
Framework architecture#
AIDGE is based on a principle of modular architecture (completion by plugin) in order to allow the addition of functionality and to meet needs not expressed during the initial design of the latter. Thus, let’s not remove the limit of what this platform can offer while taking care to maintain its performance.
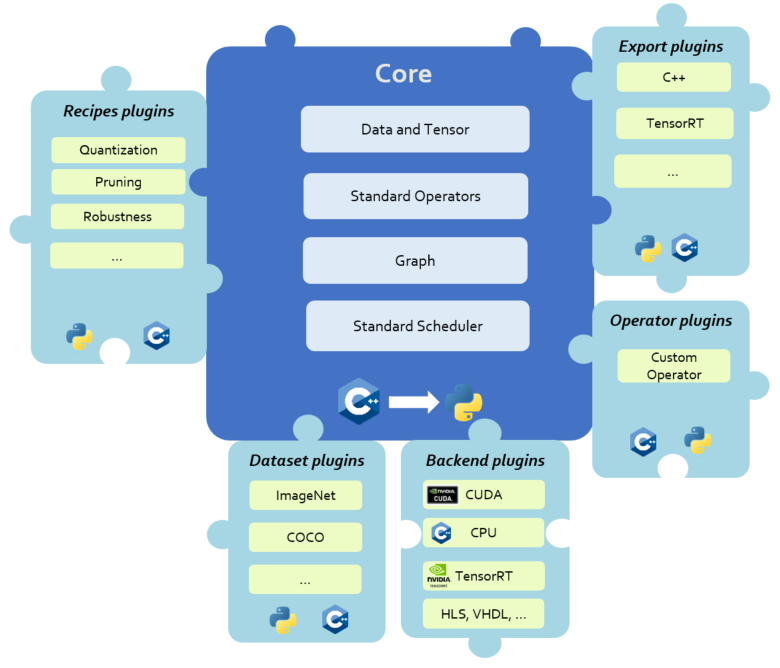
Core#
The Core module is developped entirely in C++ (14) and includes a set of functions enabling to:
Create a computational graph to model a DNN ;
Modify the computational graph (e.g. by deleting or replacing a node of the graph);
Do graph matching to find specific sequence of operators in the computational graph;
Instanciate standard operators (without implementation);
Instanciate standard data structures, such as Tensor (without implementation);
Create standard schedulers (sequential), to execute the computational graph
Access standard graph optimization functionalities, such as fusion of operators
FuseMulAdd: Fuse
MatMulandAddoperator into aFullyConnected(FC) operatorFuseConvBatchNorm: Fuse
BatchNorminto aConvolutionoperator
A Python binding is available to execute these functions from a Python (>3.8) interface.
Implementations & Backends#
In order to provide a modular platform (e.g. to switch easily from one hardware target to another), AIDGE separates the concepts of description and implementation. Operator and data descriptions are generic, while implementations are specific.
Indeed, if the implemtation of a convolution calculation differs on a GPU or CPU, the description of the convolution itself (its inputs and parameters) does not change. In this example, the implementation changes according to the hardware target, but it can also change according to the library used. For example, on the NVIDIA GPU target, programming can be done either via CUDA or via TensorRT. That is why AIDGE introduces the notion of Backend to define both the hardware target and the library used for the implementation.
Note that to associate an implementation with an operator or data, you need to define more than just a backend, you also need to define a data type and a precision. The process of choosing an implementation will be described in the sections defining operator and data respectively.
Plugins#
Plugins allow developer and users to add or adapt functionalities of the AIDGE plateform. Different kinds of plugins can be developed using a specified API:
A recipe plugin offers a set of optimizer algorithms like to reduce the model cost in term of memory and computing complexity but also specific algorithms to confer properties that will allow robustness against external attacks by implementing the principle of defense. Other kinds of recipes plugins can be integrated as long as they respect the API specified in the rest of the document.
Recipes can be categorize as follow
Load/save model recipes which allow to load/save a model either from a file or from memory. (e.g: ONNX, PyTorch, Keras…)
Optimize recipes
A dataset plugin adds the ability to load data and labels (ground truth data provided to the network during the learning step) from a specific dataset.
A backend plugin registers to the Core compiled kernel libraries (e.g. C++, CUDA, HLS) allowing to execute the computational graph.
An operator plugins adds the ability to define an operator in C++ which is not available in the Core.
An export plugins defines a set of rules and methods which aims to adapt the graph for the targeted hardware, and methods to produce source code corresponding to the opitimized graph.
Plugins can be implemented in either Cpp or Python.