant, then applies constant folding on the graph.
- Parameters:
graphview (aidge_core.GraphView) – Graph to process.
- Returns:
None
Performances#
Model |
FP acc. |
Scheme |
Requant. |
Quant. acc. |
|---|---|---|---|---|
69.748% |
W8A8 TW |
none |
69.162% |
|
W8A8 TW |
single shift |
67.406% |
||
70.832% |
W8A8 TW |
none |
64.692% |
Quantization Aware training (QAT)#
LSQ method#
- aidge_quantization.lsq.setup_quantizers(network: aidge_core.aidge_core.GraphView, nb_bits: SupportsInt | SupportsIndex) None#
Insert the LSQ quantizers in the network and add a the initialization call to the forward stack.
- Parameters:
network (
aidge_core.GraphView) – The GraphView to be trained.nb_bits (int) – The desired number of bits of the LSQ quantization.
- aidge_quantization.lsq.post_training_transform(network: aidge_core.aidge_core.GraphView, true_integers: bool) None#
Clean up a GraphView trained using the LSQ method. All the LSQ nodes are replaced with classical Quantizers, and the output multiplier nodes are absorbed when possible. Hence, the quantization scales are no longer made of floating point values, but of integer ones.
- Parameters:
network (
aidge_core.GraphView) – The GraphView trained using the LSQ method.true_integers (bool) – If True, insert Cast nodes so that the kernels are called in integer precision.
SAT method#
- aidge_quantization.sat.insert_param_clamping(network: aidge_core.aidge_core.GraphView) None#
Insert a TanhClamp node after every weight producer of the input GraphView.
- Parameters:
network (
aidge_core.GraphView) – The GraphView to be trained.
- aidge_quantization.sat.insert_param_scaling_adjust(network: aidge_core.aidge_core.GraphView, use_batchnorms: bool) None#
Insert the ScaleAdjust nodes in the input GraphView. Optionally skip the insertion when the linear node is followed by a batchnorm (as normalization can be handled by it).
- Parameters:
network (
aidge_core.GraphView) – The GraphView to be trained.use_batchnorms (bool) – If True, skip the insertion each time a batchnorm follows the linear node.
- aidge_quantization.sat.insert_sat_nodes(network: aidge_core.aidge_core.GraphView, use_batchnorms: bool) None#
Insert the TanhClamp and ScaleAdjust nodes for the first phase (pretraining) of the SAT method. Optionally skip the ScaleAdjust insertion when the linear nodes are followed by batchnorm nodes.
- Parameters:
network (
aidge_core.GraphView) – The GraphView to be trained.use_batchnorms (bool) – If True, skip the ScaleAdjust insertion each time a batchnorm follows the linear node.
- aidge_quantization.sat.insert_param_quantizers(network: aidge_core.aidge_core.GraphView, nb_bits: typing.SupportsInt | typing.SupportsIndex, mode: aidge_quantization.aidge_quantization_cuda.DoReFaMode = <DoReFaMode.Default: 0>) None#
Insert the DoReFa parameter quantizers for the second phase (fine-tuning) of the SAT method.
- Parameters:
network (
aidge_core.GraphView) – The GraphView to be trained.nb_bits (int) – The number of bits of the DoRefa scales.
mode (enum) – The mode of the DoReFa quantization scheme.
- aidge_quantization.sat.insert_activ_quantizers(network: aidge_core.aidge_core.GraphView, nb_bits: SupportsInt | SupportsIndex, init_alpha: SupportsFloat | SupportsIndex = 1.0) None#
Insert the CG-PACT activation quantizers for the second phase (fine-tuning) of the SAT method.
- Parameters:
network (
aidge_core.GraphView) – The GraphView to be trained.nb_bits (int) – The number of bits of the CG-PACT scales.
init_alpha (float) – The initial scaling factor of the CG-PACT scales.
- aidge_quantization.sat.post_training_transform(network: aidge_core.aidge_core.GraphView, true_integers: bool) None#
Clean up a GraphView trained using the SAT method. The TanhClamp nodes are folded, the DoReFa and CG-PACT nodes are replaced with classical quantizers, and the ScaleAdjust are absorbed. Hence, the quantization scales are no longer made of floating point values, but of integer ones. Also, the output multiplier nodes are fused when possible.
- Parameters:
network (
aidge_core.GraphView) – The GraphView trained using the SAT method.true_integers (bool) – If True, insert Cast nodes so that the kernels are called in integer precision.
Predefined operators#
CGPACT#
%%{init: {'flowchart': { 'curve': 'monotoneY'}, 'fontFamily': 'Verdana' } }%%
graph TD
Op("<b>CGPACTOp</b>
"):::operator
In0[data_input]:::text-only -->|"In[0]"| Op
In1[alpha]:::text-only -->|"In[1]"| Op
Op -->|"Out[0]"| Out0[data_output]:::text-only
classDef text-only fill-opacity:0, stroke-opacity:0;
classDef operator stroke-opacity:0;
- aidge_quantization.aidge_quantization_cuda.CGPACT(range: SupportsInt | SupportsIndex = 255, name: str = '') aidge_core.aidge_core.Node#
DoReFa#
%%{init: {'flowchart': { 'curve': 'monotoneY'}, 'fontFamily': 'Verdana' } }%%
graph TD
Op("<b>DoReFaOp</b>
"):::operator
In0[data_input]:::text-only -->|"In[0]"| Op
Op -->|"Out[0]"| Out0[data_output]:::text-only
classDef text-only fill-opacity:0, stroke-opacity:0;
classDef operator stroke-opacity:0;
- aidge_quantization.aidge_quantization_cuda.DoReFa(range: typing.SupportsInt | typing.SupportsIndex = 255, mode: aidge_quantization.aidge_quantization_cuda.DoReFaMode = <DoReFaMode.Default: 0>, name: str = '') aidge_core.aidge_core.Node#
-
std::shared_ptr<Node> Aidge::DoReFa(std::size_t range = 255, DoReFaMode mode = DoReFaMode::Default, const std::string &name = "")#
Factory function to create a DoReFa operator node.
- Parameters:
range – Quantization range (default: 255)
mode – Quantization mode (default: Default)
name – Node name (default: empty)
- Returns:
std::shared_ptr<Node> Shared pointer to the created node
FixedQ#
%%{init: {'flowchart': { 'curve': 'monotoneY'}, 'fontFamily': 'Verdana' } }%%
graph TD
Op("<b>FixedQOp</b>
"):::operator
In0[data_input]:::text-only -->|"In[0]"| Op
Op -->|"Out[0]"| Out0[data_output]:::text-only
classDef text-only fill-opacity:0, stroke-opacity:0;
classDef operator stroke-opacity:0;
- aidge_quantization.aidge_quantization_cuda.FixedQ(nb_bits: SupportsInt | SupportsIndex = 8, span: SupportsFloat | SupportsIndex = 4.0, is_output_unsigned: bool = False, name: str = '') aidge_core.aidge_core.Node#
LSQ#
%%{init: {'flowchart': { 'curve': 'monotoneY'}, 'fontFamily': 'Verdana' } }%%
graph TD
Op("<b>LSQOp</b>
"):::operator
In0[data_input]:::text-only -->|"In[0]"| Op
In1[step_size]:::text-only -->|"In[1]"| Op
Op -->|"Out[0]"| Out0[data_output]:::text-only
classDef text-only fill-opacity:0, stroke-opacity:0;
classDef operator stroke-opacity:0;
- aidge_quantization.aidge_quantization_cuda.LSQ(range: tuple[SupportsInt | SupportsIndex, SupportsInt | SupportsIndex] = (0, 255), name: str = '') aidge_core.aidge_core.Node#
ScaleAdjust#
%%{init: {'flowchart': { 'curve': 'monotoneY'}, 'fontFamily': 'Verdana' } }%%
graph TD
Op("<b>ScaleAdjustOp</b>
"):::operator
In0[data_input]:::text-only -->|"In[0]"| Op
Op -->|"Out[0]"| Out0[data_output]:::text-only
Op -->|"Out[1]"| Out1[scaling]:::text-only
classDef text-only fill-opacity:0, stroke-opacity:0;
classDef operator stroke-opacity:0;
- aidge_quantization.aidge_quantization_cuda.ScaleAdjust(name: str = '') aidge_core.aidge_core.Node#
TanhClamp#
%%{init: {'flowchart': { 'curve': 'monotoneY'}, 'fontFamily': 'Verdana' } }%%
graph TD
Op("<b>TanhClampOp</b>
"):::operator
In0[data_input]:::text-only -->|"In[0]"| Op
Op -->|"Out[0]"| Out0[data_output]:::text-only
Op -->|"Out[1]"| Out1[scaling]:::text-only
classDef text-only fill-opacity:0, stroke-opacity:0;
classDef operator stroke-opacity:0;
- aidge_quantization.aidge_quantization_cuda.TanhClamp(name: str = '') aidge_core.aidge_core.Node#
Importing and exporting quantized models to ONNX#
ONNX uses different representations for quantized models than Aidge. The ONNX standard distinguishes two formats for quantized models:
QOP or QOperator: Similar to a fully quantized Operator, it takes int8 as input and returns int8 as output. Although under the hood it is equivalent to QDQ.
QDQ or Quantize-Dequantize: Uses the full precision operator and inserts quantize and dequantize nodes.
See figure below:
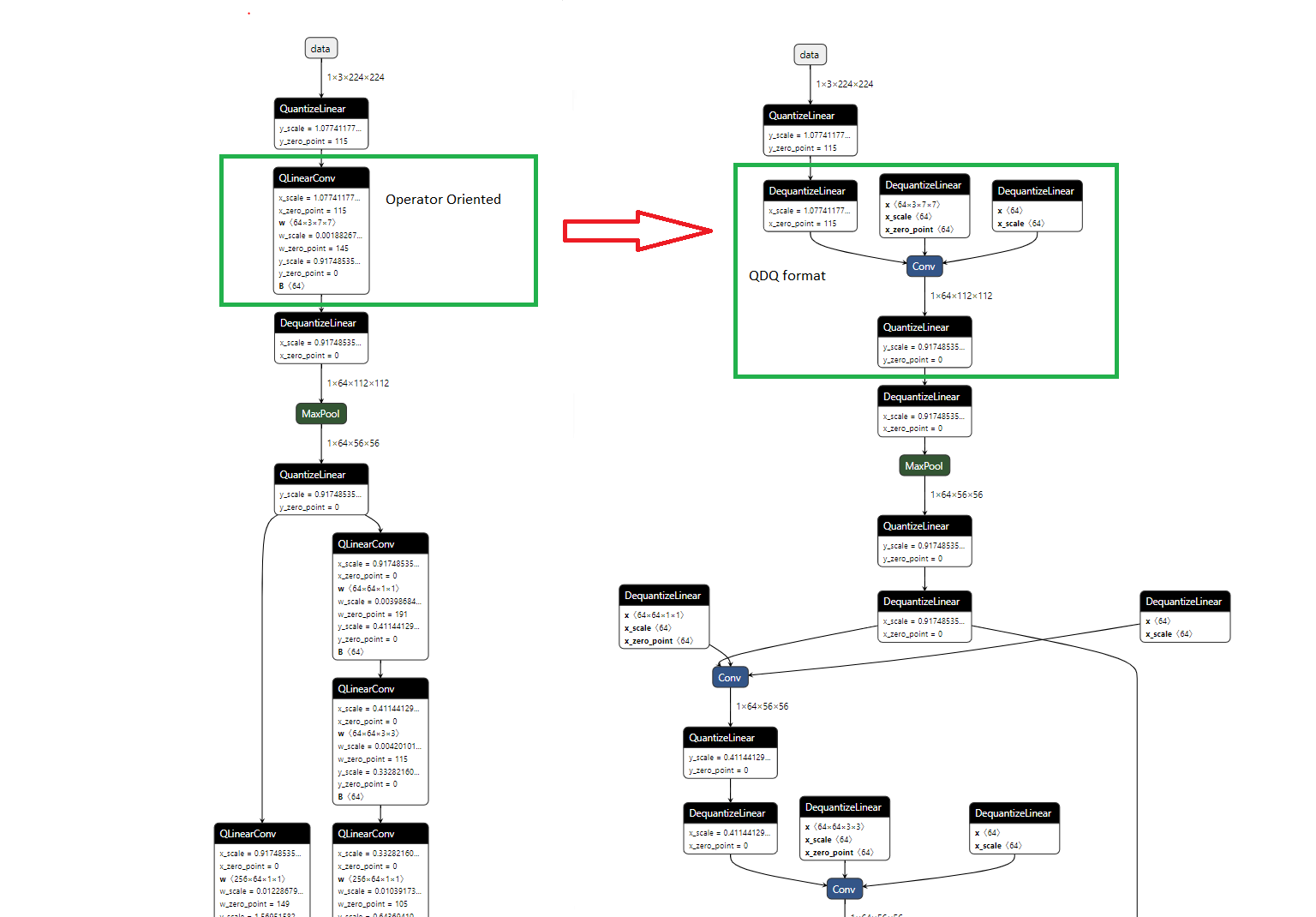
For more information please refer to ONNX documentation.
In order to handle export of quantized models to ONNX, we propose multiple functions to transform an Aidge quantized graph to/from the QDQ and QOP format.
QDQ/QOP work with different dynamics than Aidge quantization, meaning that the transformation to and from QDQ is not straightforward and there is a risk of precision, approximation or rounding errors appearing. If you would like to understand in more detail how these functions work, see the “transformation method” subsection.
The following methods enable transforming the graph before exporting it to ONNX.
- aidge_quantization.set_to_qdq(graph_view)#
Transform a freshly quantized model to QDQ format.
This function is only guaranteed to work on quantized graph that hasn’t been modified!
- aidge_quantization.set_to_qop(graph, qops_selected=[], qdq_needed=False)#
The following methods enable transforming a graph loaded from ONNX to make it compatible with the Aidge representation (for example for export)
- aidge_quantization.from_qop(graph_view, qops_to_expand=[], to_qdq=False)#
- aidge_quantization.from_qdq(graph_view)#
Usage example:#
Convert a quantized Aidge model to QDQ (resp. QOP)
quantized_network: aidge_core.GraphView = ...
aidge_quantization.set_to_qdq(quantized_network)
# Model is ready to be exported!
aidge_onnx.export_onnx(quantized_network, "QDQ_network")
Load a QDQ model (ORT quantized model):
quantized_network: aidge_core.GraphView = aidge_onnx.load("QDQ_network")
aidge_quantization.from_qdq(quantized_network)
# quantized_network is now Aidge compatible!
For a more complete example and tutorial, please refer to QDQ_ONNX_tutorial
Transformation method:#
In Aidge, quantization manages only the quantized dtype (most often int8), performing inference in int8 or int32 for accumulations. Contrary to Aidge, and as mentioned previously, QDQ and by extension QOP, surround their operators with Dequantizers at their inputs and quantize nodes at their outputs. While keeping the operator in full precision.
One performs computations in int8 (or int32 for accumulations), while the other performs all operations in full precision. Meaning that just adding or removing Dequantizer nodes would not work because the dynamics change.
To take into account these modifications, the following formulas are used:
Affine operators, FC example:
In Aidge a quantized FC would look like:
%%{init: {'flowchart': { 'curve': 'monotoneY'}, 'fontFamily': 'Verdana' } }%%
flowchart TD
input0((in#0)):::inputCls -->|Float32| Q_in["Quantize_in<br/>Sx"]
Q_in -->|Int8| FC1["FC_1"]
W1["W_1"] -->|Float32| Q_w["Quantize_w<br/>Sw"]
Q_w -->|Int8| FC1
B1["B_1"] -->|Float32| Q_b["Quantize_b<br/>Sb"]
Q_b -->|Int32| FC1
FC1 -->|Int32| Q_y["Quantize_y<br/>Sy"]
Q_y -->|int8| output0((out#0)):::outputCls
classDef inputCls fill:#afa
classDef outputCls fill:#ffa
While in QDQ, it would look like:
%%{init: {'flowchart': { 'curve': 'monotoneY'}, 'fontFamily': 'Verdana' } }%%
flowchart TD
input0((in#0)):::inputCls -->|Float32| Q_in["Quantize_in<br/>Sx"]
Q_in -->|Int8| DQ_in["DeQuantize_in<br/>1/Sx"]
W1["W_1"] -->|Float32| Q_w["Quantize_w<br/>Sw"]
Q_w -->|Int8| DQ_w["DeQuantize_w<br/>1/Sw"]
B1["B_1"] -->|Float32| Q_b["Quantize_b<br/>Sb"]
Q_b -->|Int32| DQ_b["DeQuantize_b<br/>1/Sb"]
DQ_in -->|Float32| FC1["FC_1"]
DQ_w -->|Float32| FC1
DQ_b -->|Float32| FC1
FC1 -->|Float32| Q_y["Quantize_y<br/>Sy'"]
Q_y -->|int8| output0((out#0)):::outputCls
classDef inputCls fill:#afa
classDef outputCls fill:#ffa
Let \(x \in \mathbb{R}^n\) be the input tensor, the scaling factors (layer-wise) \(\{s_{in}, s_w, s_b, s_y\} \in \mathbb{R}^4\) and the weight and bias respectively \(W \in \mathbb{R}^{m \times n}\), \(b \in \mathbb{R}^m\).
We can write the quantized output of \(FC_1\), \(y \in \mathbb{R}^m\), as:
Let’s factorize out the scaling factors for the weights and inputs:
Let
Then
So to pass from a quantized Aidge model to QDQ: - The output/activation quantizer scaling factor must be equal to \(s_y \cdot s_w \cdot s_{in}\) - The bias quantizer scaling factor must be equal to \(\frac{s_b}{s_w \cdot s_{in}}\)
Add example
Consider an Add operator with inputs \(x \in \mathbb{R}^n\) and \(w \in \mathbb{R}^n\).
Let the scaling factors be (layer-wise)
\(\{s_{in}, s_w, s_y\}\).
The quantized output of the Add operator can be written as:
For the QDQ representation, the operator works in full precision and the quantization scales are handled by Quantizers/Dequantizers.
Making the quantization and dequantization operations explicit:
To pass from a quantized Aidge model to QDQ: - The output/activation quantizer scaling factor must be equal to \(s_y \cdot s_w \cdot s_{in}\) - Both input dequantizer scaling factors must be equal, so \(s'_{dq,x} = s'_{dq,w} = s_{dq_w} \cdot s_{dq,in}\)