Structuring Algorithms
Often enough, algorithms can be divided into a number of layout phases which, executed as a pipeline, compute a layout. If your algorithm falls into this category, read on; ELK provides things you might want to use.
Layout Phases and Layout Processors
Structuring the algorithm into phases has several advantages. First, it effectively divides the big layout problem into simpler sub problems. Second, it allows the algorithm to be more flexible. Since the division into phases already forces developers to think about what exactly each phase does, it is easy to add different implementations for each phase for clients to switch between. ELK Layered, for example, implements different edge routing styles (polylines, orthogonal routing, or splines) as different implementations of its edge routing phase.
So far, the algorithm is composed of a pipeline of layout phases. Let’s take this concept one step further: what stops us from inserting pre or post processing in between the phases? If we add intermediate processing slots before, between, and after the layout phases, we arrive at the following structure:
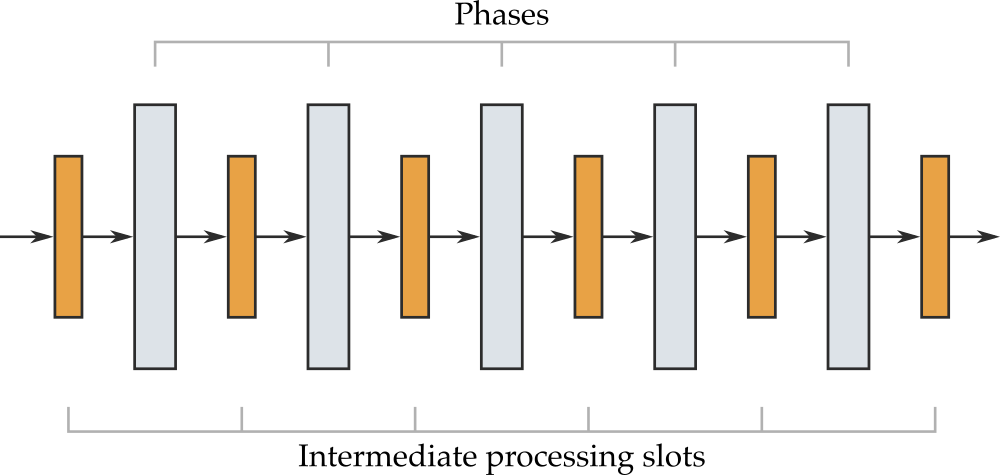
Each processing slot can hold an arbitrary number of intermediate processors, also called layout processors, but what for? Imagine that your algorithm’s first phase needs to eliminate cycles in the input graph by reversing edges. Of course, the edges need to be restored to their original direction once the algorithm has finished. If we only had layout phases, the last phase would be responsible for doing so. With intermediate processors, the first phase can simply request a processors to be executed in the last processing slot that restores edges to their original position. This way of doing things has two advantages. First, the processor has a well-defined purpose and is easy to implement. Second, if there were several different implementations of the last phase, all of them would have to include code to restore reversed edges, thereby introducing code duplication as well as a possible source for bugs.
This example already highlights a difference between layout phases and layout processors: layout phases can request layout processors to be executed in a specific processing slot. Of course, different layout phase implementations can request different processors, resulting in different pipelines. Also, if multiple processors are to be executed in a pipeline, they usually need to be sorted according to their dependencies. A processor that calculates the amount of space around a node required by labels will need a processor that places these labels to have finished executing.
The Implementation
ELK contains everything required to implement layout algorithms this way in its org.eclipse.elk.core.alg package. To use that, the first thing you should start with is to write an enumeration that lists all the phases your algorithm will consist of. For example:
public enum LayoutPhases {
P1_TREEIFICATION,
P2_NODE_ORDERING,
P3_NODE_PLACEMENT,
P4_EDGE_ROUTING;
}
Layout Phases
It is now time to start writing your phases. Implementing a layout phase is, in principle, easy: simply have your phase class implement the ILayoutPhase<P, G> interface, where P is the enumeration of layout phases you just wrote, and G is the type of the graph processed by the phase. For example:
public class NodeOrderer implements ILayoutPhase<LayoutPhases, ElkNode> {
@Override
public LayoutProcessorConfiguration<LayoutPhases, ElkNode> getLayoutProcessorConfiguration(ElkNode graph) {
// To start with, the phase won't require any layout processors
return LayoutProcessorConfiguration.<LayoutPhases, ElkNode>create();
}
public void process(ElkNode ElkNode, IElkProgressMonitor progressMonitor) {
// This will be the entry point to your phase
}
Besides the actual implementation in its process(...) method, a layout phase has one other interesting method: getLayoutProcessorConfiguration(...). We will take a closer look at that a bit later. Before we can do that, we need to take a look at how to implement intermediate processors.
Intermediate Processors
Implementing a layout processor is, again, easy: simply have your processor class implement the ILayoutProcessor<G> interface, where G is the type of the graph processed by the processor. For example:
public class RatherExcellentProcessor implements ILayoutProcessor<ElkNode> {
public void process(ElkNode theGraph, IElkProgressMonitor monitor) {
// This will be the entry point to your processor
}
}
Specifying Dependencies from Phases to Processors
Before we can specify dependencies, we will need an enumeration of all available layout processors. In fact, we will need factories to instantiate those processors, but using an enumeration can give us a simple way to implement those. For example:
public enum IntermediateProcessorStrategy implements ILayoutProcessorFactory<ElkNode> {
// Before Phase 2
ROOT_PROC,
FAN_PROC,
NEIGHBORS_PROC,
// Before Phase 3
LEVEL_HEIGHT,
// Before Phase 4
NODE_POSITION_PROC,
// After Phase 4
DETREEIFYING_PROC;
public ILayoutProcessor<ElkNode> create() {
switch (this) {
case ROOT_PROC:
return new RootProcessor();
case FAN_PROC:
return new FanProcessor();
case NEIGHBORS_PROC:
return new NeighborsProcessor();
case LEVEL_HEIGHT:
return new LevelHeightProcessor();
case NODE_POSITION_PROC:
return new NodePositionProcessor();
case DETREEIFYING_PROC:
return new Untreeifyer();
default:
throw new IllegalArgumentException(
"No implementation is available for the layout processor " + this.toString());
}
}
}
We are now ready to specify which layout processors a layout phase needs to be executed in which intermediate processing slots. This is what the phase’s getLayoutProcessorConfiguration(...) method is for. That method returns an instance of LayoutProcessorConfiguration<P, G>, which specifies exactly that: the intermediate processors to add to the different processing slots. Which processors are required may well depend on the input graph, which explains why that graph is passed to the method. A simple implementation could look like this:
private static final LayoutProcessorConfiguration<LayoutPhases, ElkNode> INTERMEDIATE_PROCESSING_CONFIG =
LayoutProcessorConfiguration.<LayoutPhases, ElkNode>create()
.addBefore(LayoutPhases.P2_NODE_ORDERING, IntermediateProcessorStrategy.ROOT_PROC)
.addBefore(LayoutPhases.P2_NODE_ORDERING, IntermediateProcessorStrategy.FAN_PROC);
@Override
public LayoutProcessorConfiguration<LayoutPhases, ElkNode> getLayoutProcessorConfiguration(ElkNode graph) {
return INTERMEDIATE_PROCESSING_CONFIG;
}
This implementation specifies that the processing slot before phase 2 should contain the ROOT_PROC and the FAN_PROC intermediate processors (whatever those are). If multiple processors should be added to the same slots, the following provides a marginally easier way to do so:
private static final LayoutProcessorConfiguration<LayoutPhases, ElkNode> INTERMEDIATE_PROCESSING_CONFIG =
LayoutProcessorConfiguration.<LayoutPhases, ElkNode>create()
.before(LayoutPhases.P2_NODE_ORDERING)
.add(IntermediateProcessorStrategy.ROOT_PROC)
.add(IntermediateProcessorStrategy.FAN_PROC);
It can be necessary to keep different configurations in our phase and assemble them depending on different graph features. LayoutProcessorConfiguration provides a way to do so, using the addAll(...) method:
private static final LayoutProcessorConfiguration<LayoutPhases, ElkNode> FOO_PROCESSING_ADDITIONS =
LayoutProcessorConfiguration.<LayoutPhases, ElkNode>create()
.addBefore(LayoutPhases.P3_NODE_PLACEMENT, IntermediateProcessorStrategy.LEVEL_HEIGHT)
.addBefore(LayoutPhases.P4_EDGE_ROUTING, IntermediateProcessorStrategy.NODE_POSITION_PROC);
public LayoutProcessorConfiguration<LayoutPhases, ElkNode> getLayoutProcessorConfiguration(ElkNode graph) {
// Basic configuration
LayoutProcessorConfiguration<LayoutPhases, ElkNode> configuration =
LayoutProcessorConfiguration.<LayoutPhases, ElkNode>createFrom(
INTERMEDIATE_PROCESSING_CONFIG);
// Additional dependencies
if (foo) {
configuration.addAll(FOO_PROCESSING_ADDITIONS);
}
return configuration;
}
Assembling the Algorithm
By now, we have phases, processors, a processor enumeration, and dependencies from phases to processors. What we do not have yet is a way to turn those configurations into a pipeline of layout processors that we can execute to compute a layout. What we are looking for is the AlgorithmAssembler class. But before we can use that, we need factories to create our layout phases.
Again, enumerations are a good way to implement those factories. For example:
public enum NodeOrderStrategy implements ILayoutPhaseFactory<LayoutPhases, ElkNode> {
NODE_ORDERER,
ORDER_BALANCER;
@Override
public ILayoutPhase<LayoutPhases, ElkNode> create() {
switch (this) {
case NODE_ORDERER:
return new NodeOrderer();
case ORDER_BALANCER:
return new OrderBalancer();
default:
throw new IllegalArgumentException(
"No implementation is available for the node orderer " + this.toString());
}
}
}
Turning this into a separate enumeration allows this enumeration to be used as a layout option value for clients to specify which implementation they want.
We are now ready to assemble the whole algorithm, for example like this:
private static final LayoutProcessorConfiguration<LayoutPhases, ElkNode> OTHER_PROCESSORS =
LayoutProcessorConfiguration.<LayoutPhases, ElkNode>create()
.addAfter(LayoutPhases.P4_EDGE_ROUTING, IntermediateProcessorStrategy.DETREEIFYING_PROC);
private final AlgorithmAssembler<LayoutPhases, ElkNode> algorithmAssembler =
AlgorithmAssembler.<LayoutPhases, ElkNode>create(LayoutPhases.class);
public void layout(ElkNode graph, IElkProgressMonitor progressMonitor) {
List<ILayoutProcessor<ElkNode>> algorithm = assembleAlgorithm(graph);
progressMonitor.begin("Tree layout", algorithm.size());
for (ILayoutProcessor<ElkNode> processor : algorithm) {
processor.process(graph, progressMonitor.subTask(1));
}
progressMonitor.done();
}
public List<ILayoutProcessor<ElkNode>> assembleAlgorithm(ElkNode graph) {
algorithmAssembler.reset();
// Configure phases
algorithmAssembler.setPhase(LayoutPhases.P1_TREEIFICATION,
graph.getProperty(MrTreeOptions.TREEIFICATION_STRATEGY));
algorithmAssembler.setPhase(LayoutPhases.P2_NODE_ORDERING,
graph.getProperty(MrTreeOptions.NODE_ORDERING_STRATEGY));
algorithmAssembler.setPhase(LayoutPhases.P3_NODE_PLACEMENT,
graph.getProperty(MrTreeOptions.NODE_PLACEMENT_STRATEGY));
algorithmAssembler.setPhase(LayoutPhases.P4_EDGE_ROUTING,
graph.getProperty(MrTreeOptions.EDGE_ROUTING_STRATEGY));
// Some algorithms need to add custom processors, independent of
// layout phases
algorithmAssembler.addProcessorConfiguration(OTHER_PROCESSORS);
// Assemble the algorithm
return algorithmAssembler.build(graph);
}
Going Further
There are still some subtle points that we have left out so far. The following are a few pointers for things that are possible:
- The question of what should be a phase and what should be an intermediate processor is a somewhat philosophical one. A rough guideline is whether something is always part of the algorithm. If so, it might be a good candidate for a phase. As another rough guideline, ask yourself whether different implementations are possible for something. If so, it should probably be a phase.
- The
AlgorithmAssemblersorts intermediate processors in the same processing slot by the order in which they appear in the intermediate processor enumeration, but that can be changed. In fact, all you need to do is throw a customComparatorat theAlgorithmAssembler. Your comparator might use other meta data available on the processors to sort them properly. The comparator only needs to be able to compare processors that will end up in the same processing slot. - It is possible for phases to be optional. While the
AlgorithmAssemblerusually throws an exception if thebuild(...)method is called while some phases are not yet configured, this behavior can be changed by callingwithFailOnMissingPhase(false).
