
Transform graph#
Overview#
AIDGE aims to simplify the manipulation of the graphs the users could have. For that purpose, the framework provides several tools to perform graph manipulation and transformation. This refers to the problematic of graph matching (a.k.a Subgraph isomorphism problem). This problem appears when you want to transform a RAW input graph into a supported one. The RAW input graph is an unaltered one (for example a graph directly imported from ONNX). It might contain nodes, which are not implemented in the framework. Therefore, you need to replace all of the unimplemented nodes (or sub graph) with implemented ones, which are mathematically equivalent. In practice, transforming a graph in AIDGE follows this pipeline :
flowchart LR
A("`**Describe graph patterns**
Node Regex & Graph Regex`") --> B("`**Match patterns**
Graph Matching`") --> C("`**Graph transformation**
Transformation functions`")
The following sections explains each step of the pipeline.
Describe graph patterns#
In order to find specific patterns inside a graph, there is first a need to describe those patterns. AIDGE introduces an innovative way to describe graph patterns, Graph Regular Expression, inspired by regular expression from the formal language theory. Graph Regular Expression combines two complementary components:
Node Regex : Describe the conditions an operator has to fullfill
Graph Regex : Describe the graph topological pattern
Node Regex#
In the context of graph matching, we need to check whether any operator corresponds to a subset of operators that we define. We want to be able to characterize:
The operator type
Example: Conv
The attributes of the operator
Example: For a convolution, we only want to recognize convolutions with 3x3 kernels.
One of several operator types
Example: Conv or BatchNorm or FC
To meet these specifications, we introduce the notion of Node Regex.

Node Regex Lexer#
Tokenize the string taken as an input of the lexer into tokens. A token is a Key and a Lexem ; the lexem is an additional information on the key.
Example of keys:
Character |
Key |
|---|---|
|
AND |
|
OR |
|
NOT |
|
EQ |
|
NEQ |
|
KEY |
|
INTEGER |
|
FLOAT |
|
STRING |
|
BOOL |
|
LAMBDA |
|
ARGSEP |
|
NODE |
|
LPAREN |
|
RPAREN |
|
STOP |
Example:
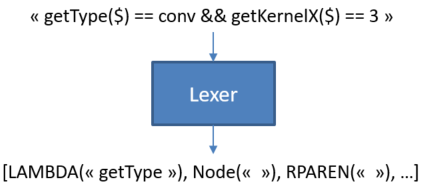
In the above figure: LAMBDA(“getType”);, LAMBDA is a key and “getType” is the lexem.
Node Regex Parser#
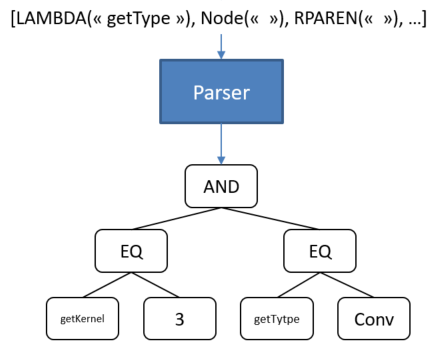
Receive token in the order of the string passed to the lexer. It will put them in an Abstract Syntax Tree (AST) by using grammatical rules.
Example of grammatical rules:
expr : cmpr ((AND | OR) cmpr)*
cmpr : val (EQ|NEQ) val | LPAREN expr RPAREN
val : (KEY|INTEGER|FOAT|STRING|LAMBDA)
lambda : LAMBDA val (ARGSEP val)* RPAREN
Example of parser intput and output:
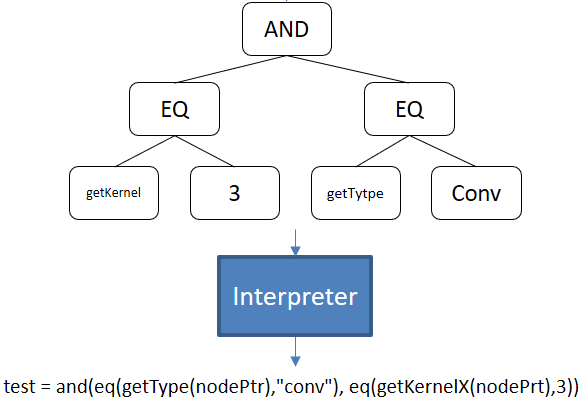
Node Regex Interpreter#
Visit the AST in order to process the desired Boolean function, which return True if the Node match the conditions and else return False.
Graph Regex#

Graph Regex Lexer#
Tokenize the string taken as an input into a token. Token, is a Key and a Lexem, the lexem is an additional information on the key.
Character |
Key |
|---|---|
|
NEXT |
|
QOM |
|
QZM |
|
CKEY |
|
KEY |
|
SEP |
|
LPAREN |
|
RPAREN |
Graph Regex Parser#
Receive token in the order of the string passed to the lexer. It will put them in an Abstract Syntax Tree (AST) by using grammatical rules.
Example of grammatical rules:
allExpr : domain (SEP domain)*
domain : (exp)(QOM | QZM)? (NEXT exp)*| exp (NEXT exp)*
exp : KEY(QOM | QZM)? | KEY (NEXT domain)* | CKEY (NEXT domain)*
Graph Matching#
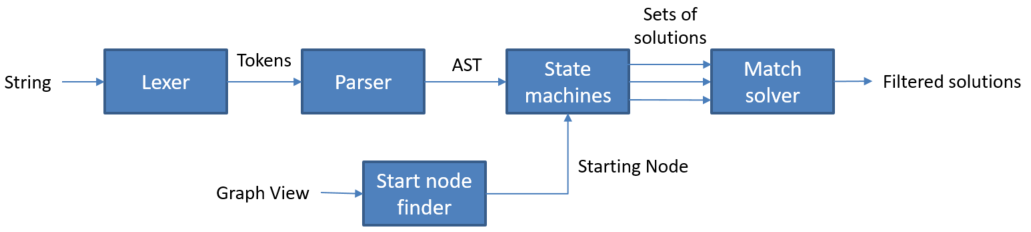
State machine#
A state machine takes as an input a starting node and an AST and outputs zero or multiple solutions. To find every possible solutions, Aidge uses multiple state machines, each one beginning with a different starting node. The graph regex produces a state machine and the transition between each state of the machine is conditioned by the Boolean function produced by Node Regex.
Match solver#
Receive a set of every solution found by the different state machines. The heuristic used to filter the solutions is to find a set of solutions, which maximise the graph covering with no intersection.
Graph transformation#
MetaNode#
A MetaNode is equivalent to a graph view as it is a collection of nodes, the difference being that it is opaque to Graph Matching. This means that nodes and Operator inside a MetaNode are not seen by the Graph Matching which only see a single node, the MetaNode. A MetaNode uses the implementation of each operator which it contains or of complex operator due to the targeted architecture. Different usage emerged:
To create a sub-graph of Operators that can be used N times
During the graph optimization recipe to encapsulate already matched operators. If a complex operator (group of several operators) does not exist during the pattern matching step, then this part of the graph must be protected. The developer must encapsulate the group of operator corresponding to the complex operator to avoid the pattern matching function to fuse one operator of this group with previous operator (if operator at the beginning of the sub-graph) or with the next operator (if at the end).
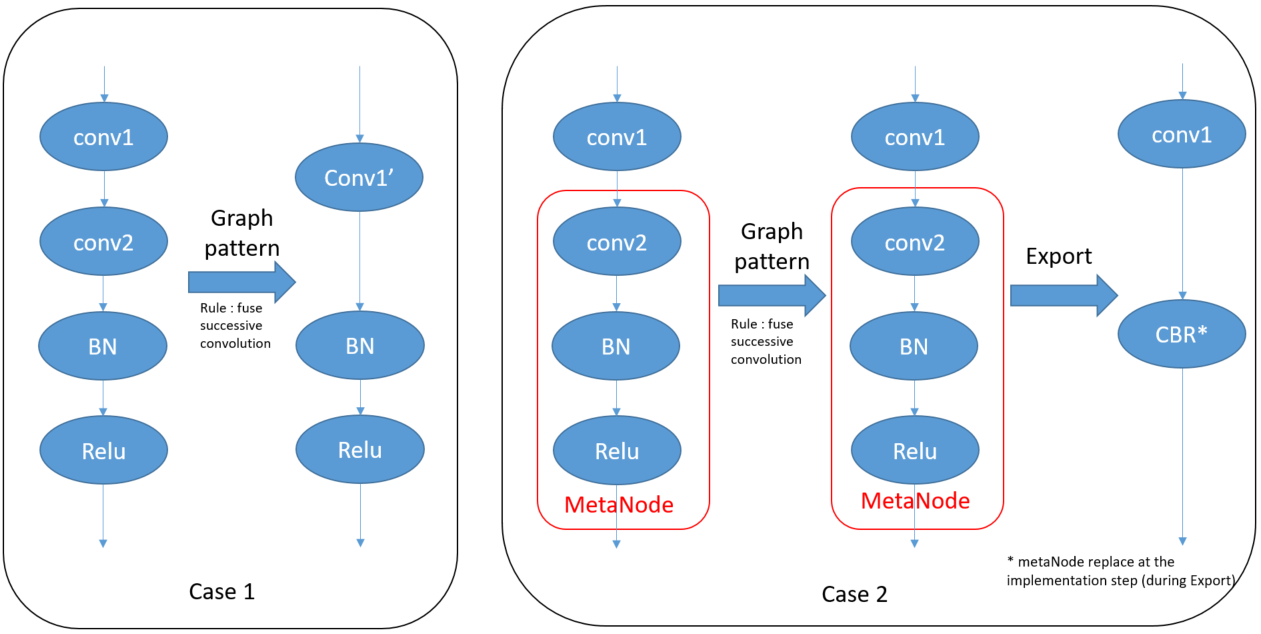
MetaNode are NOT manipulatedby users but by developpers of the paltform.
What happens when matching a MetaNode with Node instances referenced by a Graph View previously declared ?
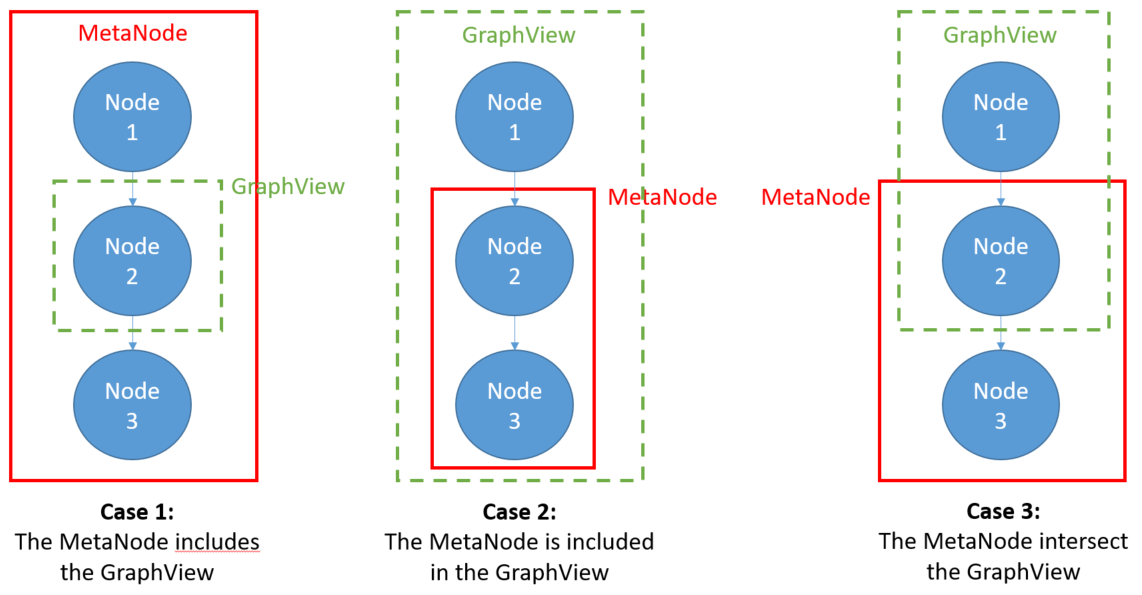
Case 1: The graph view becomes empty
Case 2: The MetaNode becomes part of the graph view
Case 3: the graph view only contains OP1
Transformation functions#
Remove operator#
An ONNX file can be built automatically using an engine. Operations may be added in unnecessary ways; for example, successive transposition of data corresponding to the identity. The pattern matching detects and remove these operations.
Replace operator#
Recognition of a previously defined pattern enables it to be replaced in the graph by a complex operator, which may be defined by a MetaNode. This new operator is implemented in an operator plugin added to the platform, and can then be integrated into a node.
Expand operator#
This involves splitting an operator into two operators. For the sake of clarity, we can imagine that a convolution cannot be performed on a resource all at once, for memory or other reasons. In this case, the convolution is performed in two steps. This will be reflected in the graph by the appearance of 2 operators.