
Perform an export#
Export strategy#
With the aim of control and explainalibity when implementing deep neural network on a given hardware target, AIDGE offers the possibity to produce an interpretable and auditable output.
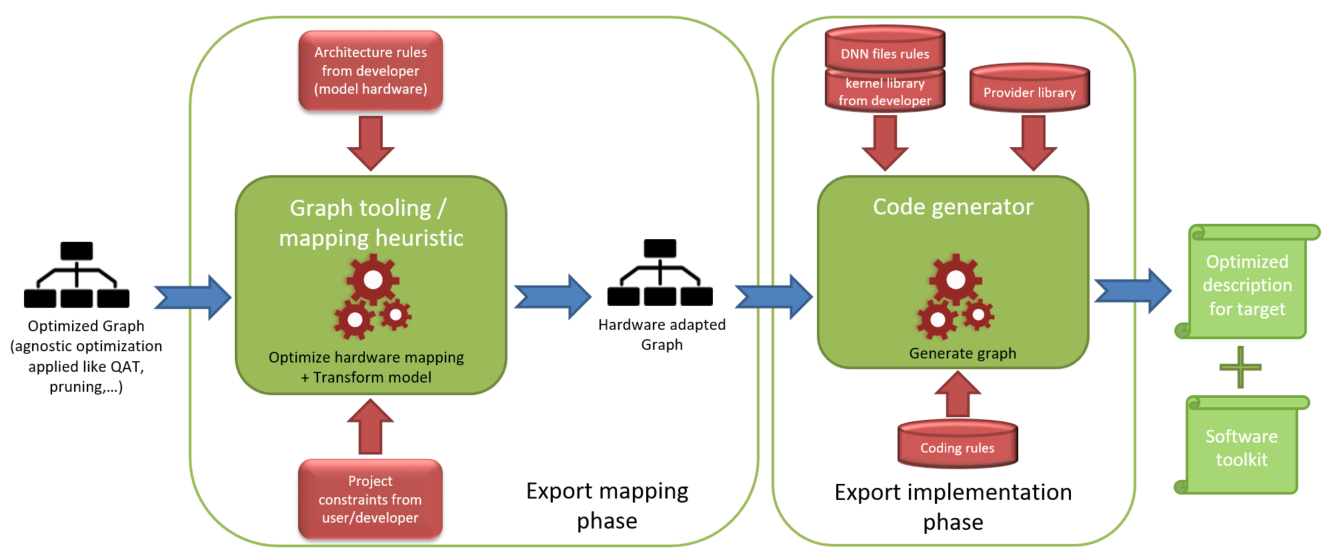
The Export Strategy is made to achieve this goal by producing a source code and a set of related resources that forms a package called the Software Toolkit. The principle of the Export Strategy can be summarized as followed.
The export strategy assumes that the computational graph used as input has already undergone an architecture-agnostic optimization phase. Indeed, many techniques such as quantization or prunning can be beneficial whatever the final target.
The Export Strategy is composed of two phases:
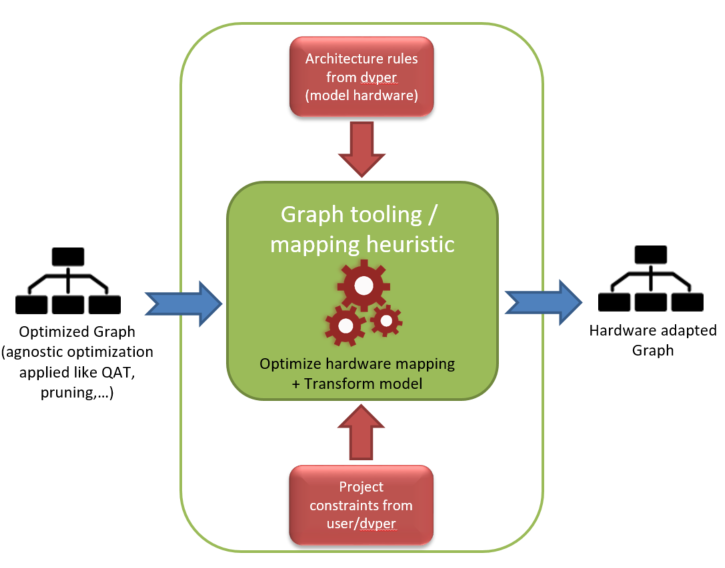
The first phase intends to modify the computational graph to fit the target hardware and produce a scheduling of the graph according to the architecture rules and the project constraints.
The second phase intends to generate the source code of the hardware-adapted graph and the Software Toolkit.
Export mapping phase#
This phase intends to modify the Graph to fit the target hardware by using several optimization techniques (see hardware mapping optimization or graph transformation). The second objective is to generate the scheduling of the graph adapted with the architecture rules of the target and some project constraints imposed by the developer or the user.
Model hardware & architecture rules#
In order to provide effective optimizations for the target hardware, one should consider the architecture of the target. The architecture rules should describe the high-level hardware architecture of the target on which the export will run, in term of memory, bandwidth and computing unit. This description is used by several optimizations (hardware mapping optimization) to adapt the Optimized Graph to the hardware.
For example, these architecture rules could be used to set up a tilling compatible with the target or to optimize the scheduler (see section scheduler).
The high-level description of hardware architecture is based on the concept of “device”. The latter may consist of a processing element (pe) with or without memory (mem). It is also possible to interface several devices together to create another device object.
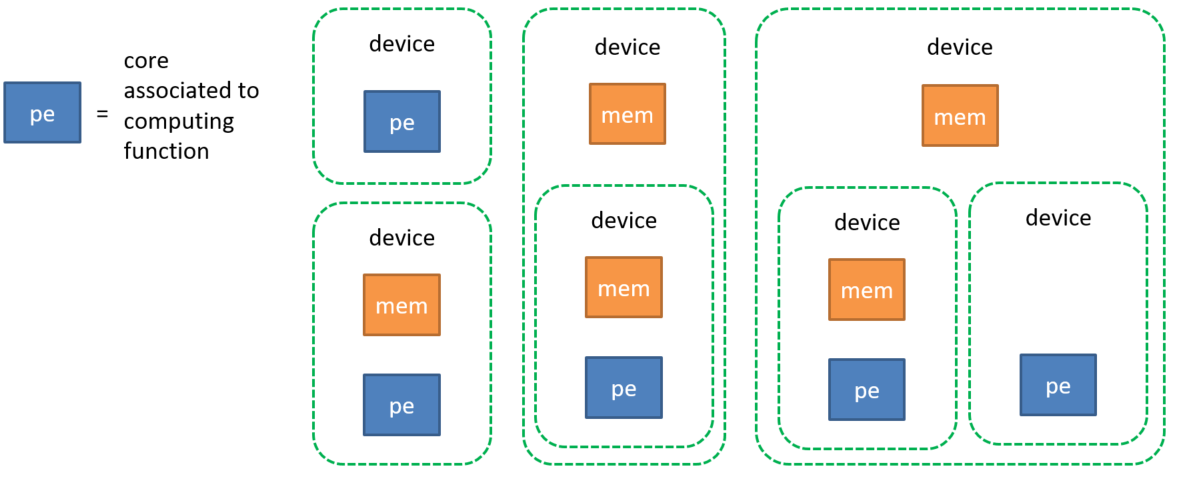
The developer is responsible for providing some information about the device:
The size of each memory;
The desired bandwidth between a calculation element and a memory or between the different memories;
Information about the processing element (if necessary).
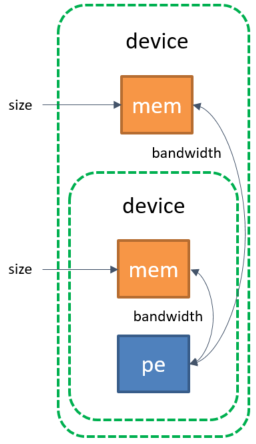
Examples of information for memory specification#
The processing element could execute one function at the time and in some cases, the function could be split among some processing elements working in cooperation mode (via bandwidths).
Project constraints#
Other extra rules, called “project contraints”, imposed by the global application also constrain or guide the export mapping phase. These “project constraints” refer to a set of rules that control the use of the hardware target for the application (the DNN) according to an environment imposed by the entire embedded system and without modifying the description of the target architecture. Among all possible project constraints, the user could modify the available memory, the available computer resources or the time allocated for execution.
Scheduler#
- The role of the scheduler is to generate a sequential list of nodes
from the optimized graph that will define how the forward process of the exported DNN will run on the target, taking into account the architecture rules and the project contraints.
The output generated by the scheduler is called the “hardware-adapted graph”. Each export plugin can implement its own scheduler, as some optimizations are only specific to the target descriptions provided by the plugin.
Export implementation phase#
This second phase aims to produce a source code of the hardware-adapted graph returned by the scheduler. The classic steps for generating source code are the following:
Design and export the computation kernels;
Export the attributes of the nodes;
Export the parameters of the nodes;
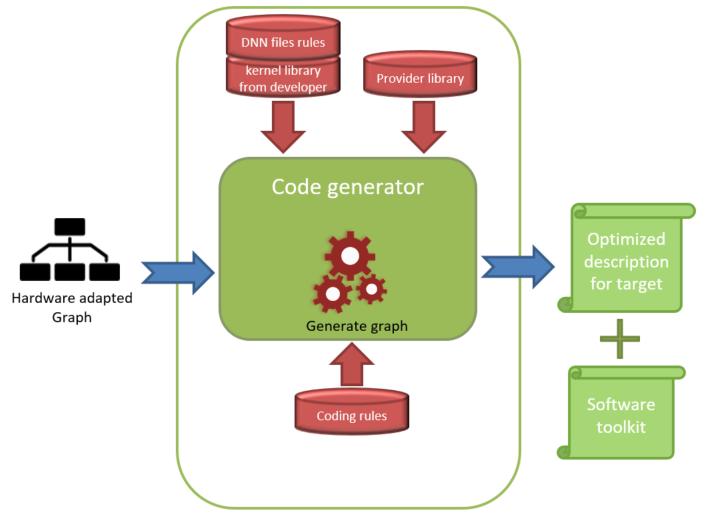
Design and export the computation kernels#
Each node of the graph must have an implementation of its forward in order to use in the export. Since only the developer really knows the components and capabilities of his target, it is his duty to provide the computation kernels. The developer can implement the kernel of each node in separated files to simplify the management of the kernels. This management can create a kernel library, which is a set of elaborated functions developed by experts targeting the architecture (computing functions, DMA programming …) and linked to the provider library (set of header libraries given by the manufacturer of the target). Coding rules can also be imposed on the expert and therefore implemented when writing these kernels. After creating the kernel files, the developer can export these files into the export directory. This action may be realized via copying those files in the export folder and generate an API file to call the kernels in the export.
Export the attributes of the nodes#
After designing the computational kernels, the developer knows which information is required from the node to run correctly the associated kernel. The aim of this step is to generate the configuration of node in the export folder, i.e. a set of files defining the tolpological information of the nodes and their attributes (number of inputs and outputs, size of parameters, etc.). Node configurations can be exported by browsing the hardware-adapted graph and generating a configuration for each node, using a template file that specifies the expected configuration format. The template files defines a set of the DNN file rules used as input of the export implementation phase.
Export the parameters of the model#
When a node has a non empty set of parameters, these parameters have to be stored in the memory of the target and loaded for the application on board. The aim of this step to export these parameters in the export folder. Parameter configurations can be exported by browsing the hardware-adapted graph and generating the parameters of each node, using a template file that specifies the expected configuration format. The template files defines a set of the DNN file rules used as input of the export implementation phase.
Export the scheduling of the graph#
The aim of this step is to generate a file that contains the source code of the forward function of the hardware-adapted graph. In this function, the forward function of each node belonging to the hardware-adapted graph is executed chronologically, according to the plan provided by the scheduler. This file may need to include the configurations of the nodes as well as the parameters to run. The developer could use a template file to describe the format of the forward file. In this phase, the developer could also generate a memory file that indicates some static allocation of the resources used by the export.
Add extra files to complete the export#
The developer has the possibility to add files to generate a whole Software toolkit that will help the comprehension of the export and how to use it on board. It can include:
compilation file to compile the export
documentation files (README, manuals, …)
files to run a whole application of the export
set of unitary tests (to test the kernels on board, …)
input data for tests
third party libraries to use board composants
resources to check other constraints like security rules or robustness directives
Export to an integrated kernel library#
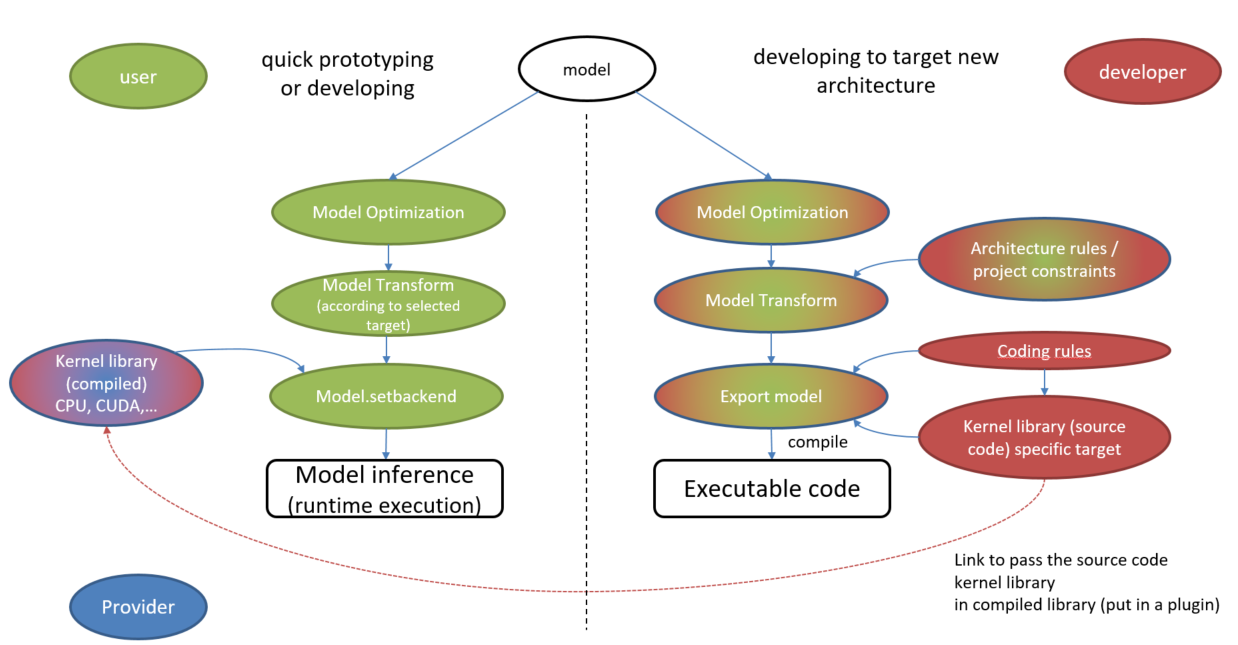
It is possible to quickly prototype or developping functions or entire backbone on a target which kernel library is available on the AIDGE platform (compiled kernel library contains on “backend plugin”).
User provides an ONNX model and choose the targeted architecture (project constraints could also be specified). The platform AIDGE optimize the computational graph and launch the application on the target.
Export strategy versus Runtime execution#
For example, you can use interpreted language such as Python that dynamically calls compiled kernel to execute on the targeted architecture.
If a developer target a new architecture, it is the export strategy that is used. An export plugin is developed and validated (according to some criterias: code coverage, security exigences). Subsequently, a user can use this new export. All it has to do is specify the “project constraints” to carry out the export.
It may be possible to use this export in a more integrated mode, as a backend plugin. It will be necessary to convert it into a compiled kernel library, and so create a new backend plugin. Users will then be able to target this new architecture without having to develop the kernels themselves.